Перенос Базы данных SQL Azure из модели на основе единиц DTU в модель на основе виртуальных ядер
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
В этой статье описывается перенос вашей базы данных в Базу данных SQL Azure из модели приобретения на основе единиц DTU в модель приобретения на основе виртуальных ядер.
Перенос базы данных
Перенос базы данных из модели приобретения на основе единиц DTU в модель приобретения на основе виртуальных ядер аналогична масштабированию между целями службы на уровнях служб "Базовый", "Стандартный" и "Премиум", с одинаковой длительностью и минимальным временем простоя в конце переноса. База данных, перенесенная в модель приобретения на основе виртуальных ядер, может быть перенесена обратно в модель приобретения на основе DTU в любой момент, используя те же действия, за исключением баз данных, перенесенных на уровень служб Гипермасштабирования .
Базу данных можно перенести в другую модель приобретения с помощью портал Azure, PowerShell, Azure CLI и Transact-SQL.
Чтобы перенести базу данных в другую модель приобретения с помощью портал Azure, выполните следующие действия.
Перейдите в базу данных SQL в портал Azure.
Выберите вычисление и хранилище в Параметры.
Используйте раскрывающийся список в разделе "Уровень служб", чтобы выбрать новую модель приобретения и уровень служб:
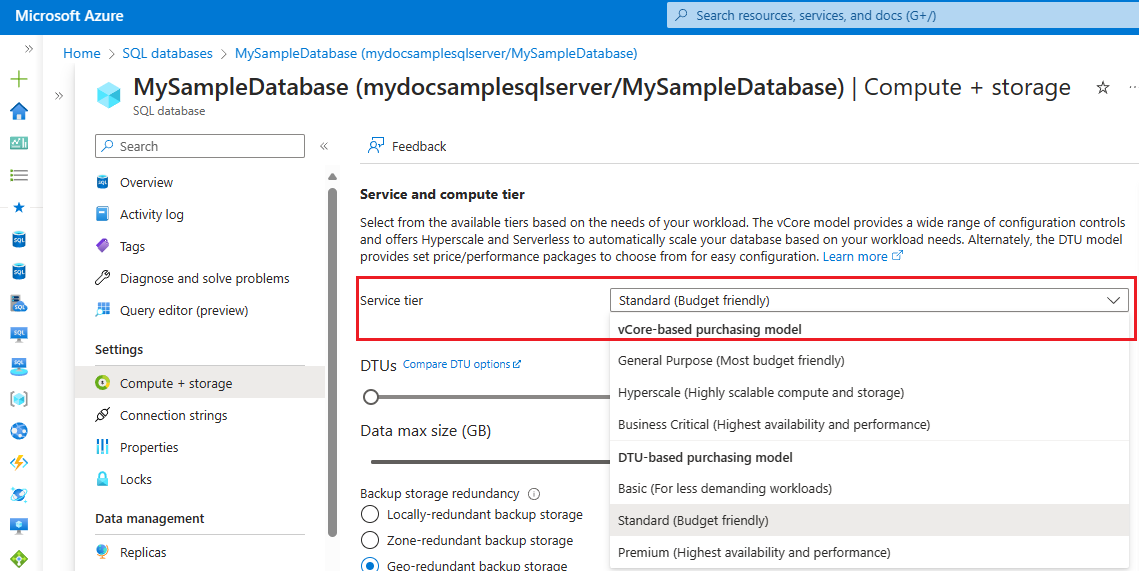

Выбор уровня службы "Виртуальное ядро" и объекта службы
Большинство сценариев, баз данных и эластичных пулов на уровнях служб "Базовый" и "Стандартный" в рамках переноса модели DTU в модель виртуального ядра будут сопоставляться с уровнем служб Общее назначение. Базы данных и эластичные пулы на уровне служб "Премиум" будут сопоставляться с уровнем служб Критически важный для бизнеса. В зависимости от сценария и требований приложения уровень служб гипермасштабирования часто можно использовать в качестве целевого объекта миграции для баз данных и эластичных пулов во всех уровнях служб DTU.
Чтобы выбрать цели службы или объем вычислительных ресурсов для перенесенной базы данных в модели виртуального ядра, можно использовать простое, но приближенное правило: каждые 100 DTU на уровнях "Базовый" или "Стандартный" требуется по крайней мере 1 виртуальное ядро, а для каждых 125 DTU на уровне "Премиум" требуется по крайней мере 1 виртуальное ядро.
Совет
Это правило является приблизительным, поскольку оно не учитывает конкретный тип оборудования, используемого для базы данных DTU или эластичного пула.
В модели на основе DTU система может выбрать любую доступную конфигурацию оборудования для базы данных или эластичного пула. Таким образом, в модели на основе DTU вы можете получить только непрямое регулирование количества виртуальных ядер (логических центральных процессоров (ЦП)), выбрав более высокие или более низкие значения DTU или eDTU.
При использовании модели на основе виртуальных ядер клиентам необходимо явно выбрать как конфигурацию оборудования, так и число виртуальных ядер (логических ЦП). Хотя модель на основе DTU не предоставляет эти варианты выбора, тип оборудования и количество логических ЦП, используемых для каждой базы данных и эластичного пула, предоставляются через динамические административные представления. Это позволяет точнее определить соответствующую цель службы виртуального ядра.
В следующем подходе используются эта информация, чтобы определить цель службы виртуального ядра с аналогичным выделением ресурсов, чтобы получить такой же уровень производительности после переноса в модель виртуального ядра.
Сопоставление DTU с виртуальным ядром
Следующий запрос T-SQL, выполняемый в контексте переносимой базы данных на основе DTU, будет возвращать соответствующее (возможно, дробное) количество виртуальных ядер в каждой конфигурации оборудования в модели на основе виртуальных ядер. Вы можете округить это число до ближайшего числа виртуальных ядер, доступных для баз данных и эластичных пулов в каждой конфигурации оборудования в модели виртуальных ядер, клиенты могут выбрать цель службы виртуальных ядер, которая является ближайшим совпадением для базы данных DTU или эластичного пула.
Примеры сценариев переноса с использованием этого подхода приведены в разделе Примеры.
Выполните этот запрос в контексте переносимой базы данных, а не в базе данных master. При переносе эластичного пула выполните запрос в контексте любой базы данных в пуле.
WITH dtu_vcore_map AS
(
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS nvarchar(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu/100. AS decimal(3,2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS decimal(4,2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (SELECT COUNT(1) AS scheduler_count FROM sys.dm_os_schedulers WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE') AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (
SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name
) slo
WHERE rg.dtu_limit > 0
AND
DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND
rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
Дополнительные факторы
Помимо количества виртуальных ядер (логических ЦП) и типа оборудования, некоторые другие факторы могут повлиять на выбор цели службы виртуального ядра:
- Запрос Transact-SQL сопоставления соответствует целям службы DTU и виртуального ядра с учетом их емкости ЦП, поэтому результаты будут более точными для рабочих нагрузок, привязанных к ЦП.
- Для того же типа оборудования и того же количества виртуальных ядер ограничения ресурсов пропускной способности IOPS и журнала транзакций для баз данных виртуальных ядер часто выше, чем для баз данных DTU. Для достижения того же уровня производительности для рабочих нагрузок с привязкой к вводу-выводу можно уменьшить количество виртуальных ядер в модели виртуальных ядер. Фактические ограничения ресурсов для баз данных на основе DTU и виртуальных ядер показаны в представлении sys.dm_user_db_resource_governance. Сравнение этих значений между переносимым пулом или базой данных на основе DTU и пулом или базой данных на основе виртуального ядра с использованием приблизительно совпадающего целевого уровня обслуживания поможет более точно выбрать этот уровень для виртуального ядра.
- Запрос сопоставления также возвращает объем памяти, используемый одним ядром, для переносимой базы данных DTU или переносимого эластичного пула и для каждой конфигурации оборудования в модели виртуального ядра. Обеспечение аналогичного или большего общего объема памяти после переноса на виртуальное ядро важно для рабочих нагрузок, требующих кэш данных большого объема памяти, чтобы достичь достаточной производительности, или рабочих нагрузок, требующих большого объема памяти для обработки запросов. Для таких рабочих нагрузок, в зависимости от фактической производительности, может потребоваться увеличение количества виртуальных ядер, чтобы получить достаточный общий объем памяти.
- При выборе цели службы виртуального ядра следует учитывать хронологию использования ресурсов в базе данных DTU. Для баз данных DTU с постоянным малым уровнем использования ресурсов ЦП может потребоваться меньше виртуальных ядер, чем число, возвращаемое запросом сопоставления. Напротив, базы данных DTU, в которых высокая постоянная загрузка ЦП приводит к недостаточной производительности при рабочей нагрузке, могут потребовать больше виртуальных ядер, чем возвращает запрос.
- При переносе баз данных с временными или прерывистыми шаблонами использования рекомендуется использование бессерверного уровня вычислений. Обратите внимание, что максимальное число одновременных рабочих ролей в бессерверной конфигурации составляет 75 % от предела в подготовленных вычислительных ресурсах для того же максимального числа настроенных виртуальных ядер. Также максимальный объем доступной памяти в бессерверной конфигурации составляет 3 ГБ, умноженные на настроенное максимальное число виртуальных ядер, что меньше предоставляемой на каждое ядро памяти для подготовленных вычислений. Например, для поколения 5 максимальный объем памяти в бессерверной конфигурации составит 120 ГБ, если настроено ограничение в 40 виртуальных ядер, а для подготовленных вычислений при 40 виртуальных ядрах это значение составит 204 ГБ.
- В модели виртуального ядра максимальный поддерживаемый размер базы данных может отличаться в зависимости от оборудования. Для больших баз данных проверьте поддерживаемые максимальные объемы в модели виртуального ядра для отдельных баз данных и эластичных пулов.
- Для эластичных пулов модели DTU и виртуального ядра различаются по максимальному поддерживаемому количеству баз данных на один пул. Это следует учитывать при переносе эластичных пулов с большим количеством баз данных.
- Некоторые конфигурации оборудования могут быть недоступны в каждом регионе. Проверьте доступность в разделе "Конфигурация оборудования для Базы данных SQL".
Внимание
Приведенные выше рекомендации по изменению DTU и виртуального ядра, чтобы помочь в первоначальной оценке цели службы целевой базы данных.
Оптимальная конфигурация целевой базы данных зависит от рабочей нагрузки. Таким образом, для достижения оптимального соотношения цены и производительности после миграции может потребоваться гибко применить модель на основе виртуальных ядер и правильно скорректировать число виртуальных ядер, конфигурацию оборудования, уровни службы и вычислений. Возможно, также потребуется настроить параметры конфигурации базы данных, например максимальную степень параллелизма и (или) изменить уровень совместимости для включения недавних улучшений ядра СУБД.
Примеры переноса DTU на виртуальное ядро
Примечание.
Значения в примерах ниже приведены только для информации. Фактические значения, возвращаемые в описанных сценариях, могут отличаться.
Перенос стандартной базы данных S9
Запрос сопоставления возвращает следующий результат (некоторые столбцы, не показанные для наглядности):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 24.00 | 5,40 | 24.000 | 5,05 |
Мы видим, что стандартная база данных DTU имеет 24 логических ЦП (виртуальные ядра) с 5,4 ГБ памяти на виртуальное ядро. Прямое сопоставление с этим является базой данных общего назначения 2 виртуальных ядер на оборудовании стандартной серии (5-го поколения), цель службы GP_Gen5_24 виртуальных ядер.
Перенос стандартной базы данных S0
Запрос сопоставления возвращает следующий результат (некоторые столбцы, не показанные для наглядности):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 0.25 | 1,3 | 0,500 | 5,05 |
Мы видим, что база данных DTU имеет эквивалент 0,25 логических ЦП (виртуальных ядер) с 1,3 ГБ памяти на виртуальное ядро. Наименьшие цели службы виртуальных ядер в конфигурации оборудования стандартной серии (5-го поколения) GP_Gen5_2 предоставляют больше вычислительных ресурсов, чем база данных Standard S0, поэтому прямое соответствие невозможно. Вариант GP_Gen5_2 предпочтителен. Кроме того, если рабочая нагрузка хорошо подходит для бессерверного уровня вычислений, отличного от GP_S_Gen5_1, сопоставление будет более близким.
Перенос базы данных Премиум p15
Запрос сопоставления возвращает следующий результат (некоторые столбцы, не показанные для наглядности):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 42.00 | 4,86 | 42.000 | 5,05 |
Мы видим, что база данных DTU имеет 42 логических ЦП (виртуальные ядра) с 4,86 ГБ памяти на виртуальное ядро. Хотя цель службы виртуальных ядер не имеет 42 ядер, цель службы BC_Gen5_40 почти эквивалентна с точки зрения емкости ЦП и памяти и является хорошим совпадением.
Перенос эластичного пула 200 eDTU базового уровня
Запрос сопоставления возвращает следующий результат (некоторые столбцы, не показанные для наглядности):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 4,00 | 5,40 | 4.000 | 5,05 |
Мы видим, что эластичные пулы DTU имеют 4 логических ЦП (виртуальные ядра) с 5,4 ГБ памяти на каждое виртуальное ядро. Аппаратные вызовы стандартной серии для 4 виртуальных ядер, однако эта цель службы поддерживает не более 200 баз данных на пул, а эластичные пулы EDTU уровня "Базовый" 200 поддерживают до 500 баз данных. Если переносимый эластичный пул содержит более 200 баз данных, соответствующей целью службы виртуального ядра должно быть GP_Gen5_6 с поддержкой до 500 баз данных.
Перенос геореплицируемых баз данных
Миграция из модели на основе DTU в модель приобретения на основе виртуальных ядер аналогична обновлению или понижению связей гео-реплика tion между базами данных на уровнях служб "Стандартный" и "Премиум". Во время переноса не нужно прекращать репликацию, но необходимо соблюдать следующие правила виртуализации:
- При повышении сначала повысьте уровень производительности базы данных-получателя, а затем — уровень базы данных-источника.
- При понижении следует действовать в обратном порядке: сначала нужно понизить уровень производительности базы данных-источника, а после этого — базы данных-получателя.
При использовании георепликации между двумя эластичными пулами рекомендуем указать один пул в качестве сервера-источника, а другой — в качестве сервера-получателя. В этом случае при переносе эластичных пулов следует использовать те же рекомендации по синхронизации. Однако если у вас присутствуют эластичные пулы, которые содержат как базу данных-источник, так и базу данных-получатель, рассматривайте пул с более высоким уровнем использования в качестве сервера-источника и следуйте соответствующим правилам.
В следующей таблице приведены рекомендации для конкретных сценариев переноса:
| Текущий уровень служб | Целевой уровень служб | Тип переноса | Действия пользователя |
|---|---|---|---|
| Стандартные | Общего назначения | Перемещение | Можно выполнять перенос в любом порядке, необходимо только обеспечить соответствующий размер виртуального ядра*, как указано выше |
| Premium | Критически важный для бизнеса | Перемещение | Можно выполнять перенос в любом порядке, необходимо только обеспечить соответствующий размер виртуального ядра*, как указано выше |
| Стандартные | Критически важный для бизнеса | Обновление | Сначала необходимо перенести базу данных-получатель |
| Критически важный для бизнеса | Стандартные | Понижение уровня | Сначала необходимо перенести базу данных-источник |
| Premium | Общее назначение | Понижение уровня | Сначала необходимо перенести базу данных-источник |
| Общего назначения | Premium | Обновление | Сначала необходимо перенести базу данных-получатель |
| Критически важный для бизнеса | Общего назначения | Понижение уровня | Сначала необходимо перенести базу данных-источник |
| Общее назначение | Критически важный для бизнеса | Обновление | Сначала необходимо перенести базу данных-получатель |
Перенос групп отработки отказа
Перемещение групп отработки отказа с несколькими базами данных требует отдельного перемещения базы данных-источника и базы данных-получателя. Во время этого процесса применяются те же рекомендации и правила последовательности. После преобразования баз данных в модель на основе виртуальных ядер в группе отработки отказа останутся в действии те же параметры политики.
Создание базы данных-получателя георепликации
Базу данных-получателя георепликации (вторичная геореплика) можно создать только с помощью того же уровня служб, который использовался для базы данных-источника. Для баз данных с высокой частотой создания журналов рекомендуется создать вторичную геореплику с тем же объем вычислительных ресурсов, что и у баз данных-источника.
Если вы создаете вторичная геореплику в эластичном пуле для отдельной базы данных-источника, убедитесь, что параметр maxVCore для пула соответствует объему вычислительных ресурсов базы данных-источника. При создании вторичной геореплики для базы данных-источника в другом эластичном пуле рекомендуется настроить для пулов одинаковые параметры maxVCore.
Копирование базы данных для переноса модели DTU в модель виртуального ядра
Копия базы данных создает транзакционно согласованный моментальный снимок данных в момент времени после запуска операции копирования. После этой точки данные между исходной и целевой базами данных не синхронизируются.
Вы можете скопировать любую базу данных с объемом вычислительных ресурсов на основе DTU в базу данных с размером вычислительных ресурсов на основе виртуальных ядер с помощью PowerShell, Azure CLI или Transact-SQL без ограничений или специальных последовательностей, если целевой размер вычислительных ресурсов поддерживает максимальный размер базы данных-источника. Копирование базы данных на другой уровень служб не поддерживается в портал Azure.
Следующие шаги
- Дополнительные сведения о конкретных объемах вычислительных ресурсов и доступных размерах хранилища для отдельных баз данных см. в статье Ограничения ресурсов на основе виртуальных ядер Базы данных SQL для отдельных баз данных.
- Дополнительные сведения о конкретных объемах вычислительных ресурсов и доступных размерах хранилища для эластичных пулов см. в статье Ограничения ресурсов на основе виртуальных ядер Базы данных SQL для эластичных пулов.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по