Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Você pode migrar seus dados, cargas de trabalho e aplicativos do Azure Data Lake Storage Gen1 para o Azure Data Lake Storage Gen2. Este artigo explica a abordagem de migração recomendada e aborda os diferentes padrões de migração e quando usá-los. Para facilitar a leitura, este artigo usa o termo Gen1 para se referir ao Azure Data Lake Storage Gen1 e o termo Gen2 para se referir ao Azure Data Lake Storage Gen2.
Nota
O Azure Data Lake Storage Gen1 foi desativado. Veja o anúncio da aposentadoria aqui. Os recursos do Data Lake Storage Gen1 não estão mais acessíveis.
O Azure Data Lake Storage Gen2 foi criado no armazenamento de Blobs do Azure e fornece um conjunto de recursos dedicados à análise de big data. O Data Lake Storage Gen2 combina recursos do Azure Data Lake Storage Gen1, como semântica de sistema de arquivos, segurança a nível de diretório e arquivo, e escala com armazenamento hierárquico de baixo custo, junto com capacidades de alta disponibilidade e recuperação de desastres do Azure Blob Storage.
Nota
Como o Gen1 e o Gen2 são serviços diferentes, não há um processo de atualização automática. Para simplificar a migração para o Gen2 usando o portal do Azure, consulte Migrar o Armazenamento do Azure Data Lake do Gen1 para o Gen2 usando o portal do Azure.
Abordagem recomendada
Para migrar de Gen1 para Gen2, recomendamos a seguinte abordagem.
Etapa 1: Avaliar a prontidão
Etapa 2: Preparar para migrar
Etapa 3: Migrar dados e cargas de trabalho de aplicativos
Passo 4: Transição de Gen1 para Gen2
Etapa 1: Avaliar a prontidão
Saiba mais sobre a oferta do Data Lake Storage Gen2, seus benefícios, custos e arquitetura geral.
Compare as capacidades do Gen1 com as do Gen2.
Analise uma lista de problemas conhecidos para avaliar quaisquer lacunas na funcionalidade.
O Gen2 oferece suporte a recursos de armazenamento de Blob, como log de diagnóstico, níveis de acesso e políticas de gerenciamento do ciclo de vida do armazenamento de Blob. Se você estiver interessado em usar qualquer um desses recursos, revise o nível atual de suporte.
Analise o estado atual do suporte ao ecossistema do Azure para garantir que o Gen2 ofereça suporte a quaisquer serviços dos quais suas soluções dependam.
Etapa 2: Preparar para migrar
Identifique os conjuntos de dados que você migrará.
Aproveite esta oportunidade para limpar conjuntos de dados que já não utiliza. A menos que você planeje migrar todos os seus dados de uma só vez, reserve esse tempo para identificar grupos lógicos de dados que você pode migrar em fases.
Realize uma Análise de Envelhecimento (ou similar) na sua conta Gen1 para identificar quais arquivos ou pastas permanecem no inventário por muito tempo ou talvez estejam se tornando obsoletos.
Determine o impacto que uma migração terá no seu negócio.
Por exemplo, considere se você pode arcar com algum tempo de inatividade enquanto a migração ocorre. Essas considerações podem ajudá-lo a identificar um padrão de migração adequado e a escolher as ferramentas mais apropriadas.
Crie um plano de migração.
Recomendamos esses padrões de migração. Você pode escolher um desses padrões, combiná-los ou criar um padrão personalizado próprio.
Etapa 3: Migrar dados, cargas de trabalho e aplicativos
Migre dados, cargas de trabalho e aplicativos usando o padrão de sua preferência. Recomendamos que você valide os cenários incrementalmente.
Crie uma conta de armazenamento e habilite o recurso de namespace hierárquico.
Migre seus dados.
Configure serviços nas suas cargas de trabalho para apontar para o seu ponto de extremidade Gen2.
Para clusters HDInsight, você pode adicionar definições de configuração de conta de armazenamento ao arquivo %HADOOP_HOME%/conf/core-site.xml. Se você planeja migrar tabelas externas do Hive de Gen1 para Gen2, certifique-se de adicionar configurações de conta de armazenamento ao arquivo %HIVE_CONF_DIR%/hive-site.xml também.
Você pode modificar as configurações de cada arquivo usando o Apache Ambari. Para localizar as configurações da conta de armazenamento, consulte Suporte do Hadoop Azure: ABFS — Azure Data Lake Storage Gen2. Este exemplo usa a configuração
fs.azure.account.keypara habilitar a autorização de Chave Compartilhada.<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Para obter links para artigos que ajudam a configurar o HDInsight, o Azure Databricks e outros serviços do Azure para usar o Gen2, consulte Serviços do Azure que dão suporte ao Azure Data Lake Storage Gen2.
Atualize os aplicativos para usar APIs Gen2. Consulte estes guias:
Atualize os scripts para usar cmdlets do PowerShell do Data Lake Storage Gen2 e comandos da CLI do Azure.
Procure referências de URI que contenham a cadeia de caracteres
adl://em arquivos de código ou em notebooks Databricks, arquivos HQL do Apache Hive ou qualquer outro arquivo usado como parte de suas cargas de trabalho. Substitua essas referências pelo URI formatado em Gen2 da sua nova conta de armazenamento. Por exemplo: o URI Gen1:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilepode se tornarabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configure a segurança em sua conta para incluir funções do Azure, segurança em nível de arquivo e pasta e firewalls e redes virtuais do Armazenamento do Azure.
Passo 4: Transição de Gen1 para Gen2
Depois de ter certeza de que seus aplicativos e cargas de trabalho estão estáveis no Gen2, você pode começar a usar o Gen2 para satisfazer seus cenários de negócios. Desative todos os pipelines restantes que estão a ser executados no Gen1 e descomissione a sua conta Gen1.
Capacidades Gen1 vs Gen2
Esta tabela compara as capacidades do Gen1 com as do Gen2.
Padrões Gen1 a Gen2
Escolha um padrão de migração e modifique-o conforme necessário.
| Padrão de migração | Detalhes |
|---|---|
| Elevador e Mudança | O padrão mais simples. Ideal se os seus pipelines de dados puderem suportar algum período de indisponibilidade. |
| Cópia incremental | Semelhante ao lift and shift, mas com menos interrupção. Ideal para grandes quantidades de dados que demoram mais tempo a copiar. |
| Pipeline duplo | Ideal para tubulações que não podem arcar com nenhum tempo de inatividade. |
| Sincronização bidirecional | Semelhante ao gasoduto duplo, mas com uma abordagem mais faseada que é adequada para gasodutos mais complicados. |
Vamos dar uma olhada mais de perto em cada padrão.
Padrão de elevação e mudança
Este é o padrão mais simples.
Interrompa todas as gravações para o Gen1.
Mova dados de Gen1 para Gen2. Recomendamos o Azure Data Factory ou usando o portal do Azure. As ACLs são copiadas juntamente com os dados.
Direcione os processos de ingestão e cargas de trabalho para o Gen2.
Encerrar Gen1.
Confira o nosso código de exemplo para o padrão lift and shift no nosso exemplo de migração lift and shift.
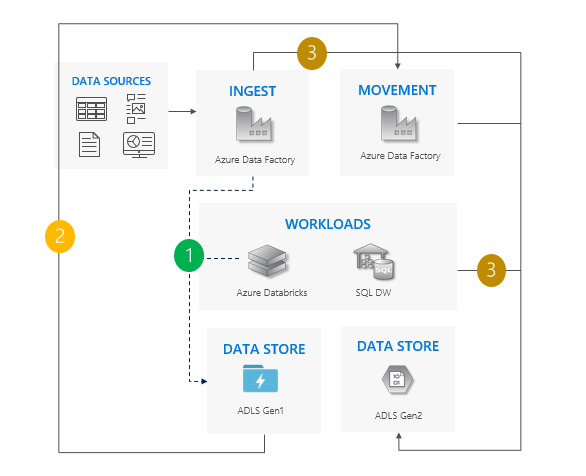
Considerações sobre o uso do padrão de elevação e deslocamento
Transferência de Gen1 para Gen2 para todas as cargas de trabalho ao mesmo tempo.
Espere tempo de inatividade durante a migração e o período de substituição.
Ideal para pipelines que podem suportar tempo de inatividade e todos os aplicativos podem ser atualizados de uma só vez.
Gorjeta
Considere usar o portal do Azure para reduzir o tempo de inatividade e o número de etapas necessárias para concluir a migração.
Padrão de cópia incremental
Comece a mover dados de Gen1 para Gen2. Recomendamos o Azure Data Factory. As ACLs são copiadas juntamente com os dados.
Copie incrementalmente novos dados do Gen1.
Depois que todos os dados forem copiados, pare todas as gravações para Gen1 e aponte cargas de trabalho para Gen2.
Descomissionamento Gen1.
Confira nosso código de exemplo para o padrão de cópia incremental em nosso Exemplo de migração de cópia incremental.
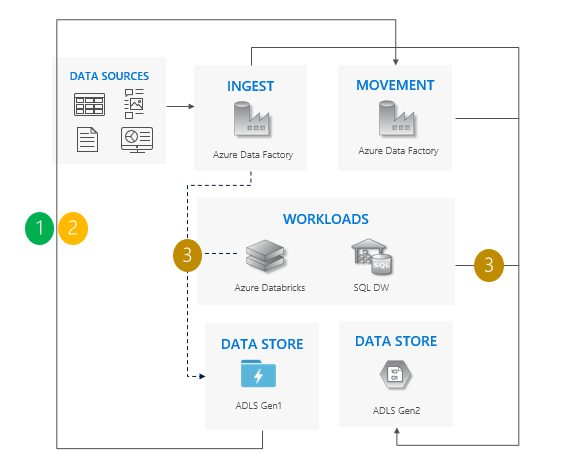
Considerações sobre o uso do padrão de cópia incremental:
Transição de Gen1 para Gen2 para todas as cargas de trabalho simultaneamente.
Espere tempo de inatividade apenas durante o período de transição.
Ideal para pipelines em que todos os aplicativos são atualizados ao mesmo tempo, mas a cópia de dados requer mais tempo.
Padrão de pipeline duplo
Mova dados de Gen1 para Gen2. Recomendamos o Azure Data Factory. As ACLs são copiadas juntamente com os dados.
Ingerir novos dados para Gen1 e Gen2.
Direcione as cargas de trabalho para o Gen2.
Interrompa todas as gravações para Gen1 e, em seguida, descomissione Gen1.
Confira o nosso código de exemplo para o padrão de pipeline duplo no nosso exemplo de migração Dual Pipeline.
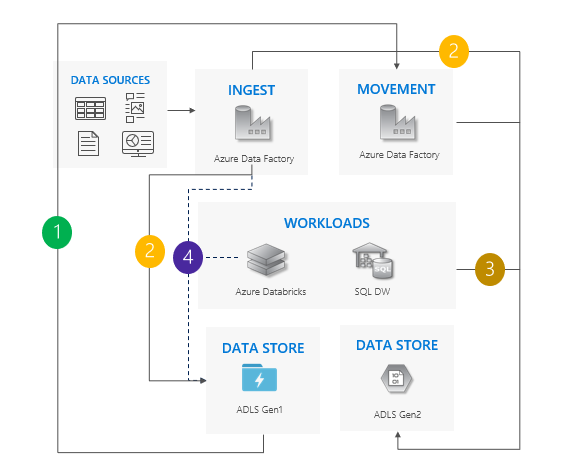
Considerações sobre o uso do padrão de pipeline duplo:
Os oleodutos Gen1 e Gen2 funcionam lado a lado.
Suporta zero tempo de inatividade.
Ideal em situações em que suas cargas de trabalho e aplicativos não podem suportar nenhum tempo de inatividade, e você pode ingerir em ambas as contas de armazenamento.
Padrão de sincronização bidirecional
Configure a replicação bidirecional entre Gen1 e Gen2. Recomendamos o WanDisco. Ele oferece um recurso de reparo para dados existentes.
Quando todas as movimentações estiverem concluídas, interrompa todas as gravações no Gen1 e desative a replicação bidirecional.
Desativação Gen1.
Confira nosso código de exemplo para o padrão de sincronização bidirecional em nosso exemplo de migração de sincronização bidirecional.
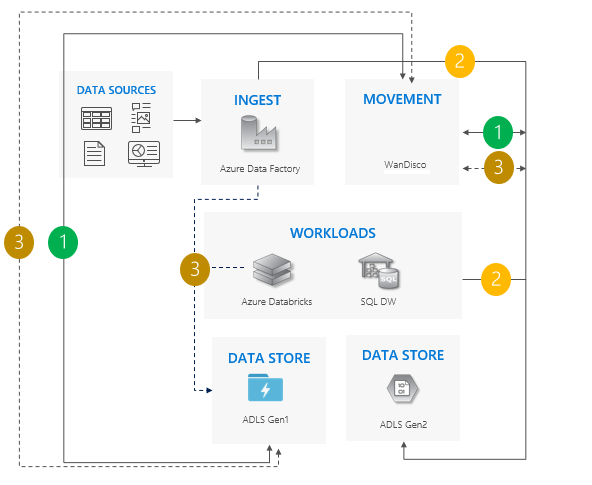
Considerações sobre o uso do padrão de sincronização bidirecional:
Ideal para cenários complexos que envolvem um grande número de pipelines e dependências onde uma abordagem em fases pode fazer mais sentido.
O esforço de migração é alto, mas fornece suporte lado a lado para Gen1 e Gen2.
Próximos passos
- Saiba mais sobre as várias partes da configuração de segurança para uma conta de armazenamento. Para obter mais informações, consulte o guia de segurança do Armazenamento do Azure.
- Otimize o desempenho do seu Repositório Data Lake. Consulte Otimizar o Azure Data Lake Storage Gen2 para desempenho
- Analise as práticas recomendadas para gerenciar seu Repositório Data Lake. Consulte Práticas recomendadas para usar o Azure Data Lake Storage Gen2