Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
ML.NET oferece a capacidade de adicionar aprendizado de máquina a aplicativos .NET, em cenários online ou offline. Com esse recurso, você pode fazer previsões automáticas usando os dados disponíveis para seu aplicativo. Os aplicativos de aprendizado de máquina fazem uso de padrões nos dados para fazer previsões, em vez de precisar ser explicitamente programado.
Central para ML.NET é um modelo de de aprendizado de máquina. O modelo especifica as etapas necessárias para transformar seus dados de entrada em uma previsão. Com ML.NET, você pode treinar um modelo personalizado especificando um algoritmo ou pode importar modelos pré-treinados do TensorFlow e do Open Neural Network Exchange (ONNX).
Depois de ter um modelo, você pode adicioná-lo ao seu aplicativo para fazer as previsões.
ML.NET é executado no Windows, Linux e macOS usando .NET ou no Windows usando o .NET Framework. 64 bits é suportado em todas as plataformas. 32 bits são suportados no Windows, exceto para TensorFlow, LightGBM e funcionalidade relacionada ao ONNX.
A tabela a seguir mostra exemplos do tipo de previsões que você pode fazer com ML.NET.
| Tipo de previsão | Exemplo |
|---|---|
| Classificação/Categorização | Divida automaticamente o feedback dos clientes em categorias positivas e negativas. |
| Regressão/Prever valores contínuos | Preveja o preço das casas com base no tamanho e na localização. |
| Deteção de anomalias | Detete transações bancárias fraudulentas. |
| Recomendações | Sugira produtos que os compradores on-line possam querer comprar, com base em suas compras anteriores. |
| Séries cronológicas/dados sequenciais | Prever o tempo ou as vendas de produtos. |
| Classificação de imagens | Categorizar patologias em imagens médicas. |
| Classificação de texto | Categorize documentos com base no seu conteúdo. |
| Semelhança de frases | Meça o quão semelhantes são duas frases. |
Aplicação ML.NET simples
O código no trecho a seguir demonstra o aplicativo ML.NET mais simples. Este exemplo constrói um modelo de regressão linear para prever os preços das casas usando dados de tamanho e preço da casa.
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public record HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public record Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new();
// 1. Import or create training data.
HouseData[] houseData = [
new() { Size = 1.1F, Price = 1.2F },
new() { Size = 1.9F, Price = 2.3F },
new() { Size = 2.8F, Price = 3.0F },
new() { Size = 3.4F, Price = 3.7F }
];
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline.
EstimatorChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> pipeline = mlContext.Transforms.Concatenate("Features", ["Size"])
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model.
TransformerChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> model = pipeline.Fit(trainingData);
// 4. Make a prediction.
HouseData size = new() { Size = 2.5F };
Prediction price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size * 1000} sq ft = {price.Price * 100:C}k");
// Predicted price for size: 2500 sq ft = $261.98k
}
}
Fluxo de trabalho de código
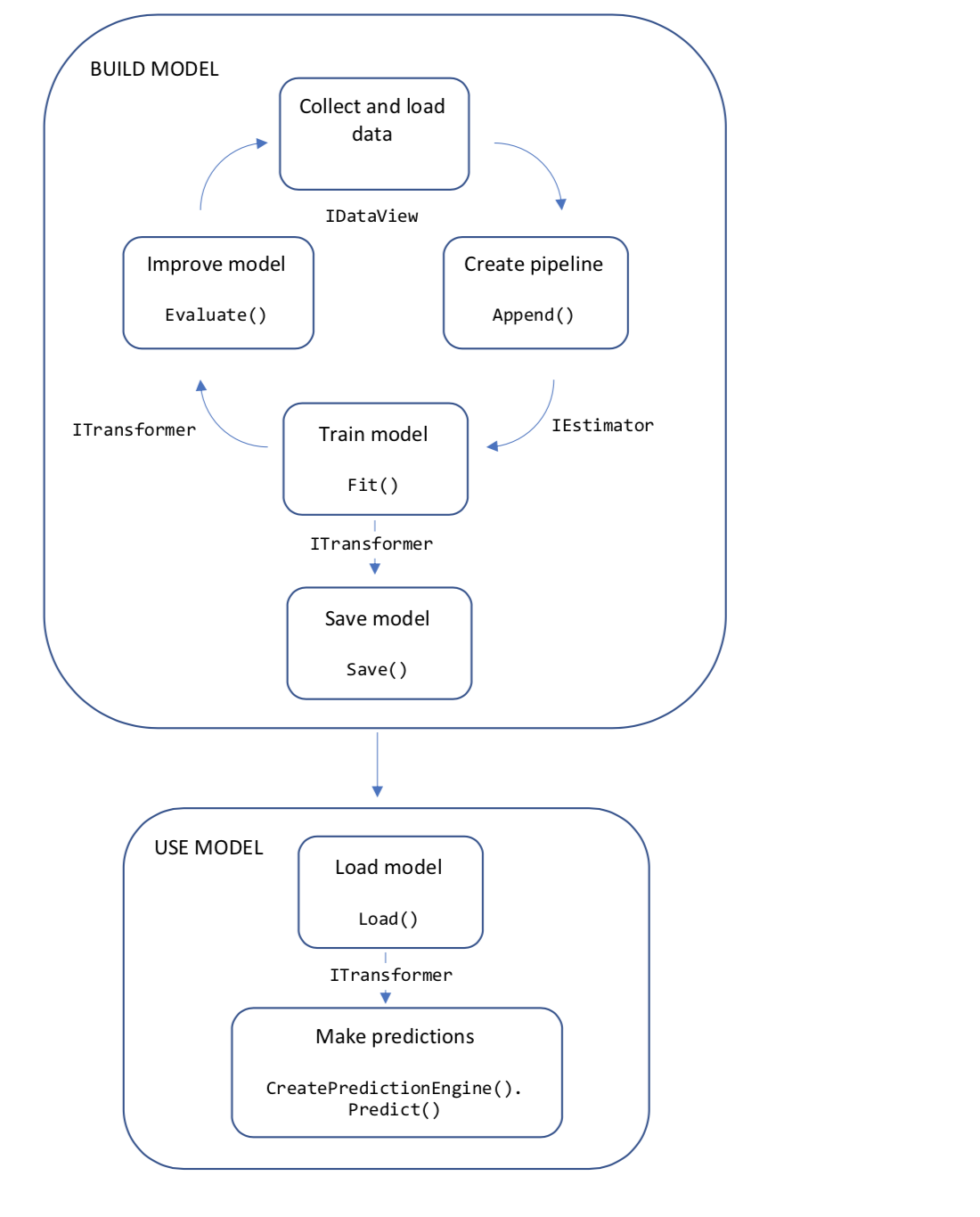
O diagrama a seguir representa a estrutura do código do aplicativo e o processo iterativo de desenvolvimento do modelo:
- Coletar e carregar dados de treinamento em um objeto IDataView
- Especificar um pipeline de operações para extrair recursos e aplicar um algoritmo de aprendizado de máquina
- Treine um modelo chamando Fit(IDataView) na pipeline
- Avalie o modelo e itere para melhorar
- Salve o modelo em formato binário, para uso em um aplicativo
- Carregue o modelo de volta em um objeto ITransformer
- Faça previsões ligando para PredictionEngineBase<TSrc,TDst>.Predict
Vamos nos aprofundar um pouco mais nesses conceitos.
Modelo de aprendizagem automática
Um modelo ML.NET é um objeto que contém transformações a serem executadas em seus dados de entrada para chegar à saída prevista.
Básico
O modelo mais básico é a regressão linear bidimensional, onde uma quantidade contínua é proporcional a outra, como no exemplo de preço da casa mostrado anteriormente.

O modelo é simples: $Price = b + Tamanho * w$. Os parâmetros $b$ e $w$ são estimados encaixando uma linha em um conjunto de pares (tamanho, preço). Os dados usados para encontrar os parâmetros do modelo são chamados de dados de treinamento. As entradas de um modelo de aprendizado de máquina são chamadas de recursos . Neste exemplo, $Size$ é o único recurso. Os valores de verdade-base usados para treinar um modelo de aprendizado de máquina são chamados de rótulos . Aqui, os valores de $Price$ no conjunto de dados de treinamento são os rótulos.
Mais complexo
Um modelo mais complexo classifica as transações financeiras em categorias usando a descrição do texto da transação.
Cada descrição de transação é dividida em um conjunto de recursos, removendo palavras e caracteres redundantes e contando combinações de palavras e caracteres. O conjunto de recursos é usado para treinar um modelo linear com base no conjunto de categorias nos dados de treinamento. Quanto mais semelhante uma nova descrição for às do conjunto de treino, maior a probabilidade de ser atribuída à mesma categoria.

Tanto o modelo de preço da casa como o modelo de classificação de texto são modelos lineares. Dependendo da natureza dos seus dados e do problema que você está resolvendo, você também pode usar árvore de decisão modelos, modelos de aditivos generalizados e outros. Você pode saber mais sobre os modelos em Tarefas.
Preparação dos dados
Na maioria dos casos, os dados que você tem disponíveis não são adequados para serem usados diretamente para treinar um modelo de aprendizado de máquina. Os dados brutos precisam ser preparados, ou pré-processados, antes de poderem ser usados para encontrar os parâmetros do seu modelo. Seus dados podem precisar ser convertidos de valores de cadeia de caracteres para uma representação numérica. Você pode ter informações redundantes em seus dados de entrada. Talvez seja necessário reduzir ou expandir as dimensões dos dados de entrada. Seus dados podem precisar ser normalizados ou dimensionados.
Os tutoriais ML.NET ensinam sobre diferentes pipelines de processamento de dados para texto, imagem, dados numéricos e de séries cronológicas usados para tarefas específicas de aprendizagem automática.
Como preparar seus dados mostra como aplicar a preparação de dados de forma mais geral.
Você pode encontrar um apêndice de todas as transformações disponíveis na seção de recursos.
Avaliação do modelo
Depois de treinar seu modelo, como você sabe o quão bem ele fará previsões futuras? Com ML.NET, você pode avaliar seu modelo em relação a alguns novos dados de teste.
Cada tipo de tarefa de aprendizado de máquina tem métricas usadas para avaliar a precisão do modelo em relação ao conjunto de dados de teste.
O exemplo de preço da casa mostrado anteriormente usou a tarefa Regressão. Para avaliar o modelo, adicione o seguinte código ao exemplo original.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
As métricas de avaliação informam que o erro é baixo e que a correlação entre a saída prevista e a saída do teste é alta. Foi fácil! Em exemplos reais, é preciso mais ajuste para alcançar boas métricas de modelo.
ML.NET arquitetura
Esta seção descreve os padrões arquitetônicos de ML.NET. Se você for um desenvolvedor .NET experiente, alguns desses padrões serão familiares para você e outros serão menos familiares.
Um aplicativo ML.NET começa com um objeto MLContext. Este objeto singleton contém catálogos. Um catálogo é uma fábrica para carregamento e salvamento de dados, transformações, instrutores e componentes de operação de modelo. Cada objeto de catálogo tem métodos para criar os diferentes tipos de componentes.
| Tarefa | Catálogo |
|---|---|
| Carregamento e gravação de dados | DataOperationsCatalog |
| Preparação dos dados | TransformsCatalog |
| Classificação binária | BinaryClassificationCatalog |
| Classificação multiclasse | MulticlassClassificationCatalog |
| Deteção de anomalias | AnomalyDetectionCatalog |
| Agrupamento | ClusteringCatalog |
| Previsão | ForecastingCatalog |
| Classificação | RankingCatalog |
| Regressão | RegressionCatalog |
| Recomendação | RecommendationCatalog |
| Séries cronológicas | TimeSeriesCatalog |
| Utilização do modelo | ModelOperationsCatalog |
Você pode navegar até os métodos de criação em cada uma das categorias listadas. Se você usar o Visual Studio, os catálogos também aparecerão via IntelliSense.
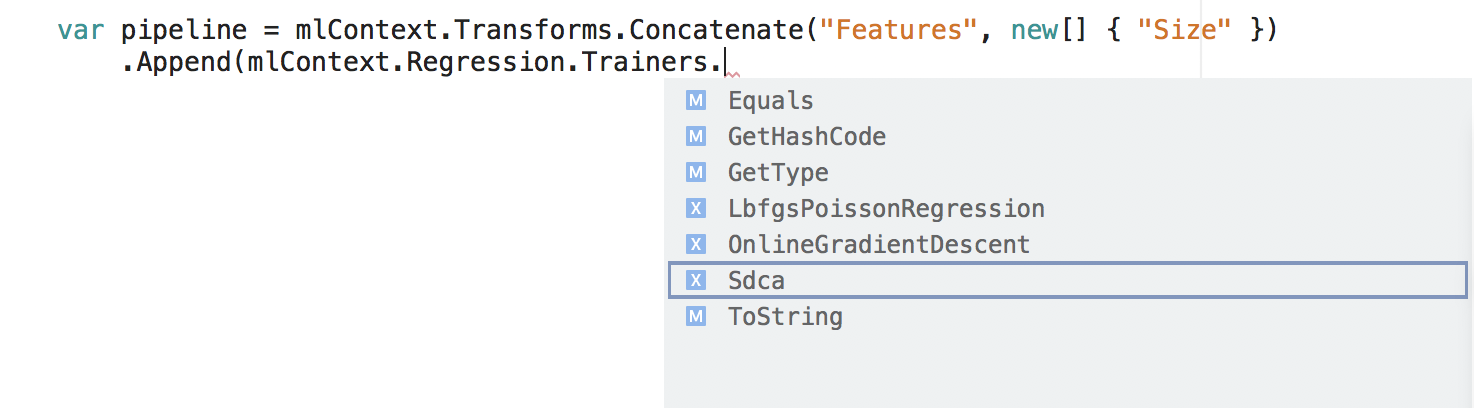
Construa o pipeline
Dentro de cada catálogo há um conjunto de métodos de extensão que você pode usar para criar um pipeline de treinamento.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
No trecho, ambos Concatenate e Sdca são métodos no catálogo. Cada um deles cria um objeto IEstimator que é anexado ao pipeline.
Neste ponto, os objetos foram criados, mas nenhuma execução aconteceu.
Treinar o modelo
Depois que os objetos no pipeline tiverem sido criados, os dados podem ser usados para treinar o modelo.
var model = pipeline.Fit(trainingData);
A chamada Fit() usa os dados de treinamento de entrada para estimar os parâmetros do modelo. Isso é conhecido como treinamento do modelo. Lembre-se, o modelo de regressão linear mostrado anteriormente tinha dois parâmetros de modelo: viés e peso. Após a chamada Fit(), os valores dos parâmetros são conhecidos. (A maioria dos modelos terá muito mais parâmetros do que isso.)
Você pode aprender mais sobre o treinamento de modelo em Como treinar seu modelo.
O objeto de modelo resultante implementa a interface ITransformer. Ou seja, o modelo transforma dados de entrada em previsões.
IDataView predictions = model.Transform(inputData);
Use o modelo
Você pode transformar dados de entrada em previsões em massa ou uma entrada de cada vez. O exemplo do preço da casa fez ambas as coisas: em grande escala para avaliar o modelo, e uma de cada vez para fazer uma nova previsão. Vamos analisar como fazer previsões individuais.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
O método CreatePredictionEngine() usa uma classe de entrada e uma classe de saída. Os nomes de campo ou atributos de código determinam os nomes das colunas de dados usadas durante o treinamento e a previsão do modelo. Para obter mais informações, consulte Fazer previsões com um modelo treinado.
Modelos de dados e esquema
No núcleo de um pipeline de aprendizado de máquina ML.NET estão objetos DataView.
Cada transformação no pipeline tem um esquema de entrada (nomes de dados, tipos e tamanhos que a transformação espera ver em sua entrada); e um esquema de saída (nomes de dados, tipos e tamanhos que a transformação produz após a transformação).
Se o esquema de saída de uma transformação no pipeline não corresponder ao esquema de entrada da próxima transformação, ML.NET lançará uma exceção.
Um objeto de exibição de dados tem colunas e linhas. Cada coluna tem um nome, um tipo e um comprimento. Por exemplo, as colunas de entrada no exemplo de preço da casa são Tamanho e Preço. Ambos são do tipo Single e são quantidades escalares em vez de vetoriais.
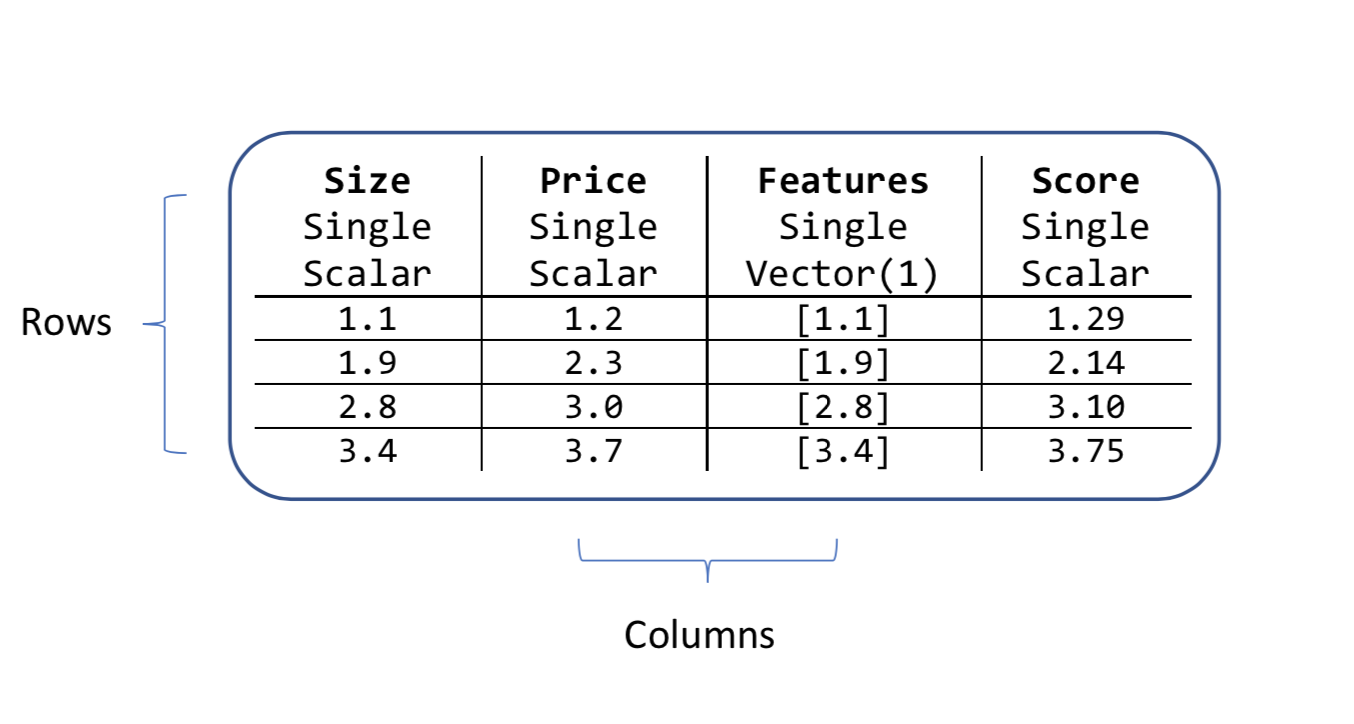
Todos os algoritmos ML.NET procuram uma coluna de entrada que seja um vetor. Por defeito, esta coluna vetorial é chamada de Características. É por isso que o exemplo de preço da casa concatenou a coluna Tamanho numa nova coluna chamada Características.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Todos os algoritmos também criam novas colunas depois de terem realizado uma previsão. Os nomes fixos dessas novas colunas dependem do tipo de algoritmo de aprendizado de máquina. Para a tarefa de regressão, uma das novas colunas é chamada Pontuação conforme mostrado no atributo de dados de preço.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Pode descobrir mais sobre colunas de saída de diferentes tarefas de aprendizagem automática no guia de Tarefas de Aprendizagem Automática.
Uma propriedade importante dos objetos DataView é que eles são avaliados de forma preguiçosa. As visualizações de dados só são carregadas e operadas durante o treinamento e a avaliação do modelo e a previsão de dados. Enquanto você está escrevendo e testando seu aplicativo ML.NET, você pode usar o depurador do Visual Studio para dar uma olhada em qualquer objeto de exibição de dados chamando o método
var debug = testPriceDataView.Preview();
Você pode observar a variável debug no depurador e examinar seu conteúdo.
Observação
Não use o método Preview(IDataView, Int32) no código de produção, pois ele degrada significativamente o desempenho.
Implantação do modelo
Em aplicações da vida real, o seu código de treinamento e avaliação do modelo será separado da sua previsão. Na verdade, estas duas atividades são muitas vezes realizadas por equipas separadas. Sua equipe de desenvolvimento de modelo pode salvar o modelo para uso no aplicativo de previsão.
mlContext.Model.Save(model, trainingData.Schema, "model.zip");
Próximos passos
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.