Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este tutorial apresenta um exemplo completo de um fluxo de trabalho Synapse Data Science no Microsoft Fabric. Ele usa tanto o recurso de dados nycflights13 quanto R para prever se um avião chega mais de 30 minutos atrasado. Em seguida, ele usa os resultados da previsão para criar um painel interativo do Power BI.
Neste tutorial, você aprenderá a:
Use pacotes tidymodels
- receitas
- Parsnip
- rsample
- fluxos de trabalho para processar dados e treinar um modelo de aprendizado de máquina
Gravar os dados de saída num lakehouse como uma tabela Delta
Criar um relatório visual no Power BI para aceder diretamente aos dados nesse lakehouse.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o seletor de experiência no canto inferior esquerdo da página inicial para alternar para o Fabric.
Abra ou crie um bloco de notas. Para saber como, consulte Como usar blocos de anotações do Microsoft Fabric.
Defina a opção de idioma como SparkR (R) para alterar o idioma principal.
Ligue o seu bloco de notas a uma casa no lago. No lado esquerdo, selecione Adicionar para adicionar uma casa de lago existente ou para criar uma casa de lago.
Instalar pacotes
Instale o pacote nycflights13 para usar o código neste tutorial.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Explore os dados
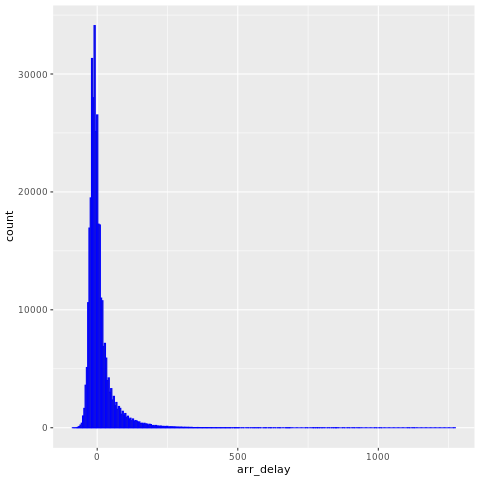
Os dados da nycflights13 têm informações sobre 325.819 voos que chegaram perto de Nova York em 2013. Em primeiro lugar, analise a distribuição dos atrasos nos voos. A célula de código abaixo gera um gráfico que indica que a distribuição do atraso de chegada está inclinada para a direita.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Tem uma cauda longa nos valores altos, como mostra a imagem a seguir:
Carregue os dados e faça algumas alterações nas variáveis:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Antes de construirmos o modelo, considere algumas variáveis específicas que têm importância tanto para o pré-processamento quanto para a modelagem.
A arr_delay variável é uma variável fatorial. Para o treinamento do modelo de regressão logística, é importante que a variável de resultado seja uma variável fatorial.
glimpse(flight_data)
Cerca de 16% dos voos deste conjunto de dados chegaram com mais de 30 minutos de atraso:
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
O dest recurso tem 104 destinos de voo:
unique(flight_data$dest)
Existem 16 transportadoras distintas:
unique(flight_data$carrier)
Dividir os dados
Divida o único conjunto de dados em dois conjuntos: um conjunto de treinamento e um conjunto de testes . Mantenha a maioria das linhas no conjunto de dados original (como um subconjunto escolhido aleatoriamente) no conjunto de dados de treinamento. Use o conjunto de dados de treinamento para ajustar o modelo e use o conjunto de dados de teste para medir o desempenho do modelo.
Use o pacote rsample para criar um objeto que contenha informações sobre como dividir os dados. Em seguida, use mais duas funções rsample para criar DataFrames para os conjuntos de treinamento e teste:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Criar uma receita e funções
Crie uma receita para um modelo de regressão logística simples. Antes de treinar o modelo, use uma receita para criar novos preditores e realize o pré-processamento que o modelo exige.
Use a função update_role(), com um papel personalizado chamado ID, para que as receitas saibam que flight e time_hour são variáveis. Uma função pode ter qualquer valor de carácter. A fórmula inclui todas as variáveis no conjunto de treino como preditores, exceto pela arr_delay. A receita mantém essas duas variáveis de ID, mas não as usa como resultados ou preditores:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Para exibir o conjunto atual de variáveis e funções, use a função summary():
summary(flights_rec)
Criar funcionalidades
A engenharia de recursos pode melhorar o seu modelo. A data do voo pode ter um efeito razoável na probabilidade de uma chegada tardia:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Pode ser útil adicionar termos do modelo, derivados da data, que tenham importância potencial para o modelo. Derive os seguintes recursos significativos da variável de data única:
- Dia da semana
- Mês
- Se a data corresponde ou não a um feriado
Adicione os três passos à sua receita:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Ajuste um modelo com uma receita
Use regressão logística para modelar os dados de voo. Primeiro, construa uma especificação de modelo com o pacote parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Utilize a embalagem workflows para agrupar o seu modelo de parsnip (lr_mod) com a sua receita (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Treinar o modelo
Esta função pode preparar a receita e treinar o modelo a partir dos preditores resultantes:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Use as funções auxiliares xtract_fit_parsnip() e extract_recipe() para extrair os objetos de modelo ou receita do fluxo de trabalho. Neste exemplo, extraia o objeto de modelo ajustado e depois use a função broom::tidy() para obter um tibble organizado de coeficientes de modelo.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Prever resultados
Uma única chamada para predict() usa o fluxo de trabalho treinado (flights_fit) para fazer previsões com os dados de teste invisíveis. O método predict() aplica a receita aos novos dados e, em seguida, passa os resultados para o modelo ajustado.
predict(flights_fit, test_data)
Obtenha a saída de predict() para retornar a classe prevista: late versus on_time. No entanto, para as probabilidades de classe previstas para cada voo, use augment() juntamente com o modelo e os dados de teste, para salvá-los em conjunto:
flights_aug <-
augment(flights_fit, test_data)
Analise os dados:
glimpse(flights_aug)
Avaliar o modelo
Agora temos um tibble com as previsões das probabilidades de classe. Nas primeiras filas, o modelo previu corretamente cinco voos pontuais (valores de .pred_on_time são p > 0.50). No entanto, precisamos de previsões para um total de 81.455 linhas.
Precisamos de uma métrica que diga quão bem o modelo previu chegadas tardias, em comparação com o verdadeiro status da variável de arr_delay resultado.
Use a Área Sob a Curva da Característica de Operação do Receptor (AUC-ROC) como métrica. Calcule-o com roc_curve() e roc_auc(), a partir do pacote yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Criar um relatório do Power BI
O resultado do modelo parece bom. Use os resultados da previsão de atraso de voo para criar um painel interativo do Power BI. O painel mostra o número de voos por companhia aérea e o número de voos por destino. O painel pode filtrar com base nos resultados da previsão de atrasos.

Inclua o nome da transportadora e o nome do aeroporto no conjunto de dados do resultado da previsão:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Analise os dados:
glimpse(flights_clean)
Converta os dados em um DataFrame do Spark:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Escreva os dados em uma tabela delta em sua casa do lago:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Use a tabela delta para criar um modelo semântico.
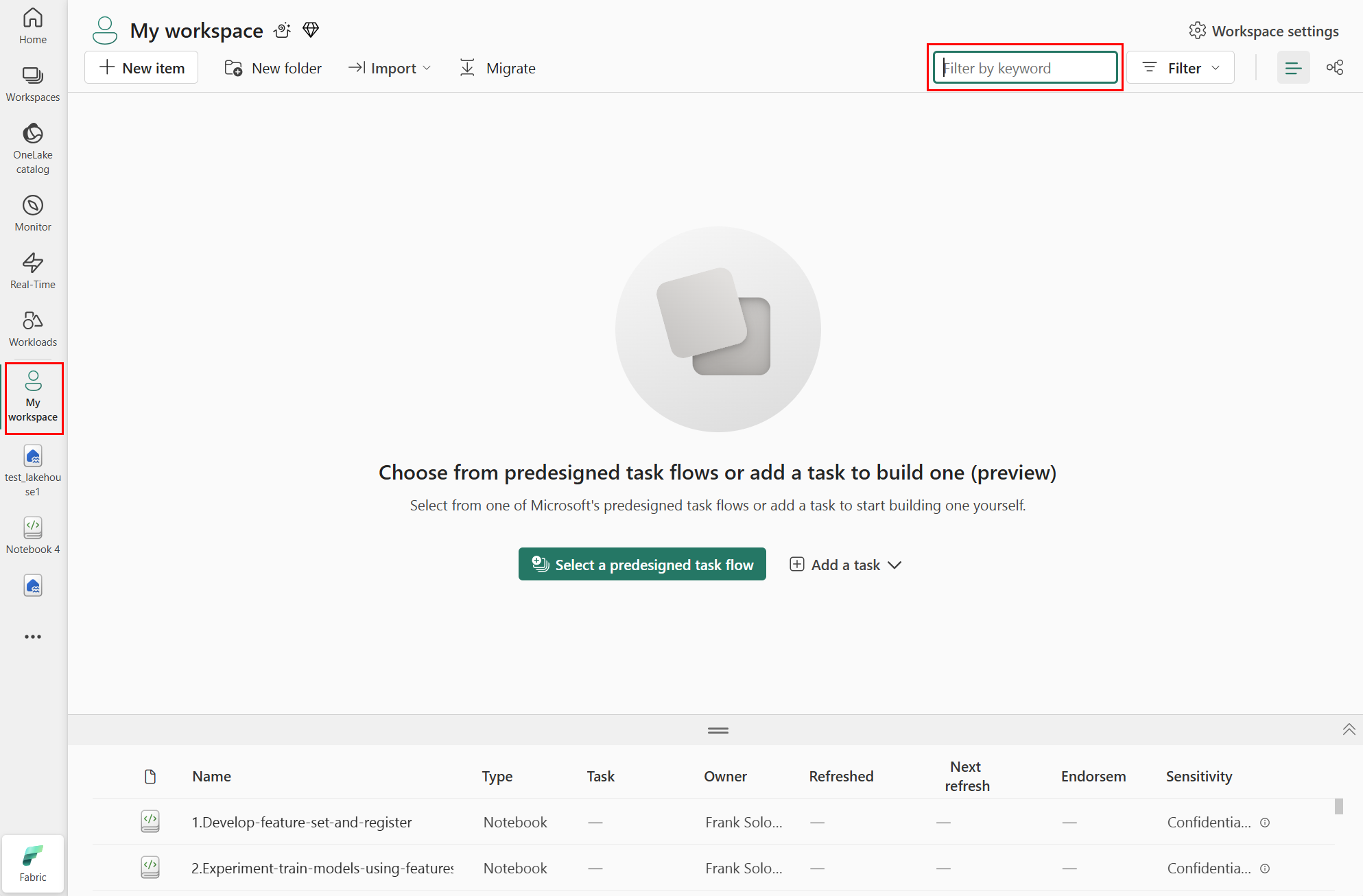
No painel de navegação esquerdo, selecione seu espaço de trabalho e, na caixa de texto no canto superior direito, digite o nome da casa do lago que você anexou ao seu bloco de anotações. A captura de tela a seguir mostra que selecionamos Meu espaço de trabalho:
Digite o nome da casa do lago que você anexou ao seu bloco de anotações. Entramos test_lakehouse1, como mostrado na captura de tela a seguir:
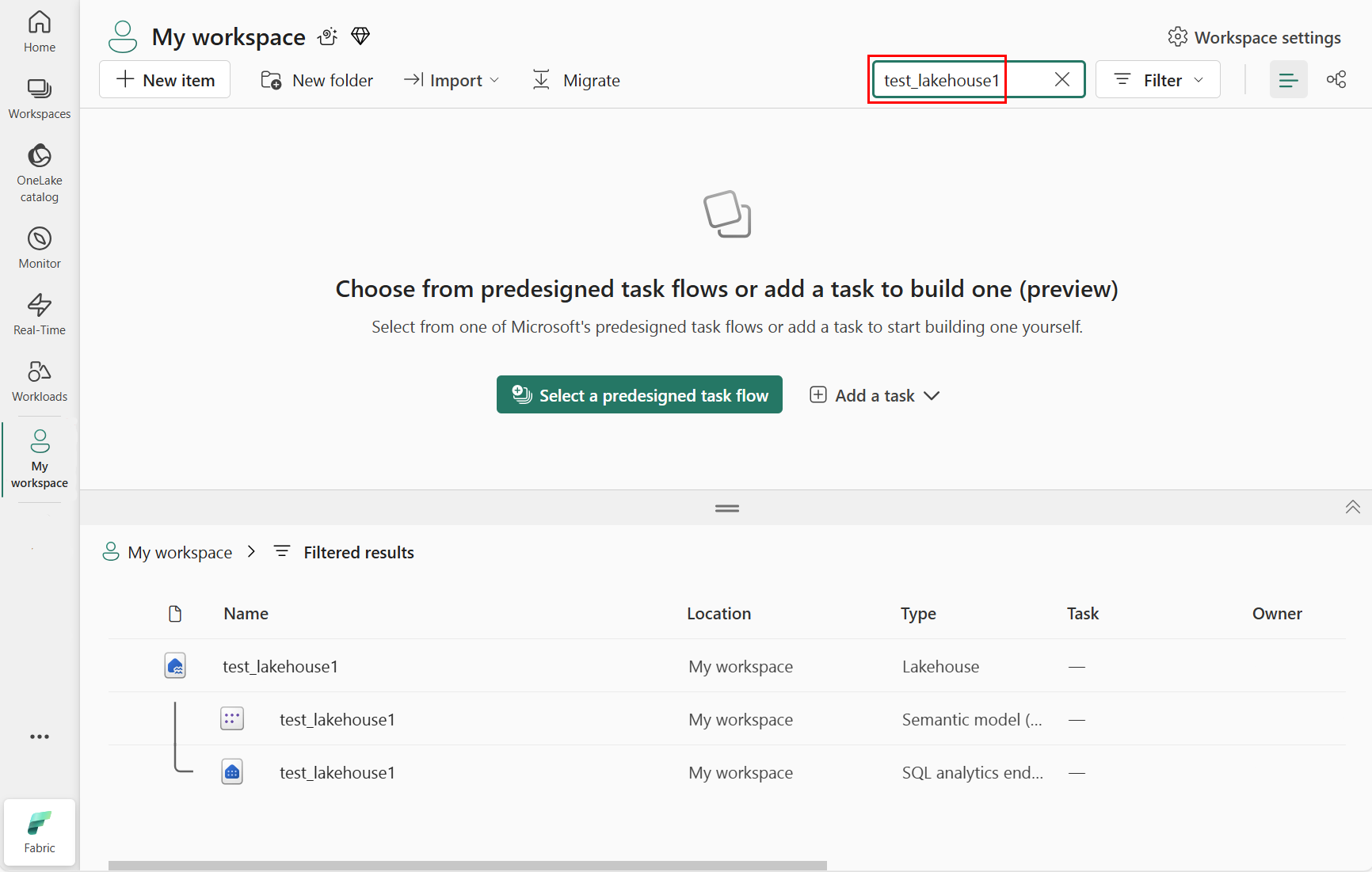
Na área de resultados filtrados, selecione a casa do lago, conforme mostrado na captura de tela a seguir:
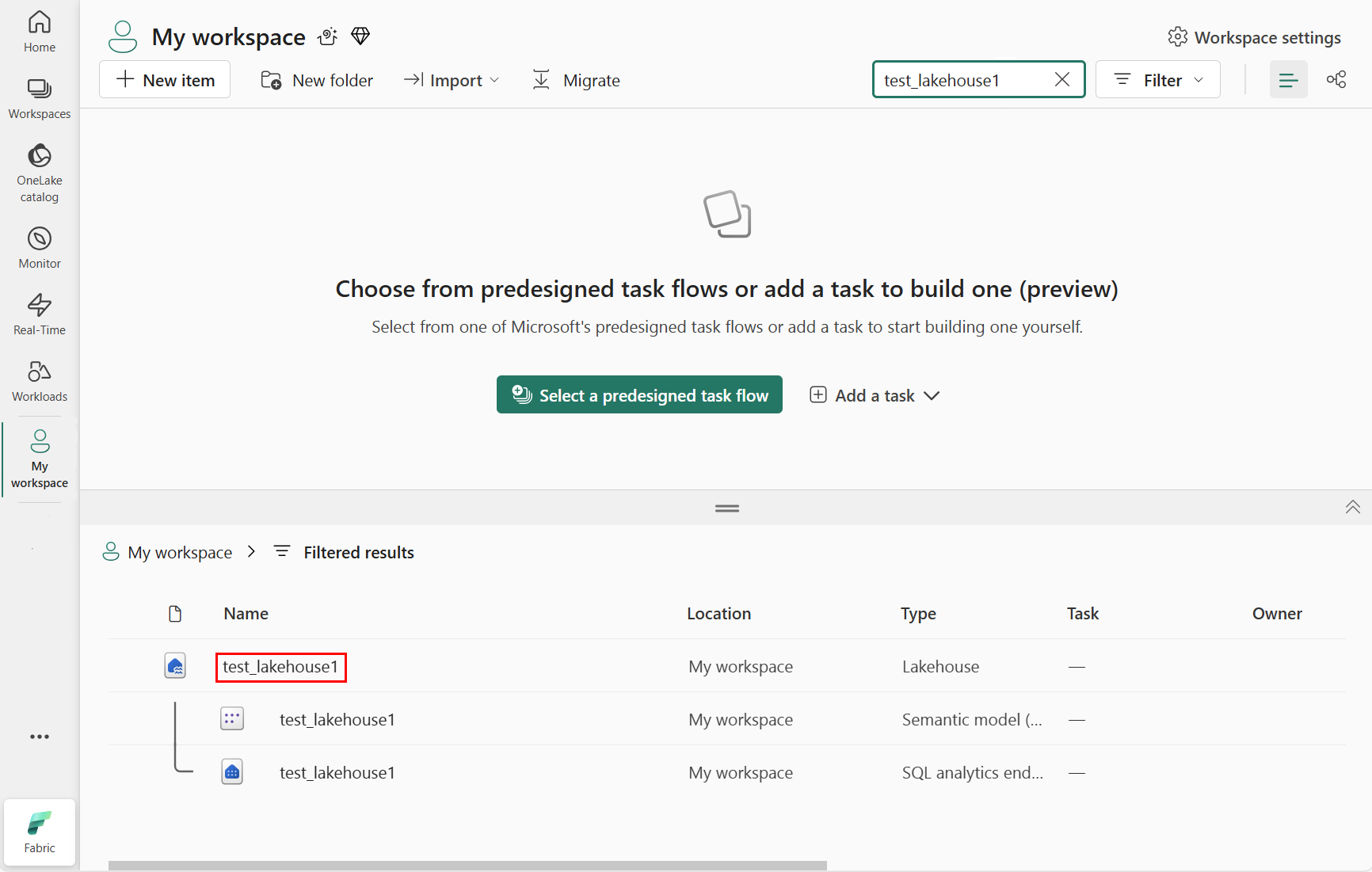
Selecione Novo modelo semântico , conforme mostrado na captura de tela a seguir:
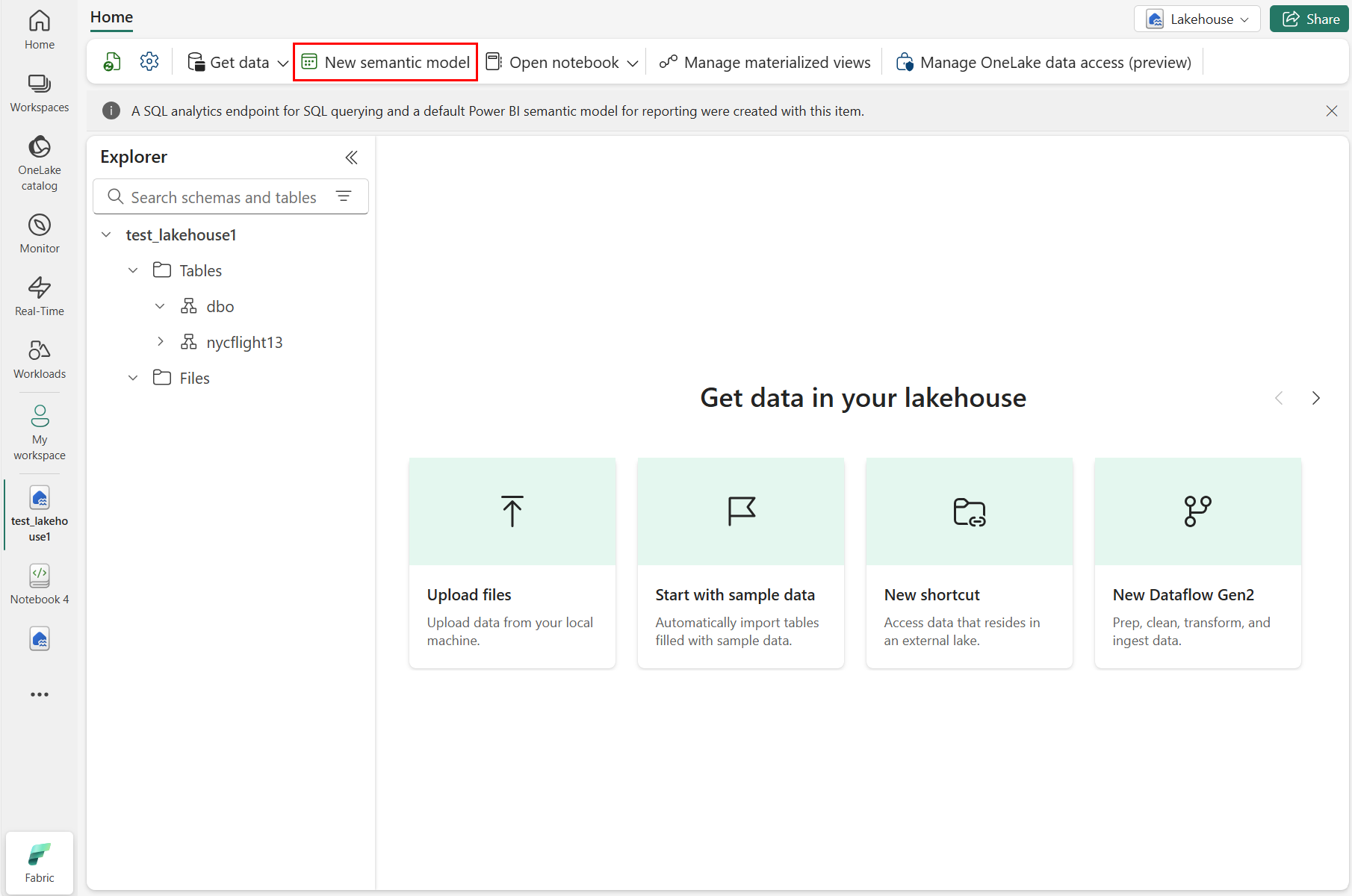
No painel Novo modelo semântico, insira um nome para o novo modelo semântico, selecione um espaço de trabalho e selecione as tabelas a serem usadas para esse novo modelo e, em seguida, selecione Confirmar, conforme mostrado na captura de tela a seguir:
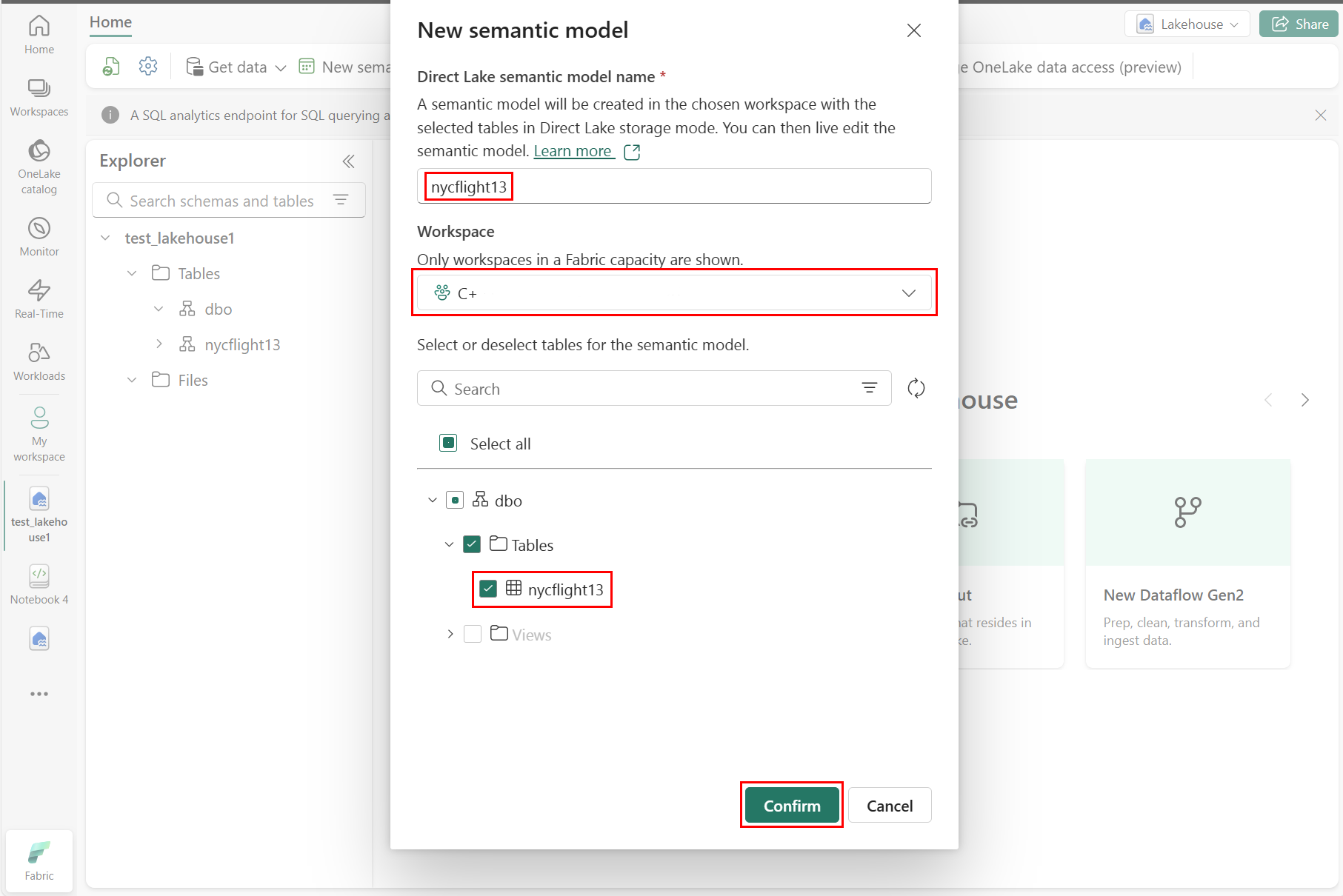
Para criar um novo relatório, selecione Criar novo relatório, conforme mostrado na captura de tela a seguir:
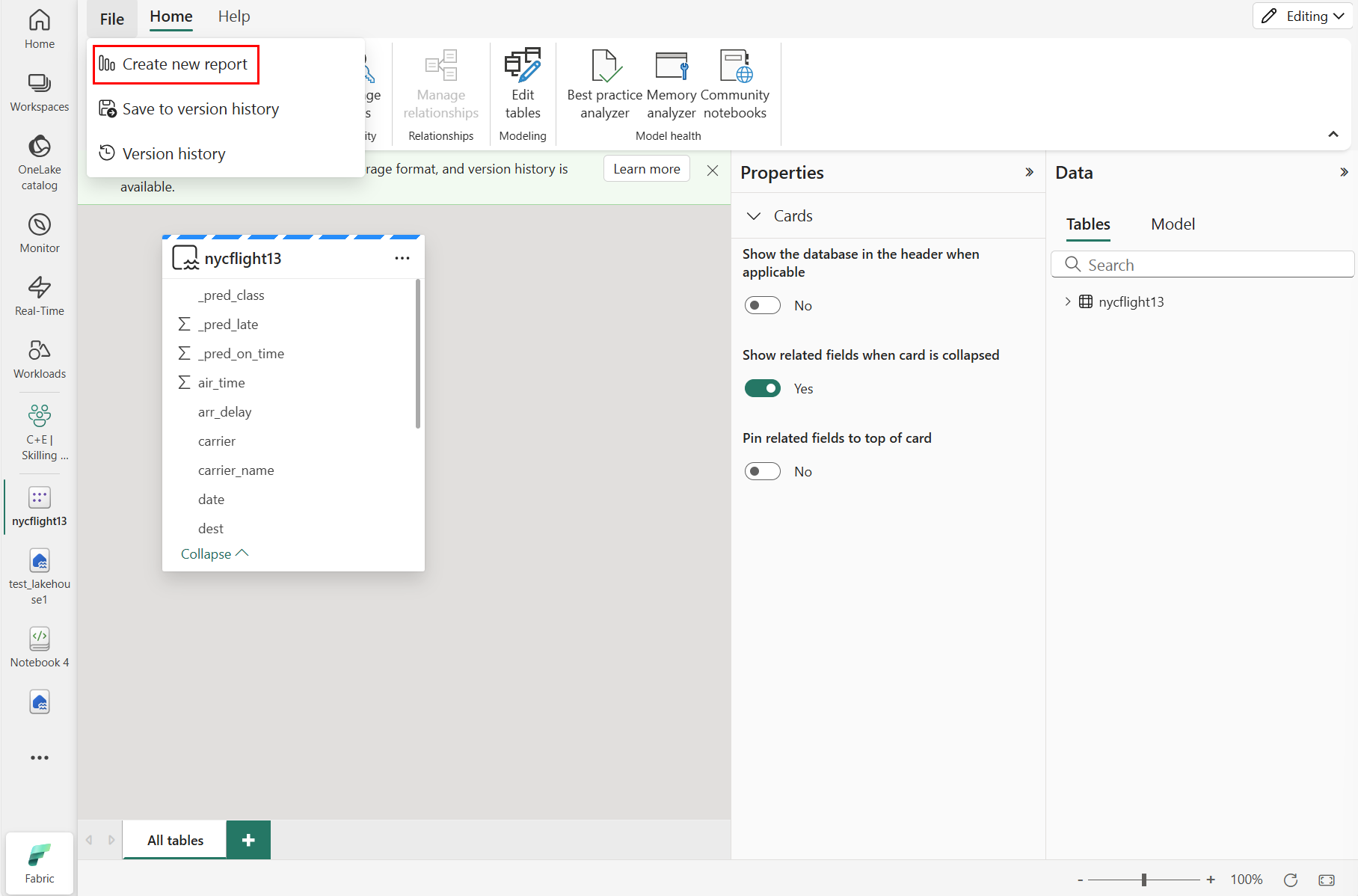
Selecione ou arraste campos dos painéis Dados e Visualizações para a tela do relatório para criar seu relatório
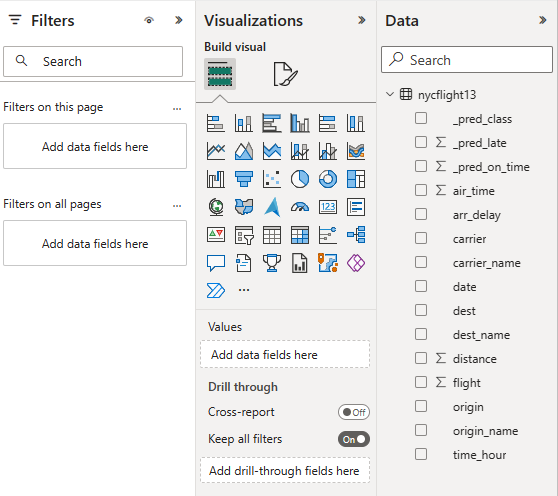






Para criar o relatório mostrado no início desta seção, use estas visualizações e dados:
-
 Gráfico de barras empilhado com:
Gráfico de barras empilhado com: - Eixo Y: carrier_name
- Eixo X: voo. Selecione Contagem para a agregação
- Legenda: origin_name
-
Gráfico de barras empilhado com:
- Eixo Y: dest_name
- Eixo X: voo. Selecione Contagem para o agrupamento
- Legenda: origin_name
-
 Filtro com:
Filtro com: - Domínio: _pred_class
-
Filtro com:
- Campo: _pred_late