Рекомендации по настройке HADR (SQL Server на виртуальных машинах Azure)
Область применения: ![]() SQL Server на виртуальной машине Azure
SQL Server на виртуальной машине Azure
Отказоустойчивый кластер Windows Server используется для обеспечения высокой доступности и аварийного восстановления (HADR) в SQL Server на Виртуальных машинах Azure.
В этой статье приведены рекомендации по конфигурации кластера для экземпляров отказоустойчивого кластера (FCI) и групп доступности при их использовании с SQL Server на виртуальных машинах Azure.
Дополнительные сведения см. в других статьях этой серии: Контрольный список, Размер виртуальной машины, Хранилище, Безопасность, Конфигурация HADR, Сбор базовых показателей.
Контрольный список
Ознакомьтесь со следующим контрольным списком, содержащим краткий обзор рекомендаций по HADR, которые более подробно описываются далее в этой статье.
Возможности HADR (высокая доступность и аварийное восстановление), такие как группы доступности Always On и экземпляр отказоустойчивого кластера, основываются на технологии отказоустойчивого кластера Windows Server. Изучите современные рекомендации по настройке параметров HADR для работы с облачной средой.
Для кластера Windows примените следующие рекомендации:
- По возможности развертывайте виртуальные машины SQL Server в нескольких подсетях, чтобы не использовать Azure Load Balancer или имя распределенной сети (DNN) для маршрутизации трафика к решению HADR.
- Измените параметры кластера на менее жесткие, чтобы избежать непредвиденных перерывов в работе из-за временных сбоев сети или обслуживания платформы Azure. Дополнительные сведения см. в разделе Параметры пульса и порога. Для Windows Server 2012 и более поздних версий используйте следующие рекомендуемые значения:
- SameSubnetDelay: 1 секунда;
- SameSubnetThreshold: 40 пульсов;
- CrossSubnetDelay: 1 секунда;
- CrossSubnetThreshold: 40 пульсов.
- Разместите виртуальные машины в группе доступности или в разных зонах доступности. Дополнительные сведения см. в разделе Параметры доступности виртуальной машины.
- Используйте одну сетевую карту на узел кластера.
- Настройте кворум для голосования в кластере таким образом, чтобы требовалось три голоса или большее нечетное число голосов. Не назначать голоса регионам аварийного восстановления.
- Тщательно отслеживайте ограничения ресурсов, чтобы избежать непредвиденных перезапусков или отработки отказа.
- Используйте последние сборки ОС, драйверов и SQL Server.
- Оптимизируйте производительность SQL Server на виртуальных машинах Azure. Ознакомьтесь с остальными разделами этой статьи, чтобы получить дополнительные сведения.
- Сократите или распределите рабочую нагрузку, чтобы не допустить превышения ограничений для ресурсов.
- Перейдите на виртуальную машину или диск с более высокими значениями ограничений, чтобы избежать их превышения.
Для группы доступности SQL Server или экземпляра отказоустойчивого кластера учитывайте следующие рекомендации:
- При частом возникновении непредвиденных сбоев следуйте рекомендациям по повышению производительности, приведенным далее в этой статье.
- Если оптимизация производительности виртуальной машины SQL Server не устраняет непредвиденные отработки отказа, рассмотрите возможность восстановления мониторинга для группы доступности или экземпляра отказоустойчивого кластера. Но источник проблемы при этом может сохраниться: вы просто скроете внешние проявления и уменьшите вероятность сбоя. Чтобы устранить первопричину, потребуется провести дополнительный анализ. Для Windows Server 2012 или более поздней версии используйте следующие рекомендуемые значения:
- Время ожидания аренды: используйте это уравнение для вычисления максимального значения времени ожидания аренды:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Начните с 40 секунд. Если вы используете расслабленныеSameSubnetThresholdзначения,SameSubnetDelayрекомендуемые ранее, не превышает 80 секунд для значения времени ожидания аренды. - Max failures in a specified period (Максимальное число сбоев за указанный период). Задайте значение 6.
- Время ожидания аренды: используйте это уравнение для вычисления максимального значения времени ожидания аренды:
- Если для подключения к решению HADR используется имя виртуальной сети (VNN) и Azure Load Balancer, укажите
MultiSubnetFailover = trueв строке подключения, даже если кластер включает только одну подсеть.- Если клиент не поддерживает
MultiSubnetFailover = TrueRegisterAllProvidersIP = 0настройку иHostRecordTTL = 300кэширование учетных данных клиента в течение более короткой длительности. Но это может привести к увеличению числа запросов к DNS-серверу.
- Если клиент не поддерживает
- Чтобы подключиться к решению HADR с использованием распределенного сетевого имени (DNN), рассмотрим следующее:
- Необходимо использовать драйвер клиента, поддерживающий
MultiSubnetFailover = True. Этот параметр должен быть указан в строке подключения. - Используйте уникальный порт DNN в строке подключения при подключении к прослушивателю DNN для группы доступности.
- Необходимо использовать драйвер клиента, поддерживающий
- Используйте строку подключения зеркального отображения базы данных для базовой группы доступности, чтобы избежать необходимости в подсистеме балансировки нагрузки или DNN.
- Проверьте размер сектора VHD перед развертыванием решения для обеспечения высокой доступности, чтобы избежать операций ввода-вывода с неверным выравниванием. Дополнительные сведения см. в статье базы знаний 3009974.
- Если для ядра СУБД SQL Server, прослушивателя группы доступности Always On или пробы работоспособности экземпляра отказоустойчивого кластера настроено использование порта в диапазоне от 49 152 до 65 536 (диапазон динамических портов по умолчанию для TCP/IP), добавьте исключение для каждого порта. Это позволяет предотвратить динамическое назначение другим системам того же порта. В следующем примере создается исключение для порта 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Чтобы сравнить контрольный список HADR с другими рекомендациями, ознакомьтесь с полным контрольным списком рекомендаций по производительности.
Параметры доступности виртуальной машины
Чтобы уменьшить влияние простоя, рассмотрите следующие параметры доступности виртуальной машины:
- Чтобы обеспечить минимальную задержку, используйте для групп размещения близкого взаимодействия ускорение сети.
- Размещайте узлы кластера виртуальных машин в отдельных зонах доступности для защиты от сбоев центра обработки данных или в одной группе доступности для обеспечения избыточности в пределах одного центра данных.
- Используйте управляемые диски категории "Премиум" для ОС и данных виртуальных машин в группе доступности.
- Настройте все уровни приложений в отдельных группах доступности.
Quorum
Хотя функции кластера с двумя узлами без ресурса кворума, клиенты строго обязаны использовать ресурс кворума для поддержки рабочей среды. Проверка кластера не передает кластер без ресурса кворума.
Технически кластер с тремя узлами может пережить потерю одного узла (до двух узлов) без ресурса кворума, но после того, как кластер будет до двух узлов, если есть другой сбой узла или связи, то есть риск того, что кластеризованные ресурсы будут работать в автономном режиме, чтобы предотвратить сценарий разделения мозга. Настройка ресурса кворума позволяет кластеру продолжать работу только с одним узлом в сети.
Диск-свидетель является наиболее устойчивым вариантом кворума, но для использования диска-свидетеля на виртуальной машине Azure необходимо использовать общий диск Azure, который накладывает некоторые ограничения на решение высокой доступности. Поэтому диск-свидетель следует использовать при настройке экземпляра отказоустойчивого кластера с общими дисками Azure. В противном случае по возможности используйте облако-свидетель.
В приведенной ниже таблице перечислены варианты кворума, доступные для SQL Server на виртуальных машинах Azure.
| Облако-свидетель | Диск-свидетель | Файловый ресурс-свидетель | |
|---|---|---|---|
| Поддерживаемые ОС | Windows Server 2016+ | Все | Все |
- Облако-свидетель идеально подходит для развертываний на нескольких сайтах, в нескольких зонах и в нескольких регионах. Облако-свидетель следует по возможности использовать во всех случаях, кроме кластерного решения с общим хранилищем.
- Диск-свидетель — это наиболее устойчивый вариант кворума, который является предпочтительным для любого кластера с общими дисками Azure (или любого решения на основе общих дисков, например общего SCSI, iSCSI или оптоволоконной сети SAN). Кластеризованный общий том нельзя использовать в качестве следящего диска.
- Общая папка-свидетель подходит, когда диск-свидетель и облако-свидетель недоступны.
Сведения о том, как приступить к работе, см. в статье Настройка кворума кластера.
Голосование кворума
Голос в кворуме узла, участвующего в отказоустойчивом кластере Windows Server, можно изменить.
При изменении параметров голоса для узла следуйте приведенным ниже рекомендациям.
| Рекомендации по голосованию кворума |
|---|
| По умолчанию у узла не должно быть голоса. Для наличия голоса у каждого узла требуется явное обоснование. |
| Включите голоса для узлов кластера, в которых размещается первичная реплика группы доступности, или для предпочтительных владельцев экземпляра отказоустойчивого кластера. |
| Включите голоса для владельцев автоматического перехода на другой ресурс. Каждый узел, который может размещать первичную реплику или FCI в результате автоматической отработки отказа, должен иметь голосование. |
| Если в группе доступности несколько вторичных реплик, включите голоса только для реплик с автоматическим переходом на другой ресурс. |
| Отключите голоса для узлов, находящихся на вторичных сайтах аварийного восстановления. Узлы на вторичных сайтах не должны способствовать принятию решения об автономном использовании кластера, если нет ничего плохого с основным сайтом. |
| Число голосов кворума должно быть нечетным (минимум три). В кластере с двумя узлами при необходимости добавьте свидетель кворума, чтобы получить дополнительный голос. |
| Перераспределяйте назначение голосов после отработки отказа. Не допускайте отработку отказа с переходом на конфигурацию кластера, которая не поддерживает работоспособность кворума. |
Подключение
Чтобы обеспечить соответствие локальной среды для подключения к прослушивателю группы доступности или экземпляру отказоустойчивого кластера, разверните виртуальные машины SQL Server в нескольких подсетях в одной виртуальной сети. Наличие нескольких подсетей устраняет необходимость в дополнительной зависимости от Azure Load Balancer или имени распределенной сети для маршрутизации трафика к прослушивателю.
Чтобы упростить решение HADR, при возможности разверните виртуальные машины SQL Server в нескольких подсетях. Дополнительные сведения см. в разделах Группа доступности с несколькими подсетями и Экземпляр отказоустойчивого кластера с несколькими подсетями.
Если ваши виртуальные сети SQL Server находятся в одной подсети, вы можете настроить имя виртуальной машины (VNN) и Azure Load Balancer или имя распределенной сети (DNN) для экземпляров отказоустойчивого кластера и прослушивателей группы доступности.
Имя распределенной сети — это рекомендуемый вариант подключения, если он доступен.
- Комплексное решение является более надежным, так как не нужно поддерживать ресурс подсистемы балансировки нагрузки.
- Устранение проверок подсистемы балансировки нагрузки сводит к минимуму длительность отработки отказа.
- DNN упрощает подготовку и администрирование экземпляра отказоустойчивого кластера или прослушивателя группы доступности с SQL Server на виртуальных машинах Azure.
Необходимо учитывать следующие ограничения.
- Драйвер клиента должен поддерживать параметр
MultiSubnetFailover=True. - Функция DNN сейчас доступна начиная с версий SQL Server 2016 SP3, SQL Server 2017 CU25 и SQL Server 2019 CU8 в Windows Server 2016 и более поздней версии.
Дополнительные сведения см. в обзоре отказоустойчивого кластера Windows Server.
Сведения о настройке подключения см. в приведенных ниже статьях.
- Группа доступности: Настройка DNN, Настройка VNN.
- Экземпляр отказоустойчивого кластера: Настройка DNN, Настройка VNN.
Большинство функций SQL Server работают прозрачно с FCI и группами доступности при использовании DNN, но существуют определенные функции, которые могут потребовать особого рассмотрения. Дополнительные сведения см. в статьях Взаимодействие FCI и DNN и Взаимодействие группы доступности и DNN.
Совет
Задайте параметр MultiSubnetFailover=true в строке подключения даже для решений HADR, которые используют одну подсеть, чтобы в дальнейшем можно было добавлять подсети, не обновляя строку подключения.
Пульс и пороговое значение
Измените параметры пульса и пороговых значений кластера на менее строгие. Параметры пульса и пороговых значений по умолчанию для кластера предназначены для высокопроизводительных локальных сетей и не учитывают возможность увеличения задержки в облачной среде. Сеть передачи пульса работает через порт UDP 3343, который обычно менее надежен, чем TCP, и более подвержен незавершенным сеансам.
Поэтому, если узлы кластера SQL Server работают на базе виртуальных машин Azure с высоким уровнем доступности, измените параметры кластера, чтобы ослабить мониторинг. Это позволит избежать временных сбоев из-за повышенной вероятности длительных задержек или ошибок сети, обслуживания инфраструктуры Azure или возникновения узких мест.
Параметры задержки и пороговых значений оказывают совокупное влияние на общее состояние работоспособности. Например, если с помощью параметра CrossSubnetDelay настроить отправку пульса каждые две секунды, а с помощью параметра CrossSubnetThreshold задать восстановление после 10 пропущенных пакетов пульса, значит, в кластере будет допускаться общая задержка в 20 секунд, прежде чем будет предпринято действие по восстановлению. Как правило, желательно отправлять пакеты пульса с высокой частотой, но использовать более высокие пороговые значения.
Чтобы обеспечить восстановление в случае истинных простоев и большую устойчивость к временным проблемам, можно снизить значения параметров задержки и порогов до рекомендованных, которые представлены в таблице ниже.
| Параметр | Windows Server 2012 или более поздней версии; | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 с | 2 секунды |
| SameSubnetThreshold | 40 пульсов | 10 пульсов (максимум) |
| CrossSubnetDelay | 1 с | 2 секунды |
| CrossSubnetThreshold | 40 пульсов | 20 пульсов (максимум) |
Используйте PowerShell для изменения параметров кластера.
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Для проверки изменений используйте PowerShell.
get-cluster | fl *subnet*
Рассмотрим следующий пример.
- Это изменение немедленно, перезапуск кластера или каких-либо ресурсов не требуется.
- Одни и те же значения подсети не должны превышать значения между подсетью.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Выбирайте менее строгие значения с учетом приемлемого времени простоя и срока до выполнения корректирующего действия в зависимости от вашего приложения, потребностей бизнеса и среды. Если превышать значения по умолчанию для Windows Server 2019 нельзя, по возможности старайтесь по крайней мере их соблюдать.
Значения по умолчанию приведены для справки в таблице ниже.
| Параметр | Windows Server 2019 | Windows Server 2016 | Windows Server версий от 2008 до 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 с | 1 с | 1 с |
| SameSubnetThreshold | 20 пульсов | 10 пульсов | 5 пульсов |
| CrossSubnetDelay | 1 с | 1 с | 1 с |
| CrossSubnetThreshold | 20 пульсов | 10 пульсов | 5 пульсов |
Дополнительные сведения см. в статье Настройка пороговых значений сети отказоустойчивого кластера.
Ослабленный мониторинг
Если настройка параметров пульса кластера и пороговых значений, как рекомендуется, недостаточно допустимо, и вы по-прежнему видите отработку отказа из-за временных проблем, а не истинных сбоев, вы можете настроить мониторинг группы доступности или FCI для более расслабленного. В некоторых сценариях может оказаться полезным временно расслабить мониторинг в течение определенного периода времени, учитывая уровень активности. Например, может потребоваться расслабить мониторинг при выполнении интенсивных рабочих нагрузок ввода-вывода, таких как резервное копирование баз данных, обслуживание индексов, DBCC CHECKDB и т. д. После завершения действия задайте для мониторинга менее расслабленные значения.
Предупреждение
Изменение этих параметров может маскировать основную проблему и использовать в качестве временного решения для уменьшения, а не устранения вероятности сбоя. Первопричину проблемы необходимо будет найти и устранить.
Начните с увеличения следующих параметров из значений по умолчанию для расслабленного мониторинга и настройки по мере необходимости:
| Параметр | Default value | Нестрогое значение | Description |
|---|---|---|---|
| Время ожидания проверки работоспособности | 30 000 | 60 000 | Определяет работоспособность первичной реплики или узла. Библиотека DLL sp_server_diagnostics ресурсов кластера возвращает результаты через интервал, равный 1/3 порога времени ожидания проверки работоспособности. Если sp_server_diagnostics данные не возвращаются или не возвращаются, библиотека DLL ресурсов ожидает полного интервала порога времени ожидания проверки работоспособности перед определением того, что ресурс не отвечает, и инициирует автоматическую отработку отказа, если это настроено. |
| Уровень условий сбоя | 3 | 2 | Условия, которые активируют автоматический переход на другой ресурс Существует пять уровней условий сбоя, которые варьируются от наименее ограничительного (уровень 1) до наиболее ограничительного (уровень 5). |
Используйте Transact-SQL (T-SQL), чтобы изменить условия проверки работоспособности и сбоя для групп доступности и экземпляров отказоустойчивого кластера.
Для групп доступности
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Для экземпляров отказоустойчивого кластера
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Для групп доступности начните со следующих рекомендуемых параметров и при необходимости скорректируйте их.
| Параметр | Default value | Нестрогое значение | Description |
|---|---|---|---|
| Время ожидания аренды | 20000 | 40000 | Предотвращает разделение. |
| Время ожидания сеанса | 10000 | 20000 | Проверяет наличие проблем связи между репликами. Время ожидания сеанса — это свойство реплики, которое определяет, сколько секунд эта реплика доступности будет ждать отклика на команду проверки связи, отправленную с подключенной реплики, перед тем, как признать попытку подключения неудачной. По умолчанию реплика ожидает ответа на команду ping 10 секунд. Это свойство реплики применимо только к подключению данной вторичной реплики к первичной реплике группы доступности. |
| Максимальное число сбоев за указанный период | 2 | 6 | Используется для предотвращения неопределенно долгого перемещения кластерного ресурса в случае сбоя нескольких узлов. Слишком низкое значение может привести к сбою группы доступности. Увеличьте это значение, чтобы избежать кратковременных перерывов в работе из-за проблем с производительностью. |
Прежде чем вносить изменения, учтите следующее.
- Не уменьшайте значения времени ожидания ниже значений по умолчанию.
- Используйте это уравнение для вычисления максимального значения времени ожидания аренды:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)
Начните с 40 секунд. Если вы используете расслабленныеSameSubnetThresholdзначения,SameSubnetDelayрекомендуемые ранее, не превышает 80 секунд для значения времени ожидания аренды. - Для реплик с синхронной фиксацией увеличение времени ожидания сеанса может привести к более долгому ожиданию HADR_sync_commit.
Время ожидания аренды
Используйте диспетчер отказоустойчивости кластеров, чтобы изменить параметры времени ожидания аренды для группы доступности. Подробные инструкции см. в документации по проверке работоспособности для аренды группы доступности SQL Server.
Время ожидания сеанса
Чтобы изменить время ожидания сеанса для группы доступности, используйте Transact-SQL (T-SQL).
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Максимальное число сбоев за указанный период
Используйте диспетчер отказоустойчивости кластеров для изменения значения Максимальное число сбоев за указанный период.
- На панели навигации выберите элемент Роли.
- В разделе Роли щелкните кластерный ресурс правой кнопкой мыши и выберите пункт Свойства.
- Перейдите на вкладку Отработка отказа и увеличьте значение Максимальное число сбоев за указанный период до нужного.
Ограничения ресурсов
Ограничения виртуальной машины или диска могут привести к возникновению узкого места, что влияет на работоспособность кластера и вызывает неудачный результат проверки работоспособности. Если у вас возникают проблемы из-за ограничений ресурсов, воспользуйтесь приведенными ниже рекомендациями.
- Используйте анализ ввода-вывода (предварительная версия) в портал Azure для выявления проблем с производительностью диска, которые могут привести к отработке отказа.
- Используйте последние сборки ОС, драйверов и SQL Server.
- Оптимизируйте SQL Server в среде виртуальных машин Azure, как описано в руководстве по производительности SQL Server на Виртуальных машинах Azure.
- Использование
- Уменьшите или распределите рабочую нагрузку, чтобы сократить использование ресурсов и избежать достижения ограничений.
- Настройте рабочую нагрузку SQL Server, если есть любая возможность, например
- добавьте или оптимизируйте индексы;
- обновляйте статистику по мере необходимости и возможности посредством полной проверки;
- используйте такие функции, как регулятор ресурсов (начиная с SQL Server 2014, только в выпуске Enterprise), чтобы ограничить использование ресурсов во время выполнения определенных рабочих нагрузок, таких как резервное копирование или обслуживание индекса;
- перейдите на виртуальную машину или диск с более высокими ограничениями, чтобы удовлетворить требования рабочей нагрузки.
Сеть
По возможности развертывайте виртуальные машины SQL Server в нескольких подсетях, чтобы не использовать Azure Load Balancer или имя распределенной сети (DNN) для маршрутизации трафика к решению HADR.
Используйте одну сетевую карту на сервер (узел кластера). Сеть Azure обладает физической избыточностью, что делает ненужными дополнительные сетевые адаптеры в кластере гостевых виртуальных машин Azure. Отчет проверки кластера предупреждает, что узлы доступны только в одной сети. Это предупреждение можно игнорировать в гостевых отказоустойчивых кластерах виртуальных машин Azure.
Ограничения пропускной способности для конкретной виртуальной машины используются для сетевых адаптеров, а добавление дополнительной сетевой карты не повышает производительность группы доступности для SQL Server на виртуальных машинах Azure. Таким образом, нет необходимости добавлять второй сетевой адаптер.
Несовместимая с RFC служба DHCP в Azure может привести к сбою при создании определенных конфигураций отказоустойчивого кластера. Такой сбой происходит потому, что сетевому имени кластера назначается дублирующий IP-адрес, например адрес, соответствующий одному из узлов кластера. Это актуально, если используются группы доступности, зависящие от функции отказоустойчивого кластера Windows.
Рассмотрим сценарий, в котором вы создаете и подключаете к сети кластер с двумя узлами.
- Кластер подключается к сети, и узел NODE1 запрашивает динамически назначаемый IP-адрес для сетевого имени кластера.
- Служба DHCP не назначает других IP-адресов, кроме собственного IP-адреса узла NODE1, так как она распознает, что запрос поступает от самого узла NODE1.
- Windows обнаруживает, что адрес-дубликат назначен как узлу NODE1, так и сетевому имени отказоустойчивого кластера, поэтому группе кластера по умолчанию не удается подключиться к сети.
- Группа кластера по умолчанию перемещается на узел NODE2. Узел NODE2 рассматривает IP-адрес узла NODE1 как IP-адрес кластера и подключает группу кластера по умолчанию к сети.
- Если узел NODE2 пытается установить соединение с узлом NODE1, пакеты, направляемые на NODE1, не покидают узел NODE2, поскольку он разрешает IP-адрес узла NODE1 на самого себя. Узлу NODE2 не удается установить соединение с узлом NODE1, что приводит к потере кворума и завершению работы кластера.
- Узел NODE1 может отправлять пакеты на узел NODE2, но NODE2 не может ответить. Узел NODE1 теряет кворум и завершает работу кластера.
Этого можно избежать путем назначения сетевому имени кластера неиспользуемого статического IP-адреса, чтобы подключить сетевое имя кластера к сети и добавить IP-адрес в Azure Load Balancer.
Если ядро СУБД SQL Server, прослушиватель группы доступности AlwaysOn, проба работоспособности экземпляра отказоустойчивого кластера, конечная точка зеркального отображения базы данных, IP-ресурс кластера или любой другой ресурс SQL настроен для использования порта в диапазоне от 49 152 до 65 536 ( динамический диапазон портов по умолчанию для TCP/IP), добавьте исключение для каждого порта. Это предотвращает динамическое назначение других системных процессов тем же портом. В следующем примере создается исключение для порта 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Важно настроить исключение порта, если порт не используется, в противном случае команда завершается ошибкой с сообщением "Процесс не может получить доступ к файлу, так как он используется другим процессом".
Чтобы убедиться, что исключения настроены правильно, используйте следующую команду: netsh int ipv4 show excludedportrange tcp
Установка этого исключения для порта IP-пробы группы доступности должна предотвратить такие события, как идентификатор события: 1069 с состоянием 10048. Это событие можно увидеть в событиях отказоустойчивого кластера Windows со следующим сообщением:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Это может быть вызвано внутренним процессом, который принимает тот же порт, что и порт пробы. Помните, что порт пробы используется для проверки состояния экземпляра внутреннего пула из Azure Load Balancer.
Если проба работоспособности не сможет получить ответ от внутреннего экземпляра, новые подключения не будут отправлены в этот серверный экземпляр до тех пор, пока проба работоспособности не будет выполнена повторно.
Известные проблемы
Ознакомьтесь с решениями некоторых распространенных проблем и ошибок.
Состязание ресурсов (в частности, операций ввода-вывода) приводит к отработке отказа
Исчерпание емкости ввода-вывода или ЦП для виртуальной машины может привести к отработку отказа группы доступности. Определение спор, которое происходит прямо перед отработой отказа, является наиболее надежным способом определить, что вызывает автоматическую отработку отказа.
Использование анализа операций ввода-вывода
Используйте анализ ввода-вывода (предварительная версия) в портал Azure для выявления проблем с производительностью диска, которые могут привести к отработке отказа.
Мониторинг метрик операций ввода-вывода в хранилище виртуальных машин
Отслеживайте Виртуальные машины Azure, чтобы просмотреть метрики использования операций ввода-вывода в хранилище, чтобы понять задержку на уровне виртуальной машины или диска.
Выполните следующие действия, чтобы проверить общее событие исчерпания операций ввода-вывода в виртуальной машине Azure.
Перейдите к виртуальной машине в портал Azure , а не виртуальные машины SQL.
Выберите метрики в разделе "Мониторинг", чтобы открыть страницу метрик.
Выберите местное время, чтобы указать интересующий вас диапазон времени и часовой пояс , локальный для виртуальной машины или UTC/GMT.
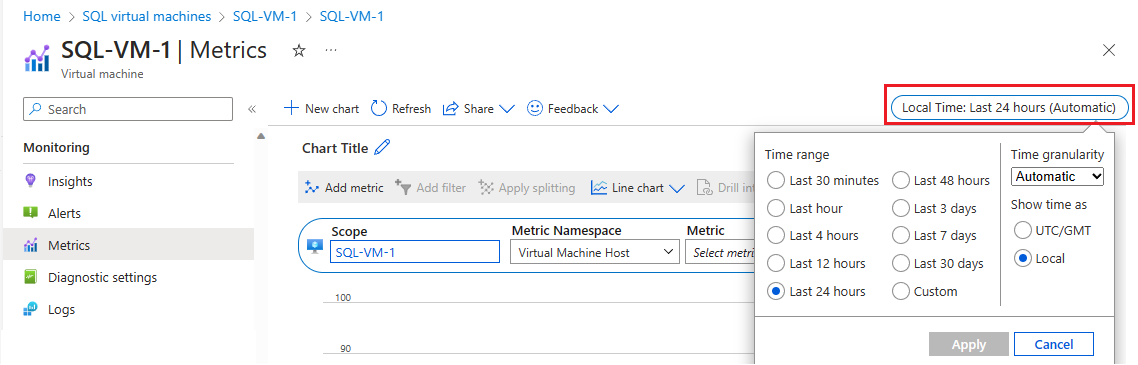
Нажмите кнопку "Добавить метрику", чтобы добавить следующие две метрики , чтобы просмотреть график:
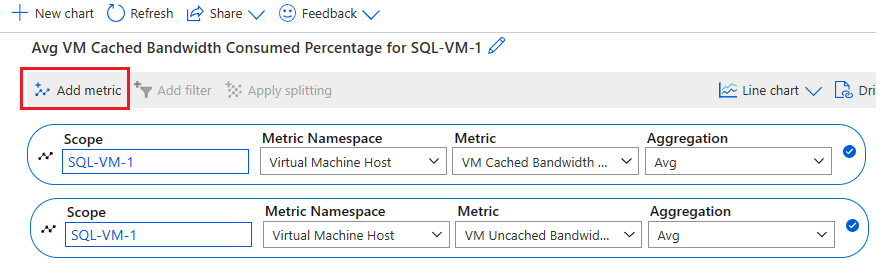
- Процент использования кэшированных пропускной способности виртуальной машины
- Процент использования некэшированной пропускной способности для виртуальной машины.
Узел виртуальной машины Azure вызывает отработку отказа
Возможно, что hostEvent виртуальной машины Azure приводит к отработке отказа группы доступности. Если вы считаете, что hostEvent виртуальной машины Azure вызвал отработку отказа, вы можете проверить журнал действий Azure Monitor и обзор Работоспособность ресурсов виртуальной машины Azure.
Журнал действий Azure Monitor — это журнал платформы в Azure, который предоставляет аналитические сведения о событиях уровня подписки. Журнал действий содержит такие сведения, как изменение ресурса или виртуальная машина. Журнал действий можно просмотреть в портал Azure или получить записи с помощью PowerShell и Azure CLI.
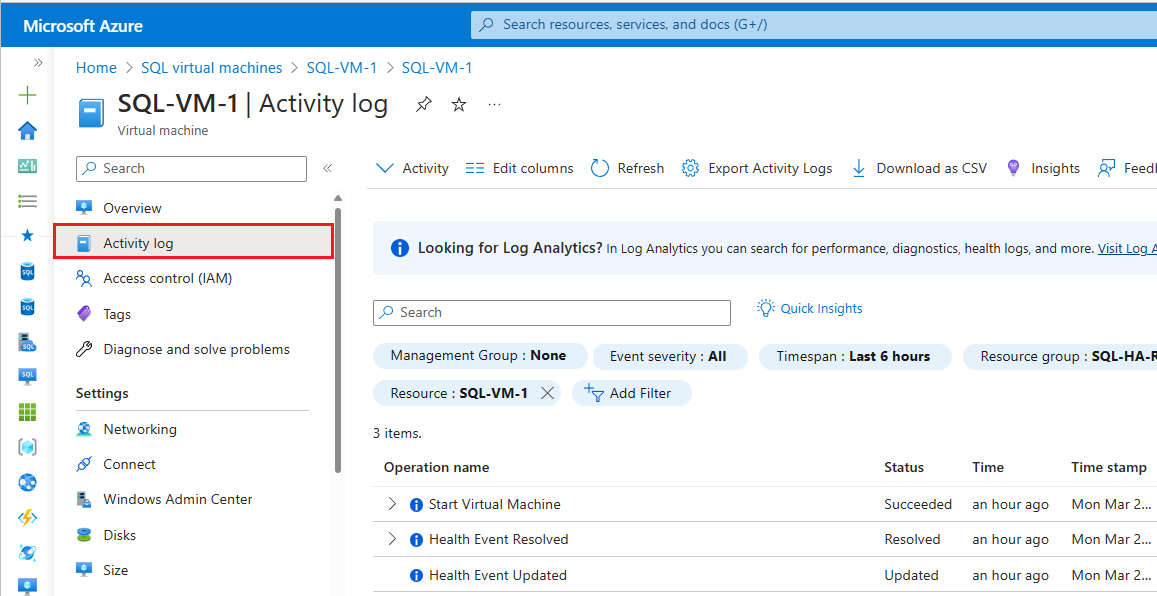
Чтобы проверить журнал действий Azure Monitor, выполните следующие действия.
Перейдите к виртуальной машине в портал Azure
Выбор журнала действий на панели "Виртуальная машина"
Выберите Timespan и выберите интервал времени при отработки отказа группы доступности. Выберите Применить.
Если в Azure есть дополнительные сведения о первопричине недоступности, инициированной платформой, эта информация может быть размещена на виртуальной машине Azure— Работоспособность ресурсов странице обзора до 72 часов после первоначальной недоступности. В настоящее время эта информация доступна только для виртуальных машин.
- Перейдите к виртуальной машине в портал Azure
- Выберите Работоспособность ресурсов в области работоспособности.
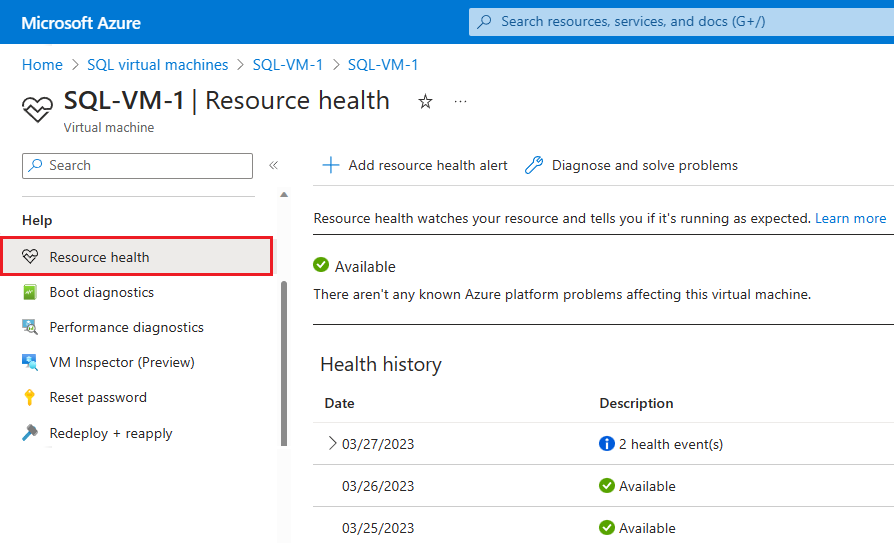
Вы также можете настроить оповещения на основе событий работоспособности на этой странице.
Узел кластера удален из членства
Если параметры пульса и порогового значения кластера Windows слишком агрессивны для вашей среды, в журнале системных событий часто отображается следующее сообщение.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Дополнительные сведения см. в статье Устранение неполадки кластера с идентификатором события 1135.
Срок аренды истек/ Аренда больше не действительна
Если мониторинг слишком агрессивный для вашей среды, может появиться частый запуск группы доступности или перезапуски FCI, сбои или отработка отказа. Кроме того, для групп доступности в журнале ошибок SQL Server могут появиться следующие сообщения:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Connection timeout
Если время ожидания сеанса слишком агрессивно для среды группы доступности, часто отображаются следующие сообщения:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Отработка отказа группы
Если значение Максимальное число сбоев за указанный период слишком мало и возникают временные сбои, группа доступности может перейти в состояние отказа. Увеличьте это значение, чтобы допускалось больше временных сбоев.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Событие 1196 . Сбой регистрации связанного DNS-имени ресурса сетевого имени
- Проверьте параметры NIC для каждого узла кластера, чтобы убедиться в отсутствии внешних записей DNS.
- Убедитесь, что запись A для кластера существует на внутренних DNS-серверах. Если нет, создайте новую запись A в DNS-сервере для объекта управления доступом к кластеру вручную и установите флажок "Разрешить всем прошедшим проверку подлинности пользователям обновлять записи DNS с тем же именем владельца".
- Переведите ресурс "имя кластера" с IP-ресурсом в автономный режим и исправьте его.
Событие 157. Диск был удивлен.
Это может произойти, если свойству "Дисковые пространства" AutomaticClusteringEnabled присвоено значение True для среды группы доступности. Укажите вместо него значение False. Кроме того, запуск отчета о проверке при использовании параметра "Хранилище" может привести к сбросу диска или неожиданному удалению. Регулирование системы хранилища также может вызвать событие внезапного удаления диска.
Событие 1206 — ресурс сетевого имени кластера не может быть подключен к сети.
Не удалось обновить объект компьютера, связанный с ресурсом, в домене. Убедитесь, что у вас есть соответствующие разрешения на домен
Ошибки кластеризации Windows
При настройке отказоустойчивого кластера Windows или его подключении могут возникнуть проблемы, если у вас нет портов службы кластеров, открытых для связи.
Если вы находитесь в Windows Server 2019 и не видите IP-адрес кластера Windows, вы настроили имя распределенной сети, которое поддерживается только в SQL Server 2019. Если у вас есть предыдущие версии SQL Server, можно удалить и повторно создать кластер с помощью имени сети.
Ознакомьтесь с другими ошибками отказоустойчивой кластеризации Windows и их решениями
Следующие шаги
Дополнительные сведения см. на следующих ресурсах:
- Параметры HADR для SQL Server на виртуальных машинах Azure
- Отказоустойчивый кластер Windows Server с SQL Server на виртуальных машинах Azure
- Группы доступности Always On с SQL Server на виртуальных машинах Azure
- Отказоустойчивый кластер Windows Server с SQL Server на виртуальных машинах Azure
- Экземпляры отказоустойчивого кластера с SQL Server на виртуальных машинах Azure
- Общие сведения об экземпляре отказоустойчивого кластера