TDSP — это гибкая и итеративная методология обработки и анализа данных, которую можно использовать для эффективного предоставления решений прогнозной аналитики и приложений искусственного интеллекта. TDSP улучшает совместную работу команды и обучение, рекомендуем оптимальные способы совместной работы ролей команды. TDSP включает рекомендации и платформы от Корпорации Майкрософт и других отраслевых лидеров, чтобы помочь вашей команде эффективно реализовать инициативы по обработке и анализу данных. TDSP позволяет полностью реализовать преимущества программы аналитики.
В этой статье представлен обзор TDSP и его основных компонентов. В нем представлены рекомендации по реализации TDSP с помощью средств и инфраструктуры Майкрософт. Более подробные ресурсы можно найти в этой статье.
Ключевые компоненты TDSP
TDSP имеет следующие ключевые компоненты:
- Определение жизненного цикла обработки и анализа данных
- Стандартизованная структура проекта
- Инфраструктура и ресурсы , которые идеально подходят для проектов обработки и анализа данных
- Ответственный ИИ: и приверженность улучшению ИИ, обусловленного этическими принципами
Жизненный цикл обработки и анализа данных
TDSP предоставляет жизненный цикл, который можно использовать для структуры разработки проектов обработки и анализа данных. Жизненный цикл охватывает все этапы, которые выполняются в успешных проектах.
TDSP на основе задач можно объединить с другими жизненными циклами обработки и анализа данных, например межиндустрийный стандартный процесс интеллектуального анализа данных (CRISP-DM), обнаружение знаний в базах данных (KDD) или другой настраиваемый процесс. На высоком уровне эти различные методики имеют много общего.
Используйте этот жизненный цикл, если у вас есть проект обработки и анализа данных, который является частью интеллектуального приложения. Интеллектуальные приложения развертывают модели машинного обучения или искусственного интеллекта для прогнозной аналитики. Этот процесс также можно использовать для исследовательских проектов по обработке и анализу импровизированных аналитических проектов.
Жизненный цикл TDSP состоит из пяти основных этапов, которые команда выполняет итеративно. Эти этапы включают:
Ниже приведено визуальное представление жизненного цикла TDSP:
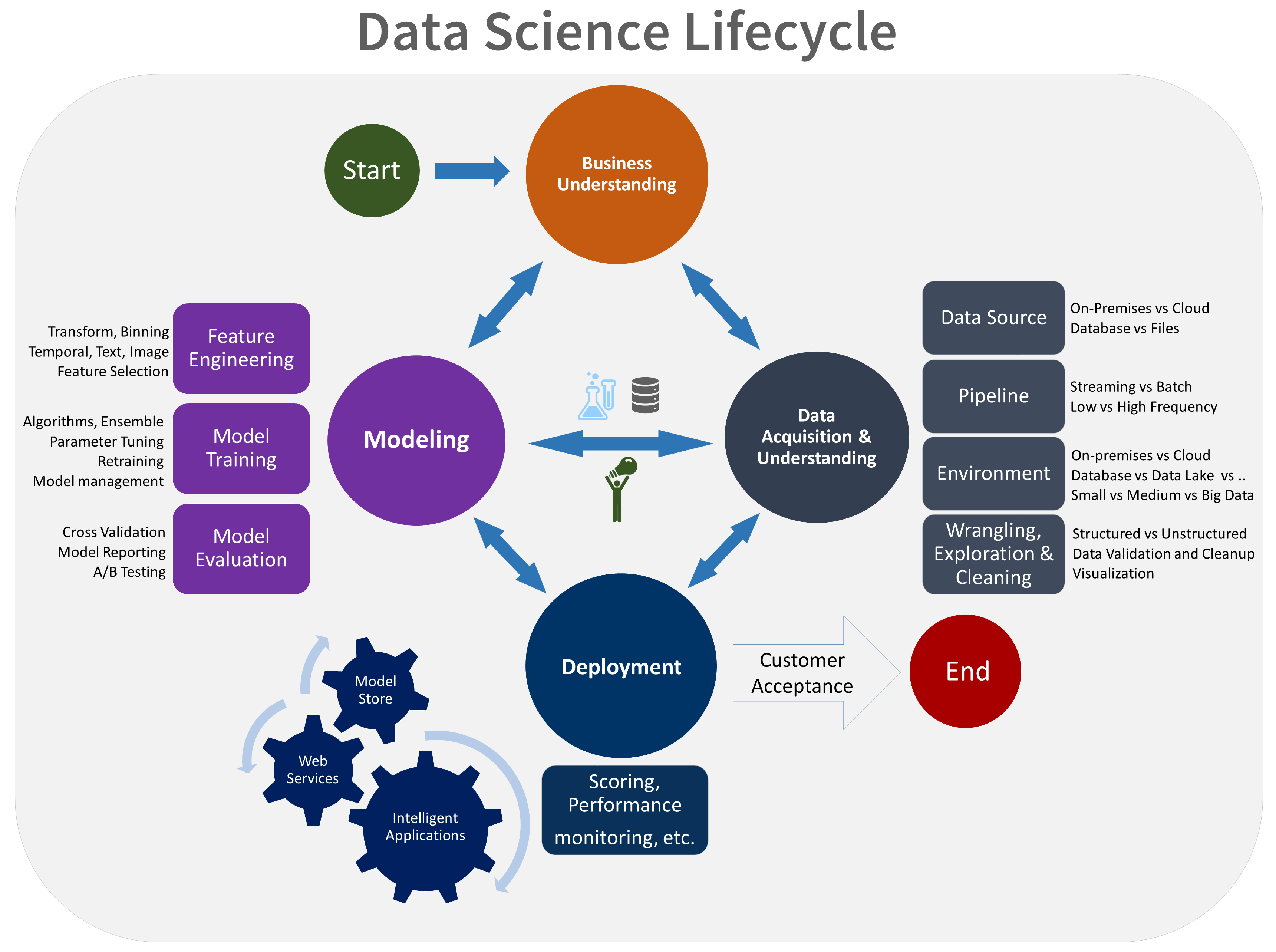
Дополнительные сведения о целях, задачах и артефактах документации для каждого этапа см. в разделе жизненный цикл TDSP.
Эти задачи и артефакты соответствуют ролям проекта, таким как:
- Архитектор решений
- Руководитель проекта
- Инженер данных
- Специалист по обработке и анализу данных
- Разработчик приложений
- Руководитель проекта
На следующей схеме показаны задачи (синие) и артефакты (в зеленом цвете), соответствующие каждому этапу жизненного цикла, изображенному на горизонтальной оси, и для ролей, отображаемых на вертикальной оси.

Стандартная структура проекта
Ваша команда может использовать инфраструктуру Azure для организации ресурсов обработки и анализа данных.
Машинное обучение Azure поддерживает открытый исходный код MLflow. Рекомендуется использовать MLflow для обработки и анализа данных и управления проектами искусственного интеллекта. MLflow предназначен для управления полным жизненным циклом машинного обучения. Он обучает и обслуживает модели на разных платформах, чтобы использовать согласованный набор инструментов независимо от того, где выполняются эксперименты. MLflow можно использовать локально на компьютере, в удаленном целевом объекте вычислений, на виртуальной машине или в вычислительном экземпляре машинного обучения.
MLflow состоит из нескольких ключевых функций:
Отслеживание экспериментов. С помощью MLflow можно отслеживать эксперименты, включая параметры, версии кода, метрики и выходные файлы. Эта функция помогает сравнить различные запуски и эффективно управлять процессом экспериментирования.
Код пакета: он предоставляет стандартизованный формат для упаковки кода машинного обучения, который включает зависимости и конфигурации. Эта упаковка упрощает воспроизведение запуска и совместного использования кода с другими пользователями.
Управление моделями: MLflow предоставляет функциональные возможности для управления моделями и версиями. Она поддерживает различные платформы машинного обучения, чтобы вы могли хранить, версии и обслуживать модели.
Обслуживание и развертывание моделей: MLflow интегрирует возможности обслуживания и развертывания моделей, чтобы легко развертывать модели в различных средах.
Регистрация моделей. Вы можете управлять жизненным циклом модели, которая включает управление версиями, переходы этапов и заметки. MLflow можно использовать для поддержания централизованного хранилища моделей в среде совместной работы.
Использование API и пользовательского интерфейса. Внутри Azure MLflow упаковано в Машинное обучение API версии 2, чтобы вы могли взаимодействовать с системой программным способом. Вы можете использовать портал Azure для взаимодействия с пользовательским интерфейсом.
MLflow упрощает и стандартизирует процесс разработки машинного обучения, от экспериментирования до развертывания.
Машинное обучение интегрируется с репозиториями Git, чтобы использовать службы, совместимые с Git, например GitHub, GitLab, Bitbucket, Azure DevOps или другую службу, совместимую с Git. Помимо ресурсов, которые уже отслеживаются в Машинное обучение, ваша команда может разработать собственную таксономию в своей службе, совместимой с Git, для хранения других данных проекта, таких как:
- Документация
- Данные проекта: например, окончательный отчет о проекте
- Отчет о данных: например, словарь данных или отчеты о качестве данных
- Модель: например, отчеты о модели
- Код
- Подготовка данных
- Разработка модели
- Эксплуатация, которая включает безопасность и соответствие требованиям
Инфраструктура и ресурсы
TDSP предоставляет рекомендации по управлению общей аналитикой и инфраструктурой хранилища в следующих категориях:
- Облачные файловые системы для хранения наборов данных
- Облачные базы данных
- Кластеры больших данных, использующие SQL или Spark
- Службы искусственного интеллекта и машинного обучения
Облачные файловые системы для хранения наборов данных
Облачные файловые системы имеют решающее значение для TDSP по нескольким причинам:
Централизованное хранилище данных: облачные файловые системы предоставляют централизованное расположение для хранения наборов данных, что является важным для совместной работы между членами группы обработки и анализа данных. Централизация гарантирует, что все члены команды могут получать доступ к самым текущим данным и снижает риск работы с устаревшими или несогласованными наборами данных.
Масштабируемость: облачные файловые системы могут обрабатывать большие объемы данных, которые часто используются в проектах обработки и анализа данных. Файловые системы предоставляют масштабируемые решения для хранения, которые растут с учетом потребностей проекта. Они позволяют командам хранить и обрабатывать массовые наборы данных, не беспокоясь об ограничениях оборудования.
Специальные возможности. С помощью облачных файловой системы вы можете получить доступ к данным из любого места с подключением к Интернету. Этот доступ важен для распределенных команд или когда участникам команды нужно работать удаленно. Облачные файловые системы упрощают непрерывную совместную работу и обеспечивают доступность данных.
Безопасность и соответствие: поставщики облачных служб часто реализуют надежные меры безопасности, включая шифрование, контроль доступа и соответствие отраслевым стандартам и нормативным требованиям. Строгие меры безопасности могут защитить конфиденциальные данные и помочь вашей команде соответствовать юридическим и нормативным требованиям.
Управление версиями: облачные файловые системы часто включают функции управления версиями, которые команды могут использовать для отслеживания изменений наборов данных с течением времени. Управление версиями имеет решающее значение для поддержания целостности данных и воспроизведения результатов в проектах обработки и анализа данных. Он также помогает выполнять аудит и устранять возникающие проблемы.
Интеграция с инструментами: облачные файловые системы могут легко интегрироваться с различными инструментами и платформами обработки и анализа данных. Интеграция инструментов поддерживает упрощение приема данных, обработку данных и анализ данных. Например, служба хранилища Azure хорошо интегрируются с Машинное обучение, Azure Databricks и другими средствами обработки и анализа данных.
Совместная работа и совместное использование: облачные файловые системы упрощают совместное использование наборов данных с другими участниками команды или заинтересованными лицами. Эти системы поддерживают функции совместной работы, такие как общие папки и управление разрешениями. Функции совместной работы упрощают совместную работу и гарантируют, что нужные люди имеют доступ к нужным данным.
Экономичность: облачные файловые системы могут быть более экономичными, чем обслуживание локальных решений хранилища. Поставщики облачных служб имеют гибкие модели ценообразования, включающие варианты оплаты по мере использования, которые могут помочь управлять затратами на основе фактических требований к использованию и хранилищу проекта обработки и анализа данных.
Аварийное восстановление: облачные файловые системы обычно включают функции резервного копирования данных и аварийного восстановления. Эти функции помогают защитить данные от сбоев оборудования, случайных удалений и других аварий. Он обеспечивает спокойствие и поддерживает непрерывность операций обработки и анализа данных.
Автоматизация и интеграция рабочих процессов. Системы облачного хранилища могут интегрироваться в автоматизированные рабочие процессы, которые позволяют легко передавать данные между различными этапами процесса обработки и анализа данных. Автоматизация может повысить эффективность и сократить необходимые усилия вручную для управления данными.
Рекомендуемые ресурсы Azure для облачных файловых систем
- Хранилище BLOB-объектов Azure — комплексная документация по Хранилище BLOB-объектов Azure, которая является масштабируемой службой хранилища объектов для неструктурированных данных.
- Azure Data Lake Storage — информация о Azure Data Lake Storage 2-го поколения, предназначенная для аналитики больших данных и поддерживает крупномасштабные наборы данных.
- Файлы Azure . Сведения о Файлы Azure, которая предоставляет полностью управляемые общие папки в облаке.
В целом облачные файловые системы важны для TDSP, так как они предоставляют масштабируемые, безопасные и доступные решения для хранения данных, поддерживающие весь жизненный цикл данных. Облачные файловые системы обеспечивают простую интеграцию данных из различных источников, которая поддерживает комплексное получение и понимание данных. Специалисты по обработке и анализу данных могут использовать облачные файловые системы для эффективного хранения, управления и доступа к большим наборам данных. Эта функция необходима для обучения и развертывания моделей машинного обучения. Эти системы также повышают совместную работу, позволяя участникам команды совместно использовать и работать над данными одновременно в единой среде. Облачные файловые системы предоставляют надежные функции безопасности, которые помогают защитить данные и обеспечить соответствие нормативным требованиям, что жизненно важно для обеспечения целостности и доверия данных.
Облачные базы данных
Облачные базы данных играют важную роль в TDSP по нескольким причинам:
Масштабируемость. Облачные базы данных предоставляют масштабируемые решения, которые могут легко расти для удовлетворения растущих потребностей в данных проекта. Масштабируемость важна для проектов обработки и анализа данных, которые часто обрабатывают большие и сложные наборы данных. Облачные базы данных могут обрабатывать различные рабочие нагрузки без необходимости ручного вмешательства или обновления оборудования.
Оптимизация производительности. Разработчики оптимизируют облачные базы данных для повышения производительности с помощью таких возможностей, как автоматическая индексация, оптимизация запросов и балансировка нагрузки. Эти функции помогают обеспечить быстрое и эффективное получение и обработку данных, что крайне важно для задач обработки и анализа данных, требующих доступа к данным в режиме реального времени или почти в реальном времени.
Специальные возможности и совместная работа: Teams может получать доступ к сохраненным данным в облачных базах данных из любого расположения. Эта возможность способствует совместной работе между участниками группы, которые могут быть географически распределены. Специальные возможности и совместная работа важны для распределенных команд или людей, работающих удаленно. Облачные базы данных поддерживают многопользовательские среды, которые обеспечивают одновременный доступ и совместную работу.
Интеграция с инструментами обработки и анализа данных: облачные базы данных легко интегрируются с различными инструментами и платформами обработки и анализа данных. Например, облачные базы данных Azure хорошо интегрируются с Машинное обучение, Power BI и другими средствами аналитики данных. Эта интеграция упрощает конвейер данных, от приема и хранения до анализа и визуализации.
Безопасность и соответствие требованиям. Поставщики облачных служб реализуют надежные меры безопасности, включающие шифрование данных, контроль доступа и соответствие отраслевым стандартам и нормативным требованиям. Меры безопасности защищают конфиденциальные данные и помогают вашей команде соответствовать юридическим и нормативным требованиям. Функции безопасности жизненно важны для поддержания целостности и конфиденциальности данных.
Экономичность. Облачные базы данных часто работают с моделью с оплатой по мере использования, которая может быть более экономичной, чем обслуживание локальных систем баз данных. Эта гибкость ценообразования позволяет организациям эффективно управлять своими бюджетами и платить только за используемые ими ресурсы хранилища и вычислительных ресурсов.
Автоматические резервные копии и аварийное восстановление: облачные базы данных предоставляют решения автоматического резервного копирования и аварийного восстановления. Эти решения помогают предотвратить потерю данных при сбоях оборудования, случайном удалении или других авариях. Надежность имеет решающее значение для обеспечения непрерывности и целостности данных в проектах обработки и анализа данных.
Обработка данных в режиме реального времени: многие облачные базы данных поддерживают обработку и аналитику данных в режиме реального времени, что важно для задач обработки и анализа данных, требующих наиболее актуальной информации. Эта возможность помогает специалистам по обработке и анализу данных принимать своевременные решения на основе последних доступных данных.
Интеграция данных. Облачные базы данных могут легко интегрироваться с другими источниками данных, базами данных, озерами данных и внешними веб-каналами данных. Интеграция помогает специалистам по обработке и анализу данных объединить данные из нескольких источников и обеспечить комплексное представление и более сложный анализ.
Гибкость и разнообразие. Облачные базы данных доступны в различных формах, таких как реляционные базы данных, базы данных NoSQL и хранилища данных. Это разнообразие позволяет командам по обработке и анализу данных выбирать лучший тип базы данных для конкретных потребностей, требовать ли они структурированного хранилища данных, неструктурированной обработки данных или крупномасштабной аналитики данных.
Поддержка расширенной аналитики: облачные базы данных часто поддерживают встроенную поддержку расширенной аналитики и машинного обучения. Например, База данных SQL Azure предоставляет встроенные службы машинного обучения. Эти службы помогают специалистам по обработке и анализу данных выполнять расширенную аналитику непосредственно в среде базы данных.
Рекомендуемые ресурсы Azure для облачных баз данных
- База данных SQL Azure — документация по База данных SQL Azure, полностью управляемая служба реляционной базы данных.
- Azure Cosmos DB — сведения о Azure Cosmos DB , глобально распределенной службе баз данных с несколькими моделями.
- База данных Azure для PostgreSQL. Руководство по База данных Azure для PostgreSQL, управляемой службе баз данных для разработки и развертывания приложений.
- База данных Azure для MySQL . Сведения о База данных Azure для MySQL, управляемой службе для баз данных MySQL.
В итоге облачные базы данных важны для TDSP, так как они предоставляют масштабируемые, надежные и эффективные решения для хранения и управления данными, поддерживающие проекты, управляемые данными. Они упрощают простую интеграцию данных, которая помогает специалистам по обработке и обработке и анализу больших наборов данных из различных источников. Облачные базы данных позволяют быстро запрашивать и обрабатывать данные, что важно для разработки, тестирования и развертывания моделей машинного обучения. Кроме того, облачные базы данных повышают совместную работу, предоставляя централизованную платформу для доступа к данным и работы с ними. Наконец, облачные базы данных предоставляют расширенные функции безопасности и поддержку соответствия требованиям для обеспечения защиты данных и соответствия нормативным стандартам, что крайне важно для обеспечения целостности и доверия данных.
Кластеры больших данных, использующие SQL или Spark
Кластеры больших данных, например те, которые используют SQL или Spark, являются основными для TDSP по нескольким причинам:
Обработка больших объемов данных: кластеры больших данных предназначены для эффективной обработки больших объемов данных. Проекты по обработке и анализу данных часто включают массовые наборы данных, превышающие емкость традиционных баз данных. Кластеры больших данных на основе SQL и Spark могут управлять и обрабатывать эти данные в большом масштабе.
Распределенные вычисления: кластеры больших данных используют распределенные вычисления для распространения данных и вычислительных задач на нескольких узлах. Возможность параллельной обработки значительно ускоряет задачи обработки и анализа данных, что является важным для получения своевременной аналитики в проектах обработки и анализа данных.
Масштабируемость: кластеры больших данных обеспечивают высокую масштабируемость, как по горизонтали, так и путем добавления дополнительных узлов и вертикального увеличения мощности существующих узлов. Масштабируемость помогает обеспечить рост инфраструктуры данных с учетом потребностей проекта, обрабатывая увеличение размера данных и сложность.
Интеграция с инструментами обработки и анализа данных: кластеры больших данных хорошо интегрируются с различными инструментами и платформами обработки и анализа данных. Например, Spark легко интегрируется с Hadoop, а кластеры SQL работают с различными средствами анализа данных. Интеграция упрощает гладкий рабочий процесс приема данных до анализа и визуализации.
Расширенная аналитика: кластеры больших данных поддерживают расширенную аналитику и машинное обучение. Например, Spark предоставляет следующие встроенные библиотеки:
- Машинное обучение, MLlib
- Обработка графов, GraphX
- Потоковая обработка, потоковая передача Spark
Эти возможности помогают специалистам по обработке и анализу данных выполнять сложную аналитику непосредственно в кластере.
Обработка данных в режиме реального времени: кластеры больших данных, особенно те, которые используют Spark, поддерживают обработку данных в режиме реального времени. Эта возможность имеет решающее значение для проектов, требующих до минутного анализа данных и принятия решений. Обработка в режиме реального времени помогает в таких сценариях, как обнаружение мошенничества, рекомендации в режиме реального времени и динамические цены.
Преобразование данных и извлечение, преобразование, загрузка (ETL): кластеры больших данных идеально подходят для преобразований данных и процессов ETL. Они могут эффективно обрабатывать сложные преобразования данных, очистку и агрегирование задач, которые часто необходимы перед анализом данных.
Экономичность. Кластеры больших данных могут быть экономически эффективными, особенно при использовании облачных решений, таких как Azure Databricks и другие облачные службы. Эти службы предоставляют гибкие модели ценообразования, которые включают оплату по мере использования, что может быть более экономичным, чем обслуживание локальной инфраструктуры больших данных.
Отказоустойчивость: кластеры больших данных разработаны с учетом отказоустойчивости. Они реплицируют данные между узлами, чтобы обеспечить работу системы, даже если некоторые узлы завершаются ошибкой. Эта надежность важна для обеспечения целостности и доступности данных в проектах обработки и анализа данных.
Интеграция озера данных: кластеры больших данных часто интегрируются без проблем с озерами данных, что позволяет специалистам по обработке и анализу различных источников данных получить единый доступ к различным источникам данных. Интеграция способствует более комплексному анализу путем поддержки сочетания структурированных и неструктурированных данных.
Обработка на основе SQL: для специалистов по обработке и анализу данных, знакомых с SQL, кластерами больших данных, которые работают с SQL-запросами, такими как Spark SQL или SQL в Hadoop, предоставляют знакомый интерфейс для запроса и анализа больших данных. Эта простота использования может ускорить процесс анализа и сделать его более доступным для более широкого круга пользователей.
Совместная работа и совместное использование. Кластеры больших данных поддерживают среды совместной работы, в которых несколько специалистов по обработке и анализу данных могут работать вместе с теми же наборами данных. Они предоставляют функции для совместного использования кода, записных книжек и результатов, которые способствуют совместной работе и обмену знаниями.
Безопасность и соответствие. Кластеры больших данных обеспечивают надежные функции безопасности, такие как шифрование данных, управление доступом и соответствие отраслевым стандартам. Функции безопасности защищают конфиденциальные данные и помогают вашей команде соответствовать нормативным требованиям.
Рекомендуемые ресурсы Azure для кластеров больших данных
- Apache Spark в Машинное обучение: интеграция Машинное обучение с Azure Synapse Analytics обеспечивает простой доступ к распределенным вычислительным ресурсам через платформу Apache Spark.
- Azure Synapse Analytics: комплексная документация по Azure Synapse Analytics, которая интегрирует большие данные и хранилище данных.
В итоге кластеры больших данных, будь то SQL или Spark, имеют решающее значение для TDSP, так как они обеспечивают вычислительные мощности и масштабируемость, необходимые для эффективной обработки огромных объемов данных. Кластеры больших данных позволяют специалистам по обработке и анализу данных выполнять сложные запросы и расширенную аналитику больших наборов данных, которые упрощают глубокое понимание и точную разработку моделей. При использовании распределенных вычислений эти кластеры обеспечивают быструю обработку и анализ данных, что ускоряет общий рабочий процесс обработки и анализа данных. Кластеры больших данных также поддерживают простую интеграцию с различными источниками данных и инструментами, что повышает возможность приема, обработки и анализа данных из нескольких сред. Кластеры больших данных также способствуют совместной работе и воспроизведению, предоставляя единую платформу, в которой команды могут эффективно обмениваться ресурсами, рабочими процессами и результатами.
ИИ и службы машинного обучения
Службы искусственного интеллекта и машинного обучения являются неотъемлемой частью TDSP по нескольким причинам:
Расширенная аналитика: службы искусственного интеллекта и машинного обучения обеспечивают расширенную аналитику. Специалисты по обработке и анализу данных могут использовать расширенную аналитику для выявления сложных шаблонов, создания прогнозов и создания аналитических сведений, которые недоступны в традиционных аналитических методах. Эти расширенные возможности важны для создания решений для обработки и анализа данных с высоким уровнем влияния.
Автоматизация повторяющихся задач: службы искусственного интеллекта и машинного обучения могут автоматизировать повторяющиеся задачи, такие как очистка данных, проектирование функций и обучение модели. Автоматизация экономит время и помогает специалистам по обработке и анализу данных сосредоточиться на более стратегических аспектах проекта, что повышает общую производительность.
Улучшенная точность и производительность: модели машинного обучения могут повысить точность и производительность прогнозов и анализов путем обучения на основе данных. Эти модели могут постоянно улучшаться по мере того, как они становятся подвержены большим данным, что приводит к улучшению принятия решений и более надежным результатам.
Масштабируемость: службы искусственного интеллекта и машинного обучения, предоставляемые облачными платформами, такими как Машинное обучение, являются высокомасштабируемыми. Они могут обрабатывать большие объемы данных и сложных вычислений, которые помогают командам обработки и анализа данных масштабировать свои решения в соответствии с растущими требованиями, не беспокоясь об ограничениях базовой инфраструктуры.
Интеграция с другими инструментами: службы искусственного интеллекта и машинного обучения легко интегрируются с другими инструментами и службами в экосистеме Майкрософт, такими как Azure Data Lake, Azure Databricks и Power BI. Интеграция поддерживает упрощенный рабочий процесс от приема и обработки данных до развертывания и визуализации модели.
Развертывание и управление моделями: службы ИИ и машинного обучения предоставляют надежные средства для развертывания моделей машинного обучения и управления ими в рабочей среде. Такие функции, как управление версиями, мониторинг и автоматическое переобучение, помогают гарантировать, что модели остаются точными и эффективными с течением времени. Этот подход упрощает обслуживание решений машинного обучения.
Обработка в режиме реального времени: службы искусственного интеллекта и машинного обучения поддерживают обработку и принятие решений в режиме реального времени. Обработка в режиме реального времени необходима для приложений, требующих немедленной аналитики и действий, таких как обнаружение мошенничества, динамическое ценообразование и системы рекомендаций.
Настраиваемость и гибкость: службы искусственного интеллекта и машинного обучения предоставляют ряд настраиваемых параметров, от предварительно созданных моделей и API до платформ для создания пользовательских моделей с нуля. Эта гибкость помогает группам обработки и анализа данных адаптировать решения для конкретных бизнес-потребностей и вариантов использования.
Доступ к передовым алгоритмам: службы искусственного интеллекта и машинного обучения предоставляют специалистам по обработке и анализу данных доступ к передовым алгоритмам и технологиям, разработанным ведущими исследователями. Access гарантирует, что команда может использовать последние достижения в искусственном интеллекте и машинном обучении для своих проектов.
Совместная работа и совместное использование: платформы искусственного интеллекта и машинного обучения поддерживают среды совместной разработки, в которых несколько участников команды могут совместно работать над тем же проектом, совместно использовать код и воспроизводить эксперименты. Совместная работа улучшает совместную работу и помогает обеспечить согласованность в разработке моделей.
Экономичность: службы искусственного интеллекта и машинного обучения в облаке могут быть более экономичными, чем создание и обслуживание локальных решений. Поставщики облачных служб имеют гибкие модели ценообразования, включающие варианты оплаты по мере использования, которые могут снизить затраты и оптимизировать использование ресурсов.
Улучшенная безопасность и соответствие требованиям: службы искусственного интеллекта и машинного обучения обеспечивают надежные функции безопасности, включая шифрование данных, безопасный контроль доступа и соответствие отраслевым стандартам и нормативным требованиям. Эти функции помогают защитить данные и модели и соответствовать юридическим и нормативным требованиям.
Предварительно созданные модели и API: многие службы ИИ и машинного обучения предоставляют предварительно созданные модели и API для распространенных задач, таких как обработка естественного языка, распознавание изображений и обнаружение аномалий. Предварительно созданные решения могут ускорить разработку и развертывание и помочь командам быстро интегрировать возможности искусственного интеллекта в свои приложения.
Экспериментирование и прототипирование: платформы искусственного интеллекта и машинного обучения предоставляют среды для быстрого экспериментирования и прототипирования. Специалисты по обработке и анализу данных могут быстро протестировать различные алгоритмы, параметры и наборы данных, чтобы найти оптимальное решение. Экспериментирование и прототипирование поддерживают итеративный подход к разработке моделей.
Рекомендуемые ресурсы Azure для служб искусственного интеллекта и машинного обучения
Машинное обучение — это основной ресурс, который мы рекомендуем использовать для приложения для обработки и анализа данных и TDSP. Кроме того, Azure предоставляет службы ИИ, которые имеют готовые модели ИИ для конкретных приложений.
- Машинное обучение: основная страница документации для Машинное обучение, которая охватывает настройку, обучение модели, развертывание и т. д.
- Службы ИИ Azure: сведения о службах ИИ, которые предоставляют предварительно созданные модели ИИ для задач визуального распознавания, речи, языка и принятия решений.
В итоге службы ИИ и МАШИН имеют решающее значение для TDSP, так как они предоставляют мощные инструменты и платформы, упрощающие разработку, обучение и развертывание моделей машинного обучения. Эти службы автоматизируют сложные задачи, такие как выбор алгоритма и настройка гиперпараметров, что значительно ускоряет процесс разработки модели. Эти службы также предоставляют масштабируемую инфраструктуру, которая помогает специалистам по обработке и анализу данных эффективно обрабатывать большие наборы данных и вычислительные задачи. Средства искусственного интеллекта и машинного обучения легко интегрируются с другими службами Azure и улучшают прием данных, предварительную обработку и развертывание модели. Интеграция помогает обеспечить комплексный рабочий процесс. Кроме того, эти службы способствуют совместной работе и воспроизведению. Teams могут обмениваться аналитическими сведениями и эффективно экспериментировать с результатами и моделями, сохраняя высокие стандарты безопасности и соответствия требованиям.
Ответственное применение ИИ
С помощью решений искусственного интеллекта или машинного обучения корпорация Майкрософт продвигает ответственные средства искусственного интеллекта в своих решениях ИИ и машинного обучения. Эти средства поддерживают стандарт Microsoft Responsible AI Standard. Рабочая нагрузка по-прежнему должна по отдельности решать вред, связанный с ИИ.
Одноранговые ссылки
TDSP — это хорошо установленная методология, используемая командами в рамках взаимодействия Майкрософт. TDSP документируется и изучается в одноранговой литературе. Ссылки предоставляют возможность исследовать функции и приложения TDSP. Дополнительные сведения и список ссылок см. в разделе жизненный цикл TDSP.