Usar um arquivo de formato para ignorar uma coluna de tabela (SQL Server)
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() PDW (Analytics Platform System)
PDW (Analytics Platform System)
Este artigo descreve como usar um arquivo de formato para ignorar a importação de uma coluna de tabela quando os dados da coluna ignorada não existem no arquivo de dados de origem. Um arquivo de dados pode conter menos campos do que o número de colunas na tabela de destino, ou seja, será possível ignorar a importação de uma coluna apenas se pelo menos uma das seguintes condições for verdadeira na tabela de destino:
- A coluna ignorada permite valor nulo.
- A coluna ignorada tem um valor padrão.
Observação
Essa sintaxe, incluindo inserção em massa, não tem suporte no Azure Synapse Analytics. No Azure Synapse Analytics e em outras integrações de plataforma de banco de dados de nuvem, efetue a movimentação de dados por meio da instrução COPY no Azure Data Factory ou usando instruções T-SQL, como COPY INTO e PolyBase.
Tabela e arquivo de dados de exemplo
Os exemplos neste artigo esperam uma tabela chamada myTestSkipCol no esquema dbo. É possível criar esta tabela em um banco de dados de exemplo como WideWorldImporters ou AdventureWorks ou em qualquer outro banco de dados. Crie essa tabela como se segue:
USE WideWorldImporters;
GO
CREATE TABLE myTestSkipCol
(
Col1 smallint,
Col2 nvarchar(50) NULL,
Col3 nvarchar(50) not NULL
);
GO
Os exemplos neste artigo também usam um arquivo de dados de exemplo, myTestSkipCol2.dat. Este arquivo de dados contém apenas dois campos, embora a tabela de destino contenha três colunas.
1,DataForColumn3
1,DataForColumn3
1,DataForColumn3
Etapas básicas
É possível usar um arquivo de formato não XML ou um arquivo de formato XML para ignorar uma coluna de tabela. Em ambos os casos, há duas etapas:
- Use o utilitário de linha de comando bcp para criar um arquivo de formato padrão.
- Modifique o arquivo de formato padrão em um editor de texto.
O arquivo de formato modificado deve mapear cada campo existente para sua coluna correspondente na tabela de destino. Ele também deve indicar qual coluna ou colunas da tabela a serem ignoradas.
Por exemplo, para importar dados em massa do myTestSkipCol2.dat para a tabela myTestSkipCol, o arquivo de formato deve mapear o primeiro campo de dados para Col1, ignorar Col2 e mapear o segundo campo para Col3.
Opção nº 1 – Usar um arquivo de formato não XML
Etapa Nº 1 – Criar um arquivo de formato não XML padrão
Crie um arquivo de formato não XML padrão para a tabela de exemplo myTestSkipCol executando o seguinte comando bcp no prompt de comando:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.fmt -c -T
Importante
Talvez seja necessário especificar o nome da instância do servidor à qual você está se conectando com o argumento -S. Além disso, talvez seja necessário especificar o nome de usuário e a senha com os argumentos -U e -P. Para obter mais informações, consulte bcp Utility.
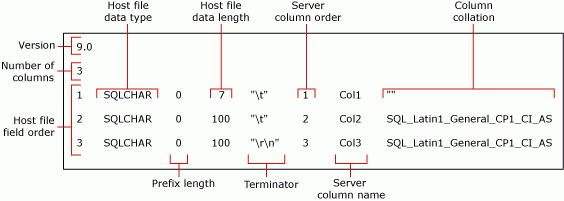
O comando anterior cria um arquivo de formato não XML, myTestSkipCol_Default.fmt. Esse arquivo de formato é denominado arquivo de formato padrão , pois esse é o formato gerado pelo bcp. Um arquivo de formato padrão descreve uma correspondência um para um entre campos de arquivo de dados e colunas de tabela.
A captura de tela a seguir exibe os valores nesses exemplos de arquivos de formato padrão.
Observação
Para obter mais informações sobre os campos de arquivo de formato, confira Arquivos de formato não XML (SQL Server).
Etapa nº 2 – Modificar um arquivo de formato não XML
Para modificar um arquivo de formato não XML padrão, há duas alternativas. Ambas indicam que o campo de dados não existe no arquivo de dados e que nenhum dado deve ser inserido na coluna de tabela correspondente.
Para ignorar uma coluna de tabela, edite o arquivo de formato não XML padrão e modifique o arquivo, recorrendo a um dos seguintes métodos alternativos:
Opção Nº 1 – Remover a linha
O método preferencial para ignorar uma coluna envolve as três etapas a seguir:
- Primeiro, exclua qualquer linha do arquivo de formato que descreva um campo ausente do arquivo de dados de origem.
- Então, reduza o valor da "Ordem do campo de arquivo host" de cada linha do arquivo de formato que segue uma linha excluída. A meta são valores sequenciais "Ordem do campo de arquivo host", de 1 a nque reflitam a posição atual de cada campo de dados no arquivo de dados.
- Finalmente, reduza o valor no campo "Número de colunas" para refletir o número real de campos no arquivo de dados.
O exemplo a seguir é baseado no arquivo de formato padrão da tabela myTestSkipCol. Este arquivo de formato modificado mapeia o primeiro campo de dados para a Col1, ignora a Col2e mapeia o segundo campo de dados para a Col3. A linha da Col2 foi excluída. O delimitador após o primeiro campo também foi alterado de \t para ,.
14.0
2
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Opção Nº 2 – Modificar a definição de linha
Como alternativa para ignorar uma coluna de tabela, é possível modificar a definição da linha do arquivo de formato que corresponde à coluna de tabela. Nessa linha do arquivo de formato, os valores "comprimento do prefixo", "comprimento dos dados do arquivo host" e "ordem da coluna do servidor" devem ser definidos como 0. Além disso, os campos "ordenação de colunas" e "terminador" devem ser definidos como "" (ou seja, um valor NULO ou vazio). O valor "nome da coluna de servidor" requer uma cadeia de caracteres não vazia, embora o nome real da coluna não seja necessário. Os campos de formato restantes requerem seus valores padrão.
O exemplo a seguir também é derivado do arquivo de formato padrão da tabela myTestSkipCol .
14.0
3
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 0 "" 0 Col2 ""
3 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Exemplos com um arquivo de formato não XML
Os exemplos a seguir são baseados na tabela de exemplo myTestSkipCol e no arquivo de dados de exemplo myTestSkipCol2.dat descritos anteriormente neste artigo.
Usar BULK INSERT
Este exemplo funciona usando os arquivos de formato não XML modificados criados conforme descrito na seção anterior. Nesse exemplo, o nome do arquivo de formato modificado é myTestSkipCol2.fmt. Para usar o BULK INSERT para importar o arquivo de dados myTestSkipCol2.dat em massa, no SSMS (SQL Server Management Studio), execute o seguinte código. Atualize os caminhos do sistema de arquivos do local dos arquivos de exemplo em seu computador.
USE WideWorldImporters;
GO
BULK INSERT myTestSkipCol
FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.fmt');
GO
SELECT * FROM myTestSkipCol;
GO
Opção nº 2 – Usar um arquivo de formato XML
Etapa 1: criar um arquivo de formato XML padrão
Crie um arquivo de formato XML padrão para a tabela de exemplo myTestSkipCol executando o seguinte comando bcp no prompt de comando:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.xml -c -x -T
Importante
Talvez seja necessário especificar o nome da instância do servidor à qual você está se conectando com o argumento -S. Além disso, talvez seja necessário especificar o nome de usuário e a senha com os argumentos -U e -P. Para obter mais informações, consulte bcp Utility.
O comando anterior cria um arquivo de formato XML, myTestSkipCol_Default.xml. Esse arquivo de formato é denominado arquivo de formato padrão , pois esse é o formato gerado pelo bcp. Um arquivo de formato padrão descreve uma correspondência um para um entre campos de arquivo de dados e colunas de tabela.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="7"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="2" NAME="Col2" xsi:type="SQLNVARCHAR"/>
<COLUMN SOURCE="3" NAME="Col3" xsi:type="SQLNVARCHAR"/>
</ROW>
</BCPFORMAT>
Observação
Para obter informações sobre a estrutura dos arquivos de formato XML, confira Arquivos de formato XML (SQL Server).
Etapa nº 2 – Modificar um arquivo de formato XML
Aqui está o arquivo de formato XML modificado, myTestSkipCol2.xml, que ignora Col2. As entradas FIELD e ROW para Col2 foram removidas e as entradas foram numeradas novamente. O delimitador após o primeiro campo também foi alterado de \t para ,.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="7"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="2" NAME="Col3" xsi:type="SQLNVARCHAR"/>
</ROW>
</BCPFORMAT>
Exemplos com um arquivo de formato XML
Os exemplos a seguir são baseados na tabela de exemplo myTestSkipCol e no arquivo de dados de exemplo myTestSkipCol2.dat descritos anteriormente neste artigo.
Para importar os dados de myTestSkipCol2.dat para a tabela myTestSkipCol , os exemplos usam o arquivo de formato XML modificado, myTestSkipCol2.xml.
Usar BULK INSERT com uma exibição
Com um arquivo de formato XML, não é possível ignorar uma coluna durante a importação direta para uma tabela usando um comando bcp ou uma instrução BULK INSERT. No entanto, é possível realizar a importação para todas as colunas de uma tabela, exceto para a última. Se for preciso ignorar alguma coluna que não seja a última, crie uma exibição da tabela de destino que contenha apenas as colunas contidas no arquivo de dados. Depois, importe em massa os dados desse arquivo para a exibição.
O exemplo a seguir cria a exibição v_myTestSkipCol na tabela myTestSkipCol . Essa exibição ignora a segunda coluna da tabela, Col2. O exemplo usa o BULK INSERT para importar o arquivo de dados myTestSkipCol2.dat para essa exibição.
No SSMS, execute o seguinte código. Atualize os caminhos do sistema de arquivos do local dos arquivos de exemplo em seu computador.
USE WideWorldImporters;
GO
CREATE VIEW v_myTestSkipCol AS
SELECT Col1,Col3
FROM myTestSkipCol;
GO
BULK INSERT v_myTestSkipCol
FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE='C:\myTestSkipCol2.xml');
GO
Usar OPENROWSET(BULK...)
Para usar um arquivo de formato XML para ignorar uma coluna de tabela usando OPENROWSET(BULK...), é necessário fornecer uma lista de colunas explícita na lista de seleção e também na tabela de destino, como segue:
INSERT ...<column_list> SELECT <column_list> FROM OPENROWSET(BULK...)
O exemplo a seguir usa o provedor de conjunto de linhas em massa OPENROWSET e o arquivo de formato myTestSkipCol2.xml . O exemplo importa em massa o arquivo de dados myTestSkipCol2.dat para a tabela myTestSkipCol . A instrução contém uma lista explícita de colunas na lista de seleção e também na tabela de destino, como exigido.
No SSMS, execute o seguinte código. Atualize os caminhos do sistema de arquivos do local dos arquivos de exemplo em seu computador.
USE WideWorldImporters;
GO
INSERT INTO myTestSkipCol
(Col1,Col3)
SELECT Col1,Col3
FROM OPENROWSET(BULK 'C:\myTestSkipCol2.Dat',
FORMATFILE='C:\myTestSkipCol2.Xml'
) as t1 ;
GO
Próximas etapas
- Utilitário bcp
- BULK INSERT (Transact-SQL)
- OPENROWSET (Transact-SQL)
- Usar um arquivo de formato para ignorar um campo de dados (SQL Server)
- Usar um arquivo de formato para mapear colunas de tabela para campos de arquivo de dados (SQL Server)
- Usar um arquivo de formato para importação em massa de dados (SQL Server)
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários