Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Os valores do cluster criam automaticamente grupos com valores semelhantes usando um algoritmo de correspondência fuzzy e depois mapeiam o valor de cada coluna para o grupo mais correspondido. Esta transformação é útil quando se trabalha com dados que têm muitas variações diferentes do mesmo valor e é necessário combinar valores em grupos consistentes.
Considere uma tabela de exemplo com uma coluna id que contém um conjunto de IDs e uma coluna Person contendo um conjunto de versões soletradas e capitalizadas dos nomes Miguel, Mike, William e Bill.
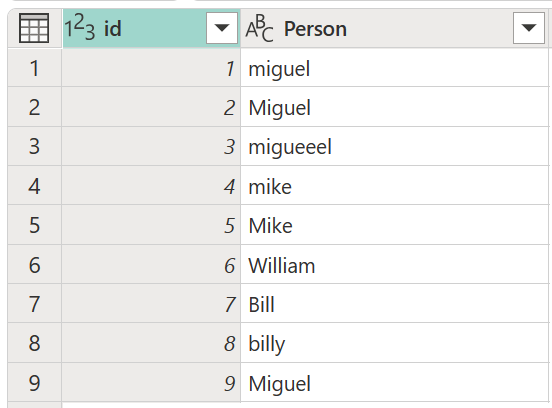
Neste exemplo, o resultado que procuras é uma tabela com uma nova coluna que mostra os grupos certos de valores da coluna Pessoa e não todas as diferentes variações das mesmas palavras.
Observação
A funcionalidade Valores do Cluster está disponível apenas para o Power Query Online.
Criar uma coluna de Cluster
Para agrupar valores, primeiro selecione a coluna Pessoa, vá ao separador Adicionar coluna na faixa de opções e em seguida selecione a opção Agrupar valores.
![]()
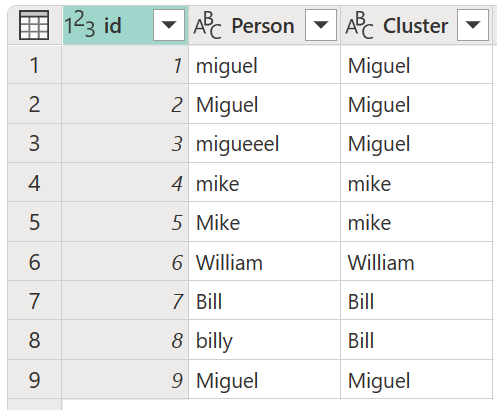
Na caixa de diálogo Valores do Cluster, confirma a coluna que queres usar para criar os clusters e insere o novo nome da coluna. Neste caso, chame a esta nova coluna Cluster.
O resultado dessa operação é mostrado na imagem seguinte.
Observação
Para cada cluster de valores, o Power Query seleciona a instância mais frequente da coluna selecionada como a instância "canónica". Se ocorrerem múltiplas instâncias com a mesma frequência, o Power Query escolhe a primeira.
Utilizar as opções do agrupamento fuzzy
As seguintes opções estão disponíveis para agrupar valores numa nova coluna:
- Limiar de similaridade (opcional): Esta opção indica quão semelhantes dois valores devem ser para serem agrupados. A definição mínima de zero (0) faz com que todos os valores sejam agrupados. A definição máxima de 1 só permite agrupar valores que correspondem exatamente. O padrão é 0,8.
- Ignorar o caso: Quando as cadeias de texto são comparadas, o caso é ignorado. Esta opção está ativada por predefinição.
- Agrupar combinando partes de texto: O algoritmo tenta combinar partes de texto (como combinar Micro e soft na Microsoft) para agrupar valores.
- Mostrar pontuações de similaridade: Mostra pontuações de similaridade entre os valores de entrada e valores representativos calculados após agrupamento fuzzy.
- Tabela de transformações (opcional): Pode selecionar uma tabela de transformações que mapeia valores (como mapear MSFT para Microsoft) para os agrupar.
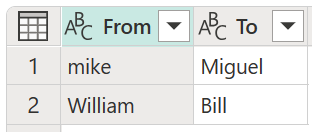
Para este exemplo, uma nova tabela de transformação com o nome My transform table é usada para demonstrar como os valores podem ser mapeados. Esta tabela de transformação tem duas colunas:
- De: A cadeia de texto a procurar na sua tabela.
- Para: A cadeia de texto a usar para substituir a cadeia de texto na coluna From .
Importante
É importante que a tabela de transformação tenha as mesmas colunas e nomes das colunas mostrados na imagem anterior (têm de se chamar "De" e "Para"), caso contrário o Power Query não reconhecerá esta tabela como tabela de transformação e nenhuma transformação ocorrerá.
Usando a consulta criada anteriormente, dê um duplo clique no passo Valores Clusterizados e depois, na caixa de diálogo 'Valores Clusterizados', expanda as opções de Clusterização Fuzzy. Nas opções do cluster Fuzzy, ativa a opção Mostrar pontuações de similaridade . Para a tabela de transformação (opcional), selecione a consulta que contém a tabela de transformação.
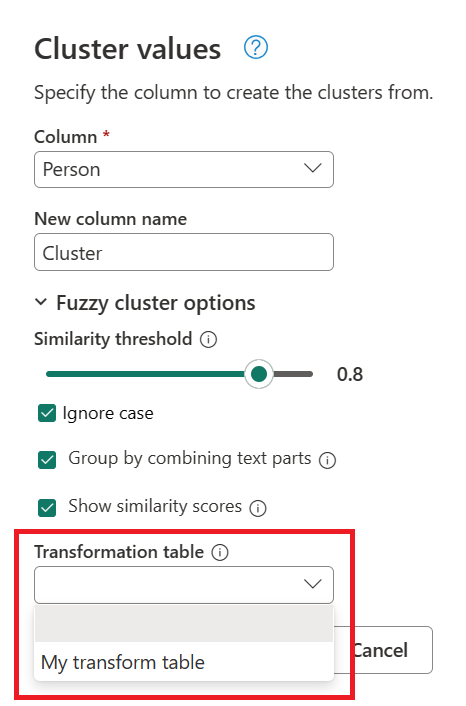
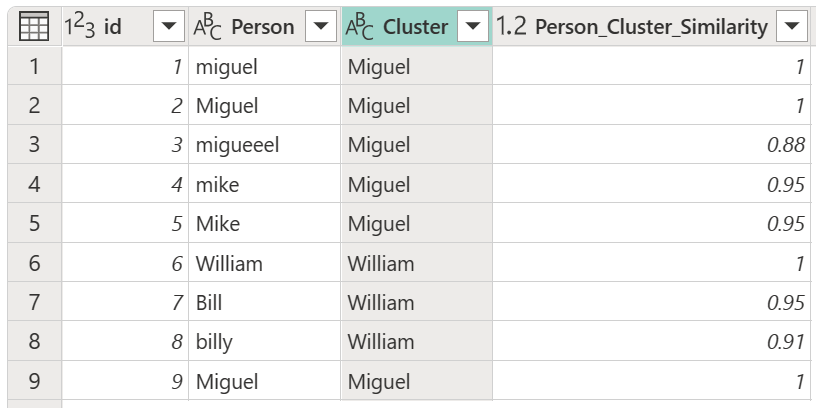
Depois de selecionar a sua tabela de transformações e ativar a opção Mostrar pontuações de similaridade, selecione OK. O resultado dessa operação dá-lhe uma tabela que contém as mesmas colunas id e Person que a tabela original, mas também inclui duas novas colunas chamadas Cluster e Person_Cluster_Similarity. A coluna Cluster contém as versões corretamente escritas e maiúsculas dos nomes Miguel para versões de Miguel e Mike, e William para versões de Bill, Billy e William. A coluna Person_Cluster_Similarity contém as pontuações de similaridade de cada um dos nomes.
Preceitos da tabela de transformação
Podes notar que a tabela de transformações na secção anterior parecia indicar que as instâncias do Mike são alteradas para Miguel e as instâncias do William são alteradas para Bill. No entanto, na tabela resultante, as instâncias de Bill e "billy" foram alteradas para William. Na tabela de transformação, em vez de ser um caminho direto de De para Para , a tabela de transformação é simétrica durante o agrupamento, o que significa que "mike" é equivalente a "Miguel" e vice-versa. O resultado dos equivalentes dados na tabela de transformações depende das seguintes regras:
- Se houver maioria de valores idênticos, estes valores têm prioridade sobre valores não idênticos.
- Se não houver maioria de valores, o valor que aparece primeiro tem prioridade.
Por exemplo, na tabela original usada neste artigo, versões de Miguel (tanto "miguel" como Miguel) na coluna Pessoa constituem a maioria das instâncias dos nomes Miguel e Mike. Além disso, o nome Miguel com maiúsculas iniciais constitui a maior parte do nome Miguel. Assim, associar Miguel e as suas derivadas e Mike e as suas derivadas na tabela de transformadas resulta no uso do nome Miguel na coluna Cluster .
No entanto, para os nomes William, Bill e "billy", não há maioria de valores, pois os três são únicos. Como William aparece primeiro, William é usado na coluna Cluster . Se "billy" tivesse aparecido primeiro na tabela, então "billy" seria usado na coluna Cluster . Além disso, como não há maioria de valores, utiliza-se o caso usado pelos nomes individuais. Ou seja, se William for o primeiro, William com "W" maiúsculo é usado como valor do resultado; Se "billy" for o primeiro, usa-se "billy" com "b" minúsculo.