Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo destina-se a modeladores de dados que desenvolvem modelos compostos do Power BI. Ele descreve casos de uso de modelos compostos e fornece orientação de projeto. Especificamente, a orientação pode ajudá-lo a determinar se um modelo composto é apropriado para sua solução. Se for, este artigo também o ajudará a projetar modelos e relatórios compostos ideais.
Nota
Uma introdução aos modelos compostos não é abordada neste artigo. Se você não estiver completamente familiarizado com modelos compostos, recomendamos que leia primeiro o artigo Usar modelos compostos no Power BI Desktop .
Como os modelos compostos consistem em pelo menos uma fonte DirectQuery, também é importante que você tenha uma compreensão completa das relações de modelo, modelos DirectQuery e diretrizes de design de modelo DirectQuery.
Casos de uso de modelos compostos
Por definição, um modelo composto combina vários grupos de fontes. Um grupo de origem pode representar dados importados ou uma conexão com uma fonte DirectQuery. Uma fonte do DirectQuery pode ser um banco de dados relacional ou outro modelo tabular, que pode ser um modelo semântico do Power BI ou um modelo tabular do Analysis Services. Quando um modelo tabular se conecta a outro modelo tabular, é conhecido como encadeamento. Para obter mais informações, consulte Usando o DirectQuery para modelos semânticos do Power BI e Analysis Services.
Nota
Quando um modelo se conecta a um modelo tabular, mas não o estende com dados adicionais, não é um modelo composto. Nesse caso, é um modelo DirectQuery que se conecta a um modelo remoto — portanto, compreende apenas um grupo de origem. Você pode criar esse tipo de modelo para modificar as propriedades do objeto do modelo de origem, como um nome de tabela, ordem de classificação de coluna ou cadeia de caracteres de formato.
A conexão a modelos tabulares é especialmente relevante ao estender um modelo semântico empresarial (quando é um modelo semântico do Power BI ou um modelo do Analysis Services). Um modelo semântico empresarial é fundamental para o desenvolvimento e operação de um data warehouse. Ele fornece uma camada de abstração sobre os dados no data warehouse para apresentar definições de negócios e terminologia. É normalmente utilizado como uma ligação entre modelos de dados físicos e ferramentas de relatórios, como o Power BI. Na maioria das organizações, ele é gerenciado por uma equipe central, e é por isso que é descrito como empresa. Para obter mais informações, consulte o cenário de uso de BI corporativo.
Você pode considerar o desenvolvimento de um modelo composto nas seguintes situações.
- Seu modelo pode ser um modelo DirectQuery e você deseja aumentar o desempenho. Em um modelo composto, você pode melhorar o desempenho configurando o armazenamento apropriado para cada tabela. Você também pode adicionar agregações definidas pelo usuário. Ambas as otimizações são descritas posteriormente neste artigo.
- Você deseja combinar um modelo DirectQuery com mais dados, que devem ser importados para o modelo. Você pode carregar dados importados de uma fonte de dados diferente ou de tabelas calculadas.
- Você deseja combinar duas ou mais fontes de dados DirectQuery em um único modelo. Essas fontes podem ser bancos de dados relacionais ou outros modelos tabulares.
Nota
Os modelos compostos não podem incluir conexões com determinados bancos de dados analíticos externos. Esses bancos de dados incluem o SAP Business Warehouse e o SAP HANA ao tratar o SAP HANA como uma fonte multidimensional.
Avaliar outras opções de design de modelo
Embora os modelos compostos do Power BI possam resolver desafios de design específicos, eles podem contribuir para um desempenho lento. Além disso, em algumas situações, podem ocorrer resultados de cálculo inesperados (descritos mais adiante neste artigo). Por estas razões, avalie outras opções de design de modelo quando existirem.
Sempre que possível, é melhor desenvolver um modelo no modo de importação. Este modo proporciona a maior flexibilidade de design e o melhor desempenho.
No entanto, os desafios relacionados a grandes volumes de dados ou relatórios sobre dados quase em tempo real nem sempre podem ser resolvidos por modelos de importação. Em qualquer um desses casos, você pode considerar um modelo DirectQuery, desde que seus dados sejam armazenados em uma única fonte de dados suportada pelo modo DirectQuery. Para obter mais informações, consulte Modelos DirectQuery no Power BI Desktop.
Gorjeta
Se o seu objetivo for apenas estender um modelo tabular existente com mais dados, sempre que possível, adicione esses dados à fonte de dados existente.
Modo de armazenamento de tabela
Em um modelo composto, você pode definir o modo de armazenamento para cada tabela (exceto tabelas calculadas).
- DirectQuery: Recomendamos que você defina esse modo para tabelas que representam grandes volumes de dados ou que precisam fornecer resultados quase em tempo real. Os dados nunca serão importados para estas tabelas. Normalmente, essas tabelas serão tabelas do tipo fato, que são tabelas que são resumidas.
- Importar: recomendamos que você defina esse modo para tabelas que não são usadas para filtragem e agrupamento de tabelas de fatos no modo DirectQuery ou híbrido. Também é a única opção para tabelas baseadas em fontes não suportadas pelo modo DirectQuery. As tabelas calculadas são sempre tabelas de importação.
- Dual: Recomendamos que você defina esse modo para tabelas de tipo de dimensão, quando houver a possibilidade de elas serem consultadas junto com tabelas de tipo de fato DirectQuery da mesma fonte.
- Híbrido: Recomendamos que você defina esse modo adicionando partições de importação e uma partição DirectQuery a uma tabela de fatos quando quiser incluir as alterações de dados mais recentes em tempo real ou quando quiser fornecer acesso rápido aos dados usados com mais freqüência por meio de partições de importação, deixando a maior parte dos dados usados com pouca frequência no data warehouse.
Há vários cenários possíveis quando o Power BI consulta um modelo composto.
- Consulta apenas importação ou tabela(s) dupla(s): o Power BI recupera todos os dados do cache do modelo. Proporcionará o desempenho mais rápido possível. Esse cenário é comum para tabelas de tipo de dimensão consultadas por filtros ou visuais de segmentação de dados.
- Consulta tabela(s) dupla(s) ou tabela(s) DirectQuery da mesma origem: o Power BI recupera todos os dados enviando uma ou mais consultas nativas para a origem do DirectQuery. Ele proporcionará um bom desempenho, especialmente quando existirem índices apropriados nas tabelas de origem. Esse cenário é comum para consultas que relacionam tabelas de tipo de dimensão dupla e tabelas de tipo de fato DirectQuery. Essas consultas são intra-grupo de origem e, portanto, todas as relações um-para-um ou um-para-muitos são avaliadas como relações regulares.
- Consulta tabela(s) dupla(s) ou tabela(s) híbrida(s) da mesma origem: este cenário é uma combinação dos dois cenários anteriores. O Power BI recupera dados do cache do modelo quando ele está disponível em partições de importação, caso contrário, ele envia uma ou mais consultas nativas para a fonte do DirectQuery. Ele fornecerá o desempenho mais rápido possível porque apenas uma fatia dos dados é consultada no data warehouse, especialmente quando existem índices apropriados nas tabelas de origem. Quanto às tabelas de tipo de dimensão dupla e tabelas de tipo de fato do DirectQuery, essas consultas são intragrupo de origem e, portanto, todas as relações um-para-um ou um-para-muitos são avaliadas como relações regulares.
- Todas as outras consultas: essas consultas envolvem relações de grupo entre fontes. É porque uma tabela de importação se relaciona com uma tabela DirectQuery ou uma tabela dupla se relaciona com uma tabela DirectQuery de uma fonte diferente, caso em que ela se comporta como uma tabela de importação. Todas as relações são avaliadas como relações limitadas. Isso também significa que os agrupamentos aplicados a tabelas que não sejam do DirectQuery devem ser enviados para a fonte do DirectQuery como subconsultas materializadas (tabelas virtuais). Nesse caso, a consulta nativa pode ser ineficiente, especialmente para grandes conjuntos de agrupamento.
Em resumo, recomendamos que você:
- Considere cuidadosamente que um modelo composto é a solução certa — embora permita a integração no nível do modelo de diferentes fontes de dados, ele também introduz complexidades de projeto com possíveis consequências (descritas mais adiante neste artigo).
- Defina o modo de armazenamento como DirectQuery quando uma tabela for uma tabela de tipo fato que armazena grandes volumes de dados ou quando precisar fornecer resultados quase em tempo real.
- Considere o uso do modo híbrido definindo uma política de atualização incremental e dados em tempo real, ou particionando a tabela de fatos usando TOM, TMSL ou uma ferramenta de terceiros. Para obter mais informações, consulte Atualização incremental e dados em tempo real para modelos semânticos e o cenário de uso de gerenciamento avançado de modelo de dados.
- Defina o modo de armazenamento como Dual quando uma tabela for uma tabela do tipo dimensão e ela será consultada junto com o DirectQuery ou tabelas híbridas de tipo de fato que estão no mesmo grupo de origem.
- Defina frequências de atualização apropriadas para manter o cache do modelo para tabelas duplas e híbridas (e quaisquer tabelas calculadas dependentes) em sincronia com o(s) banco(s) de dados de origem.
- Esforce-se para garantir a integridade dos dados em todos os grupos de origem (incluindo o cache do modelo) porque as relações limitadas eliminarão linhas nos resultados da consulta quando os valores de coluna relacionados não corresponderem.
- Sempre que possível, otimize as fontes de dados DirectQuery com índices apropriados para associações, filtragem e agrupamento eficientes.
Agregações definidas pelo usuário
Você pode adicionar agregações definidas pelo usuário às tabelas do DirectQuery. Seu objetivo é melhorar o desempenho para consultas de grãos mais altas.
Quando as agregações são armazenadas em cache no modelo, elas se comportam como tabelas de importação (embora não possam ser usadas como uma tabela modelo). Adicionar agregações de importação a um modelo DirectQuery resultará em um modelo composto.
Nota
As tabelas híbridas não suportam agregações porque algumas das partições operam no modo de importação. Não é possível adicionar agregações no nível de uma partição DirectQuery individual.
Recomendamos que uma agregação siga uma regra básica: sua contagem de linhas deve ser pelo menos um fator de 10 menor do que a tabela subjacente. Por exemplo, se a tabela subjacente armazenar 1 bilhão de linhas, a tabela de agregação não deverá exceder 100 milhões de linhas. Essa regra garante que haja um ganho de desempenho adequado em relação ao custo de criação e manutenção da agregação.
Relações de grupo entre fontes
Quando uma relação de modelo abrange grupos de origem, ela é conhecida como uma relação de grupo entre fontes. As relações de grupo entre fontes também são relações limitadas porque não há um lado "um" garantido. Para obter mais informações, consulte Avaliação de relacionamento.
Nota
Em algumas situações, você pode evitar a criação de uma relação de grupo entre fontes. Consulte o tópico Usar segmentações de dados de sincronização mais adiante neste artigo.
Ao definir relações de grupo entre fontes, considere as seguintes recomendações.
- Use colunas de relacionamento de baixa cardinalidade: para obter o melhor desempenho, recomendamos que as colunas de relacionamento sejam de baixa cardinalidade, o que significa que elas devem armazenar menos de 50.000 valores exclusivos. Essa recomendação é especialmente verdadeira ao combinar modelos tabulares e para colunas que não sejam de texto.
- Evite usar colunas de relacionamento de texto grandes: se você precisar usar colunas de texto em uma relação, calcule o comprimento de texto esperado para o filtro multiplicando a cardinalidade pelo comprimento médio da coluna de texto. O comprimento possível do texto não deve exceder 1.000.000 caracteres.
- Aumente a granularidade do relacionamento: se possível, crie relacionamentos em um nível mais alto de granularidade. Por exemplo, em vez de relacionar uma tabela de data em sua chave de data, use sua chave de mês. Essa abordagem de design requer que a tabela relacionada inclua uma coluna de chave de mês e os relatórios não poderão mostrar fatos diários.
- Esforce-se para alcançar um design de relacionamento simples: crie apenas um relacionamento de grupo entre fontes quando for necessário e tente limitar o número de tabelas no caminho do relacionamento. Esta abordagem de design ajudará a melhorar o desempenho e evitar caminhos de relacionamento ambíguos.
Aviso
Como o Power BI Desktop não valida completamente as relações de grupo entre fontes, é possível criar relações ambíguas.
Cenário de relacionamento entre grupos de origem 1
Considere um cenário de um design de relacionamento complexo e como ele poderia produzir resultados diferentes, mas válidos.
Nesse cenário, a tabela Região no grupo de origem A tem uma relação com a tabela Data e a tabela Vendas no grupo de origem B. A relação entre a tabela Região e a tabela Data está ativa, enquanto a relação entre a tabela Região e a tabela Vendas está inativa. Além disso, há uma relação ativa entre a tabela Região e a tabela Vendas , ambas no grupo de origem B. A tabela Sales inclui uma medida chamada TotalSales e a tabela Region inclui duas medidas chamadas RegionalSales e RegionalSalesDirect.
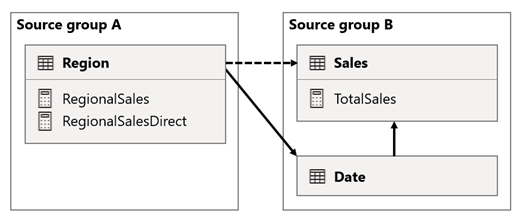
Aqui estão as definições de medida.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Observe como a medida RegionalSales se refere à medida TotalSales , enquanto a medida RegionalSalesDirect não. Em vez disso, a medida RegionalSalesDirect usa a expressão SUM(Sales[Sales]), que é a expressão da medida TotalSales.
A diferença no resultado é sutil. Quando o Power BI avalia a medida RegionalSales, aplica o filtro da tabela Região à tabela Sales e à tabela Data. Portanto, o filtro também se propaga da tabela Data para a tabela Vendas . Por outro lado, quando o Power BI avalia a medida RegionalSalesDirect , ele apenas propaga o filtro da tabela Região para a tabela Vendas . Os resultados retornados pela medida RegionalSales e pela medida RegionalSalesDirect podem diferir, mesmo que as expressões sejam semanticamente equivalentes.
Importante
Sempre que você usar a CALCULATE função com uma expressão que é uma medida em um grupo de origem remota, teste os resultados do cálculo minuciosamente.
Cenário de relacionamento entre grupos de origem 2
Considere um cenário em que uma relação de grupo entre fontes tenha colunas de relação de alta cardinalidade.
Nesse cenário, a tabela Data está relacionada à tabela Vendas nas colunas DateKey . O tipo de dados das colunas DateKey é inteiro, armazenando números inteiros que usam o formato aaaammdd . As tabelas pertencem a diferentes grupos de fontes. Além disso, é uma relação de alta cardinalidade porque a data mais antiga na tabela Data é 1º de janeiro de 1900 e a data mais recente é 31 de dezembro de 2100 — portanto, há um total de 73.414 linhas na tabela (uma linha para cada data no período de 1900-2100).
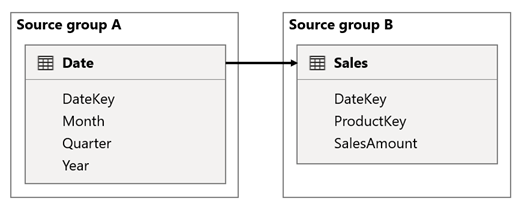
Há dois casos preocupantes.
Primeiro, quando você usa as colunas da tabela Data como filtros, a propagação do filtro filtrará a coluna DateKey da tabela Sales para avaliar medidas. Ao filtrar por um único ano, como 2022, a consulta DAX incluirá uma expressão de filtro como Sales[DateKey] IN { 20220101, 20220102, …20221231 }. O tamanho do texto da consulta pode crescer para se tornar extremamente grande quando o número de valores na expressão de filtro é grande ou quando os valores do filtro são cadeias de caracteres longas. É caro para o Power BI gerar a consulta longa e para a fonte de dados executar a consulta.
Em segundo lugar, quando você usa colunas da tabela Data, como Ano, Trimestre ou Mês, como colunas de agrupamento, isso resulta em filtros que incluem todas as combinações exclusivas de ano, trimestre ou mês e os valores da coluna DateKey. O tamanho da cadeia de caracteres da consulta, que contém filtros nas colunas de agrupamento e na coluna de relacionamento, pode se tornar extremamente grande. Isso é especialmente verdadeiro quando o número de colunas de agrupamento e/ou a cardinalidade da coluna de junção (a coluna DateKey ) é grande.
Para resolver quaisquer problemas de desempenho, você pode:
- Adicione a tabela Date à fonte de dados, resultando em um único modelo de grupo de origem (ou seja, não é mais um modelo composto).
- Aumente a granularidade da relação. Por exemplo, você pode adicionar uma coluna MonthKey a ambas as tabelas e criar a relação nessas colunas. No entanto, ao aumentar a granularidade da relação, você perde a capacidade de relatar a atividade diária de vendas (a menos que use a coluna DateKey da tabela Sales ).
Cenário de relacionamento entre grupos de origem 3
Considere um cenário em que não haja valores correspondentes entre tabelas em uma relação de grupo entre fontes.
Nesse cenário, a tabela Data no grupo de origem B tem uma relação com a tabela Vendas nesse grupo de origem e também com a tabela Destino no grupo de origem A. Todas as relações são um-para-muitos da tabela Data que relaciona as colunas Ano . A tabela Sales inclui uma coluna SalesAmount que armazena valores de vendas, enquanto a tabela Target inclui uma coluna TargetAmount que armazena valores de destino.
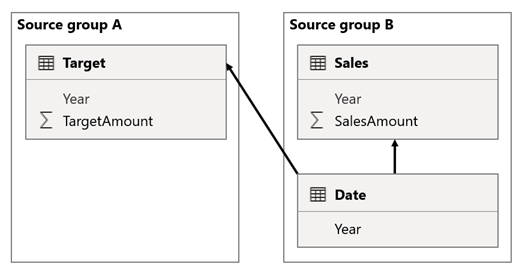
A tabela Data armazena os anos de 2021 e 2022. A tabela Vendas armazena os valores de vendas para os anos de 2021 (100) e 2022 (200), enquanto a tabela Meta armazena os valores-alvo para 2021 (100), 2022 (200) e 2023 (300) — um ano futuro.
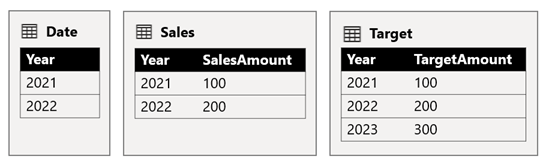
Quando um visual de tabela do Power BI consulta o modelo composto agrupando na coluna Ano da tabela Data e somando as colunas SalesAmount e TargetAmount , ele não mostrará um valor de destino para 2023. Isso ocorre porque a relação de grupo entre fontes é uma relação limitada e, portanto, usa INNER JOIN semântica, que elimina linhas onde não há valor correspondente em ambos os lados. No entanto, ele produzirá um total de valor alvo correto (600), porque um filtro de tabela Data não se aplica à sua avaliação.
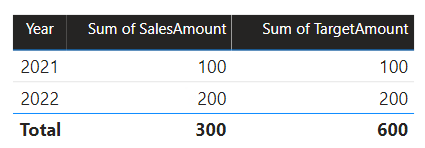
Se a relação entre a tabela Data e a tabela Destino for uma relação de grupo intra-origem (supondo que a tabela Destino pertencia ao grupo de origem B), o visual incluirá um ano (em branco) para mostrar o valor alvo de 2023 (e quaisquer outros anos incomparáveis).
Importante
Para evitar relatórios incorretos, verifique se há valores correspondentes nas colunas de relacionamento quando as tabelas de dimensões e fatos residirem em grupos de origem diferentes.
Para obter mais informações sobre relações limitadas, consulte Avaliação de relacionamentos.
Cálculos
Você deve considerar limitações específicas ao adicionar colunas calculadas e grupos de cálculo a um modelo composto.
Colunas calculadas
As colunas calculadas adicionadas a uma tabela DirectQuery que originam seus dados de um banco de dados relacional, como o Microsoft SQL Server, são limitadas a expressões que operam em uma única linha de cada vez. Essas expressões não podem usar funções de iterador DAX, como SUMX, ou funções de modificação de contexto de filtro, como CALCULATE.
Nota
Não é possível adicionar colunas calculadas ou tabelas calculadas que dependem de modelos tabulares encadeados.
Uma expressão de coluna calculada em uma tabela remota do DirectQuery é limitada apenas à avaliação intra-linha. No entanto, você pode criar essa expressão, mas ela resultará em um erro quando ela for usada em um visual. Por exemplo, se você adicionar uma coluna calculada a uma tabela remota do DirectQuery chamada DimProduct usando a expressão [Product Sales] / SUM (DimProduct[ProductSales]), poderá salvar com êxito a expressão no modelo. No entanto, ele resultará em um erro quando for usado em um visual porque viola a restrição de avaliação intra-linha.
Por outro lado, as colunas calculadas adicionadas a uma tabela remota do DirectQuery que é um modelo tabular, que é um modelo semântico do Power BI ou um modelo do Analysis Services, são mais flexíveis. Nesse caso, todas as funções DAX são permitidas porque a expressão será avaliada dentro do modelo tabular de origem.
Muitas expressões exigem que o Power BI materialize a coluna calculada antes de usá-la como um grupo ou filtro, ou agregá-la. Quando uma coluna calculada é materializada em uma tabela grande, pode ser caro em termos de CPU e memória, dependendo da cardinalidade das colunas das quais a coluna calculada depende. Nesse caso, recomendamos que você adicione essas colunas calculadas ao modelo de origem.
Nota
Ao adicionar colunas calculadas a um modelo composto, certifique-se de testar todos os cálculos do modelo. Os cálculos upstream podem não funcionar corretamente porque não consideraram sua influência no contexto do filtro.
Grupos de cálculo
Se existirem grupos de cálculo em um grupo de origem que se conecta a um modelo semântico do Power BI ou a um modelo do Analysis Services, o Power BI poderá retornar resultados inesperados. Para obter mais informações, consulte Grupos de cálculo, consulta e avaliação de medidas.
Design do modelo
Você sempre deve otimizar um modelo do Power BI adotando um design de esquema em estrela.
Gorjeta
Para obter mais informações, consulte Compreender o esquema em estrela e a importância para o Power BI.
Certifique-se de criar tabelas de dimensão separadas das tabelas de fatos para que o Power BI possa interpretar associações corretamente e produzir planos de consulta eficientes. Embora esta orientação seja verdadeira para qualquer modelo do Power BI, é especialmente verdadeira para modelos que você reconhece que se tornarão um grupo de origem de um modelo composto. Permitirá uma integração mais simples e eficiente de outras tabelas em modelos a jusante.
Sempre que possível, evite ter tabelas de dimensão em um grupo de origem que se relacionem a uma tabela de fatos em um grupo de origem diferente. Isso porque é melhor ter relações de grupo intra-fonte do que relações de grupo entre fontes, especialmente para colunas de relacionamento de alta cardinalidade. Conforme descrito anteriormente, as relações de grupo entre fontes dependem de ter valores correspondentes nas colunas de relacionamento, caso contrário, resultados inesperados podem ser mostrados nos visuais de relatório.
Segurança ao nível da linha
Se o seu modelo incluir agregações definidas pelo usuário, colunas calculadas em tabelas de importação ou tabelas calculadas, certifique-se de que qualquer segurança em nível de linha (RLS) esteja configurada corretamente e testada.
Se o modelo composto se conectar a outros modelos tabulares, as regras RLS serão aplicadas apenas no grupo de origem (modelo local) onde estão definidas. Eles não serão aplicados a outros grupos de origem (modelos remotos). Além disso, você não pode definir regras RLS em uma tabela de outro grupo de origem nem pode definir regras RLS em uma tabela local que tenha uma relação com outro grupo de origem.
Design de relatório
Em algumas situações, você pode melhorar o desempenho de um modelo composto criando um layout de relatório otimizado.
Visuais de grupo de origem única
Sempre que possível, crie elementos visuais que usem campos de um único grupo de origem. Isso porque as consultas geradas por elementos visuais terão um desempenho melhor quando o resultado for recuperado de um único grupo de fontes. Considere a criação de dois elementos visuais posicionados lado a lado que recuperam dados de dois grupos de fontes diferentes.
Usar segmentações de dados de sincronização
Em algumas situações, você pode configurar segmentações de dados de sincronização para evitar a criação de uma relação de grupo entre fontes em seu modelo. Ele pode permitir que você combine grupos de código-fonte visualmente que podem ter um melhor desempenho.
Considere um cenário quando seu modelo tiver dois grupos de origem. Cada grupo de origem tem uma tabela de dimensões de produto usada para filtrar revendedores e vendas pela Internet.
Nesse cenário, o grupo de origem A contém a tabela Produto relacionada à tabela ResellerSales . O grupo de origem B contém a tabela Product2 relacionada à tabela InternetSales . Não existem relações de grupo entre fontes.
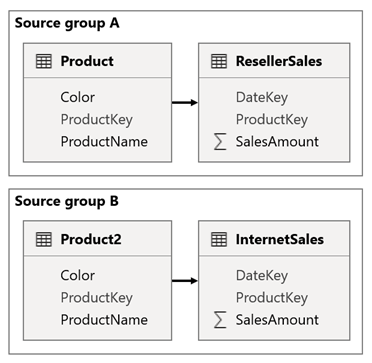
No relatório, você adiciona uma segmentação de dados que filtra a página usando a coluna Cor da tabela Produto. Por padrão, a segmentação de dados filtra a tabela ResellerSales , mas não a tabela InternetSales . Em seguida, adicione uma segmentação de dados oculta usando a coluna Cor da tabela Product2 . Ao definir um nome de grupo idêntico (encontrado nas opções avançadas das segmentações de dados), os filtros aplicados à segmentação de dados visível propagam-se automaticamente para a segmentação de dados oculta.
Nota
Embora o uso de segmentações de dados de sincronização possa evitar a necessidade de criar uma relação de grupo entre fontes, isso aumenta a complexidade do design do modelo. Certifique-se de educar outros usuários sobre por que você projetou o modelo com tabelas de dimensões duplicadas. Evite confusão, ocultando tabelas de dimensão que você não deseja que outros usuários usem. Você também pode adicionar texto de descrição às tabelas ocultas para documentar sua finalidade.
Para obter mais informações, consulte Sincronizar segmentações de dados separadas.
Outras orientações
Aqui estão algumas outras orientações para ajudá-lo a projetar e manter modelos compostos.
- Desempenho e escala: se os relatórios estivessem anteriormente conectados ao vivo a um modelo semântico do Power BI ou a um modelo do Analysis Services, o serviço do Power BI poderia reutilizar caches visuais entre relatórios. Depois de converter a conexão ao vivo para criar um modelo DirectQuery local, os relatórios não se beneficiarão mais desses caches. Como resultado, você pode experimentar um desempenho mais lento ou até mesmo falhas de atualização. Além disso, a carga de trabalho para o serviço do Power BI aumentará, o que pode exigir que você aumente sua capacidade ou distribua a carga de trabalho entre outras capacidades. Para obter mais informações sobre atualização de dados e cache, consulte Atualização de dados no Power BI.
- Renomear: não recomendamos que você renomeie modelos semânticos usados por modelos compostos ou renomeie seus espaços de trabalho. Isso ocorre porque os modelos compostos se conectam aos modelos semânticos do Power BI usando o espaço de trabalho e os nomes dos modelos semânticos (e não seus identificadores exclusivos internos). Renomear um modelo semântico ou espaço de trabalho pode quebrar as conexões usadas pelo seu modelo composto.
- Governança: Não recomendamos que sua versão única do modelo verdade seja um modelo composto. Isso porque ele dependeria de outras fontes de dados ou modelos, que, se atualizados, poderiam resultar na quebra do modelo composto. Em vez disso, recomendamos que você publique um modelo semântico empresarial como a única versão da verdade. Considere este modelo como uma base confiável. Outros modeladores de dados podem criar modelos compostos que estendem o modelo de base para criar modelos especializados.
- Linhagem de dados: use os recursos de análise de impacto de linhagem de dados e modelo semântico antes de publicar alterações de modelo composto. Esses recursos estão disponíveis no serviço do Power BI e podem ajudá-lo a entender como os modelos semânticos são relacionados e usados. É importante entender que você não pode executar análises de impacto em modelos semânticos externos que são exibidos no modo de exibição de linhagem, mas na verdade estão localizados em outro espaço de trabalho. Para executar a análise de impacto em um modelo semântico externo, você precisa navegar até o espaço de trabalho de origem.
- Atualizações de esquema: você deve atualizar seu modelo composto no Power BI Desktop quando forem feitas alterações de esquema em fontes de dados upstream. Em seguida, você precisará publicar novamente o modelo no serviço do Power BI. Certifique-se de testar minuciosamente os cálculos e relatórios dependentes.
Conteúdos relacionados
Para obter mais informações relacionadas a este artigo, consulte os seguintes recursos.
- Utilizar modelos compostos no Power BI Desktop
- Relações de modelo no Power BI Desktop
- Modelos DirectQuery no Power BI Desktop
- Usar o DirectQuery no Power BI Desktop
- Usando o DirectQuery para modelos semânticos do Power BI e o Analysis Services
- Modo de armazenamento no Power BI Desktop
- Agregações definidas pelo usuário
- Perguntas? Tente perguntar à Comunidade do Power BI
- Sugestões? Contribua com ideias para melhorar o Power BI