Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se para:✅ Armazém no Microsoft Fabric
Este artigo destaca as funcionalidades e inovações na arquitetura do Fabric Data Warehouse que impulsionam o seu desempenho, escalabilidade e eficiência de custos.
O Fabric Data Warehouse funciona numa arquitetura preparada para o futuro numa plataforma de dados convergente. Com um formato de armazenamento Delta aberto e integração com o OneLake, os seus dados no Fabric Data Warehouse estão prontos para análise.
Arquitetura de alto nível

O Fabric Data Warehouse é concebido especificamente para análise em escala, com os seguintes blocos de construção:
| Bloco de construção | Descrição |
|---|---|
| Otimizador unificado de consultas | Gera um plano de execução ótimo para ambientes cloud distribuídos, independentemente da qualidade das consultas SQL criadas pelos utilizadores. |
| Processamento distribuído de consultas | Suporta a execução massiva de consultas paralelas com infraestrutura cloud de rápida escalabilidade automática, fornecendo instantaneamente os recursos computacionais necessários para as consultas. Cargas de trabalho SELECT e DML separadas utilizam pools distintos para uma execução eficiente e isolada. |
| Motor de Execução de Consultas | Um motor baseado em SQL para executar consultas analíticas em grandes volumes de dados com desempenho rápido e alta concorrência. |
| Gestão de metadados e transações | Os metadados residem no frontend, backend e tanto na cache SSD local como no armazenamento remoto OneLake. Suporta transações concorrentes e assegura a conformidade com o ACID. |
| Armazenamento em OneLake | Tabelas Estruturadas de Logs implementadas usando o formato de tabela Open Delta, um modelo lakehouse com armazenamento aberto seguro. |
| Plataforma Fabric | A Plataforma Fabric fornece um modelo unificado de autenticação e segurança, monitorização e auditoria. O seu Fabric Data Warehouse está automaticamente disponível para outros serviços da plataforma Fabric para satisfazer necessidades empresariais, incluindo Power BI, pipelines de dados no Data Factory, Real-Time Intelligence e mais. |
Motor unificado de otimização de consultas
O otimizador unificado de consultas no Fabric Data Warehouse é o motor que decide a forma mais inteligente de executar as suas consultas SQL.
Quando submete uma consulta, o otimizador unificado de consultas analisa possíveis formas de a executar: como juntar tabelas, onde mover dados e como usar recursos como CPU, memória e rede. O otimizador unificado de consultas não escolhe apenas a primeira opção, como também escolhe o plano mais ótimo dentro do tempo permitido, avaliando o custo através destes fatores e metadados e estatísticas disponíveis.
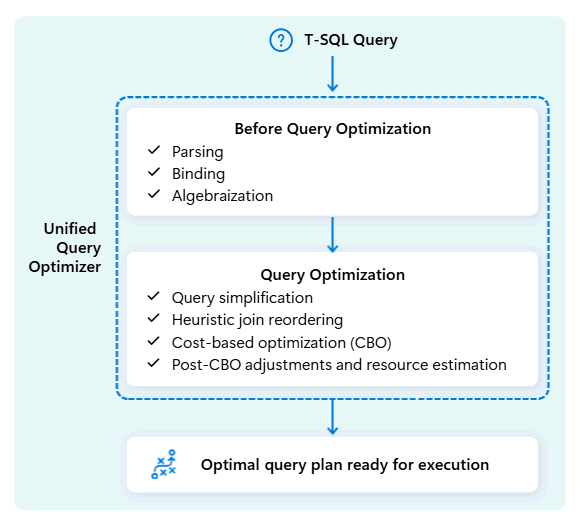
Ao otimizar o plano de execução de uma consulta, o otimizador unificado de consultas considera tudo de uma só vez: a forma da sua consulta, a distribuição dos dados das tabelas e o custo de mover dados em comparação com o processamento local. O otimizador de consultas unificado pode fazer compensações inteligentes, como decidir se transmitir uma tabela pequena é mais barato do que redistribuir uma grande. Isto significa menos embaralhamentos desnecessários de dados, melhor utilização do cálculo e desempenho mais rápido, mesmo para consultas T-SQL complexas ou mal escritas.
Um desempenho consistente não exige que os programadores dediquem tempo a ajustar manualmente as consultas em T-SQL. Por exemplo, não precisa de determinar manualmente a melhor JOIN ordem nas consultas. Se o seu SQL listar primeiro a tabela grande e depois uma tabela de dados mais pequena e altamente seletiva, o otimizador pode mudar automaticamente as suas posições para melhor desempenho. Vai usar a tabela menor como ponto de partida para as linhas correspondentes (o lado "build") e a tabela maior para procurar (o lado "probe", para verificação de correspondências). Esta abordagem minimiza o uso de memória, reduz o movimento de dados e melhora o paralelismo, mantendo ainda assim resultados precisos.
O otimizador unificado de consultas aprende continuamente com execuções anteriores de consultas à medida que as cargas de trabalho evoluem, refinando o seu algoritmo de otimização para oferecer o melhor desempenho possível. Os utilizadores beneficiam de uma execução rápida de consultas automaticamente, independentemente da complexidade e sem necessidade de intervir.
Motor de processamento de consultas distribuído
No Fabric Data Warehouse, o motor distribuído de processamento de consultas aloca recursos computacionais para tarefas nos planos de consulta. O motor distribuído de processamento de consultas pode agendar tarefas entre nós de computação para que cada nó execute parte de um plano de consulta, permitindo a execução paralela para um desempenho mais rápido. Relatórios complexos sobre grandes conjuntos de dados podem beneficiar do processamento distribuído de consultas.
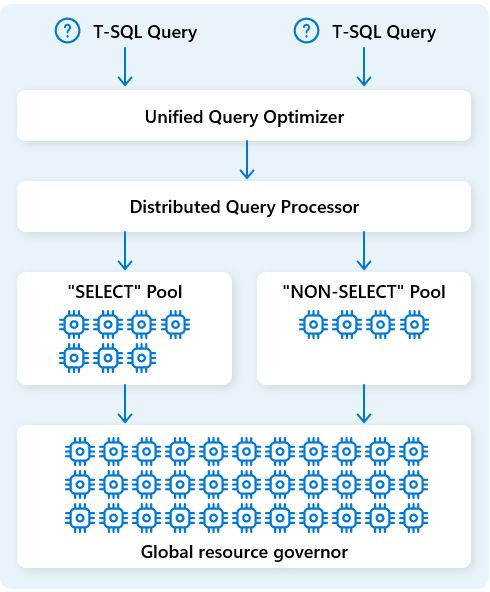
Para otimizar ainda mais os recursos, o motor distribuído de processamento de consultas separa os recursos computacionais em dois grupos: um para consultas SELECT e outro para tarefas de ingestão de dados, as consultas NON-SELECT. Cada carga de trabalho recebe recursos dedicados conforme necessário. Isto significa, por exemplo, que os seus trabalhos noturnos de ETL não vão atrasar os dashboards matinais.
Com o aprovisionamento rápido de nós na cloud, o motor distribuído de processamento de consultas escala automaticamente os recursos computacionais para cima ou para baixo em resposta a alterações no volume das consultas, tamanho dos dados e complexidade das consultas. O Fabric Data Warehouse tem capacidades de processamento paralelo para pequenos conjuntos de dados ou dados à escala de vários petabytes.
Motor de execução de consultas
O motor de execução de consultas é um processo que executa partes do plano de execução distribuído atribuídas aos nós de computação individuais. O motor de execução de consultas baseia-se no mesmo motor usado pelo SQL Server e pelo Azure SQL Database para usar formatos de execução em lote e dados colunares para análises eficientes em big data a um custo ótimo.
O motor de execução de consultas lê dados diretamente dos ficheiros Delta Parquet armazenados no Fabric OneLake e utiliza múltiplas camadas de cache (memória e SSD) para acelerar o desempenho das consultas e garantir que as consultas sejam executadas à velocidade ideal. O motor de execução de consultas processa dados na memória e, quando necessário, recupera dados adicionais da cache SSD ou do armazenamento OneLake.
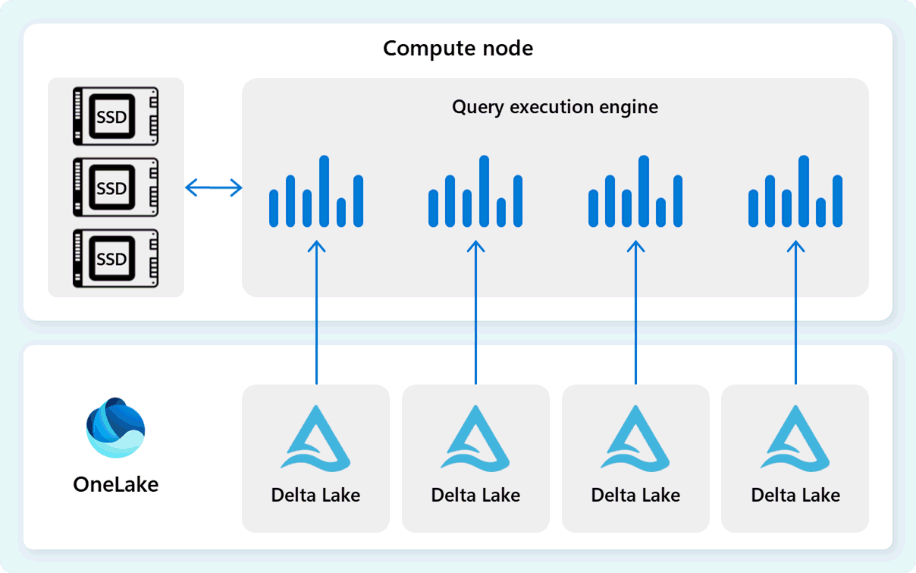
À medida que processa dados, o motor de execução de consultas realiza a eliminação de colunas e grupos de linhas para saltar segmentos que não são relevantes para a consulta. Esta otimização reduz a quantidade de dados digitalizados dos ficheiros e da cache de memória, ajudando a minimizar o uso de recursos e a melhorar o tempo total de execução.
O motor de execução de consultas destaca-se na filtragem e agregação de milhares de milhões de linhas, suportando os padrões genéricos de análise de dados usados nas soluções modernas de data warehouse. A execução em modo batch aproveita a capacidade moderna da CPU de processar múltiplas linhas em paralelo, reduzindo drasticamente a sobrecarga e fazendo com que as consultas corram até centenas de vezes mais rápido em comparação com a execução tradicional linha a linha.
Gestão de metadados e transações
O motor de armazém utiliza metadados para descrever o esquema da tabela, organização de ficheiros, histórico de versões e estados transacionais. Estes metadados permitem ao motor de armazém gerir e consultar dados de forma eficiente. O Fabric Data Warehouse oferece uma arquitetura robusta e abrangente de gestão de metadados e transações, estendendo um gestor de transações OLTP para orquestrar operações altamente concorrentes de metadados e garantir a conformidade com o ACID.
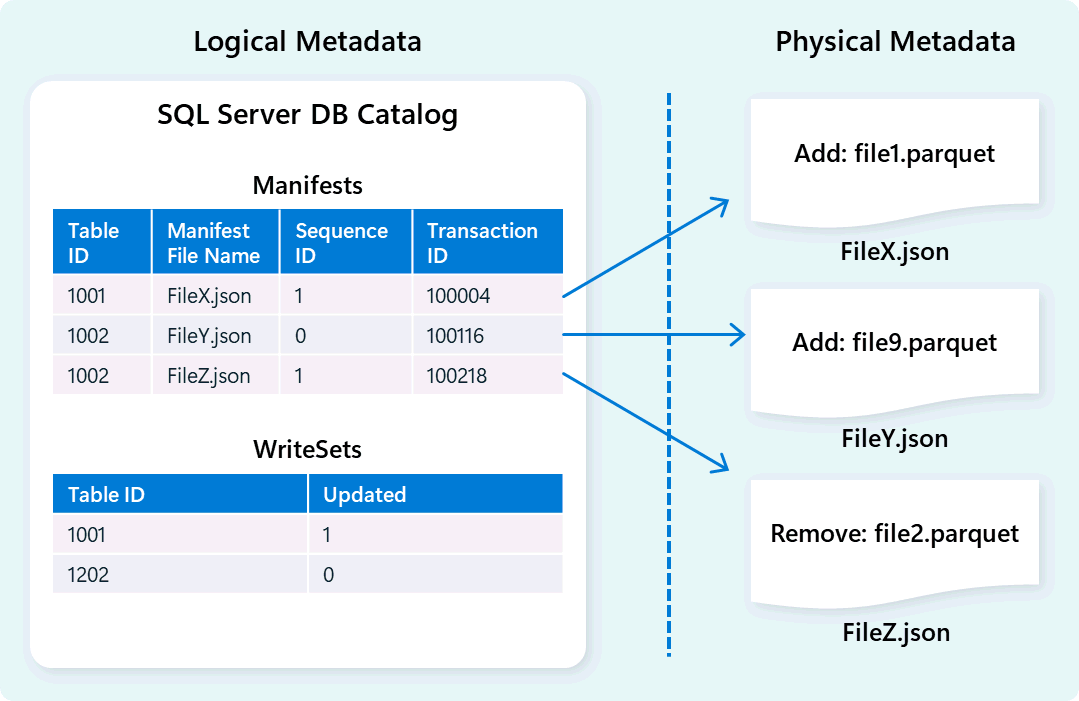
Este design permite uma navegação rápida e fiável de estados transacionais, suportando cargas de trabalho com elevada concorrência e garantindo consistência.
Armazenamento e ingestão de dados
O Fabric Data Warehouse utiliza uma arquitetura lakehouse com o formato open-source Delta para armazenamento escalável, seguro e de alto desempenho. O formato de tabela Delta suporta versionamento de dados, permitindo acesso instantâneo a instantâneos históricos através da viagem no tempo e clonagem sem cópia para testes seguros e operações de reversão. Os dados do utilizador são armazenados no OneLake, permitindo que todos os motores Fabric acedam eficientemente a dados partilhados sem redundância.
Com base nesta base, o Fabric Data Warehouse foi concebido para oferecer um desempenho ótimo na ingestão de dados, com foco na simplicidade e flexibilidade. O motor gere eficientemente o armazenamento de tabelas através da compactação automática de dados, que consolida ficheiros fragmentados em segundo plano para reduzir varreduras desnecessárias de dados. O seu método inteligente de distribuição de dados divide e organiza os dados em células microparticionadas para potenciar o processamento paralelo e melhorar os resultados das consultas. Estas capacidades funcionam de forma autónoma, sem necessidade de ajustes manuais.