Непрерывность бизнес-процессов и аварийное восстановление (BCDR) для Oracle в azure Виртуальные машины акселератор целевой зоны
Эта статья основана на рекомендациях и рекомендациях, определенных в области проектирования целевой зоны Azure для BCDR. В этой статье приведены рекомендации по проектированию и рекомендации по обеспечению непрерывности бизнес-процессов и аварийного восстановления (BCDR), доступные для развертываний рабочих нагрузок Oracle в Виртуальные машины инфраструктуры Azure.
Azure предоставляет службы для разработки высокодоступной и устойчивой архитектуры. В этом руководстве описаны различные варианты и рекомендации по проектированию высокого уровня доступности и аварийного восстановления баз данных Oracle в акселераторе целевой зоны Azure Виртуальные машины. В нем также описывается, как сопровождающие службы Azure настроены для обеспечения высокого уровня доступности для решения.
Первым шагом в создании устойчивой архитектуры для рабочей нагрузки является определение требований к доступности решения по целевой цели восстановления (RTO) и целевой точки восстановления (RPO) для различных уровней сбоя. RTO — это максимальное время, когда приложение недоступно после инцидента, а RPO — максимальное количество потери данных во время аварии. После определения требований к решению необходимо разработать архитектуру, чтобы обеспечить установленные уровни устойчивости и доступности.
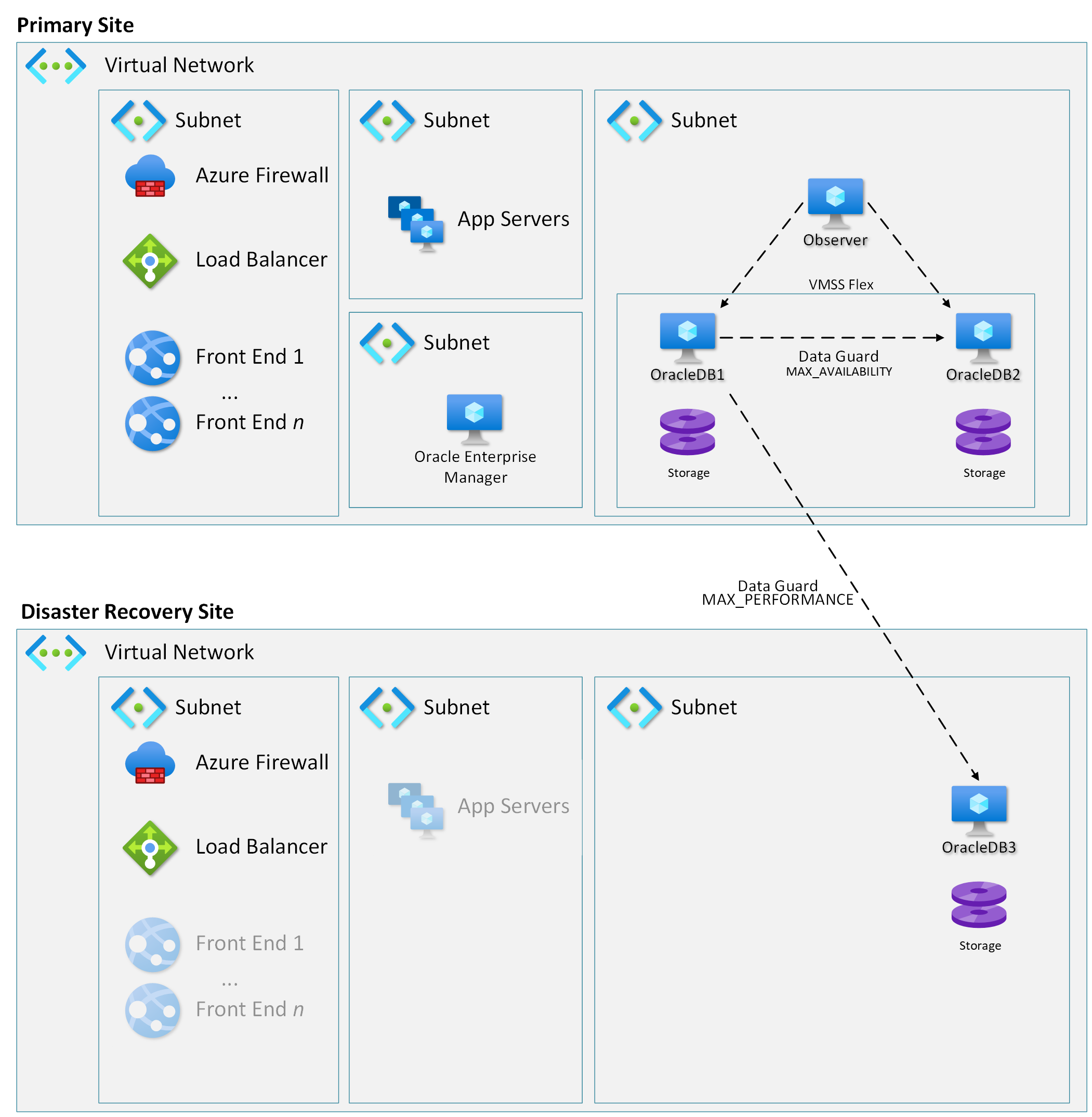
Oracle в рабочих нагрузках Azure в основном использует Data Guard, встроенную технологию реплика tion баз данных Oracle (как функцию выпуск Enterprise), чтобы обеспечить высокий уровень доступности и аварийного восстановления. Data Guard предлагает три режима защиты: максимальная производительность, максимальная доступность и максимальная защита. Выбор режима защиты зависит от архитектуры и конкретных требований RPO и RTO.
Высокий уровень доступности рабочих нагрузок Oracle в акселераторе целевой зоны Azure Виртуальные машины
Экземпляры виртуальных машин Azure, выполняющие рабочие нагрузки Oracle, получают преимущества от архитектуры группы доступности. Конфигурация высокой доступности обеспечивает реплика данных практически в режиме реального времени с потенциально быстрыми возможностями отработки отказа, но не обеспечивает защиту от сбоев на уровне центра обработки данных Azure или уровня региона.
Выберите правильный вариант высокого уровня доступности
Используйте следующую блок-схему, чтобы выбрать оптимальный вариант высокого уровня доступности для базы данных Oracle.

Высокий уровень доступности с помощью Data Guard в режиме максимальной доступности
Data Guard в режиме максимальной доступности обеспечивает максимальную доступность с нулевой обещанием потери данных (RPO=0) для обычных операций. Для высокодоступной конфигурации двух серверов баз данных Oracle, созданных в группе доступности, Azure предоставляет соглашение об уровне обслуживания 99,95 % для доступности служб.

Пошаговые инструкции по настройке Data Guard в Azure см. в статье "Реализация Oracle Data Guard на виртуальной машине Linux Azure".
Высокий уровень доступности с помощью Data Guard в режиме максимальной защиты
Если вам всегда требуется транзакционная копия базы данных, можно использовать Data Guard в максимальном режиме защиты. Однако максимальный режим защиты не позволяет транзакциям продолжаться, если резервная база данных недоступна. Поэтому, несмотря на использование групп доступности, соглашение об уровне обслуживания уменьшается до 99,9%x99.9%=99,8% при использовании максимального режима защиты. Эта конфигурация больше подходит для обеспечения согласованной копии данных, а не повышения доступности.
Другие атрибуты этой архитектуры совпадают с максимальным режимом доступности (то есть RPO=0, RTO<=2 мин).
Особые рекомендации по использованию для обеспечения высокой доступности
В следующих разделах описываются особые рекомендации по обеспечению высокого уровня доступности.
Использование зон доступности и групп доступности для обеспечения высокой доступности
Зоны доступности Azure — это центры обработки данных Azure в том же регионе Azure, что гарантирует <задержку в 2 мс. Хотя обычно используется для аварийного восстановления, как описано далее, их можно использовать для обеспечения высокой доступности вместо групп доступности. Однако необходимо убедиться, что решение может выполняться с задержкой и пропускной способностью, предоставленной между зонами доступности, которые вы используете.
Одним из преимуществ использования зон доступности по сравнению с группами доступности является то, что соглашение об уровне обслуживания увеличится с 99,95% до 99,99%.
Общий кластеризация хранилища для обеспечения высокой доступности
Общие технологии хранения кластеризация предоставляют уникальные атрибуты, которые помогут достичь бизнес-целей. Одна из таких технологий, которые можно адаптировать в Azure, — кластер Pacemaker/Corosync (PCS) с общим хранилищем. Управляемые диски или Azure NetApp Files можно использовать в качестве общего хранилища для экземпляров кластера PCS. Использование кластера PCS не дублирует данные и предоставляет виртуальную IP-службу со статическим IP-адресом или сетевым именем, который не изменяется при отработках отказа.
ПРИМЕЧАНИЕ. Кластер PCS не является сертифицированным решением Oracle. Учитывайте это при определении архитектуры высокой доступности.

Использование групп размещения близкого взаимодействия
Рекомендуется использовать группы размещения близкого взаимодействия, чтобы обеспечить минимальную задержку между серверами базы данных в одной группе доступности и между серверами баз данных и серверами приложений, чтобы свести к минимуму задержку в сети.
Аварийное восстановление для Oracle в рабочих нагрузках Azure
Архитектура аварийного восстановления обеспечивает устойчивость к сбоям, которые влияют на центр обработки данных Azure или регион или препятствуют работе приложений в целом регионе. В любом случае вы хотите переместить всю рабочую нагрузку в другой центр обработки данных или регион.
Как упоминалось ранее, архитектура аварийного восстановления должна основываться на требованиях к решению, как указано RTO и RPO. Так как архитектура аварийного восстановления создана для исключительных случаев сбоя, процесс отработки отказа выполняется вручную, а не для разработки высокого уровня доступности. Как правило, у вас должны быть более расслабленные требования к RTO и RPO, что может обеспечить более экономичные проекты.
В этом документе рассматриваются сценарии, в которых первичные и вторичные серверы находятся в Azure. Кроме того, для аварийного восстановления можно использовать основной сервер локального и дополнительного сервера в Azure. Дополнительные сведения об этом сценарии аварийного восстановления для базы данных Oracle 12c в среде Azure.
Выберите правильный вариант аварийного восстановления
Используйте следующую блок-схему, чтобы выбрать оптимальный вариант аварийного восстановления для базы данных Oracle.

Аварийное восстановление с помощью Data Guard
Data Guard можно использовать для реплика данных на сайт аварийного восстановления. Этот сайт может быть другой зоной доступности в одном регионе или может быть другим регионом в зависимости от требований к защите данных. Она также зависит от структуры зоны доступности, предоставленной на рабочем сайте. Использование Oracle Data Guard в сценарии аварийного восстановления аналогично сценарию высокой доступности, описанному ранее с несколькими важными различиями.
- При отработке отказа на вторичную реплика в сценарии высокой доступности вы отправляете Azure Load Balancer перенаправлению запросов на новый первичный объект.
- При отработе отказа на сайт аварийного восстановления вы выполняете отработку отказа всего решения на новый сайт.
Если сайт аварийного восстановления находится в другом регионе, необходимо разработать его для отработки отказа в зависимости от ваших требований.
Задержка между центрами обработки данных Azure, разделенными далеко друг от друга, и задержка между регионами или центрами обработки данных выше задержки в одном центре обработки данных. По этой причине для аварийного восстановления рекомендуется использовать Data Guard в максимальном режиме производительности. Если режим максимальной производительности слишком рискованно, можно использовать максимальный режим доступности с механизмом FarSync. Однако использование экземпляра FarSync активирует лицензирование Active Data Guard как в основных, так и в резервных средах. Дополнительные сведения см. в разделе "Сведения о лицензии".
Кроме того, при отправке данных в регионах Или центрах обработки данных Azure вы сталкиваетесь с затратами на исходящий трафик для данных (например, журналов повтора), которые отправляются на сайт аварийного восстановления. Если вам не нужно реплика te все данные в базе данных, вы можете реплика содержать только частичные данные при необходимости с помощью реплика tion и экономии на затратах на исходящий трафик.
Пошаговые инструкции по настройке Data Guard в Azure см. в статье "Реализация Oracle Data Guard на виртуальной машине Linux Azure".
Аварийное восстановление с помощью Golden Gate
Golden Gate — это логическое программное обеспечение реплика tion, которое позволяет в режиме реального времени реплика, фильтрацию и преобразование данных из исходной базы данных в целевую базу данных или между несколькими базами данных-источником. Эта функция гарантирует, что изменения в исходной базе данных реплика почти в режиме реального времени, что позволяет целевой базе данных быть актуальной с последними данными.
Golden Gate можно использовать для реплика te данных из базы данных-источника в вторичную в конфигурацию аварийного восстановления. Golden Gate может быть более практическим, например, если не все данные должны быть защищены. Golden Gate позволяет выборочно реплика таблицы и даже отфильтровать строки таблиц во время реплика, чтобы избежать реплика ненужных данных.
Пошаговое руководство по реализации Golden Gate в Azure см. в статье "Реализация Oracle Golden Gate на виртуальной машине Azure Linux".
Аварийное восстановление с помощью резервного копирования
Резервное копирование и восстановление были традиционным способом для архитектуры аварийного восстановления. Существует два основных компонента использования резервного копирования в качестве метода аварийного восстановления для баз данных Oracle в Azure:
Обеспечьте актуальность данных на сайте аварийного восстановления путем извлечения и перемещения резервных копий данных из базы данных.
Убедитесь в актуальном развертывании на сайте аварийного восстановления. Вы обновляете сайт, реплика одновременное развертывание всех сетевых компонентов, серверов приложений и конфигурации на сайте аварийного восстановления.
Когда дело доходит до реплика данных с помощью резервного копирования, вы можете изучить несколько различных вариантов, как описано в стратегиях резервного копирования для баз данных Oracle в Azure.
Рассмотрите возможность использования одного из следующих подходов к обслуживанию сайта аварийного восстановления:
- Одним из подходов является то, что вы не поддерживаете физическое развертывание на сайте аварийного восстановления, тем самым избегая усилий по обслуживанию и затрат на него. Для разработки и поддержания репозитория, который может реплика выполнять развертывание в качестве конфигурации с помощью единого щелчка мыши во время отработки отказа на сайт аварийного восстановления, можно использовать методики проектирования инфраструктуры как кода (IaC) и обеспечения надежности сайта аварийного восстановления. Этот метод оптимизирует затраты, так как не использует физические ресурсы до момента отработки отказа.
Внимание
При создании всего развертывания с нуля во время отработки отказа необходимо обеспечить соответствие требованиям RTO решения. Обычное моделирование и тестирование сценария аварийного восстановления необходимо, чтобы код развертывания не был нарушен.
- Второй подход — это развертывание и обслуживание масштабируемой версии рабочей среды. Версия, которая может работать точно для небольшой рабочей нагрузки и может быть масштабирована по мере необходимости во время отработки отказа для рабочей нагрузки. Этот параметр является наиболее используемым методом, особенно для сложных развертываний, где вы не хотите рисковать созданием всей среды или когда вы хотите быстро выполнить отработку отказа, чтобы обеспечить более низкую RTO.
Третий подход — это развертывание и обслуживание всего решения на сайте аварийного восстановления для самых быстрых времени RTO и отработки отказа за счет потенциального удвоения затрат.
Особые рекомендации по аварийному восстановлению
В следующих разделах описываются особые рекомендации по аварийному восстановлению.
Использование FarSync
Oracle Data Guard Far Sync не помогает с высоким уровнем доступности, но позволяет достичь нулевой возможности защиты от потери данных реплика для баз данных Oracle. Если рабочая нагрузка требует нулевой потери данных при сбое основного, ознакомьтесь со справочными архитектурами Oracle в Azure , чтобы получить дополнительные сведения об использовании Far Sync в Azure.
Выбор правильной технологии реплика данных
Помимо собственных технологий, описанных в этом документе, можно использовать любую технологию, которая упрощает реплика обработки данных в двух базах данных Oracle для обеспечения высокой доступности реплика и аварийного восстановления реплика для баз данных Oracle в Azure. Важно, чтобы выбранная технология служила вашим требованиям к решению в этих основных аспектах.
Задержка: время, затрачаемое на реплика обновление от основного до вторичных файлов для обеспечения высокой доступности и аварийного восстановления, должно соответствовать вашим требованиям к решению.
Пропускная способность: необходимо предоставить объем и стоимость пропускной способности, необходимо реплика te данных в секундах для обеспечения высокой доступности и аварийного восстановления. Azure уже предоставляет высокоскоростную сетевую инфраструктуру между зонами доступности. При рассмотрении реплика выхода из других регионов Azure для аварийного восстановления рассмотрите объем пропускной способности, которую можно достичь, а также затраты на исходящие данные, покидающие центр обработки данных Azure.
Влияние. Объем влияния реплика налагает на транзакции в базе данных-источнике должны соответствовать вашим требованиям к решению.
Потеря данных: объем потери данных, ожидаемый при резком сбое базы данных-источника, должен соответствовать требованиям решения.
Общая стоимость владения: стоимость приобретения (стороннее решение реплика tion) и количество усилий, необходимых для настройки и поддержания решения реплика tion, также следует учитывать и проверять, чтобы соответствовать требованиям решения.
Оптимизация экземпляра отработки отказа
При использовании защиты данных в режиме высокой доступности или высокой защиты также можно настроить автоматическую отработку отказа, чтобы при сбое сервера-источника сервер-получатель автоматически отображался. Настроив серверы приложений соответствующим образом, вы можете убедиться, что время простоя приложения близко к нулю во время отработки отказа.
В этой реализации, так как база данных должна служить таким же образом после отработки отказа, сервер-получатель должен быть настроен с той же емкостью ЦП, памяти и ввода-вывода, что и основной сервер. В этом случае вам потребуется поддерживать высокую емкость с дополнительным сервером, который увеличит затраты на базу данных Azure и лицензии на базу данных Oracle. Сервер-получатель больше всего не обрабатывает запросы пользователей.
Azure уже предоставляет 99,9 % доступности для виртуальных машин в зоне доступности, как указано в соглашении об уровне обслуживания виртуальной машины (SLA). При сохранении вторичной реплика базы данных в той же зоне доступности, другой зоне доступности или другом регионе с помощью любой технологии реплика tion данных можно оптимизировать вторичную емкость.
Благодаря этому подходу базы данных-получателей настраиваются с учетом емкости, необходимой для обновления. При сбое база данных-получатель изменяется, чтобы создать ее до той же емкости, что и исходная первичная база данных. Эта операция выполняется только при сбое, поэтому во время нормальной работы вы оплачиваете только часть стоимости исходного сервера. Так как база данных-источник в данный момент не работает, вам не потребуются другие лицензии на базу данных Oracle.
Емкость, необходимая для работы базы данных-получателя в качестве назначения реплика tion, зависит от используемой технологии реплика. По сути, рабочая нагрузка в системе OLTP транзакций состоит в основном из запросов на чтение. Например, 90%-10% или 95%-5% параметров чтения и записи распространены в приложении OLTP. Данные реплика, по сути, реплика приводит к написанию запросов в исходной базе данных. При этой настройке разумно ожидать, что база данных-получатель будет работать с 1/10-й (если коэффициент чтения-записи 90%-10%) или даже 1/10-й емкости базы данных-источника.
Также рекомендуется автоматизировать процедуры отработки отказа, чтобы обеспечить корпоративные стандарты во время отработки отказа. Этот же процесс можно разработать для включения операций изменения размера сервера, упрощающих комплексный процесс.
Топология сети для защиты служб и защиты данных
Для достижения высокого уровня доступности и аварийного восстановления требуется финансовое и бизнес-решение, которое балансирует время восстановления (RTO) и потенциальную потерю данных (RPO) с другими лицензиями Oracle, обслуживанием виртуальных машин и затратами на передачу данных для реализации. Размещение рабочей нагрузки на одной виртуальной машине Azure обеспечивает базовую защиту от распространенных сбоев оборудования и обеспечивает наименее затратное решение. Однако, поскольку сбой на одной виртуальной машине, скорее всего, приведет к простою и потере данных, рабочие среды должны включать в себя базу данных Oracle, размещенную на отдельной виртуальной машине с Oracle Data Guard. Правильно настройте защиту данных для реплика tion данных с помощью одной или нескольких следующих архитектур в зависимости от ваших требований.
- Оптимальный RTO и RPO. Чтобы свести к минимуму задержку, включите базу данных-получатель Oracle на отдельной виртуальной машине в пределах одной зоны доступности и в группе размещения близкого взаимодействия в качестве базы данных-источника.
- Защита данных от сбоя центра обработки данных. Размещение вторичной виртуальной машины во второй базе данных увеличивает защиту данных в случае сбоя всего центра обработки данных. Задержка между базой данных-источником и базой данных-получателем может составлять до 2 мс, что может повлиять на производительность, RTO и RPO.
- Защита данных от регионального сбоя. Чтобы расширить защиту, чтобы предотвратить потерю данных из регионального сбоя Azure, базу данных-получатель можно разместить в другом регионе. Так как задержка между регионами может составлять от 30 мс до 300 мс, влияние рабочей нагрузки и RTO и RPO может увеличиться. Заранее оцените эту задержку.
Для обеспечения непрерывности бизнес-процессов требуется интегрированный подход, включающий все компоненты рабочей нагрузки. Сетевая инфраструктура является основным компонентом для любой рабочей нагрузки в Azure и должна соответствовать архитектуре высокого уровня доступности и аварийного восстановления.
- Oracle Data Guard обеспечивает высокий уровень доступности и (в большинстве сценариев) обеспечивает достаточную поддержку распространенных сбоев. При размещении виртуальных машин в группах доступности все виртуальные машины и службы в одном решении должны находиться в одной зоне доступности, чтобы снизить задержку в сети. Кроме того, по той же причине службы должны совместно использовать одну и ту же виртуальную сеть.
- Для другой защиты виртуальные машины могут быть стратегически размещены в отдельных зонах доступности, а не в одной зоне доступности. Такой подход может предотвратить простой во время сбоя центра обработки данных.
- Для крайней защиты база данных-получатель может размещаться в другом регионе Azure с непрерывными обновлениями, примененными к Oracle Data Guard, с помощью пиринга глобальной виртуальной сети. Эта защита позволяет применять обновления данных к дополнительному региону в частном порядке через магистраль Майкрософт. Ресурсы взаимодействуют напрямую, без шлюзов, дополнительных прыжков или передачи через общедоступный Интернет. Этот параметр сети позволяет использовать подключение с высокой пропускной способностью и низкой задержкой между одноранговых виртуальных сетей в разных регионах. Пиринг глобальной виртуальной сети можно использовать для подключения основного сайта к сайту аварийного восстановления в другом регионе через высокоскоростную сеть.
Сводка по устойчивости к различным типам сбоев
| Сценарий сбоя | Сценарий Oracle в Azure HA/DR | RPO/RTO |
|---|---|---|
| Сбой одного компонента (узел, стойка, охлаждение, сеть, питание) | Data Guard с двумя узлами в одной группе доступности в одном центре обработки данных. — защищает от сбоя одного экземпляра. — приведет к простою, если весь центр обработки данных отключен. |
RPO=0 RTO<=2 мин — использование наблюдателя для быстрой отработки отказа — Использование режима MAX_AVAILABILITY или MAX_PROTECTION для Data Guard. |
| Сбой Центра обработки данных | Data Guard с двумя узлами в отдельных зонах доступности. — защищает от сбоя центра обработки данных. — приведет к простою, если весь регион отключен. — требуется дополнительная конфигурация отработки отказа для серверов приложений для управления задержкой сети. |
RPO<=5 мин RTO<=5 мин — Использование режима MAX_PERFORMANCE для Data Guard RPO=0 RTO<=5 мин — Использование режима MAX_AVAILABILITY для Data Guard |
| Сбой региона | Data Guard с двумя узлами в отдельных регионах Azure: — защищает от региональных сбоев — требуется дополнительная конфигурация отработки отказа для серверов приложений для управления задержкой сети. |
RPO>=10 мин RTO>=15 мин — Использование режима MAX_PERFORMANCE для Data Guard. |
| Резервные копии, отправленные в другой регион Azure: — защищает от региональных сбоев. — во время отработки отказа требуется настроить всю среду Azure в целевом регионе. |
RPO>=24 часа RTO>=4 часа |
Следующие шаги
Узнайте о рекомендациях по проектированию Oracle в Azure Виртуальные машины безопасности акселератора целевой зоны в сценарии корпоративного масштаба.
Ознакомьтесь с рекомендациями по безопасности oracle в azure Виртуальные машины акселераторе целевой зоны.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по