Этап моделирования в жизненном цикле процесса обработки и анализа данных группы
В этой статье описаны цели, задачи и конечные результаты, связанные с этапом моделирования процесса обработки и анализа данных группы (TDSP). Этот процесс предоставляет рекомендуемый жизненный цикл, который ваша команда может использовать для структуры проектов обработки и анализа данных. Жизненный цикл описывает основные этапы, которые выполняет ваша команда, часто итеративно:
- Коммерческий аспект.
- Получение и анализ данных.
- Моделирование
- Развертывание
- Прием клиентом.
Ниже приведено визуальное представление жизненного цикла TDSP:
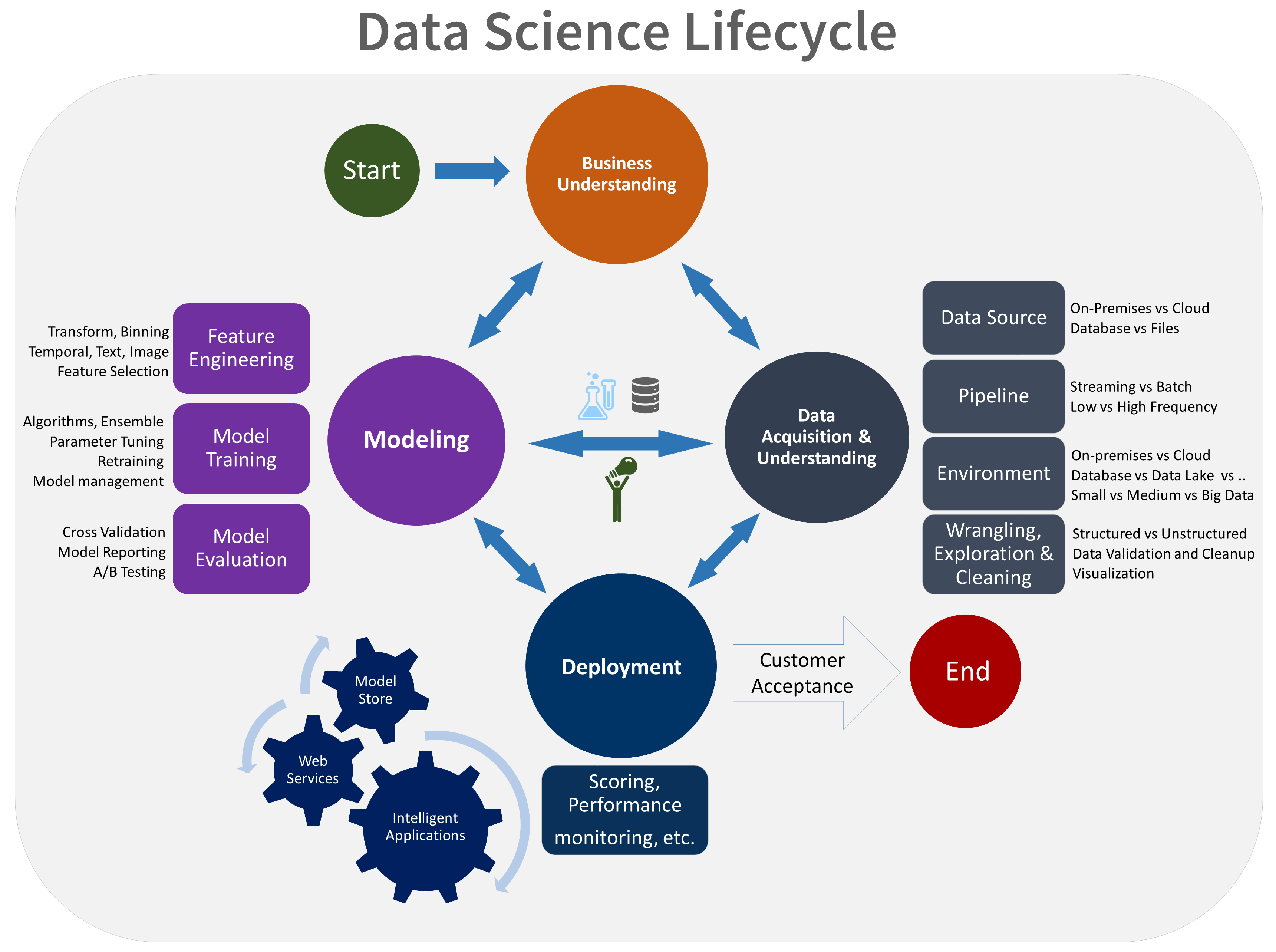
Цели
Целями этапа моделирования являются следующие задачи:
Определите оптимальные функции данных для модели машинного обучения.
Создайте информативную модель машинного обучения, которая прогнозирует целевой объект наиболее точно.
Создайте модель машинного обучения, подходящую для рабочей среды.
Как выполнить задачи
Этап моделирования состоит из трех основных задач:
Проектирование признаков. Создайте характеристики данных на основе необработанных данных, чтобы упростить обучение модели.
Обучение модели. Поиск модели, которая наиболее точно отвечает на вопрос, сравнивая метрики успеха моделей.
Оценка модели. Определите, подходит ли ваша модель для рабочей среды.
Проектирование признаков
Проектирование признаков включает учет, статистическую обработку и преобразование необработанных переменных для создания характеристик, используемых в анализе. Если вы хотите получить представление о том, как создается модель, необходимо изучить базовые функции модели.
На этом этапе требуется творческое сочетание опыта и информации, полученной на этапе исследования данных. Проектирование признаков — это балансирующий акт поиска и включения информативных переменных, но в то же время пытается избежать слишком большого количества несвязанных переменных. Информативные переменные улучшают результат. Несвязанные переменные вводят ненужный шум в модель. При создании признаков нужно учитывать все новые данные, полученные во время оценки. В результате создание признаков может основываться только на данных, доступных во время оценки.
Обучение модели
Существует множество алгоритмов моделирования, которые можно использовать в зависимости от типа вопроса, который вы пытаетесь ответить. Рекомендации по выбору предварительно созданного алгоритма см. в Машинное обучение памятку по алгоритму для конструктора Машинное обучение Azure. Другие алгоритмы доступны через пакеты с открытым кодом в R или Python. Хотя в этой статье основное внимание уделяется Машинное обучение Azure, рекомендации, которые она предоставляет для многих проектов машинного обучения.
Процесс обучения модели включает следующие шаги:
Разделите входные данные для моделирования случайным образом на два набора данных: для обучения и для тестирования.
Создайте модель с помощью набора данных для обучения.
Оцените набор данных для обучения и тестирования. Используйте ряд конкурирующих алгоритмов машинного обучения. Используйте различные связанные параметры настройки (известные как очистки параметров), которые предназначены для ответа на интересующие вопросы с текущими данными.
Определите лучшее решение для ответа на вопрос, сравнивая метрики успеха между альтернативными методами.
Дополнительные сведения см. в разделе "Обучение моделей с помощью Машинное обучение".
Примечание.
Избегайте утечки: вы можете вызвать утечку данных, если вы включаете данные извне обучающего набора данных, что позволяет модели или алгоритму машинного обучения сделать нереалистично хорошие прогнозы. Именно риск утечки заставляет волноваться специалистов по обработке и анализу данных, когда полученные ими прогнозы являются слишком хорошими, чтобы быть правдой. Эти зависимости могут быть трудно обнаружить. Для предотвращения утечки часто требуется итерацию между созданием набора данных анализа, созданием модели и оценкой точности результатов.
Оценка модели
После обучения модели специалист по обработке и анализу данных в вашей команде фокусируется на оценке модели.
Определите, выполняется ли модель достаточно для рабочей среды. Здесь нужно ответить на такие вопросы.
Отвечает ли модель на поставленный вопрос по тестовым данным достаточно надежно?
Не нужно ли рассмотреть альтернативные решения,
Следует ли собирать больше данных, делать больше функций или экспериментировать с другими алгоритмами?
Интерпретация модели. Используйте пакет SDK для Python Машинное обучение для выполнения следующих задач:
Пояснение принципов работы всей модели и отдельных прогнозов на локальном персональном компьютере.
Задействование приемов интерпретации для сконструированных признаков.
Пояснение принципов работы всей модели и отдельных прогнозов в Azure.
Отправьте объяснения в журнал выполнения Машинное обучение.
Используйте панель мониторинга визуализации для взаимодействия с объяснениями модели как в записной книжке Jupyter, так и в рабочей области Машинное обучение.
Развертывание блока пояснения оценки вместе с моделью для отслеживания пояснений во время ее работы.
Оценка справедливости: используйте пакет Python с открытым кодом fairlearn с Машинное обучение для выполнения следующих задач:
Оценка справедливости прогнозов модели. Этот процесс помогает вашей команде узнать больше о справедливости в машинном обучении.
Отправка, перечисление и скачивание аналитических сведений об оценке справедливости в Машинное обучение studio и из нее.
Просмотрите панель мониторинга оценки справедливости в Машинное обучение студии, чтобы взаимодействовать с аналитикой справедливости моделей.
Интеграция с MLflow
Машинное обучение интегрируется с MLflow для поддержки жизненного цикла моделирования. Он использует отслеживание MLflow для экспериментов, развертывания проектов, управления моделями и реестра моделей. Эта интеграция обеспечивает простой и эффективный рабочий процесс машинного обучения. Следующие функции в Машинное обучение помогают поддерживать этот элемент жизненного цикла моделирования:
Отслеживание экспериментов: основные функциональные возможности MLflow широко используются на этапе моделирования для отслеживания различных экспериментов, параметров, метрик и артефактов.
Развертывание проектов. Упаковка кода с помощью проектов MLflow обеспечивает согласованный запуск и простой обмен данными между участниками команды, что является важным во время разработки итеративной модели.
Управление моделями: управление и управление моделями управления версиями имеет решающее значение на этом этапе, так как различные модели создаются, оцениваются и уточнены.
Регистрация моделей: реестр моделей используется для управления версиями и управления моделями на протяжении всего жизненного цикла.
Одноранговая литература
Исследователи публикуют исследования о TDSP в одноранговой литературе. Ссылки предоставляют возможность исследовать другие приложения или аналогичные идеи TDSP, включая этап жизненного цикла моделирования.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Автор субъекта:
- Марк Табладильо | Старший архитектор облачных решений
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Связанные ресурсы
В этих статьях описаны другие этапы жизненного цикла TDSP: