Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
No mínimo, cada base de dados SQL Server tem dois ficheiros do sistema operativo: um ficheiro de dados e um ficheiro de registo. Os ficheiros de dados contêm dados e objetos como tabelas, índices, procedimentos armazenados e vistas. Os ficheiros de registo contêm a informação necessária para recuperar todas as transações na base de dados. Os ficheiros de dados podem ser agrupados em grupos de ficheiros para fins de alocação e administração.
Ficheiros de base de dados
As bases de dados SQL Server têm três tipos de ficheiros, como mostrado na tabela seguinte.
| Ficheiro | Description |
|---|---|
| Primária | Contém informação de arranque da base de dados e aponta para os outros ficheiros da base de dados. Cada base de dados tem um ficheiro de dados primário. A extensão de nome de ficheiro recomendada para ficheiros de dados primários é .mdf. |
| Secundária | Ficheiros de dados definidos pelo utilizador opcionais. Os dados podem ser distribuídos por vários discos colocando cada ficheiro numa unidade de disco diferente. A extensão de nome de ficheiro recomendada para ficheiros de dados secundários é .ndf. |
| Registo de transações | O registo contém informações usadas para recuperar a base de dados. Deve haver pelo menos um arquivo de log para cada banco de dados. A extensão de nome de ficheiro recomendada para registos de transações é .ldf. |
Por exemplo, uma base de dados simples chamada Sales tem um ficheiro primário que contém todos os dados e objetos e um ficheiro de registo que contém a informação do registo de transações. Pode ser criada uma base de dados mais complexa nomeada Orders , que inclui um ficheiro primário e cinco ficheiros secundários. Os dados e objetos dentro da base de dados espalham-se por todos os seis ficheiros, e os quatro ficheiros de registo contêm a informação do registo de transações.
Por defeito, os registos de dados e transações são colocados no mesmo disco e caminho para lidar com sistemas de disco único. Esta escolha pode não ser ideal para ambientes de produção. Recomendamos que coloque dados e ficheiros de registo em discos separados.
Nomes lógicos e físicos de ficheiros
Os ficheiros SQL Server têm dois tipos de nomes de ficheiro:
logical_file_name: O nome usado para se referir ao ficheiro físico em todas as Transact-SQL instruções. O nome lógico do ficheiro deve cumprir as regras para identificadores SQL Server e deve ser único entre os nomes lógicos da base de dados.os_file_name: O nome do ficheiro físico, incluindo o caminho da diretoria. Deve seguir as regras para os nomes dos ficheiros do sistema operativo.
Para mais informações sobre os argumentos NAME e FILENAME, consulte ALTER DATABASE Opções de Ficheiro e Grupo de Ficheiros.
Quando múltiplas instâncias do SQL Server são executadas num único computador, cada instância recebe um diretório predefinido diferente para armazenar os ficheiros das bases de dados criadas na instância. Para mais informações, consulte Localizações de ficheiros para instâncias padrão e nomeadas do SQL Server.
Suporte a sistemas de ficheiros
Os dados e ficheiros de registo do SQL Server podem ser colocados em sistemas de ficheiros FAT ou NTFS. Nos sistemas Windows, a Microsoft recomenda o uso do sistema de ficheiros NTFS devido aos aspetos de segurança do NTFS.
Grupos de ficheiros de dados de leitura/escrita e ficheiros de registo não são suportados num sistema de ficheiros comprimido NTFS. Apenas bases de dados de leitura e grupos de ficheiros secundários só de leitura podem ser colocados num sistema de ficheiros comprimido NTFS. Para poupar espaço, use compressão de dados em vez de compressão do sistema de ficheiros.
Páginas de ficheiros de dados
As páginas num ficheiro de dados SQL Server são numeradas sequencialmente, começando com zero (0) na primeira página do ficheiro. Cada ficheiro numa base de dados tem um número único de ID de ficheiro. Para identificar de forma única uma página numa base de dados, são necessários tanto o ID do ficheiro como o número da página. O exemplo seguinte mostra os números das páginas numa base de dados que possui um ficheiro de dados primário de 4 MB e um ficheiro secundário de 1 MB.
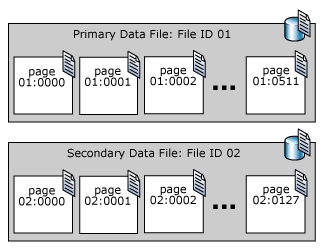
Uma página de cabeçalho de ficheiro é a primeira página que contém informações sobre os atributos do ficheiro. Várias das outras páginas no início do ficheiro também contêm informação do sistema, como mapas de alocação. Uma das páginas do sistema armazenadas tanto no ficheiro de dados primário como no primeiro ficheiro de registo é uma página de arranque da base de dados que contém informações sobre os atributos da base de dados.
Tamanho do ficheiro
Os ficheiros do SQL Server podem crescer automaticamente a partir do tamanho originalmente especificado. Quando defines um ficheiro, podes especificar um incremento de crescimento específico. Cada vez que o ficheiro é preenchido, aumenta o seu tamanho pelo incremento de crescimento. Se houver vários ficheiros num grupo de ficheiros, eles não vão crescer automaticamente até que todos os ficheiros estejam cheios.
Para mais informações sobre páginas e tipos de página, consulte o guia de arquitetura de Páginas e extensões.
Cada ficheiro pode também ter um tamanho máximo especificado. Se não for especificado um tamanho máximo, o ficheiro pode continuar a crescer até esgotar todo o espaço disponível no disco. Esta funcionalidade é especialmente útil quando o SQL Server é usado como base de dados embutida numa aplicação onde o utilizador não tem acesso conveniente a um administrador de sistema. O utilizador pode deixar que os ficheiros cresçam automaticamente conforme necessário para reduzir o encargo administrativo de monitorizar o espaço livre na base de dados e alocar manualmente espaço adicional.
Para mais informações sobre a gestão de ficheiros de registo de transações, consulte Gerir o tamanho do ficheiro de registo de transações.
Ficheiros de snapshot da base de dados
A forma de ficheiro utilizada por uma cópia instantânea de base de dados para armazenar os seus dados de cópia em escrita depende de a cópia instantânea ser criada por um utilizador ou utilizada internamente.
Um snapshot de base de dados criado por um utilizador armazena os seus dados num ou mais ficheiros esparsos. A tecnologia de ficheiros esparsos é uma funcionalidade do sistema de ficheiros NTFS. Inicialmente, um ficheiro esparso não contém dados do utilizador, e o espaço em disco para os dados do utilizador não foi alocado ao ficheiro esparso. Para informações gerais sobre o uso de ficheiros esparsos em snapshots de bases de dados e como os snapshots de base de dados crescem, consulte Ver o Tamanho do Ficheiro Esparso de um Snapshot de Base de Dados.
Instantâneos de bases de dados são utilizados internamente por certos comandos DBCC. Estes comandos incluem
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOC, eDBCC CHECKFILEGROUP. Um instantâneo interno da base de dados utiliza fluxos de dados alternativos esparsos dos ficheiros originais da base de dados. Tal como os ficheiros esparsos, os fluxos de dados alternativos são uma característica do sistema de ficheiros NTFS. A utilização de fluxos de dados alternativos e esparsos permite associar múltiplas alocações de dados a um único ficheiro ou pasta sem afetar o tamanho do ficheiro ou as estatísticas de volume.
Filegroups
- O grupo de ficheiros primário contém o ficheiro de dados primário e quaisquer ficheiros secundários que não estejam inseridos noutros grupos de ficheiros.
- Grupos de ficheiros definidos pelo utilizador podem ser criados para agrupar ficheiros de dados para fins administrativos, de alocação e colocação de dados.
Por exemplo: Data1.ndf, , e Data2.ndf, podem ser criados em três unidades de disco, respetivamente, e atribuídas ao grupo Data3.ndffgroup1de ficheiros . Pode então ser criada uma tabela especificamente no grupo fgroup1de ficheiros . As consultas para os dados da tabela serão distribuídas pelos três discos; Vai melhorar o desempenho. A mesma melhoria de desempenho pode ser alcançada usando um único ficheiro criado num conjunto de stripes RAID (array redundante de discos independentes). No entanto, ficheiros e grupos de ficheiros permitem-te adicionar facilmente novos ficheiros a novos discos.
Todos os ficheiros de dados estão armazenados nos grupos de ficheiros listados na tabela seguinte.
| Filegroup | Description |
|---|---|
| Primária | O grupo de ficheiros que contém o ficheiro primário. Todas as tabelas do sistema fazem parte do grupo de ficheiros primário. |
| Dados Otimizados para Memória | Um grupo de ficheiros otimizado para memória baseia-se no grupo de ficheiros FILESTREAM |
| Filestream | Os dados não estruturados armazenados em diretórios do sistema de ficheiros. |
| Definido pelo utilizador | Qualquer grupo de ficheiros criado pelo utilizador quando este cria ou modifica posteriormente a base de dados. |
Grupo de ficheiros padrão (primário)
Quando os objetos são criados na base de dados sem especificar a que grupo de ficheiros pertencem, são atribuídos ao grupo de ficheiros predefinido. A qualquer momento, exatamente um grupo de ficheiros é designado como o grupo de ficheiros predefinido. Os ficheiros no grupo de ficheiros predefinido devem ser suficientemente grandes para conter quaisquer novos objetos que não sejam alocados a outros grupos de ficheiros.
O PRIMARY grupo de ficheiros é o grupo de ficheiros predefinido, a menos que seja alterado usando a ALTER DATABASE instrução. A alocação para os objetos e tabelas do sistema mantém-se dentro do PRIMARY grupo de ficheiros, não no novo grupo de ficheiros predefinido.
Grupo de ficheiros de dados otimizado para memória
Para mais informações sobre grupos de ficheiros otimizados para memória, veja O grupo de ficheiros otimizado para memória.
Grupo de ficheiros FILESTREAM
Para mais informações sobre grupos de ficheiros FILESTREAM, consulte FILESTREAM e Criar uma Base de Dados FILESTREAM-Enabled.
Exemplo de ficheiros e grupos de ficheiros
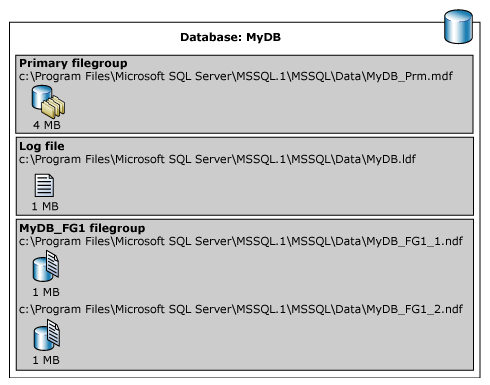
O exemplo seguinte cria uma base de dados numa instância do SQL Server. A base de dados tem um ficheiro de dados primário, um grupo de ficheiros definido pelo utilizador e um ficheiro de registo. O ficheiro de dados primário está no grupo de ficheiros primário e o grupo de ficheiros definido pelo utilizador tem dois ficheiros de dados secundários. Uma ALTER DATABASE instrução torna o grupo de ficheiros definido pelo utilizador como predefinido. É então criada uma tabela que especifica o grupo de ficheiros definido pelo utilizador. (Este exemplo utiliza um caminho C:\Program Files\Microsoft SQL Server\MSSQL.1 genérico para evitar especificar uma versão do SQL Server.)
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
A ilustração seguinte resume os resultados do exemplo anterior (exceto os dados do FILESTREAM).
Estratégia de preenchimento de ficheiros e grupos de ficheiros
Os grupos de ficheiros utilizam uma estratégia de preenchimento proporcional em todos os ficheiros dentro de cada grupo de ficheiros. À medida que os dados são escritos no grupo de ficheiros, o Motor de Base de Dados SQL Server escreve uma quantidade proporcional ao espaço livre no ficheiro para cada ficheiro dentro do grupo, em vez de escrever todos os dados no primeiro ficheiro até estar completo. Depois escreve para o ficheiro seguinte. Por exemplo, se o ficheiro f1 tem 100 MB livres e o ficheiro f2 tem 200 MB livres, uma extensão é dada a partir do ficheiro f1, duas extensões a partir do ficheiro f2, e assim sucessivamente. Desta forma, ambos os ficheiros ficam cheios aproximadamente ao mesmo tempo, e consegue-se uma simples risca.
Por exemplo, um grupo de ficheiros é composto por três ficheiros, todos configurados para crescer automaticamente. Quando o espaço em todos os ficheiros do grupo de ficheiros se esgota, apenas o primeiro ficheiro é expandido. Quando o primeiro ficheiro está cheio e não é possível gravar mais dados no grupo de ficheiros, o segundo ficheiro é expandido. Quando o segundo ficheiro está cheio e não é possível gravar mais dados no grupo de ficheiros, o terceiro ficheiro é expandido. Se o terceiro ficheiro ficar cheio e não puder ser gravados mais dados no grupo de ficheiros, o primeiro ficheiro é expandido novamente, e assim sucessivamente.
Regras para desenhar ficheiros e grupos de ficheiros
As seguintes regras referem-se a ficheiros e grupos de ficheiros:
Um ficheiro ou grupo de ficheiros não pode ser usado por mais do que uma base de dados. Por exemplo, ficheiro
sales.mdfesales.ndf, que contêm dados e objetos da base de dados de vendas, não podem ser usados por nenhuma outra base de dados.Um ficheiro pode ser membro de apenas um grupo de ficheiros.
Os ficheiros de registo de transações nunca fazem parte de nenhum grupo de ficheiros.
Recommendations
Recomendações ao trabalhar com ficheiros e grupos de ficheiros:
A maioria das bases de dados funciona bem com um único ficheiro de dados e um único ficheiro de registo de transações.
Se usares vários ficheiros de dados, cria um segundo grupo de ficheiros para o ficheiro adicional e faz desse grupo o grupo de ficheiros predefinido. Desta forma, o ficheiro primário conterá apenas tabelas e objetos do sistema.
Para maximizar o desempenho, crie ficheiros ou grupos de ficheiros em diferentes discos disponíveis o máximo possível. Coloca objetos que competem fortemente por espaço em diferentes grupos de ficheiros.
Use grupos de ficheiros para permitir a colocação de objetos em discos físicos específicos.
Coloque diferentes tabelas usadas nas mesmas consultas de junção em diferentes grupos de ficheiros. Este passo irá melhorar o desempenho, devido à pesquisa paralela de I/O em disco por dados associados.
Coloque tabelas muito acessadas e os índices não agrupados que pertencem a essas tabelas em diferentes grupos de ficheiros. Usar grupos de ficheiros diferentes melhora o desempenho, devido à E/S paralela se os ficheiros estiverem localizados em discos físicos diferentes.
Não coloque os ficheiros de registo de transações no mesmo disco físico que tem os outros ficheiros e grupos de ficheiros.
Se precisares de estender um volume ou partição onde residem os ficheiros da base de dados usando ferramentas como o diskpart, deves fazer backup de todas as bases de dados do sistema e dos utilizadores e parar os serviços SQL Server primeiro. Além disso, uma vez que os volumes de disco forem estendidos com sucesso, deve considerar executar o comando DBCC CHECKDB para garantir a integridade física de todas as bases de dados que residem no volume.
Para mais informações sobre as recomendações de gestão de ficheiros de registo de transações, consulte Gerir o tamanho do ficheiro de registo de transações.
Conteúdo relacionado
- CREATE DATABASE
- ALTER DATABASE (Transact-SQL) Opções de ficheiros e grupos de ficheiros
- Desanexação e anexação de bases de dados (SQL Server)
- Guia de arquitetura e gerenciamento de log de transações do SQL Server
- Guia de arquitetura de páginas e extensões
- Manage the size of the transaction log file (Gerir o tamanho do ficheiro de registo de transações)