Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если вам требуется анализировать файлы Excel, следуйте инструкциям, приведенным в этой статье. Служба поддерживает расширения XLS и XLSX.
Формат Excel поддерживается для следующих соединителей: Amazon S3, хранилище, совместимое с Amazon S3, BLOB-объекты Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения, Файлы Azure, файловая система, FTP, облачное хранилище Google, HDFS , HTTP, Oracle Cloud Storage и SFTP. Он поддерживается как источник, но не приемник.
Примечание.
Формат ".xls" не поддерживается при использовании HTTP.
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Excel.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type набора данных необходимо задать значение Excel. | Да |
| расположение | Параметры расположения файлов. Каждый файловый соединитель имеет собственный тип расположения и поддерживает собственный набор свойств в разделе location. |
Да |
| названиеЛиста | Название листа Excel, из которого следует читать данные. | Следует задать значение sheetName или sheetIndex |
| sheetIndex | Индекс листа Excel для чтения данных (начинается с 0). | Следует задать значение sheetName или sheetIndex |
| диапазон | Диапазон ячеек на данном листе для нахождения избранных данных, например: - не указано: считывается весь лист в виде таблицы из первой непустой строки и столбца; - A3: таблица считывается, начиная с заданной ячейки, при этом динамически обнаруживаются все строки ниже и все столбцы справа;- A3:H5: указанный фиксированный диапазон считывается в виде таблицы;- A3:A3: считывается эта одна ячейка. |
Нет |
| первая строка как заголовок | Следует ли рассматривать первую строку в заданном листе или диапазоне как строку заголовка с именами столбцов. Допустимые значения: true и false (по умолчанию). |
Нет |
| нулевое значение | Задает строковое представление значения NULL. Значение по умолчанию — пустая строка. |
Нет |
| сжатие | Группа свойств для настройки сжатия файлов. Настройте этот раздел, если вы хотите выполнить сжатие/распаковку при выполнении действия. | Нет |
| тип (в разделе compression) |
Кодек сжатия, используемый для чтения и записи двоичных файлов JSON. Допустимые значения: bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy, lz4. Значение по умолчанию — без сжатия. Примечание. В настоящее время операция копирования не поддерживает кодеки "snappy" и "lz4", а поток данных сопоставления не поддерживает кодеки "ZipDeflate", "TarGzip" и "Tar". Примечание: При использовании процесса копирования для распаковки файлов формата ZipDeflate и их записи в файловое хранилище данных, файлы извлекаются в папку <path specified in dataset>/<folder named as source zip file>/. |
№ |
| уровень (в разделе compression) |
Коэффициент сжатия. Допустимые значения: оптимальный или самый быстрый. - Самый быстрый: операция сжатия должна выполняться как можно быстрее, даже если результирующий файл не является оптимальным сжатием. - Optimal: операция сжатия должна выполняться оптимально, даже если для ее завершения требуется больше времени. Дополнительные сведения см. в разделе Уровень сжатия. |
Нет |
Ниже приведен пример набора данных Excel в хранилище BLOB-объектов Azure:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры. В этом разделе приведен список свойств, поддерживаемых источником в формате Excel.
Excel в качестве источника
В разделе *source* действия копирования поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type источника действия копирования необходимо задать значение ExcelSource. | Да |
| НастройкиМагазина | Группа свойств, определяющих способ чтения данных из хранилища данных. Каждый файловый соединитель поддерживает собственный набор параметров чтения в разделе storeSettings. |
Нет |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Сопоставление свойств потока данных
При сопоставлении потоков данных можно читать данные формата Excel в следующих хранилищах данных: Хранилище BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения, Amazon S3 и SFTP. Указывать на файлы Excel можно либо с помощью набора данных Excel, либо с помощью встроенного набора данных.
Свойства источника
В приведенной ниже таблице перечислены свойства, поддерживаемые источником данных Excel. Эти свойства можно изменить на вкладке "Параметры источника". При использовании встроенного набора данных вы увидите дополнительные параметры файла, которые совпадают с свойствами, описанными в разделе свойств набора данных.
| Имя | Описание: | Обязательное поле | Допустимые значения | Свойство скрипта потока данных |
|---|---|---|---|---|
| Пути с подстановочными знаками | Будут обработаны все файлы, соответствующие пути с подстановочными знаками. Переопределяет папку и путь к файлу, заданные в наборе данных. | нет | String[] | wildcardPaths |
| Корневой путь раздела | Для секционированных файловых данных можно ввести корневой путь к секции, чтобы считывать секционированные папки как столбцы | нет | Строка | partitionRootPath |
| Список файлов | Сообщает о том, указывает ли источник на текстовый файл, в котором перечислены файлы для обработки. | нет |
true или false |
список файлов |
| Столбец для хранения имени файла | Создайте новый столбец с именем и путем к исходному файлу. | нет | Строка | rowUrlColumn |
| После завершения | Инструкции в отношении удаления или перемещения файлов после обработки. Путь к файлу начинается с корня контейнера. | нет | Удалить: true или false Перемещение: ['<from>', '<to>'] |
Очистка файлов переместитьФайлы |
| Фильтр по последнему изменению | Задает фильтр для файлов по времени последнего изменения | нет | Метка времени | измененоПосле измененоДо |
| Никакие файлы не найдены | Если значение true, ошибка не возникает, если файлы не найдены | нет |
true или false |
ignoreNoFilesFound |
Пример источника
Ниже приведен пример конфигурации источника Excel в потоках данных для сопоставления при использовании режима набора данных.
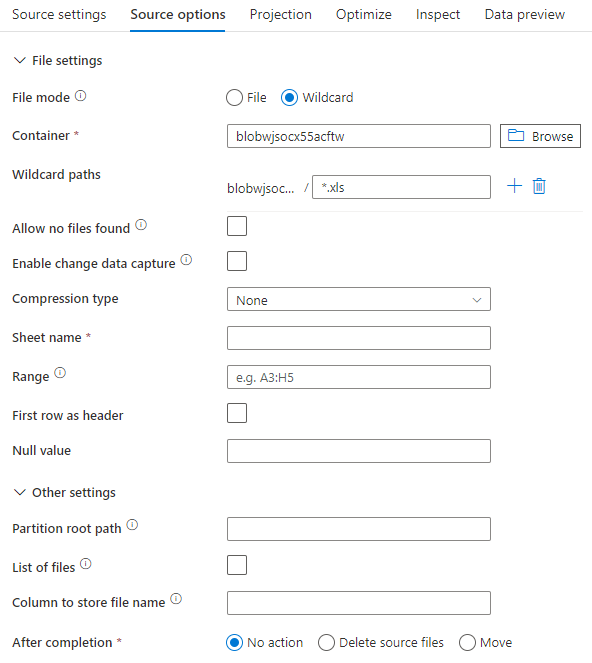
Связанный скрипт потока данных:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
При использовании встроенного набора данных в потоке данных для сопоставления отображаются следующие параметры источника.
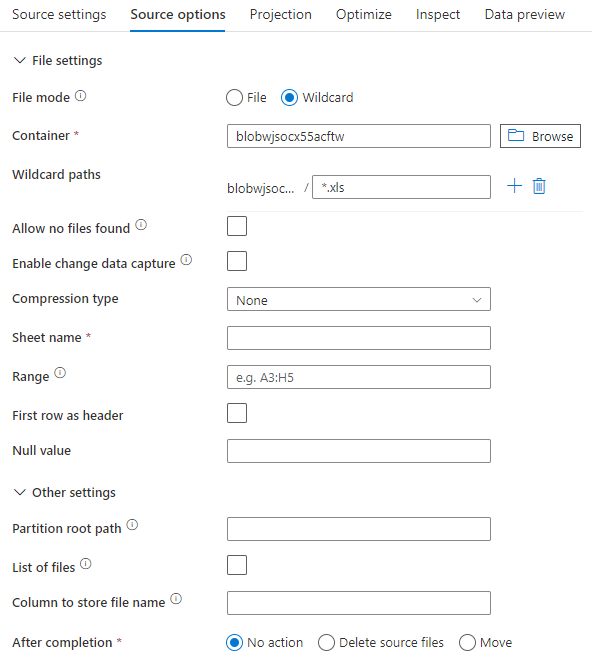
Связанный скрипт потока данных:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Примечание.
Сопоставление потоков данных не поддерживает чтение защищённых файлов Excel, поскольку эти файлы могут содержать уведомления о конфиденциальности или накладывать определённые ограничения на доступ к их содержимому.
Обработка очень больших файлов Excel
Соединитель Excel не поддерживает потоковое чтение для операции копирования и должен загружать весь файл в память, прежде чем данные можно будет читаться. Чтобы импортировать схему, просмотреть данные или обновить набор данных Excel, данные должны возвращаться до истечения времени ожидания HTTP-запроса (100 с). Для больших файлов Excel эти операции могут не завершиться в течение этого периода времени, что приведет к ошибке тайм-аута. Если вы хотите переместить большие файлы Excel (>100 МБ) в другое хранилище данных, можно использовать один из следующих вариантов, чтобы обойти это ограничение:
- Используйте локальную среду выполнения интеграции (SHIR), а затем используйте действие Copy для перемещения большого файла Excel в другое хранилище данных с помощью SHIR.
- Разделите большой Excel файл на несколько небольших, а затем используйте действие Copy для перемещения папки, содержащей файлы.
- Используйте действие потока данных для перемещения большого файла Excel в другое хранилище данных. Dataflow поддерживает потоковое чтение для Excel и может быстро перемещать и передавать большие файлы.
- Вручную преобразуйте большой файл Excel в формат CSV, а затем используйте действие Copy для перемещения файла.