Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aprenda a treinar um modelo personalizado de aprendizagem profunda usando aprendizagem por transferência, um modelo TensorFlow pré-treinado e a API de Classificação de Imagens ML.NET para classificar imagens de superfícies de betão como rachadas ou não rachadas.
Neste tutorial, aprenderás como:
- Entenda o problema
- Saiba mais sobre ML.NET API de Classificação de Imagens
- Compreenda o modelo pré-treinado
- Use a aprendizagem por transferência para treinar um modelo personalizado de classificação de imagens TensorFlow
- Classificar imagens com o modelo personalizado
Pré-requisitos
Entenda o problema
A classificação de imagens é um problema de visão computacional. A classificação de imagens recebe uma imagem como entrada e categoriza-a numa classe prescrita. Os modelos de classificação de imagem são normalmente treinados usando aprendizagem profunda e redes neuronais. Para mais informações, veja Deep learning vs. machine learning.
Alguns cenários em que a classificação de imagens é útil incluem:
- Reconhecimento facial
- Deteção de emoções
- Diagnóstico médico
- Deteção de marcos
Este tutorial treina um modelo personalizado de classificação de imagens para realizar inspeção visual automatizada dos tabuleiros das pontes, de modo a identificar estruturas danificadas por fissuras.
ML.NET API de Classificação de Imagens
ML.NET fornece várias formas de realizar a classificação de imagens. Este tutorial aplica a aprendizagem por transferência usando a API de Classificação de Imagens. A API de Classificação de Imagens utiliza TensorFlow.NET, uma biblioteca de baixo nível que fornece ligações em C# para a API TensorFlow em C++.
O que é a transferência de aprendizagem?
A aprendizagem por transferência aplica o conhecimento adquirido ao resolver um problema para outro problema relacionado.
Treinar um modelo de aprendizagem profunda do zero requer definir vários parâmetros, uma grande quantidade de dados de treino rotulados e uma enorme quantidade de recursos computacionais (centenas de horas de GPU). Usar um modelo pré-treinado juntamente com aprendizagem por transferência permite-te encurtar o processo de treino.
Processo de formação
A API de Classificação de Imagens inicia o processo de treino carregando um modelo TensorFlow pré-treinado. O processo de formação consiste em dois passos:
- Fase de gargalo.
- Fase de treino.
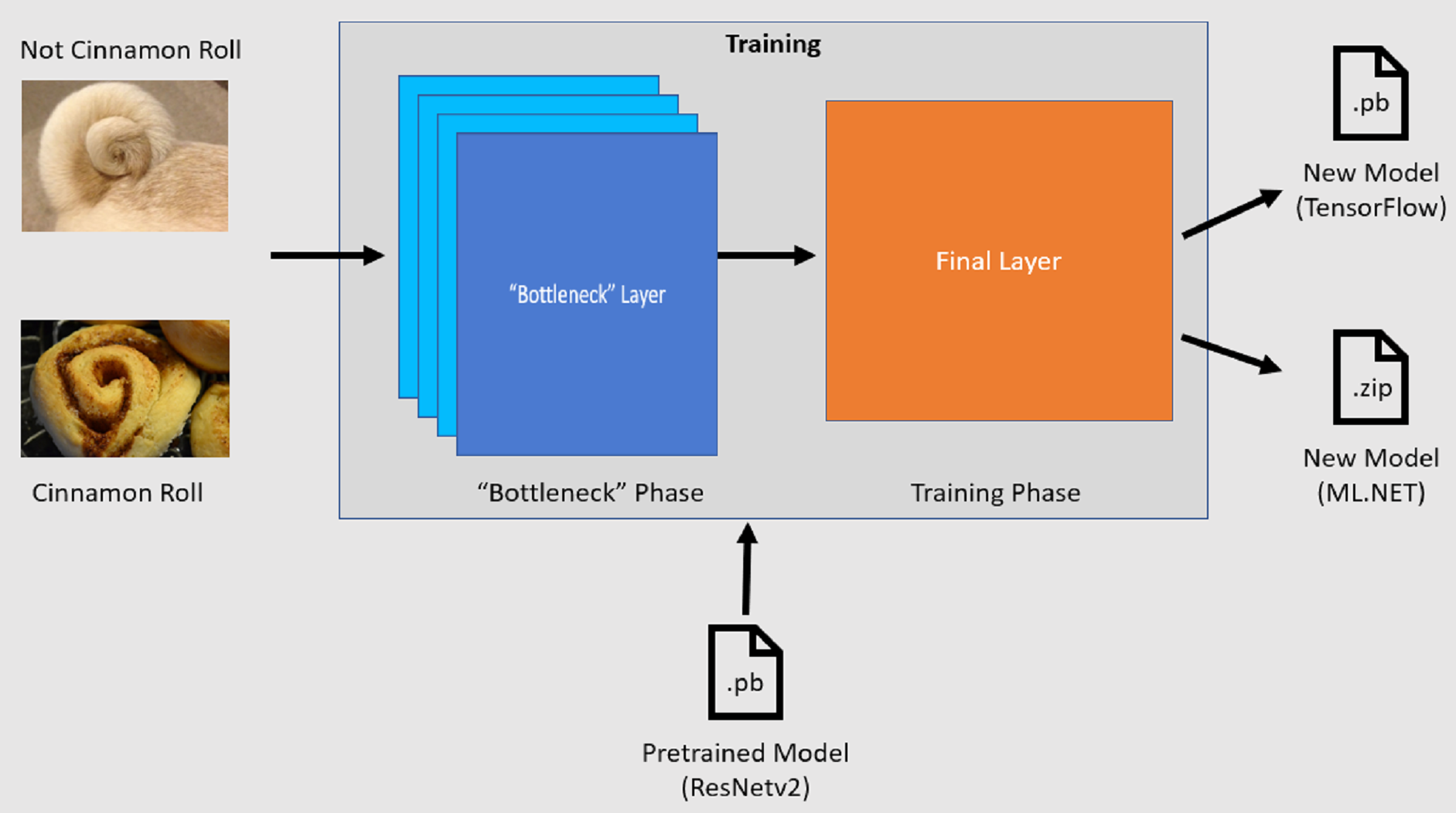
Fase de estrangulamento
Durante a fase de gargalo, o conjunto de imagens de treino é carregado e os valores dos píxeis são usados como entrada, ou funcionalidade, para as camadas congeladas do modelo pré-treinado. As camadas congeladas incluem todas as camadas da rede neural até à penúltima camada, informalmente conhecida como camada de gargalo. Estas camadas são chamadas de congeladas porque não há treino nestas camadas e as operações são de passagem direta. É nestas camadas congeladas que são calculados os padrões de nível inferior que ajudam um modelo a diferenciar entre as diferentes classes. Quanto maior o número de camadas, mais intensiva é esta etapa. Felizmente, como este é um cálculo único, os resultados podem ser armazenados em cache e usados em execuções posteriores quando se experimenta diferentes parâmetros.
Fase de formação
Depois de calculados os valores de saída da fase de gargalo, são usados como entrada para reeducar a camada final do modelo. Este processo é iterativo e executa-se pelo número de vezes especificado pelos parâmetros do modelo. Durante cada corrida, a perda e a precisão são avaliadas. Depois, são feitos os ajustes adequados para melhorar o modelo, com o objetivo de minimizar a perda e maximizar a precisão. Quando o treinamento termina, são gerados dois formatos de modelo. Um deles é a .pb versão do modelo, e o outro é a .zip versão ML.NET serializada do modelo. Ao trabalhar em ambientes suportados pela ML.NET, recomenda-se usar a .zip versão do modelo. No entanto, em ambientes onde ML.NET não é suportado, tens a opção de usar a .pb versão.
Compreenda o modelo pré-treinado
O modelo pré-treinado utilizado neste tutorial é a variante de 101 camadas do modelo Residual Network (ResNet) v2. O modelo original é treinado para classificar imagens em mil categorias. O modelo recebe como entrada uma imagem de tamanho 224 x 224 e apresenta as probabilidades de classe para cada uma das classes em que foi treinado. Parte deste modelo é usada para treinar um novo modelo usando imagens personalizadas para fazer previsões entre duas classes.
Criar aplicação de consola
Agora que tens uma compreensão geral da aprendizagem por transferência e da API de Classificação de Imagens, está na altura de construir a aplicação.
Crie uma aplicação de consola C# chamada "DeepLearning_ImageClassification_Binary". Clique no botão Seguinte.
Escolha .NET 8 como framework a usar e depois selecione Criar.
Instale o pacote NuGet Microsoft.ML:
Observação
Este exemplo utiliza a versão estável mais recente dos pacotes NuGet mencionados, salvo indicação em contrário.
- No Explorador de Soluções, clique com o botão direito no seu projeto e selecione Gerir Pacotes NuGet.
- Escolha "nuget.org" como fonte do pacote.
- Selecione a guia Procurar.
- Assinala a opção Incluir pré-lançamento .
- Procure Microsoft.ML.
- Selecione o botão Instalar.
- Seleciona o botão Aceitar no diálogo de Aceitação de Licença se concordares com os termos da licença dos pacotes listados.
- Repita estes passos para os pacotes NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (versão 2.3.1) e Microsoft.ML.ImageAnalytics .
Prepare e compreenda os dados
Observação
Os conjuntos de dados deste tutorial são de Maguire, Marc; Dorafshan, Sattar; e Thomas, Robert J., "SDNET2018: Um conjunto de dados de imagens de fissuras concretas para aplicações de aprendizagem automática" (2018). Consulte todos os conjuntos de dados. Papel 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 é um conjunto de dados de imagens que contém anotações para estruturas de betão rachadas e não rachadas (tabuleiros de pontes, paredes e pavimentos).

Os dados estão organizados em três subdiretórios:
- D contém imagens do tabuleiro da ponte
- P contém imagens do pavimento
- W contém imagens de parede
Cada um destes subdiretórios contém dois subdiretórios adicionais com prefixos:
- C é o prefixo usado para superfícies rachadas
- U é o prefixo usado para superfícies não rachadas
Neste tutorial, são usadas apenas imagens do tabuleiro da ponte.
- Descarregue o conjunto de dados e descompacte.
- Crie um diretório chamado "Assets" no seu projeto para guardar os ficheiros do seu conjunto de dados.
- Copie os subdiretórios CD e UD do diretório recentemente descompactado para o diretório Assets.
Criar classes de entrada e saída
Abra o ficheiro Program.cs e substitua o conteúdo existente pelas seguintes
usingdiretivas:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Crie uma classe chamada
ImageData. Esta classe é usada para representar os dados inicialmente carregados.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatacontém as seguintes propriedades:-
ImagePathé o caminho totalmente qualificado onde a imagem é armazenada. -
Labelé a categoria a que a imagem pertence. Este é o valor a prever.
-
Cria classes para os teus dados de entrada e saída.
Abaixo da
ImageDataclasse, defina o esquema dos seus dados de entrada numa nova classe chamadaModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputcontém as seguintes propriedades:-
Imageé abyte[]representação da imagem. O modelo espera que os dados de imagem sejam deste tipo para treinamento. -
LabelAsKeyé a representação numérica doLabel. -
ImagePathé o caminho totalmente qualificado onde a imagem é armazenada. -
Labelé a categoria a que a imagem pertence. Este é o valor a prever.
Apenas
ImageeLabelAsKeysão usados para treinar o modelo e fazer previsões. AsImagePathpropriedades eLabelsão mantidas para facilitar o acesso ao nome original do ficheiro de imagem e à categoria.-
Depois, abaixo da
ModelInputclasse, defina o esquema dos seus dados de saída numa nova classe chamadaModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputcontém as seguintes propriedades:-
ImagePathé o caminho totalmente qualificado onde a imagem é armazenada. -
Labelé a categoria original a que a imagem pertence. Este é o valor a prever. -
PredictedLabelé o valor previsto pelo modelo.
Semelhante a
ModelInput, apenas oPredictedLabelé necessário para fazer previsões, pois contém a previsão feita pelo modelo. AsImagePathpropriedades eLabelsão mantidas para facilitar o acesso ao nome e categoria original do ficheiro de imagem.-
Definir caminhos e inicializar variáveis
Nas
usingdiretivas, adicione o seguinte código a:Defina a localização dos ativos.
Inicialize a
mlContextvariável com uma nova instância de MLContext.A classe MLContext é um ponto de partida para todas as operações ML.NET, e inicializar o mlContext cria um novo ambiente ML.NET que pode ser partilhado entre os objetos de fluxo de trabalho de criação de modelos. É semelhante, do ponto de vista conceptual, ao
DbContextno Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Carregar os dados
Criar método de utilidade para carregamento de dados
As imagens são armazenadas em dois subdiretórios. Antes de carregar os dados, é necessário formatá-los numa lista de ImageData objetos. Para isso, crie o LoadImagesFromDirectory método:
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
O método LoadImagesFromDirectory:
- Obtém todos os caminhos dos ficheiros dos subdiretórios.
- Itera por cada um dos ficheiros usando uma
foreachinstrução e verifica se as extensões dos ficheiros são suportadas. A API de Classificação de Imagens suporta os formatos JPEG e PNG. - Obtém a etiqueta do ficheiro. Se o
useFolderNameAsLabelparâmetro for definido paratrue, então o diretório pai onde o ficheiro está guardado é usado como rótulo. Caso contrário, espera que o rótulo seja um prefixo do nome do ficheiro ou do próprio nome do ficheiro. - Cria uma nova instância de
ModelInput.
Preparar os dados
Adicione o código seguinte após a linha onde cria a nova instância de MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
O código anterior:
Chama o
LoadImagesFromDirectorymétodo utilitário para obter a lista de imagens usadas para treino após inicializar amlContextvariável.Carrega as imagens num
IDataViewusando oLoadFromEnumerablemétodo.Embaralha os dados usando o
ShuffleRowsmétodo. Os dados são carregados pela ordem em que foram lidos a partir dos diretórios. O embaralhamento é realizado para garantir o equilíbrio.Realiza algum pré-processamento dos dados antes do treino. Isto acontece porque os modelos de aprendizagem automática esperam que a entrada seja em formato numérico. O código de pré-processamento cria um
EstimatorChaincomposto pelasMapValueToKeyeLoadRawImageBytestransformações. AMapValueToKeytransformação pega no valor categórico daLabelcoluna, converte-o num valor numéricoKeyTypee armazena-o numa nova coluna chamadaLabelAsKey.LoadImagesretira os valores da colunaImagePathjuntamente com o parâmetroimageFolderpara o carregamento de imagens para treino.Utiliza o
Fitmétodo para aplicar os dados aopreprocessingPipelineEstimatorChainmétodo seguidoTransform, que devolve eIDataViewcontém os dados pré-processados.Divide os dados em conjuntos de treino, validação e teste.
Para treinar um modelo, é importante ter um conjunto de dados de treino, bem como um conjunto de dados de validação. O modelo é treinado no conjunto de treino. A qualidade das previsões sobre dados não vistos é medida pelo desempenho em relação ao conjunto de validação. Com base nos resultados desse desempenho, o modelo faz ajustes ao que aprendeu numa tentativa de melhorar. O conjunto de validação pode resultar da divisão do seu conjunto de dados original ou de outra fonte que já foi reservada para esse fim.
O exemplo de código realiza duas divisões. Primeiro, os dados pré-processados são divididos e 70% são usados para treino, enquanto os restantes 30% são usados para validação. Depois, o conjunto de validação de 30% é ainda dividido em conjuntos de validação e de teste, onde 90% são usados para validação e 10% para testes.
Uma forma de pensar no propósito destas partições de dados é fazer um exame. Ao estudar para um exame, revê as suas notas, livros ou outros recursos para compreender os conceitos que estão no exame. É para isso que serve o comboio. Depois, podes fazer um exame simulado para validar o teu conhecimento. É aqui que o conjunto de validação é útil. Deves verificar se tens um bom domínio dos conceitos antes de fazeres o exame propriamente dito. Com base nesses resultados, registas o que erraste ou não percebeste bem e incorporas as alterações enquanto reves para o exame real. Finalmente, fazes o exame. É para isto que o conjunto de testes é usado. Nunca viste as perguntas do exame e agora usa o que aprendeste com o treino e validação para aplicar o teu conhecimento à tarefa em questão.
Atribui às partições os respetivos valores para os dados de comboio, validação e teste.
Defina o pipeline de treinamento
O treino de modelos consiste em dois passos. Primeiro, a API de Classificação de Imagens é usada para treinar o modelo. Depois, as etiquetas codificadas na PredictedLabel coluna são convertidas de volta ao seu valor categórico original usando a transformação MapKeyToValue.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
O código anterior:
Cria uma nova variável para armazenar um conjunto de parâmetros obrigatórios e opcionais para um ImageClassificationTrainer. An ImageClassificationTrainer assume vários parâmetros opcionais:
-
FeatureColumnNameé a coluna usada como entrada para o modelo. -
LabelColumnNameé a coluna para o valor a prever. -
ValidationSeté oIDataViewque contém os dados de validação. -
Archdefine qual das arquiteturas de modelos pré-treinadas utilizar. Este tutorial utiliza a variante de 101 camadas do modelo ResNetv2. -
MetricsCallbackvincula uma função para acompanhar o progresso durante o treino. -
TestOnTrainSetdiz ao modelo para medir o desempenho em relação ao conjunto de treino quando não existe um conjunto de validação presente. -
ReuseTrainSetBottleneckCachedValuesindica ao modelo se deve usar os valores em cache da fase de gargalo em execuções subsequentes. A fase de gargalo é um cálculo de passagem única que é computacionalmente intensivo na primeira vez que é realizado. Se os dados de treino não mudarem e quiseres experimentar usar um número diferente de épocas ou tamanho de lote, usar os valores em cache reduz significativamente o tempo necessário para treinar um modelo. -
ReuseValidationSetBottleneckCachedValuesé semelhante aReuseTrainSetBottleneckCachedValues, mas neste caso, é para o conjunto de dados de validação.
-
Define-se o
EstimatorChainfluxo de trabalho de treino que consiste tanto nomapLabelEstimatorcomo no ImageClassificationTrainer.Usa o
Fitmétodo para treinar o modelo.
Use o modelo
Agora que treinaste o modelo, está na hora de o utilizar para classificar imagens.
Crie um novo método utilitário chamado OutputPrediction para mostrar informação de previsão na consola.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Classificar uma única imagem
Crie um método chamado
ClassifySingleImagepara fazer e gerar uma única previsão de imagem.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }O método
ClassifySingleImage:- Cria um
PredictionEngineinterior doClassifySingleImagemétodo. ÉPredictionEngineuma API de conveniência que permite passar e depois realizar uma previsão sobre uma única instância de dados. - Para aceder a uma única
ModelInputinstância, converte odataIDataViewem umIEnumerableusando oCreateEnumerablemétodo e depois obtém a primeira observação. - Usa o
Predictmétodo para classificar a imagem. - Envia a previsão para a consola com o
OutputPredictionmétodo.
- Cria um
Ligue
ClassifySingleImagedepois de chamar o métodoFitusando o conjunto de imagens de teste.ClassifySingleImage(mlContext, testSet, trainedModel);
Classificar múltiplas imagens
Crie um método chamado
ClassifyImagespara fazer e gerar múltiplas previsões de imagem.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }O método
ClassifyImages:- Cria e
IDataViewcontém as previsões usando oTransformmétodo. - Para iterar sobre as previsões, converte o
predictionDataIDataViewemIEnumerableusando o métodoCreateEnumerablee depois obtém as primeiras 10 observações. - Itera e gera os rótulos originais e previstos para as previsões.
- Cria e
Ligue
ClassifyImagesdepois de chamar o métodoClassifySingleImage()usando o conjunto de imagens de teste.ClassifyImages(mlContext, testSet, trainedModel);
Execute o aplicativo
Executa a tua aplicação de consola. A saída deve ser semelhante à seguinte.
Observação
Pode ver avisos ou mensagens de processamento; Essas mensagens foram removidas dos resultados seguintes para maior clareza. Para ser breve, o resultado foi condensado.
Fase de estrangulamento
Não é impresso nenhum valor para o nome da imagem porque as imagens são carregadas como a byte[] , portanto não há nome de imagem para mostrar.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fase de formação
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Classificar imagens de saída
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Ao inspecionar a imagem7001-220.jpg , pode confirmar que não está rachada, como o modelo previu.

Parabéns! Agora construiu com sucesso um modelo de deep learning para classificar imagens.
Melhorar o modelo
Se não estiver satisfeito com os resultados do modelo, pode tentar melhorar o seu desempenho tentando algumas das seguintes abordagens:
- Mais Dados: Quanto mais exemplos um modelo aprende, melhor tem o seu desempenho. Descarregue o conjunto de dados completo de SDNET2018 e use-o para treinar.
- Aumentar os dados: Uma técnica comum para adicionar variedade aos dados é aumentar os dados tirando uma imagem e aplicando diferentes transformações (rodar, inverter, deslocar, recortar). Isto acrescenta exemplos mais variados para o modelo aprender.
- Treine por mais tempo: Quanto mais tempo treinar, mais aperfeiçoado será o modelo. Aumentar o número de épocas pode melhorar o desempenho do seu modelo.
- Experimente com os hiperparâmetros: Para além dos parâmetros usados neste tutorial, outros parâmetros podem ser ajustados para potencialmente melhorar o desempenho. Alterar a taxa de aprendizagem, que determina a magnitude das atualizações feitas ao modelo após cada época, pode melhorar o desempenho.
- Use uma arquitetura de modelo diferente: Dependendo do aspeto dos seus dados, o modelo que melhor consegue aprender as suas características pode ser diferente. Se não estiver satisfeito com o desempenho do seu modelo, experimente mudar a arquitetura.
Próximos passos
Neste tutorial, aprendeste a construir um modelo personalizado de deep learning usando transfer learning, um modelo pré-treinado de classificação de imagens TensorFlow e a API ML.NET Image Classification para classificar imagens de superfícies de betão como rachadas ou não rachadas.
Avance para o próximo tutorial para saber mais.
Consulte também
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.