Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Os recursos do Power Query, como mesclagem difusa, valores de cluster e agrupamento difuso , usam os mesmos mecanismos para funcionar como correspondência difusa.
Este artigo aborda muitos cenários que demonstram como tirar proveito das opções que a correspondência difusa tem, com o objetivo de deixar 'confuso' claro.
Observação
Embora a opção de valores de cluster só esteja disponível no Power Query Online, os mecanismos mostrados nesta seção também se aplicam à mesclagem difusa e ao agrupamento difuso.
Ajustar o limiar de semelhança
O melhor cenário para aplicar o algoritmo de correspondência difusa é quando todas as cadeias de texto em uma coluna contêm apenas as cadeias de caracteres que precisam ser comparadas e nenhum componente extra. Por exemplo, comparar Apples com 4ppl3s produz pontuações de semelhança mais altas do que comparar com ApplesMy favorite fruit, by far, is Apples. I simply love them!.
Como a palavra Apples na segunda cadeia de caracteres é apenas uma pequena parte de toda a cadeia de texto, essa comparação produz uma pontuação de similaridade mais baixa.
Por exemplo, o conjunto de dados a seguir consiste em respostas de uma pesquisa que tinha apenas uma pergunta: "Qual é a sua fruta favorita?"
| Fruta |
|---|
| Mirtilos |
| As bagas azuis são simplesmente as melhores |
| Morangos |
| Morangos = <3 |
| Apples |
| « baços |
| 4PPL3S |
| Bananas |
| fav fruta é bananas |
| Banas |
| Minha fruta favorita, de longe, é a maçã. Eu simplesmente os amo! |
A pesquisa forneceu uma única caixa de texto para inserir o valor e não teve validação.
Agora você tem a tarefa de agrupar os valores. Para realizar essa tarefa, carregue a tabela anterior de frutas no Power Query, selecione a coluna e, em seguida, selecione a opção Valores de cluster no separador Adicionar coluna no friso.
![]()
A caixa de diálogo Valores do cluster é exibida, onde você pode especificar o nome da nova coluna. Nomeie esta nova coluna como Cluster e selecione OK.
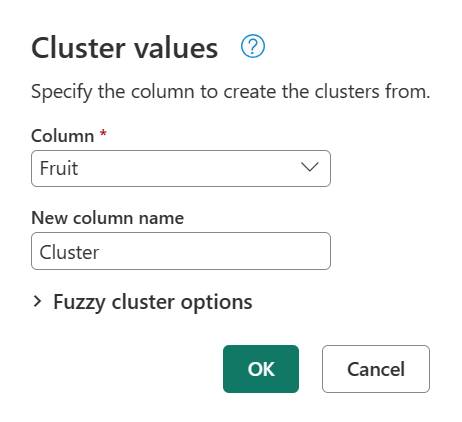
Por predefinição, o Power Query utiliza um limiar de semelhança de 0,8 (ou 80%). O valor mínimo de 0,00 faz com que todos os valores com qualquer nível de semelhança correspondam entre si, e o valor máximo de 1,00 só permite correspondências exatas. Uma "correspondência exata" difusa pode ignorar diferenças como invólucro, ordem das palavras e pontuação. O resultado da operação anterior produz a tabela a seguir com uma nova coluna Cluster .
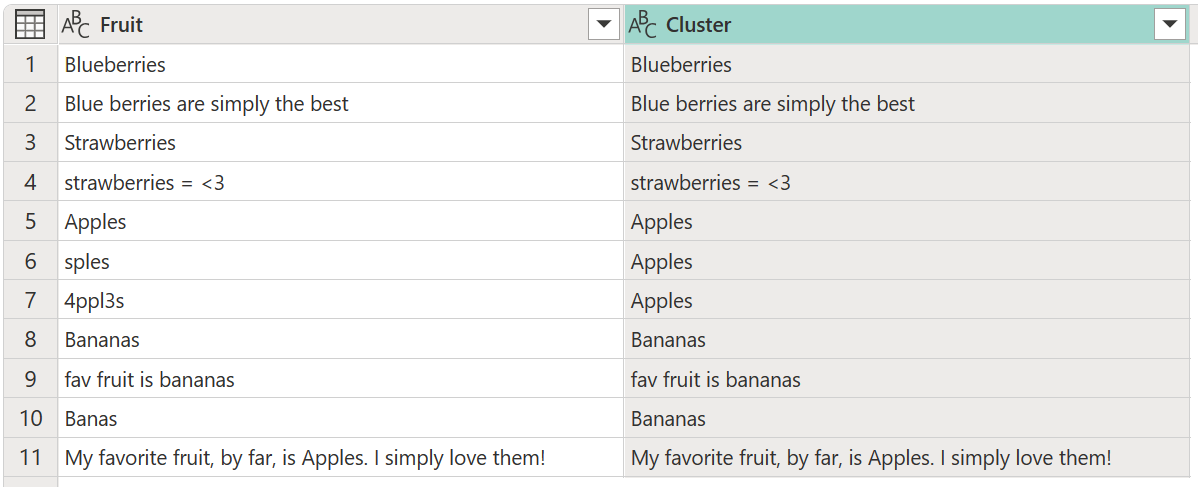
Embora o clustering seja feito, ele não está fornecendo os resultados esperados para todas as linhas. A linha número dois (2) ainda tem o valor Blue berries are simply the best, mas deve ser agrupada em Blueberries, e algo semelhante acontece com as cadeias de Strawberries = <3texto , fav fruit is bananase My favorite fruit, by far, is Apples. I simply love them!.
Para determinar o que está causando esse clustering, clique duas vezes em Valores clusterizados no painel Etapas aplicadas para recuperar a caixa de diálogo Valores de cluster . Dentro desta caixa de diálogo, expanda Opções de cluster difuso. Habilite a opção Mostrar pontuações de semelhança e selecione OK.
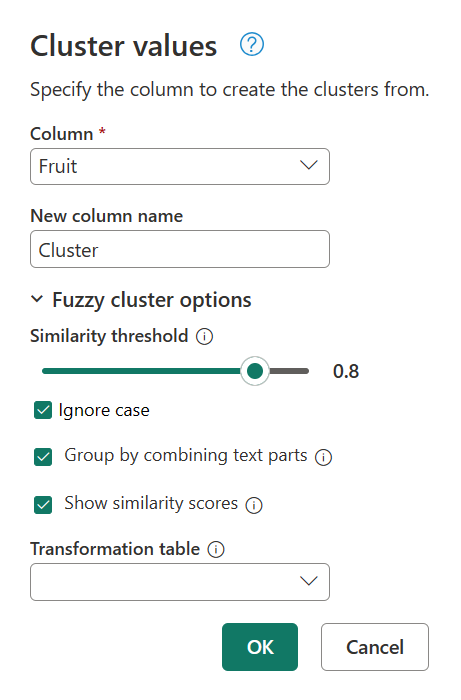
Ativar a opção Mostrar pontuações de semelhança cria uma nova coluna na tabela. Esta coluna mostra a pontuação de semelhança exata entre o cluster definido e o valor original.

Após uma inspeção mais detalhada, o Power Query não conseguiu encontrar outros valores no limiar de semelhança para as cadeias de Blue berries are simply the besttexto ,Strawberries = <3, fav fruit is bananase My favorite fruit, by far, is Apples. I simply love them!.
Volte para a caixa de diálogo Valores de cluster mais uma vez clicando duas vezes em Valores agrupados no painel Etapas aplicadas . Altere o limite de semelhança de 0,8 para 0,6 e, em seguida, selecione OK.
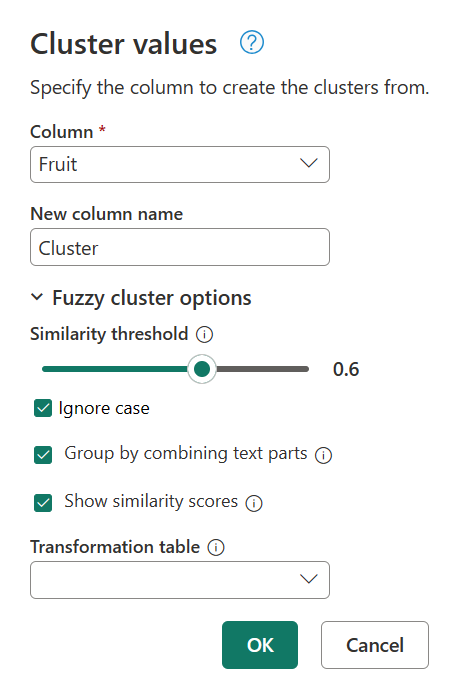
Essa alteração aproxima você do resultado que você está procurando, exceto para a cadeia de caracteres de My favorite fruit, by far, is Apples. I simply love them!texto . Quando alterou o valor do limiar de Semelhança de 0,8 para 0,6, o Power Query podia agora utilizar os valores com uma pontuação de semelhança que começa em 0,6 até 1.

Observação
O Power Query utiliza sempre o valor mais próximo do limiar para definir os clusters. O limite define o limite inferior da pontuação de similaridade aceitável para atribuir o valor a um cluster.
Você pode tentar novamente alterando a pontuação de Similaridade de 0,6 para um número menor até obter os resultados que está procurando. Nesse caso, altere a pontuação de Similaridade para 0,5. Essa alteração produz o resultado exato que você espera com a cadeia de caracteres My favorite fruit, by far, is Apples. I simply love them! de texto agora atribuída ao cluster Apples.

Observação
Atualmente, apenas a funcionalidade Valores de cluster no Power Query Online fornece uma nova coluna com a pontuação de semelhança.
Considerações especiais para a tabela de transformação
A tabela de transformação ajuda a mapear valores da coluna para novos valores antes de executar o algoritmo de correspondência difusa.
Alguns exemplos de como a tabela de transformação pode ser usada:
- Tabela de transformação em valores de cluster
- Tabela de transformação em consultas de mesclagem difusa
- Tabela de transformação em grupo por
Importante
Quando a tabela de transformação é usada, a pontuação máxima de similaridade para os valores da tabela de transformação é 0,95. Esta penalidade deliberada de 0,05 está em vigor para distinguir que o valor original de tal coluna não é igual aos valores com os quais foi comparado desde que ocorreu uma transformação.
Para cenários em que você primeiro deseja mapear seus valores e, em seguida, executar a correspondência difusa sem a penalidade de 0,05, recomendamos que você substitua os valores da sua coluna e, em seguida, execute a correspondência difusa.