Usar o Jupyter Notebooks no Azure Data Studio
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook é uma aplicação web de código aberto que permite criar e compartilhar documentos contendo código ao vivo, equações, visualizações e texto narrativo. O uso inclui limpeza e transformação de dados, simulação numérica, modelagem estatística, visualização de dados e aprendizado de máquina.
Este artigo descreve como criar um novo bloco de anotações na versão mais recente do Azure Data Studio e como começar a criar seus próprios blocos de anotações usando kernels diferentes.
Assista a este pequeno vídeo de 5 minutos para uma introdução aos blocos de anotações no Azure Data Studio:
Criar um bloco de notas
Há várias maneiras de criar um novo bloco de anotações. Em cada caso, um novo arquivo chamado Notebook-1.ipynb é aberto.
Vá para o Menu Arquivo no Azure Data Studio e selecione Novo Bloco de Anotações.
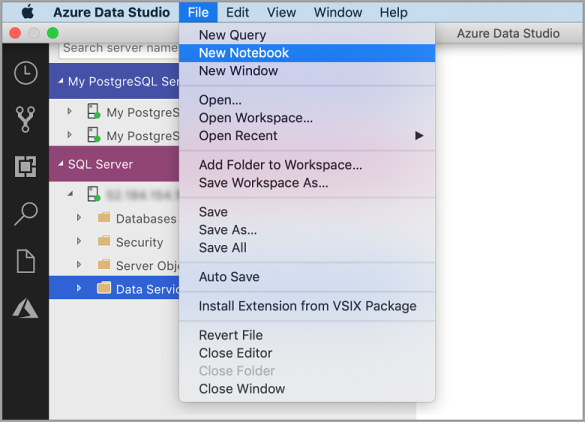
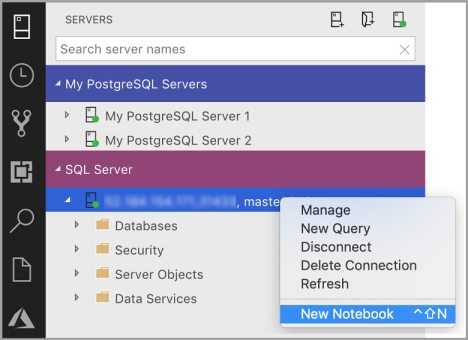
Clique com o botão direito do mouse em uma conexão do SQL Server e selecione Novo Bloco de Anotações.
Abra a paleta de comandos (Ctrl+Shift+P), digite "novo bloco de anotações" e selecione o comando Novo bloco de anotações .

Conectar-se a um kernel
Os blocos de anotações do Azure Data Studio dão suporte a vários kernels diferentes, incluindo SQL Server, Python, PySpark e outros. Cada kernel suporta um idioma diferente nas células de código do seu bloco de anotações. Por exemplo, quando conectado ao kernel do SQL Server, você pode inserir e executar instruções T-SQL em uma célula de código do bloco de anotações.
Anexar a fornece o contexto para o kernel. Por exemplo, se você estiver usando o SQL Kernel, poderá anexar a qualquer uma das suas instâncias do SQL Server. Se você estiver usando o kernel Python3, você anexa ao localhost e pode usar esse kernel para seu desenvolvimento Python local.
O SQL Kernel também pode ser usado para se conectar a instâncias de servidor PostgreSQL. Se você for um desenvolvedor PostgreSQL e quiser conectar os blocos de anotações ao seu Servidor PostgreSQL, baixe a extensão PostgreSQL no Azure Data Studio extension Marketplace e conecte-se ao servidor PostgreSQL.
Se você estiver conectado ao cluster de big data do SQL Server 2019, o padrão Anexar a é o ponto final do cluster. Você pode enviar código Python, Scala e R usando a computação Spark do cluster.
| Kernel | Description |
|---|---|
| SQL Kernel | Escreva código SQL direcionado ao seu banco de dados relacional. |
| Kernel PySpark3 e PySpark | Escreva código Python usando a computação do Spark a partir do cluster. |
| Spark Kernel | Escreva o código Scala e R usando a computação do Spark a partir do cluster. |
| Python Kernel | Escreva código Python para desenvolvimento local. |
Para obter mais informações sobre kernels específicos, consulte:
- Criar e executar um bloco de anotações do SQL Server
- Criar e executar um bloco de anotações Python
- Extensão Kqlmagic no Azure Data Studio - isso estende os recursos do kernel Python
Adicionar uma célula de código
As células de código permitem que você execute o código interativamente dentro do bloco de anotações.
Adicione uma nova célula de código clicando no comando +Célula na barra de ferramentas e selecionando Célula de código. Uma nova célula de código é adicionada após a célula selecionada no momento.
Insira o código na célula para o kernel selecionado. Por exemplo, se você estiver usando o kernel SQL, poderá inserir comandos T-SQL na célula de código.
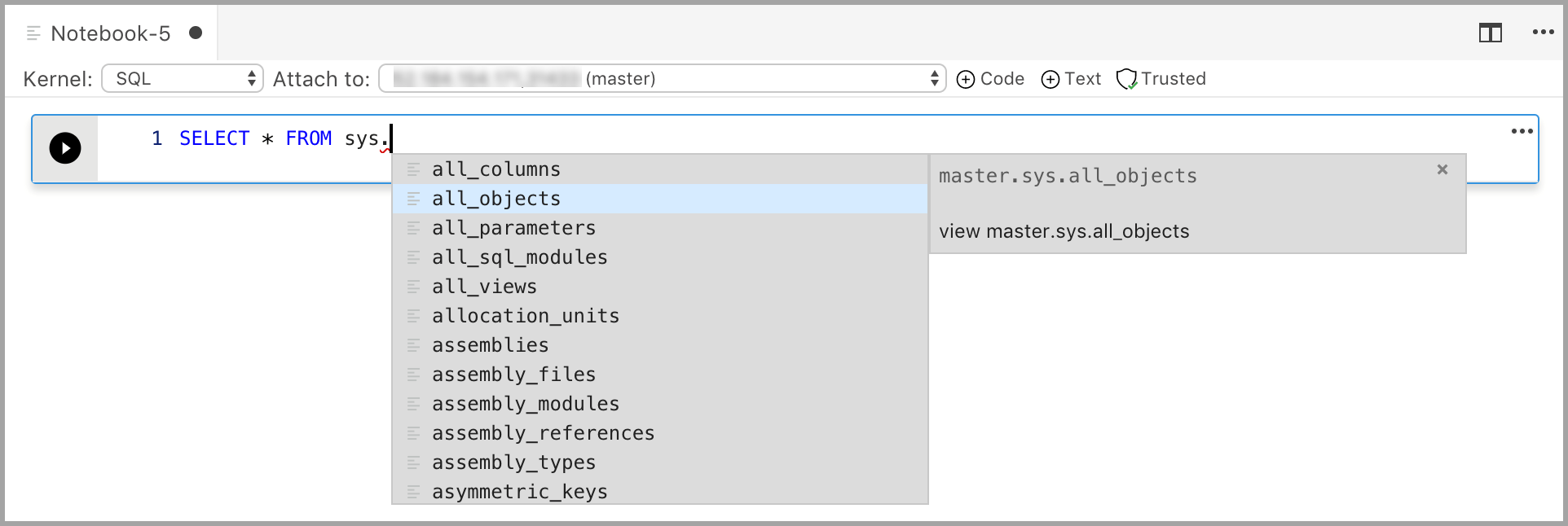
Inserir código com o kernel SQL é semelhante a um editor de consultas SQL. A célula de código oferece suporte a uma experiência moderna de codificação SQL com recursos internos, como um editor SQL avançado, IntelliSense e trechos de código internos. Trechos de código permitem gerar a sintaxe SQL adequada para criar bancos de dados, tabelas, exibições, procedimentos armazenados e atualizar objetos de banco de dados existentes. Use trechos de código para criar rapidamente cópias do seu banco de dados para fins de desenvolvimento ou teste e para gerar e executar scripts.
Adicionar uma célula de texto
As células de texto permitem que você documente seu código adicionando blocos de texto Markdown entre as células de código.
Adicione uma nova célula de texto clicando no comando +Célula na barra de ferramentas e selecionando Célula de texto.
A célula começa no modo de edição no qual você pode digitar texto Markdown. À medida que você digita, uma visualização é mostrada abaixo.
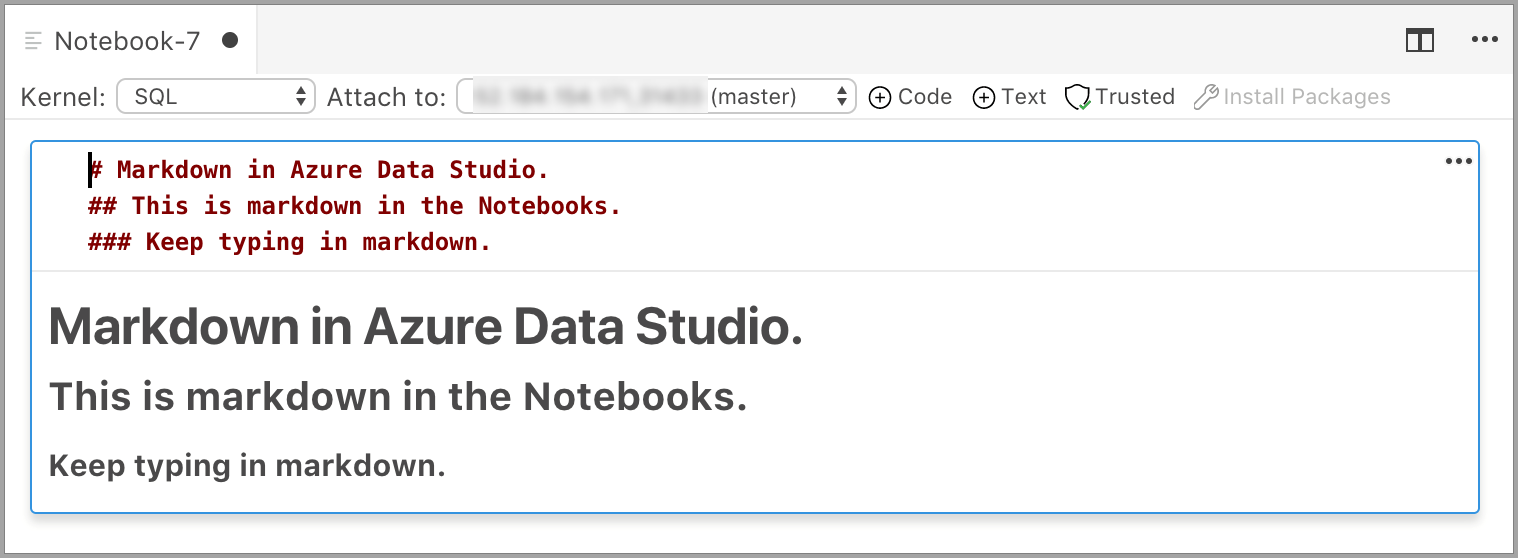
A seleção fora da célula de texto mostra o texto Markdown.
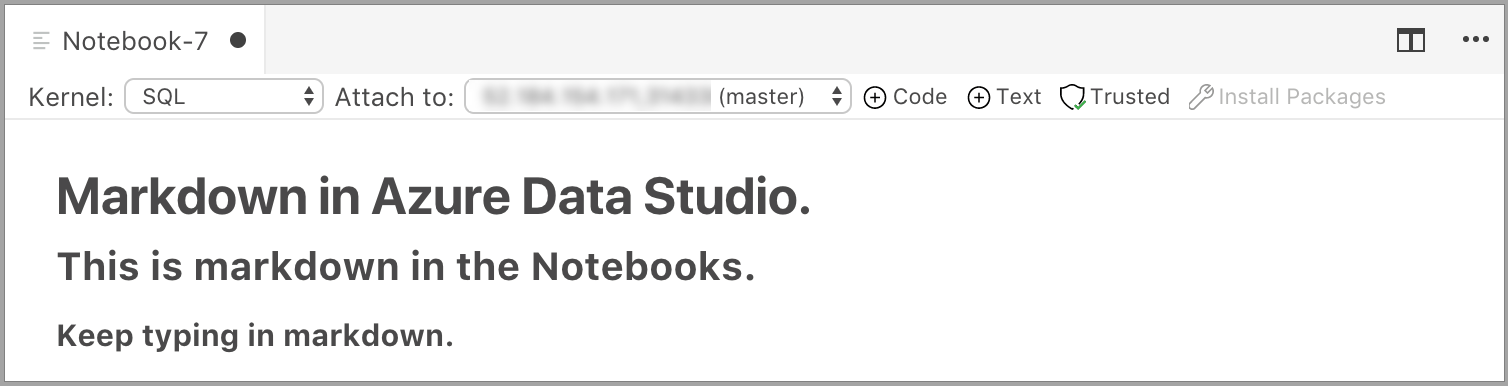
Se você clicar na célula de texto novamente, ele mudará para o modo de edição.
Executar uma célula
Para executar uma única célula, clique em Executar célula (a seta preta redonda) à esquerda da célula ou selecione a célula e pressione F5. Pode executar todas as células do bloco de notas clicando em Executar tudo na barra de ferramentas - as células são executadas uma de cada vez e a execução para se for encontrado um erro numa célula.
Os resultados da célula são mostrados abaixo da célula. Você pode limpar os resultados de todas as células executadas no bloco de anotações selecionando o botão Limpar resultados na barra de ferramentas.
Guardar um bloco de notas
Para salvar um bloco de anotações, siga um destes procedimentos.
- Digite Ctrl+S
- Selecione Salvar no menu Arquivo
- Selecione Salvar como... no menu Arquivo
- Selecione Salvar tudo no menu Arquivo - isso salva todos os blocos de anotações abertos
- Na paleta de comandos, digite Arquivo: Salvar
Os blocos de notas são guardados como .ipynb ficheiros.
Confiável e não confiável
Os blocos de anotações abertos no Azure Data Studio têm como padrão Confiável.
Se você abrir um bloco de anotações de alguma outra fonte, ele será aberto no modo Não Confiável e, em seguida, você poderá torná-lo Confiável.
Exemplos
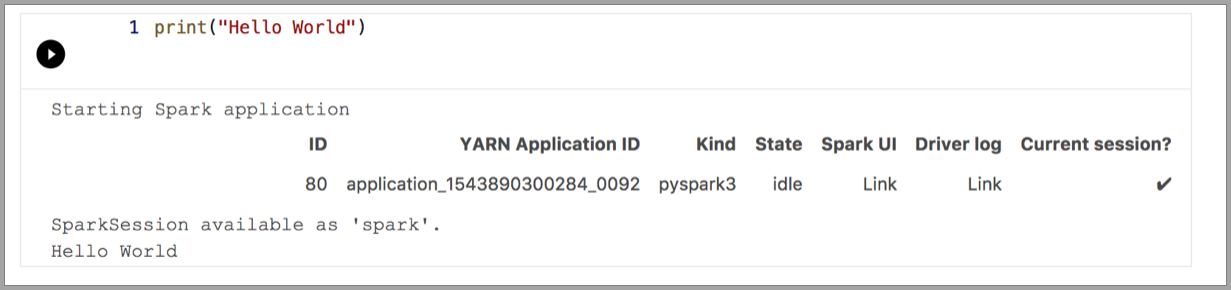
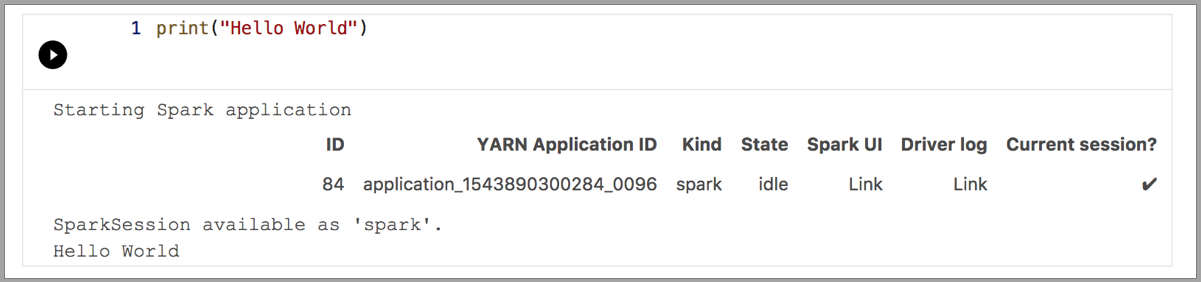
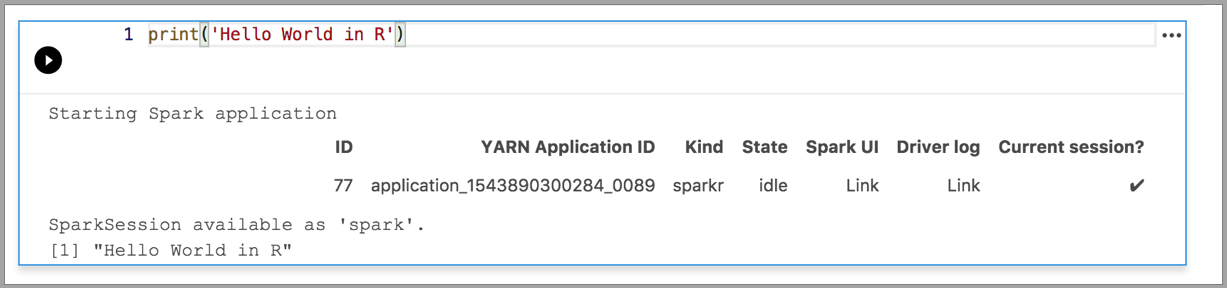
Os exemplos a seguir demonstram o uso de kernels diferentes para executar um comando simples "Hello World". Selecione o kernel, insira o código de exemplo em uma célula e clique em Executar célula.
Pyspark
Faísca | Língua Scala
Faísca | Linguagem R
Python 3

Próximos passos
- Crie e execute um bloco de anotações do SQL Server.
- Criar e executar um bloco de anotações Python
- Execute scripts Python e R em blocos de anotações do Azure Data Studio com os Serviços de Aprendizado de Máquina do SQL Server.
- Implante o cluster de big data do SQL Server com o notebook do Azure Data Studio.
- Gerencie clusters de Big Data do SQL Server com blocos de anotações do Azure Data Studio.
- Execute um bloco de anotações de exemplo usando o Spark.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários