Модель приобретения на основе виртуальных ядер (База данных SQL Azure)
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
В этой статье рассматривается модель приобретения на основе виртуальных ядер для Базы данных SQL Azure.
Обзор
Виртуальное ядро (vCore) представляет логический ЦП с возможностью выбора физических характеристик оборудования (например, количество ядер, память и размер хранилища). Модель приобретения на основе виртуальных ядер обеспечивает гибкость, контроль и прозрачность потребления отдельных ресурсов. Это эффективный способ удовлетворить свои требования к локальной рабочей нагрузке в облаке. Эта модель оптимизирует стоимость и позволяет выбирать вычислительные ресурсы, память и хранилище с учетом потребностей рабочих нагрузок.
В модели приобретения на основе виртуальных ядер расходы зависят от выбора и использования:
- Уровень служб
- Настройка оборудования
- Вычислительные ресурсы (число виртуальных ядер и объем памяти)
- Зарезервированное хранилище базы данных
- Фактическое хранилище резервных копий
Внимание
Плата за вычислительные ресурсы, операции ввода-вывода, хранилища данных и журналов взимается для каждой базы данных или эластичного пула. Плата за хранилище резервных копий взимается для каждой базы данных. Информацию о ценах см. на странице цен на Базу данных SQL Azure.
Сравнение моделей приобретения виртуальных ядер и DTU
Модель приобретения виртуальных ядер, используемая База данных SQL Azure, предоставляет несколько преимуществ по сравнению с моделью приобретения на основе DTU:
- Более высокие лимиты вычислительной мощности, памяти, операций ввода-вывода и хранилища.
- Выбор конфигурации оборудования для лучшего соответствия требованиям рабочей нагрузки к вычислениям и памяти.
- Скидки на Преимущество гибридного использования Azure (AHB).
- Более прозрачные сведения об оборудовании, обеспечивающем вычисления, что упрощает планирование миграции из локальных развертываний.
- Цены на зарезервированные экземпляры доступны только для модели приобретения на основе виртуальных ядер.
- Более высокая точность масштабирования благодаря наличию нескольких объемов вычислительных ресурсов.
Сведения о выборе между моделями приобретения виртуальных ядер и DTU см . в различиях между моделями приобретения на основе виртуальных ядер и DTU
Службы вычислений
Модель приобретения на основе виртуальных ядер имеет подготовленный уровень вычислений и бессерверный уровень вычислений. На уровне подготовленных вычислительных ресурсов стоимость вычислительных ресурсов отражает общую вычислительную мощность, которая непрерывно подготавливается для приложения независимо от рабочей нагрузки. Выберите выделение ресурсов, которое лучше всего подходит для вашего бизнеса, на основе требований к виртуальным ядрам и памяти, а затем вертикально увеличивайте и уменьшайте масштаб ресурсов по мере необходимости в зависимости от рабочей нагрузки. На уровне бессерверных вычислений для База данных SQL Azure вычислительные ресурсы автоматически масштабируются на основе емкости рабочей нагрузки и выставляются счета за объем используемых вычислений в секунду.
Подведение итогов.
- Хотя подготовленный уровень вычислений предоставляет определенный объем вычислительных ресурсов, которые постоянно подготавливаются независимо от активности рабочей нагрузки, бессерверный уровень вычислений автоматически масштабирует вычислительные ресурсы на основе действия рабочей нагрузки.
- Уровень подготовленных вычислительных ресурсов использует оплату за объем предоставленных ресурсов по фиксированной цене в час, а уровень бессерверных вычислительных ресурсов — за объем реально используемых вычислительных ресурсов, посекундно.
Независимо от уровня вычислений, три дополнительных вторичных реплики высокого уровня доступности автоматически выделяются на уровне служб критически важный для бизнеса, чтобы обеспечить высокую устойчивость к сбоям и быстрой отработке отказа. Эти дополнительные реплики делают стоимость примерно в 2,7 раза выше, чем на уровне служб общего назначения. Аналогичным образом, более высокая стоимость хранения на ГБ на уровне служб критически важный для бизнеса отражает более высокие ограничения операций ввода-вывода и низкую задержку локального хранилища SSD.
В Гипермасштабировании клиенты управляют количеством дополнительных реплик высокой доступности от 0 до 4, чтобы получить уровень устойчивости, необходимый для своих приложений при управлении затратами.
Дополнительные сведения о вычислительных ресурсах в База данных SQL Azure см. в разделе "Вычислительные ресурсы( ЦП и память)".
Ограничения ресурсов
Для ограничений ресурсов виртуальных ядер просмотрите доступные конфигурации оборудования, а затем просмотрите ограничения ресурсов для следующих значений:
Хранилище данных и журналов
Объем хранилища, используемого для данных и файлов журналов, на уровнях служб "Общего назначения" и "Критически важный для бизнеса" зависит от указанных ниже факторов.
- Объем вычислительных ресурсов поддерживает настраиваемый максимальный размер данных (размер по умолчанию — 32 ГБ).
- При настройке максимального размера данных для файла журнала автоматически добавляется дополнительное 30 процентов оплачиваемого хранилища.
- При использовании уровня служб "Общего назначения"
tempdbиспользует локальное хранилище SSD, а затраты на хранилище входят в стоимость виртуального ядра. - При использовании уровня служб "Критически важный для бизнеса"
tempdbиспользует локальное хранилище SSD как для данных, так и для файлов журналов, а затраты на хранилищеtempdbвходят в стоимость виртуального ядра. - В уровнях общего назначения и критически важный для бизнеса взимается плата за максимальный размер хранилища, настроенный для базы данных или эластичного пула.
- Для База данных SQL можно выбрать любой максимальный размер данных в диапазоне от 1 ГБ до максимального размера поддерживаемого хранилища в 1 ГБ.
Следующие рекомендации по хранению применяются к гипермасштабированию.
- Максимальный размер хранилища данных имеет значение 100 ТБ и не настраивается.
- Плата взимается только за выделенное хранилище данных, а не для максимального хранилища данных.
- Плата за хранение журналов не взимается.
tempdbиспользует локальное хранилище SSD, а его стоимость включена в цену виртуальных ядер. Чтобы отслеживать текущий выделенный и используемый размер хранилища данных в Базе данных SQL, используйте метрики Azure Monitor allocated_data_storage и storage соответственно.
Чтобы отслеживать текущий выделенный и используемый размер хранилища отдельных данных и файлов журнала в базе данных с помощью T-SQL, используйте представление sys.database_files и функцию FILEPROPERTY(... , SpaceUsed).
Совет
В некоторых случаях может потребоваться уменьшить базу данных, чтобы освободить неиспользуемое пространство. Дополнительные сведения см. в статье об управлении файловым пространством в Базе данных SQL Azure.
Хранилище резервных копий
Хранилище резервных копий базы данных выделяется для поддержки возможностей восстановления на определенный момент времени (PITR) и долгосрочного хранения (LTR) База данных SQL. Это отдельное хранилище, не связанное с хранилищем файлов данных и журналов, и оплачивается оно отдельно.
- PITR: на уровнях "Общего назначения" и "Критически важный для бизнеса" резервные копии отдельных баз данных автоматически копируются в хранилище Azure. Размер этого хранилища динамически увеличивается по мере создания новых резервных копий. В хранилище помещаются полные разностные резервные копии и копии журналов транзакций. Потребление хранилища зависит от скорости изменения базы данных и настроенного периода хранения резервных копий. Вы можете настроить отдельный период хранения для каждой базы данных в диапазоне от 1 до 35 дней в течение База данных SQL. Объем хранилища резервных копий, равный настроенному максимальному размеру данных, предоставляется без дополнительной оплаты.
- LTR. Вы также можете настроить долгосрочное хранение полных резервных копий до 10 лет. Если вы включите политику долгосрочно хранения, резервные копии будут автоматически сохраняться в хранилище BLOB-объектов Azure, но вы можете контролировать частоту их копирования. Чтобы выполнять требования к соответствию, вы можете выбрать разные периоды хранения для резервных копий, создаваемых еженедельно, ежемесячно или ежегодно. Выбранная конфигурация определяет, сколько хранилища используется для резервных копий LTR. Дополнительные сведения см. в разделе Долгосрочное хранение резервных копий.
Сведения о хранилище резервных копий в гипермасштабировании см. в статье "Автоматизированные резервные копии для баз данных с гипермасштабированием".
Уровни службы
Модель приобретения на основе виртуальных ядер предоставляет следующие уровни служб: "общего назначения", "критически важный для бизнеса" и "Гипермасштабирование". Уровень служб обычно определяет тип хранилища и производительность, высокий уровень доступности и аварийного восстановления, а также доступность некоторых функций, таких как OLTP в памяти.
| Вариант использования | Общего назначения | Критически важный для бизнеса | Гипермасштабирование |
|---|---|---|---|
| Оптимально для | Большинства рабочих нагрузок. Предлагает бюджетные, сбалансированные и масштабируемые варианты вычислений и хранения. | Предлагает бизнес-приложениям максимальную устойчивость к сбоям с помощью нескольких вторичных реплик высокого уровня доступности и обеспечивает максимальную производительность ввода-вывода. | Самый широкий спектр рабочих нагрузок, включая эти рабочие нагрузки с высокомасштабируемым хранилищем и требованиями к масштабированию чтения. Обеспечивает более высокую устойчивость к сбоям, разрешая настройку нескольких вторичных реплик высокого уровня доступности. |
| Объем вычислительных ресурсов | 2–128 виртуальных ядер | 2–128 виртуальных ядер | 2–128 виртуальных ядер |
| Тип хранилища | Удаленное хранилище класса Premium (для каждого экземпляра) | Сверхбыстрое локальное хранилище SSD (для каждого экземпляра) | Отсоединяемое хранилище с локальным кэшем SSD (на реплику вычислений) |
| Размер хранилища | От 1 ГБ до 4 ТБ | От 1 ГБ до 4 ТБ | 10 ГБ – 100 ТБ |
| ОПЕРАЦИЙ ВВОДА-ВЫВОДА | 320 операций ввода-вывода в секунду на виртуальное ядро с максимальной скоростью 16 000 операций ввода-вывода в секунду | 4000 операций ввода-вывода в секунду на виртуальное ядро с максимальным числом операций ввода-вывода в секунду 327 680 операций ввода-вывода в секунду | 327 680 операций ввода-вывода в секунду с максимальным локальным SSD Гипермасштабирование — это многоуровневая архитектура с кэшированием на нескольких уровнях. Эффективные операции ввода-вывода в секунду зависят от рабочей нагрузки. |
| Память и виртуальные ядра | 5.1 ГБ | 5.1 ГБ | 5,1 ГБ или 10,2 ГБ |
| Резервные копии | Выбор геоизбыточного, избыточного между зонами или локально избыточного хранилища резервных копий, 1–35 дней хранения (по умолчанию 7 дней) Долгосрочное хранение доступно до 10 лет |
Выбор геоизбыточного, избыточного между зонами или локально избыточного хранилища резервных копий, 1–35 дней хранения (по умолчанию 7 дней) Долгосрочное хранение доступно до 10 лет |
Выбор локально избыточного хранилища (LRS), избыточного между зонами (ZRS) или геоизбыточного хранилища (GRS) Срок хранения 1–35 дней (по умолчанию — 7 дней) с сроком хранения до 10 лет. |
| Доступность | Одна реплика, ни одна реплика, не масштабируемая реплика, высокий уровень доступности с избыточностью в между зонами |
Три реплики, одна реплика для чтения, высокий уровень доступности с избыточностью в между зонами |
высокий уровень доступности с избыточностью в между зонами |
| Цены и выставление счетов | Оплачиваются: виртуальное ядро, зарезервированное хранилище и хранилище резервных копий. Плата за операции ввода-вывода в секунду не взимается. |
Оплачиваются: виртуальное ядро, зарезервированное хранилище и хранилище резервных копий. Плата за операции ввода-вывода в секунду не взимается. |
Оплачиваются: виртуальное ядро для каждой реплики и используемое хранилище. Плата за операции ввода-вывода в секунду не взимается. |
| Модели скидок | Зарезервированные экземпляры Преимущество гибридного использования Azure (недоступно в подписках для разработки и тестирования) Корпоративные и разработка и тестирование с оплатой по мере использования подписки |
Зарезервированные экземпляры Преимущество гибридного использования Azure (недоступно в подписках для разработки и тестирования) Корпоративные и разработка и тестирование с оплатой по мере использования подписки |
Преимущество гибридного использования Azure (недоступно для подписок разработки и тестирования) 1 Корпоративные и разработка и тестирование с оплатой по мере использования подписки |
| Таблицы OLTP в памяти | No | Да | Нет |
1 Упрощенная цена на База данных SQL Гипермасштабирование в ближайшее время. Дополнительные сведения см. в блоге о ценах на гипермасштабирование.
Более подробные сведения вы найдете в описании ограничений по ресурсам для логического сервера, отдельных баз данных и баз данных в пуле.
Примечание.
Дополнительные сведения о Соглашении об уровне обслуживания для Базы данных SQL Azure см. здесь.
Общего назначения
Архитектурная модель для уровня служб "Общего назначения" основана на разделении вычислений и хранилища. Эта архитектурная модель зависит от высокой доступности и надежности хранилища BLOB-объектов Azure, который прозрачно реплицирует файлы базы данных и гарантирует отсутствие потери данных в случае сбоя базовой инфраструктуры.
На следующем рисунке показано четыре узла в стандартной архитектурной модели с разделенными уровнями вычислений и хранения.
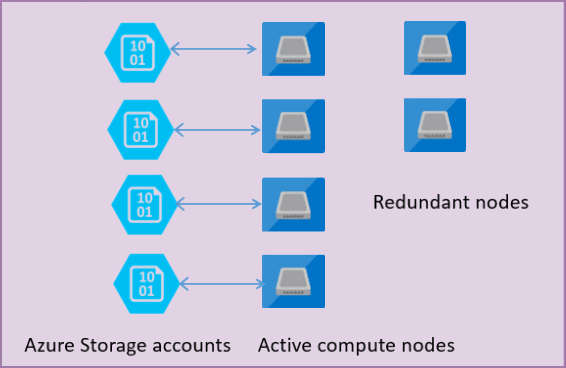
В архитектурной модели для уровня служб "Общего назначения" существует два уровня:
- Уровень вычислений без отслеживания состояния, выполняющий
sqlservr.exeпроцесс и содержащий только временные и кэшированные данные (например, кэш планов, буферный пул, пул columnstore). Этим узлом без отслеживания состояния управляет платформа Azure Service Fabric, которая инициализирует процесс, контролирует работоспособность узла и при необходимости выполняет переход на другой ресурс. - Уровень данных с отслеживанием состояния, где файлы базы данных (MDF/LDF) хранятся в хранилище BLOB-объектов Azure. Хранилище BLOB-объектов Azure гарантирует отсутствие потери данных любой записи, размещенной в любом файле базы данных. служба хранилища Azure имеет встроенную доступность и избыточность данных, которая гарантирует сохранение каждой записи в файле журнала или странице в файле данных, даже если процесс завершается сбоем.
При обновлении ядра СУБД или операционной системы некоторые части базовой инфраструктуры завершается сбоем или при обнаружении какой-либо критической проблемы в sqlservr.exe процессе, Azure Service Fabric перемещает процесс без отслеживания состояния в другой вычислительный узел без отслеживания состояния. Существует набор запасных узлов, ожидающих запуска новой вычислительной службы, если отработка отказа первичного узла происходит, чтобы свести к минимуму время отработки отказа. Данные на уровне хранилища Azure не затрагиваются, а файлы данных и журналов присоединяются к только что инициализированному процессу. Этот процесс гарантирует доступность в течение 99,99 % времени по умолчанию и доступность в течение 99,995 % времени, если включена избыточность между зонами. В результате перехода может возникнуть некоторое влияние на производительность рабочих нагрузок, которые выполняются во время перехода, и тот факт, что новый узел начинается с холодного кэша.
Когда нужно выбирать этот уровень служб?
Уровень служб общего назначения — это уровень служб по умолчанию в База данных SQL Azure предназначен для большинства универсальных рабочих нагрузок. Если вам нужен полностью управляемый ядро СУБД с задержкой обслуживания по умолчанию и задержкой хранилища в диапазоне от 5 мс до 10 мс, уровень общего назначения — это вариант.
Критически важный для бизнеса
Модель уровня служб "критически важный для бизнеса" основана на кластере процессов ядра СУБД. Эта архитектурная модель использует кворум узлов ядра СУБД, чтобы свести к минимуму влияние производительности на рабочую нагрузку даже во время обслуживания. Обновления и исправления базовой операционной системы, драйверов и ядра СУБД выполняются прозрачно с минимальным временем простоя для конечных пользователей.
В модели критически важный для бизнеса вычислительные ресурсы и хранилище интегрируются на каждом узле. Репликация данных между процессами ядра СУБД на каждом узле кластера с четырьмя узлами обеспечивает высокую доступность, при этом каждый узел использует локально подключенный SSD в качестве хранилища данных. На следующей схеме показано, как уровень служб критически важный для бизнеса упорядочивает кластер узлов ядра СУБД в репликах группы доступности.

Процесс ядра СУБД и базовые файлы .mdf/.ldf размещаются на одном узле с локально подключенным хранилищем SSD, обеспечивая низкую задержку в рабочей нагрузке. Высокий уровень готовности реализуется с помощью технологии, аналогичной группам доступности Always On SQL Server. Каждая база данных — это кластер узлов базы данных с одной первичной репликой, доступной для клиентских рабочих нагрузок, и тремя вторичными репликами, содержащими копии данных. Первичная реплика постоянно отправляет изменения в вторичные реплики, чтобы обеспечить доступность данных на вторичных репликах, если первичный сбой по какой-либо причине. Отработка отказа обрабатывается Service Fabric и ядром СУБД— одна вторичная реплика становится основной, и создается новая вторичная реплика, чтобы убедиться, что в кластере достаточно узлов. Рабочая нагрузка автоматически перенаправляется на новую первичную реплику.
Кроме того, в кластере критически важный для бизнеса есть встроенная возможность масштабирования чтения, которая предоставляет бесплатную реплику только для чтения, используемую для выполнения запросов только для чтения (например, отчетов), которые не влияют на производительность рабочей нагрузки на первичной реплике.
Когда нужно выбирать этот уровень служб?
Уровень служб критически важный для бизнеса предназначен для приложений, требующих ответов с низкой задержкой от базового хранилища SSD (в среднем 1–2 мс), ускорения восстановления, если базовая инфраструктура завершается сбоем, или требуется отключить отчеты, аналитику и запросы только для чтения в бесплатную читаемую вторичную реплику базы данных-источника.
Ниже приведены основные причины, по которым следует выбрать критически важный для бизнеса уровень служб вместо уровня общего назначения.
- Низкие требования к задержке ввода-вывода — рабочие нагрузки, требующие согласованного быстрого ответа от уровня хранилища (1–2 миллисекунда в среднем) должны использовать уровень критически важный для бизнеса.
- Рабочая нагрузка с запросами отчетов и аналитики , в которых достаточно одна вторичная вторичная реплика только для чтения.
- Повышение устойчивости и более быстрое восстановление после сбоев. В случае сбоя системы база данных на первичном экземпляре отключена, а одна из вторичных реплик сразу же становится новой базой данных-источником для чтения и записи, готовой к обработке запросов.
- Расширенная защита от повреждений данных. Так как уровень критически важный для бизнеса использует реплики баз данных за кулисами, служба использует автоматическое восстановление страниц, доступное с зеркальным отображением и группами доступности для устранения повреждения данных. Если реплика не может считывать страницу из-за проблемы целостности данных, новая копия страницы извлекается из другой реплики, заменив нечитаемую страницу без потери данных или простоя клиента. Эта функция доступна на уровне общего назначения, если база данных имеет геореплику-вторичную.
- Более высокий уровень доступности — уровень критически важный для бизнеса в конфигурации зоны с несколькими доступностью обеспечивает устойчивость к зональным сбоям и более высокой доступности.
- Быстрое геовосстановление. Если настроена активная георепликация, уровень "Критически важный для бизнеса" предоставляет гарантированные значения 5 секунд для RPO (целевая точка восстановления) и 30 секунд для RTO (целевое время восстановления) с покрытием 100 % часов развертывания.
Гипермасштабирование
Уровень служб "Гипермасштабирование" подходит для всех типов рабочих нагрузок. Ее облачная архитектура обеспечивает независимо масштабируемые вычислительные ресурсы и хранилище для поддержки самых разнообразных традиционных и современных приложений. Вычислительные ресурсы и ресурсы хранилища в гипермасштабировании значительно превышают ресурсы, доступные на уровнях общего назначения и критически важный для бизнеса.
Дополнительные сведения см. на уровне служб "Гипермасштабирование" для База данных SQL Azure.
Когда нужно выбирать этот уровень служб?
Уровень служб "Гипермасштабирование" устраняет многие практические ограничения, традиционно наблюдаемые в облачных базах данных. В то время как большинство других баз данных ограничены ресурсами, доступными на одном узле, базы данных на уровне служб "Гипермасштабирование" не имеют таких ограничений. Благодаря гибкой архитектуре хранилища база данных Гипермасштабирования растет по мере необходимости, и вы оплачиваете только для используемой емкости хранилища.
Помимо расширенных возможностей масштабирования, Гипермасштабирование — отличный вариант для любой рабочей нагрузки, а не только для больших баз данных. С гипермасштабированием можно:
- Обеспечить высокую устойчивость и быстрое восстановление сбоев при управлении затратами, выбрав количество реплик высокой доступности от 0 до 4.
- Повышение уровня доступности путем включения избыточности зоны для вычислений и хранилища.
- Обеспечение низкой задержки ввода-вывода (1–2 миллисекунда в среднем) для часто доступной части базы данных. Для небольших баз данных это может применяться ко всей базе данных.
- Реализуйте широкий спектр сценариев масштабирования чтения с именованных репликами.
- Воспользуйтесь преимуществами быстрого масштабирования, не ожидая копирования данных в локальное хранилище на новых узлах.
- Наслаждайтесь непрерывным резервным копированием базы данных без нуля и быстрым восстановлением.
- Поддержка требований к непрерывности бизнес-процессов с помощью групп отработки отказа и георепликации.
Настройка оборудования
Общие конфигурации оборудования в модели виртуальных ядер включают стандартные серии (5-го поколения), Fsv2-series и DC-series. Гипермасштабирование также предоставляет возможность для оборудования, оптимизированного для памяти серии "Премиум" и "Премиум". Конфигурация оборудования определяет ограничения вычислительных ресурсов и памяти и другие характеристики, влияющие на производительность рабочей нагрузки.
Некоторые аппаратные конфигурации, такие как стандартная серия (5-го поколения), могут использовать несколько типов процессоров (ЦП), как описано в разделе вычислительных ресурсов (ЦП и памяти). Хотя определенная база данных или эластичный пул, как правило, остаются на оборудовании с одинаковым типом ЦП в течение длительного периода времени (обычно — много месяцев), некоторые события могут создавать необходимость в перемещении базы данных или пула на оборудование с процессором другого типа.
Базу данных или пул можно переместить для различных сценариев, включая, но не ограничивается тем, когда:
- Цель службы изменена
- Текущая инфраструктура в центре обработки данных приближается к ограничениям емкости
- В настоящее время используемое оборудование удаляется из-за окончания срока жизни
- Конфигурация с избыточностью между зонами включена, переход на другое оборудование из-за доступной емкости
Для некоторых рабочих нагрузок переход на другой тип ЦП повлечь изменения производительности. База данных SQL настраивает оборудование с целью обеспечить прогнозируемую производительность рабочей нагрузки, даже при изменении типа ЦП. В результате производительность меняется лишь в узком диапазоне. Однако в широком спектре рабочих нагрузок клиентов в База данных SQL и по мере того, как новые типы ЦП становятся доступными, иногда можно увидеть более заметные изменения производительности, если база данных или пул перемещается на другой тип ЦП.
Независимо от используемого типа ЦП ограничения ресурсов для базы данных или эластичного пула (например, количество ядер, объем памяти, максимальное число операций ввода-вывода в секунду, максимальное число операций ввода-вывода в секунду и максимальное число одновременных рабочих ролей) остаются неизменными, если база данных остается в той же цели службы.
Вычислительные ресурсы (ЦП и память)
В следующей таблице сравниваются вычислительные ресурсы в разных конфигурациях оборудования и уровнях вычислений:
| Настройка оборудования | ЦП | Память |
|---|---|---|
| Серия Standard (5-е поколение) | Подготовленные вычисления - Intel® E5-2673 v4 (Broadwell) 2,3 ГГц, Intel SP-8160 (Skylake)*, Intel®® 8272CL (Каскадное озеро) 2,5 ГГц*, Intel®® Xeon Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Милан) процессоры — Подготовка до 128 виртуальных ядер (с поддержкой технологии Hyper-Threading) Бессерверные вычисления - Intel® E5-2673 v4 (Broadwell) 2,3 ГГц, Intel SP-8160 (Skylake)*, Intel®® 8272CL (Каскадное озеро) 2,5 ГГц*, Intel®® Xeon Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Милан) процессоры — автомасштабирование до 80 виртуальных ядер (гиперпоток) — Соотношение памяти к виртуальным ядрам динамически адаптируется к памяти и использованию ЦП на основе спроса на рабочую нагрузку и может составлять не более 24 ГБ на виртуальное ядро. Например, в определенный момент времени рабочая нагрузка может использовать и выставляться счет за 240 ГБ памяти и только 10 виртуальных ядер. |
Подготовленные вычисления 5,1 ГБ на виртуальное ядро. — подготовка до 625 ГБ Бессерверные вычисления — автомасштабирование до 24 ГБ на виртуальное ядро — автомасштабирование до 240 ГБ макс. |
| серия Fsv2; | Процессоры Intel® 8168 (Skylake). Обеспечение постоянной тактовой частоты всех ядер в режиме Turbo Boost 3,4 ГГц и максимальной частоты отдельного ядра в режиме Turbo Boost 3,7 ГГц. — Подготовка до 72 виртуальных ядер (с поддержкой технологии Hyper-Threading) |
1,9 ГБ на виртуальное ядро. Подготовка до 136 ГБ. |
| Серия DC | — процессоры Intel® Xeon® E-2288G — с расширением Intel Software Guard (Intel SGX) — Подготовка до 8 виртуальных ядер (физических) |
4,5 ГБ на виртуальное ядро. |
* В sys.dm_user_db_resource_governance динамическом представлении управления оборудование для баз данных с помощью процессоров Intel® SP-8160 (Skylake) отображается как поколение 6-го поколения, поколение оборудования для баз данных с помощью Intel® 8272CL (Каскадное озеро) отображается как Gen7, а оборудование для баз данных с помощью Intel®® Xeon Platinum 8370C (Ice Lake) или AMD® EPYC® 7763v (Милан) отображается как Gen8. Для заданного размера вычислительных ресурсов и аппаратной конфигурации ограничения ресурсов одинаковы независимо от типа ЦП (Intel Broadwell, Skylake, Ice Lake, Каскадного озера или AMD Милана).
Дополнительные сведения см. в разделе об ограничениях ресурсов для отдельных баз данных и эластичных пулов.
Сведения о вычислительных ресурсах и спецификациях базы данных гипермасштабирования см. в разделе "Ресурсы вычислений с гипермасштабированием".
Серия Standard (5-е поколение)
- Оборудование серии "Стандартный" (5-го поколения) обеспечивает сбалансированные вычислительные ресурсы и ресурсы памяти и подходит для большинства рабочих нагрузок базы данных.
Поколение серии Standard (поколение Gen5) доступно во всех общедоступных регионах по всему миру.
Серия "Премиум" с гипермасштабированием
- Варианты оборудования серии "Премиум" используют новейшие технологии ЦП и памяти intel и AMD. Серия "Премиум" обеспечивает повышение производительности вычислений относительно оборудования стандартной серии.
- Вариант серии "Премиум" обеспечивает более высокую производительность ЦП по сравнению с серией "Стандартный" и более высоким количеством максимальных виртуальных ядер.
- Оптимизированный для памяти категории "Премиум" вариант обеспечивает двойной объем памяти относительно категории "Стандартный".
- Для эластичных пулов с гипермасштабированием доступны стандартные, премиум-серии и оптимизированные для памяти серии "Премиум".
Дополнительные сведения см. в объявлении блога о серии "Гипермасштабирование премиум".
Доступные регионы см. в разделе "Доступность серии "Премиум" с гипермасштабированием.
серия Fsv2;
- Серия Fsv2 — это оптимизированная для вычислений конфигурация оборудования, обеспечивающая низкую задержку и высокую тактовую частоту ЦП для большинства ресурсоемких рабочих нагрузок. Аналогично конфигурациям оборудования серии "Премиум", серия Fsv2 работает с помощью новейших технологий ЦП и памяти intel и AMD, что позволяет клиентам воспользоваться новейшим оборудованием при использовании баз данных и эластичных пулов на уровне служб общего назначения.
- В зависимости от рабочей нагрузки серия Fsv2 может обеспечить большую производительность ЦП на виртуальное ядро, чем оборудование других типов. Например, размер вычислительных ресурсов 72 vCore Fsv2 может обеспечить более высокую производительность ЦП, чем 80 виртуальных ядер в серии "Стандартный" (5-го поколения), при более низкой стоимости.
- Fsv2 обеспечивает меньше памяти и
tempdbна виртуальные ядра, чем другое оборудование, поэтому рабочие нагрузки, чувствительные к этим ограничениям, могут повысить производительность в стандартной серии (5-го поколения).
Серия Fsv2 поддерживается только для уровня "Общего назначения". Регионы, в которых доступна серия Fsv2, приведены в разделе Серия Fsv2.
Серия DC
- Оборудование серии DC использует процессоры Intel с поддержкой расширений Software Guard Extensions (Intel SGX).
- Серия dc-series необходима для always Encrypted с безопасными анклавами рабочих нагрузок, требующих более надежной защиты аппаратных анклавах, по сравнению с анклавами безопасности на основе Виртуализации (VBS).
- Серия DC предназначена для рабочих нагрузок, которые обрабатывают конфиденциальные данные и нуждаются в возможностях конфиденциальной обработки запросов, предоставляемых Always Encrypted с безопасными анклавами.
- Оборудование серии DC обеспечивает сбалансированные вычислительные ресурсы и ресурсы памяти.
Серия DC поддерживается только для подготовленных вычислений (бессерверные не поддерживаются) и не поддерживает избыточность зоны. Регионы, в которых доступна серия DC, приведены в разделе Серия DC.
Типы предложений Azure, поддерживаемые серией DC
Для создания баз данных и эластичных пулов на оборудовании серии DC нужна платная подписка с оплатой по мере использования или Соглашением Enterprise (EA). Полный список типов предложений Azure, поддерживаемых серией DC, приведен в разделе Сведения о предложении решения Microsoft Azure.
Выбор конфигурации оборудования
Вы можете выбрать конфигурацию оборудования для базы данных или эластичного пула в Базе данных SQL во время создания. Вы также можете изменить конфигурацию оборудования существующей базы данных или эластичного пула.
Выбор конфигурации оборудования при создании Базы данных SQL или пула
Дополнительные сведения см. в статье Краткое руководство. Создание отдельной базы данных в Базе данных SQL Azure.
На вкладке Основное в разделе Вычисления и хранилище щелкните ссылку Настройка базы данных, а затем щелкните ссылку Изменить конфигурацию.

Выберите нужную конфигурацию оборудования:

Изменение конфигурации оборудования существующей Базы данных SQL или пула
На странице "Обзор" для базы данных щелкните ссылку Ценовая категория.

Для пула на странице "Обзор " выберите "Настроить".
Выполните действия по изменению конфигурации и выберите конфигурацию оборудования, как описано на предыдущих шагах.
Доступность оборудования
Сведения о оборудовании предыдущего поколения см. в разделе "Доступность оборудования предыдущего поколения".
Серия Standard (5-е поколение)
Поколение серии Standard (поколение Gen5) доступно во всех общедоступных регионах по всему миру.
Серия "Премиум" с гипермасштабированием
Высокомасштабируемое оборудование уровня служб уровня "Премиум" и "Премиум", оптимизированное для памяти серии "Премиум", доступно для отдельных баз данных и эластичных пулов в следующих регионах:
- Восточная Австралия **
- Юго-Восточная часть Австралии
- Южная Бразилия **
- Центральная Канада **
- Восточная Канада
- Восточная Азия
- Европа Северная **
- Европа Запад **
- Центральная Франция
- Центрально-Западная Германия
- Центральная Индия
- Южная Индия
- Восточная Япония **
- Западная Япония
- Юго-Восточная Азия**
- Северная Швейцария
- Центральная Швеция **,*
- Южная Часть Великобритании **
- Западная часть Великобритании *
- Центральная часть США **
- Восточная часть США **
- Восточная часть США 2 **
- Центрально-северная часть США
- Центрально-южная часть США
- Центрально-западная часть США
- Западная часть США 1
- Западная часть США 2 **
- Западная часть США 3 **
* Оптимизированное для памяти оборудование серии "Премиум" в настоящее время недоступно.
** Включает поддержку избыточности зоны.
серия Fsv2;
Серия Fsv2 доступна в следующих регионах:
- Центральная Австралия
- Центральная Австралия 2
- Восточная Австралия
- Юго-Восточная часть Австралии
- Южная Бразилия
- Центральная Канада
- Восточная Азия
- Северная Европа
- Западная Европа
- Центральная Франция
- Центральная Индия
- Республика Корея, центральный регион
- Республика Корея, южный регион
- Северная часть ЮАР
- Юго-Восточная Азия
- южная часть Соединенного Королевства
- западная часть Соединенного Королевства
- Восточная часть США
- Западная часть США 2
Серия DC
Серия DC доступна в следующих регионах:
- Центральная Канада
- Западная Европа
- Северная Европа
- Юго-Восточная Азия
- южная часть Соединенного Королевства
- Западная часть США
- Восточная часть США
Если вам нужна серия DC в неподдерживаемом регионе, отправьте запрос на поддержку. На вкладке Основные используйте следующие значения.
- В качестве типа проблемы укажите Техническая.
- Укажите нужную подписку для оборудования. Выберите Далее.
- В качестве типа службы выберите База данных SQL.
- Для ресурса выберите общий вопрос.
- В разделе "Сводка" укажите нужную доступность оборудования и регион.
- В качестве типа проблемы выберите Безопасность, конфиденциальность и соответствие требованиям.
- В качестве подтипа проблемы выберите Always Encrypted.

Оборудование прошлых поколений
4-го поколения
Оборудование 4-го поколения было прекращено и недоступно для подготовки, масштабирования или уменьшения масштабирования. Перенос базы данных в поддерживаемое поколение оборудования для более широкого диапазона масштабируемости виртуальных ядер и хранилища, ускорения сети, оптимальной производительности операций ввода-вывода и минимальной задержки. Просмотрите параметры оборудования для отдельных баз данных и аппаратных параметров для эластичных пулов. Дополнительные сведения см. в статье о завершении поддержки оборудования 4-го поколения на База данных SQL Azure.