Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Versão original do produto: SQL Server
Número original do KB: 243589
Introdução
Este artigo descreve como lidar com um problema de desempenho que os aplicativos de banco de dados podem enfrentar ao usar o SQL Server: desempenho lento de uma consulta ou grupo específico de consultas. A metodologia a seguir ajudará você a restringir a causa do problema de consultas lentas e direcioná-lo para a resolução.
Localizar consultas lentas
Para estabelecer que você tem problemas de desempenho de consulta em sua instância do SQL Server, comece examinando as consultas pelo tempo de execução (tempo decorrido). Verifique se o tempo excede um limite definido (em milissegundos) com base em uma linha de base de desempenho estabelecida. Por exemplo, em um ambiente de teste de estresse, você pode ter estabelecido um limite para que sua carga de trabalho não seja superior a 300 ms e pode usar esse limite. Em seguida, você pode identificar todas as consultas que excedem esse limite, concentrando-se em cada consulta individual e sua duração de linha de base de desempenho preestabelecida. Em última análise, os usuários corporativos se preocupam com a duração geral das consultas ao banco de dados; portanto, o foco principal está na duração da execução. Outras métricas, como tempo de CPU e leituras lógicas, são coletadas para ajudar a restringir a investigação.
Para instruções em execução no momento, verifique total_elapsed_time e cpu_time colunas em sys.dm_exec_requests. Execute a seguinte consulta para obter os dados:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Para execuções anteriores da consulta, verifique last_elapsed_time e last_worker_time colunas em sys.dm_exec_query_stats. Execute a seguinte consulta para obter os dados:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCObservação
Se
avg_wait_timemostrar um valor negativo, será uma consulta paralela.Se você puder executar a consulta sob demanda no SQL Server Management Studio (SSMS) ou no Azure Data Studio, execute-a com SET STATISTICS TIME
ONe SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFEm seguida, em Mensagens, você verá o tempo de CPU, o tempo decorrido e as leituras lógicas como esta:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Se você puder coletar um plano de consulta, verifique os dados nas propriedades do plano de execução.
Execute a consulta com Incluir Plano de Execução Real ativado.
Selecione o operador mais à esquerda em Plano de execução.
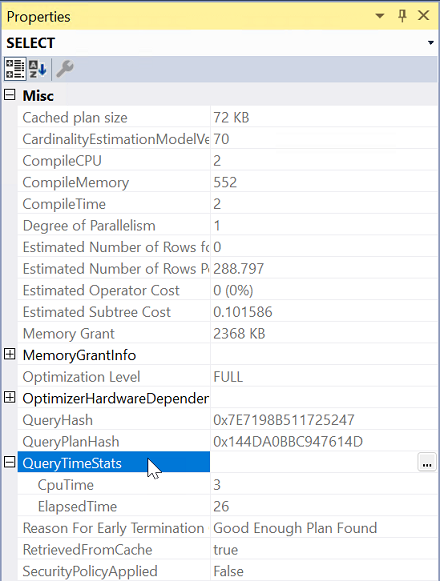
Em Propriedades, expanda a propriedade QueryTimeStats .
Verifique ElapsedTime e CpuTime.
Execução vs. espera: por que as consultas são lentas?
Se você encontrar consultas que excedam seu limite predefinido, examine por que elas podem ser lentas. A causa dos problemas de desempenho pode ser agrupada em duas categorias, em execução ou aguardando:
AGUARDANDO: As consultas podem ser lentas porque estão aguardando um gargalo por um longo tempo. Veja uma lista detalhada de gargalos nos tipos de esperas.
RUNNING: as consultas podem ser lentas porque estão em execução (executando) por um longo tempo. Em outras palavras, essas consultas estão usando ativamente recursos da CPU.
Uma consulta pode ficar em execução por algum tempo e em espera por algum tempo em seu tempo de vida (duração). No entanto, seu foco é determinar qual é a categoria dominante que contribui para seu longo tempo decorrido. Portanto, a primeira tarefa é estabelecer em qual categoria as consultas se enquadram. É simples: se uma consulta não estiver em execução, ela estará esperando. Idealmente, uma consulta gasta a maior parte do tempo decorrido em um estado de execução e muito pouco tempo aguardando recursos. Além disso, na melhor das hipóteses, uma consulta é executada dentro ou abaixo de uma linha de base predeterminada. Compare o tempo decorrido e o tempo de CPU da consulta para determinar o tipo de problema.
Tipo 1: vinculado à CPU (runner)
Se o tempo de CPU for próximo, igual ou maior que o tempo decorrido, você poderá tratá-lo como uma consulta associada à CPU. Por exemplo, se o tempo decorrido for de 3000 milissegundos (ms) e o tempo de CPU for de 2900 ms, isso significa que a maior parte do tempo decorrido será gasto na CPU. Então podemos dizer que é uma consulta vinculada à CPU.
Exemplos de consultas em execução (associadas à CPU):
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
As leituras lógicas - leitura de páginas de dados/índice no cache - são mais freqüentemente os impulsionadores da utilização da CPU no SQL Server. Pode haver cenários em que o uso da CPU vem de outras fontes: um loop while (em T-SQL ou outro código como objetos XProcs ou SQL CRL). O segundo exemplo na tabela ilustra esse cenário, em que a maioria da CPU não é de leituras.
Observação
Se o tempo da CPU for maior que a duração, isso indica que uma consulta paralela foi executada; vários threads estão usando a CPU ao mesmo tempo. Para obter mais informações, consulte Consultas paralelas - executor ou garçom.
Tipo 2: Esperando por um gargalo (garçom)
Uma consulta está aguardando um afunilamento se o tempo decorrido for significativamente maior que o tempo de CPU. O tempo decorrido inclui o tempo de execução da consulta na CPU (tempo de CPU) e o tempo de espera para que um recurso seja liberado (tempo de espera). Por exemplo, se o tempo decorrido for de 2000 ms e o tempo de CPU for de 300 ms, o tempo de espera será de 1700 ms (2000 - 300 = 1700). Para obter mais informações, consulte Tipos de esperas.
Exemplos de consultas em espera:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Consultas paralelas - executor ou garçom
As consultas paralelas podem usar mais tempo de CPU do que a duração geral. O objetivo do paralelismo é permitir que vários threads executem partes de uma consulta simultaneamente. Em um segundo de tempo de clock, uma consulta pode usar oito segundos de tempo de CPU executando oito threads paralelos. Portanto, torna-se um desafio determinar uma consulta associada à CPU ou em espera com base no tempo decorrido e na diferença de tempo da CPU. No entanto, como regra geral, siga os princípios listados nas duas seções acima. O resumo é:
- Se o tempo decorrido for muito maior que o tempo da CPU, considere-o um garçom.
- Se o tempo da CPU for muito maior do que o tempo decorrido, considere-o um executor.
Exemplos de consultas paralelas:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1.500.000 |
Representação visual de alto nível da metodologia

Diagnosticar e resolver consultas em espera
Se você estabeleceu que suas consultas de interesse são garçons, seu próximo passo é se concentrar na resolução de problemas de gargalo. Caso contrário, vá para a etapa 4: Diagnosticar e resolver consultas em execução.
Para otimizar uma consulta que está aguardando gargalos, identifique quanto tempo é a espera e onde está o gargalo (o tipo de espera). Assim que o tipo de espera for confirmado, reduza o tempo de espera ou elimine completamente a espera.
Para calcular o tempo de espera aproximado, subtraia o tempo de CPU (tempo de trabalho) do tempo decorrido de uma consulta. Normalmente, o tempo de CPU é o tempo de execução real e a parte restante do tempo de vida da consulta está aguardando.
Exemplos de como calcular a duração aproximada da espera:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Tempo de espera (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identifique o gargalo ou aguarde
Para identificar consultas históricas de longa espera (por exemplo, >20% do tempo total decorrido é tempo de espera), execute a consulta a seguir. Essa consulta usa estatísticas de desempenho para planos de consulta armazenados em cache desde o início do SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPara identificar consultas em execução no momento com esperas superiores a 500 ms, execute a seguinte consulta:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Se você puder coletar um plano de consulta, verifique os WaitStats nas propriedades do plano de execução no SSMS:
- Execute a consulta com Incluir Plano de Execução Real ativado.
- Clique com o botão direito do mouse no operador mais à esquerda na guia Plano de execução
- Selecione Propriedades e, em seguida, a propriedade WaitStats .
- Verifique os WaitTimeMs e WaitType.
Se você estiver familiarizado com os cenários PSSDiag/SQLdiag ou SQL LogScout LightPerf/GeneralPerf, considere usar qualquer um deles para coletar estatísticas de desempenho e identificar consultas em espera em sua instância do SQL Server. Você pode importar os arquivos de dados coletados e analisar os dados de desempenho com o SQL Nexus.
Referências para ajudar a eliminar ou reduzir esperas
As causas e resoluções para cada tipo de espera variam. Não há um método geral para resolver todos os tipos de espera. Aqui estão os artigos para solucionar problemas comuns de tipo de espera:
- Entender e resolver problemas de bloqueio (LCK_M_*)
- Entender e resolver problemas de bloqueio do Banco de Dados SQL do Azure
- Solucionar problemas de desempenho lento do SQL Server causados por problemas de E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Resolva a contenção de PAGELATCH_EX de inserção da última página no SQL Server
- A memória concede explicações e soluções (RESOURCE_SEMAPHORE)
- Solucionar problemas de consultas lentas resultantes de ASYNC_NETWORK_IO tipo de espera
- Solução de problemas do tipo de espera de alta HADR_SYNC_COMMIT com Grupos de Disponibilidade Always On
- Como funciona: CMEMTHREAD e depurando-os
- Tornando as esperas de paralelismo acionáveis (CXPACKET e CXCONSUMER)
- Espera do THREADPOOL
Para obter descrições de muitos tipos de espera e o que eles indicam, consulte a tabela em Tipos de esperas.
Diagnosticar e resolver consultas em execução
Se o tempo da CPU (trabalho) estiver muito próximo da duração geral decorrida, a consulta passará a maior parte de seu tempo de vida em execução. Normalmente, quando o mecanismo do SQL Server gera alto uso da CPU, o alto uso da CPU é proveniente de consultas que geram um grande número de leituras lógicas (o motivo mais comum).
Para identificar as consultas responsáveis pela atividade alta da CPU no momento, execute a seguinte instrução:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Se as consultas não estiverem usando a CPU no momento, você poderá executar a seguinte instrução para procurar consultas históricas associadas à CPU:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Métodos comuns para resolver consultas de longa execução associadas à CPU
- Examinar o plano de consulta da consulta
- Atualização de Estatísticas
- Identificar e aplicar índices ausentes. Para obter mais etapas sobre como identificar índices ausentes, consulte Ajustar índices não clusterizados com sugestões de índice ausente
- Reprojetar ou reescrever as consultas
- Identificar e resolver planos sensíveis a parâmetros
- Identificar e resolver problemas de capacidade SARG
- Identifique e resolva problemas de meta de linha em que loops aninhados de longa duração podem ser causados por TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Para obter mais informações, consulte Aprimoramentos de Metas de Linha Desonestas e Plano de Execução - Meta de Linha EstimateRowsWithoutRowGoal
- Avalie e resolva problemas de estimativa de cardinalidade. Para obter mais informações, consulte Diminuição do desempenho da consulta após a atualização do SQL Server 2012 ou anterior para 2014 ou posterior
- Identificar e resolver consultas que parecem não nunca concluídas, consulte Solucionar problemas de consultas que parecem nunca terminar no SQL Server
- Identificar e resolver consultas lentas afetadas pelo tempo limite do otimizador
- Identifique problemas de alto desempenho da CPU. Para obter mais informações, consulte Solucionar problemas de alto uso da CPU no SQL Server
- Solucionar problemas de uma consulta que mostra uma diferença significativa de desempenho entre dois servidores
- Aumentar os recursos de computação no sistema (CPUs)
- Solucionar problemas de desempenho de ATUALIZAÇÃO com planos estreitos e amplos
Recursos recomendados
- Tipos detectáveis de gargalos de desempenho de consulta no SQL Server e na Instância Gerenciada de SQL do Azure
- Ferramentas para monitoramento e ajuste de desempenho
- Opções de ajuste automático no SQL Server
- Guia de arquitetura e design de índice
- Solucionar problemas de tempo limite de consulta
- Solucionar problemas de alto uso da CPU no SQL Server
- Diminuição do desempenho da consulta após a atualização do SQL Server 2012 ou anterior para 2014 ou posterior