Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
В этой статье описано, как скопировать данные с сервера распределенной файловой системы Hadoop (HDFS). Дополнительные сведения см. в вводных статьях по Azure Data Factory и Synapse Analytics.
Поддерживаемые возможности
Соединитель HDFS поддерживает следующие возможности:
| Поддерживаемые возможности | IR |
|---|---|
| Copy activity (источник/-) | (1) (2) |
| Операция поиска | (1) (2) |
| Удаление действия | (1) (2) |
(1) Azure среды выполнения интеграции (2) локальная среда выполнения интеграции
В частности, этот соединитель HDFS поддерживает:
- Копирование файлов с помощью проверки подлинности Windows (Kerberos) или Anonymous.
- Копирование файлов с помощью протокола webhdfs или встроенной поддержки DistCp.
- Копирование файлов "как есть" либо посредством разбора или создания файлов с использованием поддерживаемых форматов файлов и кодеков сжатия.
Требуемые условия
Если хранилище данных находится в локальной сети, виртуальной сети Azure или Amazon Virtual Private Cloud, необходимо настроить самостоятельно размещаемую среду выполнения интеграции для подключения к нему.
Если хранилище данных является управляемой облачной службой данных, можно использовать Azure Integration Runtime. Если доступ ограничен ip-адресами, утвержденными в правилах брандмауэра, в список разрешений можно добавить ip-адреса Azure Integration Runtime/c0.
Вы также можете использовать функцию управляемой среды выполнения интеграции виртуальной сети в Azure Data Factory для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Примечание.
Убедитесь, что Integration Runtime может получить доступ ко всем [сервер_узла_имен]:[порт_узла_имен] и [серверы_узлов_данных]:[порты_узлов_данных] кластера Hadoop. По умолчанию используются [порт_узла_имен] 50070 и [порт_узла_данных] 50075.
Начало работы
Для выполнения действия копирования с конвейером можно использовать один из следующих средств или пакетов SDK:
- Средство копирования данных
- портал Azure
- SDK .NET
- пакет SDK Python
- Azure PowerShell
- REST API
- шаблон Azure Resource Manager
Создание связанной службы с HDFS с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу с HDFS в пользовательском интерфейсе портала Azure.
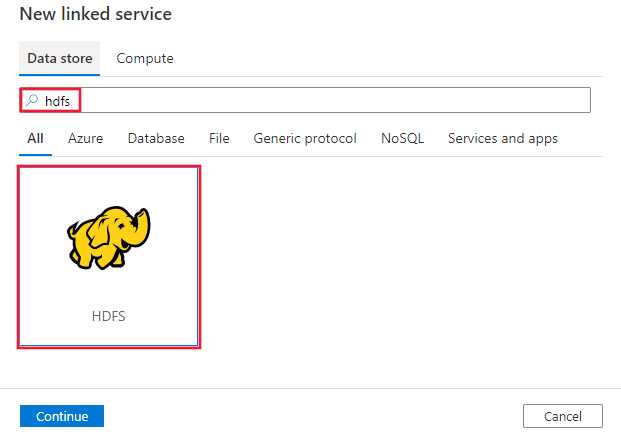
Перейдите на вкладку "Управление" в рабочей области Azure Data Factory или Synapse и выберите "Связанные службы", а затем нажмите кнопку "Создать".
Найдите HDFS и выберите разъем HDFS.
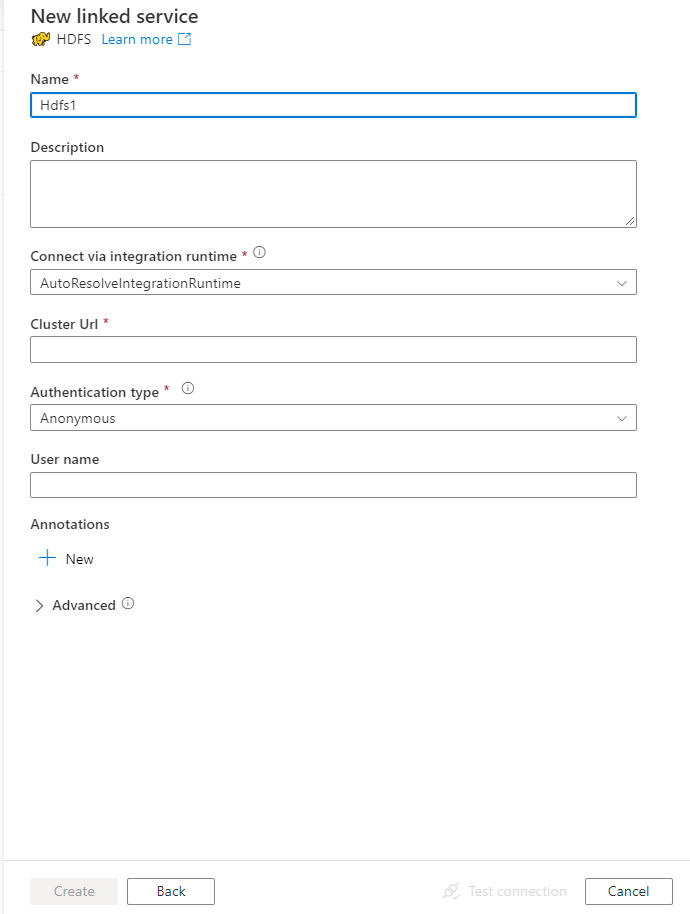
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей фабрики данных, относящихся к HDFS.
Свойства связанной службы
Для связанной службы HDFS поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение Hdfs. | Да |
| URL-адрес | URL-адрес в HDFS | Да |
| тип аутентификации | Допустимые значения : Anonymous или Windows. Сведения о настройке локальной среды см. в разделе Использование проверки подлинности Kerberos для соединителя HDFS. |
Да |
| userName | Имя пользователя для аутентификации Windows. Для проверки подлинности Kerberos укажите <username>@<domain>.com. | Да (для Windows authentication) |
| пароль | Пароль для аутентификации Windows. Отметьте это поле как SecureString для безопасного хранения или обратитесь к секрету, хранящемуся в хранилище ключей Azure. | Да (для проверки подлинности Windows) |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Подробнее см. в разделе Необходимые требования. Если integration runtime не указан, служба использует Azure Integration Runtime по умолчанию. | Нет |
Пример: использование анонимной проверки подлинности
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование аутентификации Windows
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Для получения полного списка разделов и свойств, доступных для определения наборов данных, см. Datasets.
Azure Data Factory поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для HDFS-сервера в настройках location в наборе данных на основе формата:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type в location для набора данных должно быть HdfsLocation. |
Да |
| folderPath | Путь к папке. Если вы хотите использовать подстановочный знак для фильтрации папки, пропустите этот параметр и укажите путь в параметрах источника действия. | Нет |
| имя файла | Имя файла в указанном пути folderPath. Если вы хотите использовать подстановочный знак для фильтрации файлов, пропустите этот параметр и укажите имя файла в параметрах источника действия. | Нет |
Пример:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Свойства Copy activity
Для получения полного списка разделов и свойств, доступных для определения действий, см. Конвейеры и действия. Этот раздел содержит список свойств, поддерживаемых источником HDFS.
HDFS в качестве источника
Azure Data Factory поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для HDFS в параметрах storeSettings в источнике копирования на основе формата:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type в разделе storeSettings необходимо задать значение HdfsReadSettings. |
Да |
| Найдите файлы для копирования | ||
| ВАРИАНТ 1. Статический путь |
Копируйте из указанного в наборе данных пути к папке или файлу. Если вы хотите скопировать все файлы из папки, дополнительно укажите wildcardFileName со значением *. |
|
| ВАРИАНТ 2. Подстановочный знак — wildcardFolderPath |
Путь к папке с подстановочными знаками для фильтрации исходных папок. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^ для экранирования, если фактическое имя папки содержит подстановочный знак или этот escape-символ. Больше примеров см. в разделе Примеры фильтров папок и файлов. |
Нет |
| ВАРИАНТ 2. Подстановочный знак — wildcardFileName |
Имя файла с подстановочными знаками в заданном пути folderPath/wildcardFolderPath для фильтрации исходных папок. Допустимые подстановочные знаки: * (соответствует нулю или большему количеству знаков) и ? (соответствует нулю или одному знаку). Для экранирования используйте ^, если фактическое имя файла содержит подстановочный знак или escape-символ. Больше примеров см. в разделе Примеры фильтров папок и файлов. |
Да |
| Вариант 3. Список файлов - fileListPath |
Указывает, что нужно скопировать заданный набор файлов. Укажите текстовый файл со списком файлов, которые необходимо скопировать, по одному файлу в строке (каждая строка должна содержать относительный путь к заданному в наборе данных пути). При использовании этого параметра не указывайте имя файла в наборе данных. Больше примеров см. в разделе Примеры списка файлов. |
Нет |
| Дополнительные параметры | ||
| рекурсивный | Указывает, следует ли читать данные рекурсивно из вложенных каталогов или только из конкретной папки. Если свойству recursive задано значение true, и приемником является файловое хранилище, пустые папки и вложенные папки не копируются и не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. Это свойство не применяется при настройке fileListPath. |
Нет |
| УдалитьФайлыПослеЗавершения | Указывает, удаляются ли двоичные файлы из исходного хранилища после успешного перемещения в конечное хранилище. Файлы удаляются поочередно, поэтому в случае сбоя действия копирования вы увидите, что некоторые файлы уже скопированы в место назначения и удалены из источника, в то время как остальные находятся в исходном хранилище. Это свойство допустимо только в сценарии копирования двоичных файлов. По умолчанию имеет значение false. |
Нет |
| modifiedDatetimeStart | Фильтрация файлов на основе атрибута Last Modified. Выбираются все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате 2018-12-01T05:00:00Z. Свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не применяются к набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени.Это свойство не применяется при настройке fileListPath. |
Нет |
| modifiedDatetimeEnd | То же, что выше. | |
| " enablePartitionDiscovery | Для секционированных файлов укажите, следует ли анализировать секции из пути к файлу и добавлять их как дополнительные исходные столбцы. Допустимые значения: false (по умолчанию) и true. |
Нет |
| Корневой путь раздела | Если обнаружение секций включено, укажите абсолютный корневой путь, чтобы считывать секционированные папки как столбцы данных. Если параметр не задан (по умолчанию), происходит следующее. — При использовании пути к файлу в наборе данных или списке файлов в источнике корневым путем секции считается путь, настроенный в наборе данных. — При использовании фильтра папки с подстановочными знаками корневым путем раздела считается подчасть пути до первого подстановочного знака. Предположим, что вы настроили путь в наборе данных следующим образом: "root/folder/year=2020/month=08/day=27". — Если указать корневой путь секции "root/folder/year=2020", действие копирования в дополнение к указанным в файлах столбцам создаст еще два столбца, month и day, со значениями "08" и "27" соответственно.— Если корневой путь секции не указан, дополнительные столбцы создаваться не будут. |
Нет |
| максимальное количество одновременных подключений | Верхний предел одновременных подключений, установленных в хранилище данных при запуске задачи. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Нет |
| Параметры DistCp | ||
| distcpSettings | Группа свойств, которую следует использовать при работе с HDFS DistCp. | Нет |
| конечная_точка_диспетчера_ресурсов | Конечная точка YARN (Yet Another Resource Negotiator) | Да, если используется DistCp |
| tempScriptPath | Путь к папке для хранения временного командного скрипта DistCp. Файл сценария создается, а после завершения задания копирования он удаляется. | Да, если используется DistCp |
| distcpOptions | Дополнительные параметры для команды DistCp. | Нет |
Пример:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Примеры фильтров папок и файлов
В этом разделе описываются результаты применения фильтров с подстановочными знаками к пути папки и имени файла.
| folderPath | имя файла | рекурсивный | Структура исходной папки и результат фильтрации (извлекаются файлы, выделенные полужирным шрифтом) |
|---|---|---|---|
Folder* |
(пусто, используйте по умолчанию) | ложь | ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
Folder* |
(пусто, используйте по умолчанию) | true | ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
Folder* |
*.csv |
ложь | ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
Folder* |
*.csv |
true | ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv ДругаяПапкаB Файл6.csv |
Примеры списков файлов
В этом разделе описывается поведение, которое возникает при использовании пути списка файлов в источнике Copy activity. Предположим, что у вас есть следующая исходная структура папок и вы хотите скопировать файлы, выделенные полужирным шрифтом.
| Пример исходной структуры | Содержимое в файле FileListToCopy.txt | Настройка |
|---|---|---|
| корень ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Метаданные FileListToCopy.txt |
Файл1.csv Вложенная_папка1/Файл3.csv Подпапка1/Файл5.csv |
В наборе данных: – Путь к папке: root/FolderAВ источнике задачи копирования: – Путь к списку файлов: root/Metadata/FileListToCopy.txt Путь к списку файлов указывает на текстовый файл в том же хранилище данных, содержащий список файлов для копирования, с указанием по одному файлу в строке с относительным путем к заданному в наборе данных пути. |
Использовать DistCp для копирования данных из HDFS
DistCp является программой командной строки Hadoop для создания распределенной копии в кластере Hadoop. При выполнении команды в DistCp сначала выводится список всех копируемых файлов, а затем в кластере Hadoop создается несколько заданий сопоставления. Каждая Map-задача создает побитовую копию из источника в приемник.
Copy activity поддерживает использование DistCp для копирования файлов в хранилище объектов Azure Blob (включая стажированное копирование) или в хранилище Azure Data Lake. В этом случае DistCp может воспользоваться возможностями кластера, а не работать в локальной среде выполнения интеграции. При использовании DistCp пропускная способность копирования будет выше, особенно если ваш кластер очень мощный. На основе конфигурации Copy activity автоматически создает команду DistCp, отправляет ее в кластер Hadoop и отслеживает состояние копирования.
Требуемые условия
Чтобы использовать DistCp для копирования файлов из HDFS в хранилище BLOB-объектов Azure (включая поэтапное копирование) или озеро данных Azure, убедитесь, что ваш кластер Hadoop соответствует следующим требованиям:
Службы MapReduce и YARN включены.
Версия YARN— 2.5 или более поздняя.
Сервер HDFS интегрирован с целевым хранилищем данных: хранилище BLOB Azure или Azure Data Lake Store (ADLS Первого поколения):
- Файловая система Azure Blob поддерживается изначально начиная с Hadoop 2.7. Необходимо только указать путь JAR в конфигурации среды Hadoop.
- Azure Data Lake Store FileSystem упаковается начиная с Hadoop 3.0.0-alpha1. Если версия вашего кластера Hadoop более ранняя, чем указанная, необходимо вручную импортировать JAR-пакеты, связанные с Azure Data Lake Store (azure-datalake-store.jar), в кластер из здесь и указать путь к JAR-файлу в конфигурации среды Hadoop.
Подготовьте временную папку в HDFS. Эта временная папка используется для хранения скрипта оболочки DistCp, поэтому она будет занимать пространство порядка нескольких килобайтов.
Убедитесь, что учетная запись пользователя, предоставленная в связанной службе HDFS, имеет следующие разрешения:
- Отправьте приложение в YARN.
- Создайте вложенную папку и читайте/записывайте файлы во временной папке.
Конфигурации
См. варианты конфигурации, связанные с DistCp, а также примеры в разделе HDFS в качестве источника.
Использование проверки подлинности Kerberos для соединителя HDFS
Есть два способа настроить локальную инфраструктуру для использования аутентификации с использованием Kerberos в соединителе HDFS. Вы можете выбрать тот, который лучше подходит для вашей ситуации.
- Вариант 1. Присоединение компьютера, где выполняется локальная среда выполнения интеграции, к области Kerberos
- Вариант 2: Включить взаимное доверие между доменом Windows и областью Kerberos
Для любого из этих вариантов включите webhdfs для кластера Hadoop:
Создайте HTTP-принципал и keytab для webhdfs.
Внимание
Принципал Kerberos для HTTP должен начинаться с "HTTP/" в соответствии со спецификацией Kerberos HTTP SPNEGO. Узнайте больше здесь.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>Параметры конфигурации HDFS: добавьте следующие три свойства в
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Вариант 1. Присоединение компьютера, где выполняется локальная среда выполнения интеграции, к области Kerberos
Требования
- Компьютер локальной среды выполнения интеграции должен присоединиться к области Kerberos и не может присоединиться к домену Windows.
Порядок настройки
На сервере KDC:
Создайте учетную запись и укажите пароль.
Внимание
Имя пользователя не должно содержать имя узла.
Kadmin> addprinc <username>@<REALM.COM>
На машине с локально размещенной интеграционной средой выполнения:
Запустите служебную программу Ksetup, чтобы настроить сервер центра распространения ключей (KDC) и область Kerberos.
Компьютер должен быть настроен как член рабочей группы, так как область Kerberos отличается от домена Windows. Эту конфигурацию можно настроить, задав область Kerberos и добавив сервер KDC с помощью следующих команд. Замените REALM.COM названием своей области.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>После выполнения этих команд перезапустите компьютер.
Проверьте конфигурацию с помощью команды
Ksetup. Результат должен выглядеть примерно так:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
В хранилище данных или рабочей области Synapse:
- Настройте соединитель HDFS с помощью аутентификации Windows совместно с вашим именем субъекта Kerberos и паролем для подключения к источнику данных HDFS. Дополнительные сведения о конфигурации см. в разделе свойств связанной службы HDFS.
Вариант 2. Включение взаимного доверия между доменом Windows и областью Kerberos
Требования
- Компьютер локальной среды выполнения интеграции должен присоединиться к домену Windows.
- Требуется разрешение на обновление параметров контроллера домена.
Порядок настройки
Примечание.
При необходимости замените REALM.COM и AD.COM именем области и контроллером домена в следующем руководстве.
На сервере KDC:
Измените конфигурацию KDC в файле krb5.conf, чтобы позволить KDC доверять домену Windows, ссылаясь на следующий шаблон конфигурации. По умолчанию файл конфигурации содержится в папке /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }После настройки файла перезапустите сервис KDC.
Настройте учетную запись с именем krbtgt/REALM.COM@AD.COM на сервере KDC с помощью следующей команды:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMВ файл конфигурации службы HDFS hadoop.security.auth_to_local добавьте
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
На контроллере домена:
Выполните следующие
Ksetupкоманды, чтобы добавить запись в область:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMУстановите доверие из домена Windows в область Kerberos. [password] — это пароль для субъекта krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Выберите алгоритм шифрования, используемый в Kerberos.
a. Выберите Диспетчер сервера>Управление групповыми политиками>Домен>Объекты групповой политики>Политику по умолчанию или активный домен, а затем выберите Изменить.
b. В области Редактор управления групповой политикой выберите Конфигурация компьютера>Политики>Параметры Windows>Параметры безопасности>Локальные политики>Параметры безопасности, и затем настройте Сетевая безопасность: настройте типы шифрования, разрешенные для Kerberos.
с. Выберите алгоритм шифрования, который будет использоваться для подключения к KDC. Можно выбрать все параметры.

d. С помощью команды
Ksetupзадайте алгоритм шифрования, который будет использоваться для этой области.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Создайте сопоставление между доменной учетной записью и Kerberos principal, чтобы использовать Kerberos principal в домене Windows.
a. Выберите Административные инструменты>Active Directory Users and Computers.
b. Настройте дополнительные функции, выбрав Вид>Дополнительные параметры.
с. На панели Дополнительные функции щелкните правой кнопкой мыши учетную запись, для которой нужно создать сопоставления, и на панели Сопоставления имен выберите вкладку Имена Kerberos.
d. Добавьте принципал из домена.
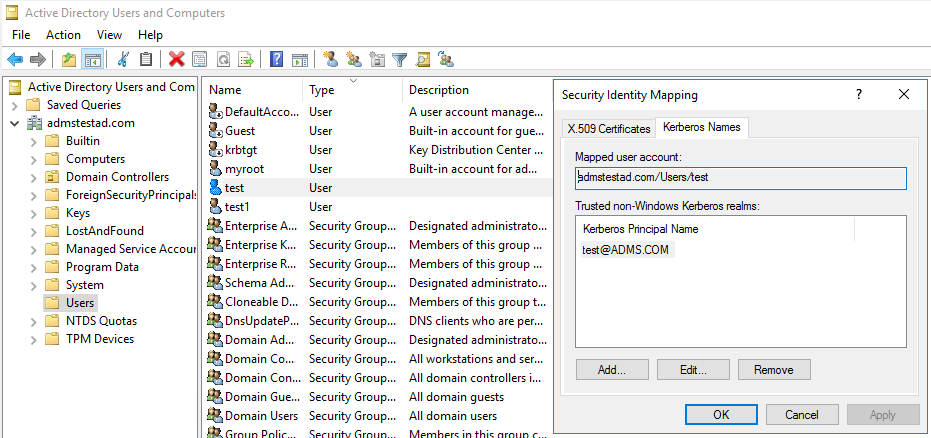
На машине с локально размещенной интеграционной средой выполнения:
Выполните следующие команды
Ksetup, чтобы добавить запись в область.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
В хранилище данных или рабочей области Synapse:
- Настройте соединитель HDFS, используя аутентификацию Windows вместе с либо вашей учетной записью домена, либо основной учетной записью Kerberos, для подключения к источнику данных HDFS. Сведения о настройке см. в разделе Свойства связанной службы HDFS.
Свойства операции поиска
Сведения о свойствах действия поиска см. в разделе Действие поиска.
Удалить свойства активности
Сведения о свойствах действия удаления см. в статье Действие удаления.
Устаревшие модели
Примечание.
Следующие модели по-прежнему поддерживаются на условиях "как есть" для обеспечения обратной совместимости. Рекомендуется использовать ранее описанную новую модель, так как пользовательский интерфейс разработки переключен для создания новой модели.
Устаревшая модель набора данных
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type для набора данных должно иметь значение FileShare | Да |
| folderPath | Путь к папке. Фильтр с подстановочными символами поддерживается. Допустимые подстановочные знаки: * (соответствует нулю или большему количеству знаков) и ? (соответствует нулю или одному знаку). Для экранирования используйте ^, если фактическое имя файла содержит подстановочный знак или escape-символ. Примеры: rootfolder/subfolder/. Дополнительные примеры см. в разделе Примеры фильтров папок и файлов. |
Да |
| имя файла | Имя или фильтр постановочных знаков для файлов по указанному folderPath. Если этому свойству не присвоить значение, набор данных будет указывать на все файлы в папке. Допустимые знаки подстановки для фильтра: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному отдельному символу).Пример 1. "fileName": "*.csv"Пример 2. "fileName": "???20180427.txt"Используйте ^ для экранирования, если фактическое имя папки содержит подстановочный знак или этот escape-символ. |
Нет |
| modifiedDatetimeStart | Фильтрация файлов на основе атрибута Last Modified. Выбираются все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате 2018-12-01T05:00:00Z. Учтите, что включение этого параметра в случае, если требуется применить фильтр файлов к огромному числу файлов, повлияет на общую производительность перемещения данных. Свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не применяются к набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
Нет |
| modifiedDatetimeEnd | Фильтрация файлов на основе атрибута Last Modified. Выбираются все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате 2018-12-01T05:00:00Z. Учтите, что включение этого параметра в случае, если требуется применить фильтр файлов к огромному числу файлов, повлияет на общую производительность перемещения данных. Свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не применяются к набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
Нет |
| format | Если требуется скопировать файлы между файловыми хранилищами "как есть" (двоичное копирование), можно пропустить раздел форматирования в определениях входного и выходного наборов данных. Если нужно проанализировать файлы определенного формата, поддерживаются следующие форматы: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Свойству type в разделе format необходимо присвоить одно из этих значений. Дополнительные сведения см. в разделах о текстовом формате, формате JSON, формате Avro, формате ORC и формате Parquet. |
Нет (только для сценария двоичного копирования) |
| сжатие | Укажите тип и уровень сжатия данных. Дополнительные сведения см. в разделе Поддержка сжатия. Поддерживаемые типы: Gzip, Deflate, Bzip2 и ZipDeflate. Поддерживаемые уровни: Optimal и Fastest. |
Нет |
Совет
Чтобы скопировать все файлы в папке, укажите только folderPath.
Чтобы скопировать один файл с заданным именем, укажите folderPath с частью папки и fileName с именем файла.
Чтобы скопировать подмножество файлов в папке, укажите folderPath с частью папки и fileName с фильтром подстановочных знаков.
Пример:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Устаревшая исходная модель Copy activity
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type источника Copy activity должно иметь значение HdfsSource. | Да |
| рекурсивный | Указывает, следует ли читать данные рекурсивно из вложенных каталогов или только из конкретной папки. Если для свойства recursive задано значение true, а приемником является файловое хранилище, пустые папки и вложенные папки не копируются и не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. |
Нет |
| distcpSettings | Группа свойств, когда вы используете HDFS DistCp. | Нет |
| конечная_точка_диспетчера_ресурсов | Конечная точка YARN Менеджера ресурсов | Да, если используется DistCp |
| tempScriptPath | Путь к папке для хранения временного командного скрипта DistCp. Файл сценария создается, а после завершения задания копирования он удаляется. | Да, если используется DistCp |
| distcpOptions | Предоставляются дополнительные параметры для команды DistCp. | Нет |
| максимальное количество одновременных подключений | Верхний предел одновременных подключений, установленных в хранилище данных при запуске задачи. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Нет |
Пример: источник HDFS в операции копирования с помощью DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Связанный контент
Список хранилищ данных, поддерживаемых в качестве источников и приемников Copy activity, см. в разделе поддерживаемые хранилища данных.