Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este documento descreve como funciona a Desduplicação de Dados .
Como funciona a Desduplicação de Dados?
A Desduplicação de Dados no Windows Server foi criada com os dois princípios a seguir:
A otimização não deve atrapalhar as gravações no disco a Eliminação de Duplicação de Dados otimiza os dados usando um modelo de pós-processamento. Todos os dados são gravados sem otimização no disco e, em seguida, otimizados posteriormente pela Desduplicação de Dados.
Otimização não deve alterar a semântica de acesso Os usuários e aplicativos que acessam dados em um volume otimizado desconhecem completamente que os arquivos que estão acessando foram desduplicados.
Uma vez habilitada para um volume, a Desduplicação de Dados é executada em segundo plano para:
- Identifique padrões repetidos entre arquivos nesse volume.
- Mova perfeitamente essas partes, ou pedaços, com ponteiros especiais chamados pontos de reparo que apontam para uma cópia exclusiva desse pedaço.
Isso ocorre nas quatro etapas a seguir:
- Analise o sistema de arquivos em busca de arquivos que atendam à política de otimização.

- Divida os arquivos em partes de tamanho variável.

- Identifique partes exclusivas.
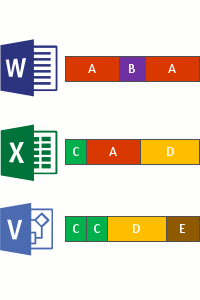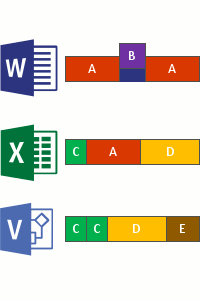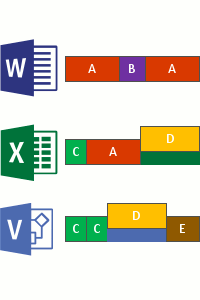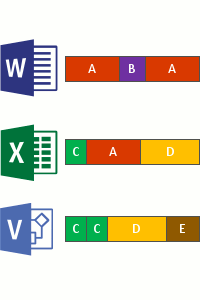
- Coloque blocos no armazenamento de blocos e, opcionalmente, comprima.
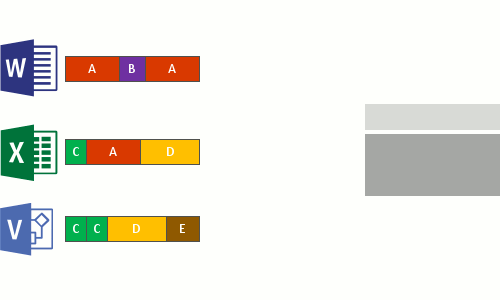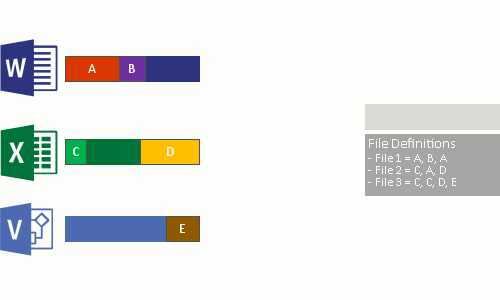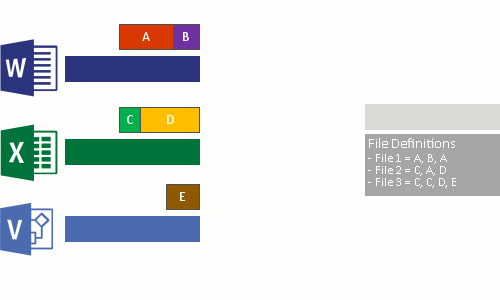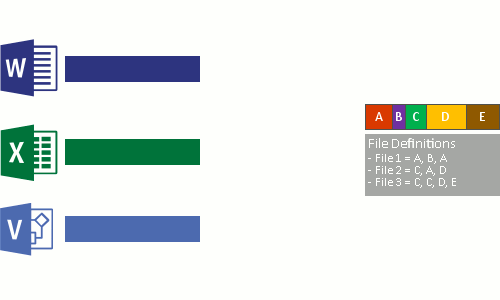
- Substitua o fluxo de ficheiros original dos ficheiros agora otimizados por um ponto de reanálise para o armazenamento de blocos.
Quando os arquivos otimizados são lidos, o sistema de ficheiros envia os ficheiros com um ponto de reanálise para o filtro do sistema de ficheiros Data Deduplication (Dedup.sys). O filtro redireciona a operação de leitura para as partes apropriadas que constituem o fluxo para esse arquivo no armazenamento de blocos. As modificações nos intervalos de ficheiros desduplicados são gravadas sem optimização no disco e são otimizadas pelo processo de otimização na próxima execução.
Tipos de uso
Os seguintes tipos de uso fornecem uma configuração razoável de eliminação de duplicação de dados para cargas de trabalho comuns:
| Tipo de Utilização | Cargas de trabalho ideais | O que é diferente |
|---|---|---|
| Padrão | Servidor de arquivos de uso geral:
|
|
| Hyper-V | Servidores VDI (Virtualized Desktop Infrastructure, infraestrutura de área de trabalho virtualizada) |
|
| Backup | Aplicativos de backup virtualizados, como Microsoft Data Protection Manager (DPM) |
|
Jobs
A Desduplicação de Dados usa uma estratégia de pós-processamento para otimizar e manter a eficiência de espaço de um volume.
| Nome do trabalho | Descrição das funções | Agendamento padrão |
|---|---|---|
| Otimização | O trabalho de Otimização desduplica dividindo dados em um volume de acordo com as configurações de política de volume, (opcionalmente) compactando esses blocos e armazenando blocos exclusivamente no repositório de blocos. O processo de otimização que a Desduplicação de Dados usa é descrito em detalhes em Como funciona a Desduplicação de Dados?. | Uma vez a cada hora |
| Recolha de Lixo | O trabalho de coleta de lixo recupera espaço em disco removendo partes desnecessárias que não estão mais sendo referenciadas por arquivos que foram recentemente modificados ou excluídos. | Todos os sábados às 2:35 AM |
| Limpeza de Integridade | O trabalho de verificação de integridade identifica corrupção no armazenamento de fragmentos devido a falhas de disco ou setores defeituosos. Quando possível, a Desduplicação de Dados pode usar automaticamente recursos de volume (como espelho ou paridade em um volume de Espaços de Armazenamento) para reconstruir os dados corrompidos. Além disso, a Desduplicação de Dados mantém cópias de backup de fragmentos populares quando são referenciados mais de cem vezes em uma área denominada 'hotspot'. | Todos os sábados às 3:35 AM |
| Desotimização | O trabalho de Desotimização , que é um trabalho especial que só deve ser executado manualmente, desfaz a otimização feita por desduplicação e desabilita a Desduplicação de Dados para esse volume. | Apenas sob demanda |
Terminologia de Deduplicação de Dados
| Term | Definition |
|---|---|
| Bloco | Um bloco é uma seção de um arquivo que foi selecionado pelo algoritmo de segmentação de Desduplicação de Dados como provável de ocorrer em outros arquivos semelhantes. |
| Armazém de Blocos | O armazenamento de fragmentos é uma série organizada de ficheiros de contentor na pasta System Volume Information que o Data Deduplication usa para armazenar de forma única fragmentos. |
| Dedup | Uma abreviação para Eliminação de Duplicação de Dados que é comumente usada no PowerShell, nas APIs e componentes do Windows Server e na comunidade do Windows Server. |
| Metadados do arquivo | Cada arquivo contém metadados que descrevem propriedades interessantes sobre o arquivo que não estão relacionadas ao conteúdo principal do arquivo. Por exemplo, Data de criação, Data da última leitura, Autor, etc. |
| Fluxo de arquivos | O fluxo de arquivos é o conteúdo principal do arquivo. Esta é a parte do arquivo que a Desduplicação de Dados otimiza. |
| Sistema de arquivos | O sistema de arquivos é o software e a estrutura de dados em disco que o sistema operacional usa para armazenar arquivos em mídia de armazenamento. A Desduplicação de Dados é suportada em volumes formatados NTFS. |
| Filtro do sistema de arquivos | Um filtro de sistema de arquivos é um plug-in que modifica o comportamento padrão do sistema de arquivos. Para preservar a semântica de acesso, a Eliminação de Duplicação de Dados usa um filtro de sistema de arquivos (Dedup.sys) para redirecionar leituras para conteúdo otimizado de forma completamente transparente para o usuário ou aplicativo que faz a solicitação de leitura. |
| Otimização | Um arquivo é considerado otimizado (ou desduplicado) pela Desduplicação de Dados se tiver sido fragmentado e seus blocos exclusivos tiverem sido armazenados no armazenamento de blocos. |
| Política de otimização | A política de otimização especifica os arquivos que devem ser considerados para a Eliminação de Duplicação de Dados. Por exemplo, os arquivos podem ser considerados fora da política se forem novos, abertos, em um determinado caminho no volume ou em um determinado tipo de arquivo. |
| Ponto de análise | Um ponto de análise é uma marca especial que notifica o sistema de arquivos para passar E/S para um filtro de sistema de arquivos especificado. Quando o fluxo de arquivos de um arquivo é otimizado, a Eliminação de Duplicação de Dados substitui o fluxo de arquivos por um ponto de análise, o que permite que a Eliminação de Duplicação de Dados preserve a semântica de acesso para esse arquivo. |
| Volume | Um volume é uma construção do Windows para uma unidade de armazenamento lógico que pode abranger vários dispositivos de armazenamento físico em um ou mais servidores. A desduplicação é habilitada volume a volume. |
| Carga de trabalho | Uma carga de trabalho é um aplicativo executado no Windows Server. Exemplos de cargas de trabalho incluem servidor de arquivos de uso geral, Hyper-V e SQL Server. |
Warning
A menos que seja instruído pela equipa de suporte autorizada da Microsoft, não tente modificar manualmente o armazenamento de blocos. Fazer isso pode resultar em corrupção ou perda de dados.
Perguntas frequentes
Qual é a diferença entre a Desduplicação de Dados e outros produtos de otimização? Há várias diferenças importantes entre a eliminação de duplicação de dados e outros produtos comuns de otimização de armazenamento:
Qual é a diferença entre a Desduplicação de Dados e o Armazenamento de Instância Única? O Repositório de Instância Única, ou SIS, é uma tecnologia que precedeu a Desduplicação de Dados e foi introduzida pela primeira vez no Windows Storage Server 2008 R2. Para otimizar um volume, o Repositório de Instância Única identificou arquivos que eram completamente idênticos e os substituiu por links lógicos para uma única cópia de um arquivo armazenado no armazenamento comum do SIS. Ao contrário do Armazenamento de Instância Única, a Desduplicação de Dados pode obter economia de espaço de arquivos que não são idênticos, mas compartilham muitos padrões comuns e de arquivos que contêm muitos padrões repetidos. O Repositório de Instância Única foi descontinuado no Windows Server 2012 R2 e removido no Windows Server 2016 em favor da Deduplicação de Dados.
Qual é a diferença entre a Desduplicação de Dados e a compactação NTFS? A compactação NTFS é um recurso do NTFS que você pode opcionalmente habilitar no nível do volume. Com a compressão NTFS, cada ficheiro é otimizado individualmente através de compressão em tempo de escrita. Ao contrário da compactação NTFS, a Desduplicação de Dados pode obter economia de espaçamento em todos os arquivos em um volume. Isso é melhor do que a compactação NTFS porque os arquivos podem ter duplicação interna (que é abordada pela compactação NTFS) e ter semelhanças com outros arquivos no volume (que não é abordado pela compactação NTFS). Além disso, a Desduplicação de Dados tem um modelo de pós-processamento, o que significa que os arquivos novos ou modificados serão gravados no disco sem otimização e serão otimizados posteriormente pela Desduplicação de Dados.
Como a Desduplicação de Dados difere dos formatos de arquivo como zip, rar, 7z, cab, etc.? Formatos de arquivo, como zip, rar, 7z, cab, etc., realizam compressão de um conjunto especificado de ficheiros. Como na desduplicação de dados, padrões duplicados dentro de arquivos e padrões duplicados entre arquivos são otimizados. No entanto, você tem que escolher os arquivos que você deseja incluir no arquivo. A semântica de acesso também é diferente. Para acessar um arquivo específico dentro do arquivo, você precisa abrir o arquivo, selecionar um arquivo específico e descompactar esse arquivo para uso. A Desduplicação de Dados opera de forma transparente para usuários e administradores e não requer início manual. Além disso, a Desduplicação de Dados preserva a semântica de acesso: os arquivos otimizados aparecem inalterados após a otimização.
Posso alterar as configurações de Eliminação de Duplicação de Dados para o Tipo de Uso selecionado? Yes. Embora a Eliminação de Duplicação de Dados forneça padrões razoáveis para cargas de trabalho recomendadas, talvez você ainda queira ajustar as configurações de Eliminação de Duplicação de Dados para aproveitar ao máximo seu armazenamento. Além disso, outras cargas de trabalho exigirão alguns ajustes para garantir que a Eliminação de Duplicação de Dados não interfira com a carga de trabalho.
Posso executar manualmente um trabalho de Eliminação de Duplicação de Dados? Sim, todos os trabalhos de Desduplicação de Dados podem ser executados manualmente. Isso pode ser desejável se os trabalhos agendados não foram executados devido a recursos insuficientes do sistema ou devido a um erro. Além disso, o trabalho de desotimização só pode ser executado manualmente.
Posso monitorar os resultados históricos dos trabalhos de Desduplicação de Dados? Sim, todos os trabalhos de Desduplicação de Dados fazem registos no Registo de Eventos do Windows.
Posso alterar as agendas padrão para os trabalhos de Desduplicação de Dados no meu sistema? Sim, todos os horários são configuráveis. Modificar as agendas padrão de Desduplicação de Dados é particularmente desejável para garantir que os trabalhos de Desduplicação de Dados tenham tempo para concluir e não compitam por recursos com a carga de trabalho.