Начало работы с сбором измененных данных в аналитическом хранилище для Azure Cosmos DB
Область применения: ![]() Nosql
Nosql ![]() MongoDB
MongoDB
Используйте сбор измененных данных (CDC) в аналитическом хранилище Azure Cosmos DB в качестве источника для Фабрика данных Azure или Azure Synapse Analytics для записи конкретных изменений в данные.
Примечание.
Обратите внимание, что связанный интерфейс службы для API Azure Cosmos DB для MongoDB еще недоступен в потоке данных. Однако вы сможете использовать конечную точку документа учетной записи с интерфейсом связанной службы Azure Cosmos DB для NoSQL в качестве рабочей области, пока связанная служба Mongo не будет поддерживаться. В связанной службе NoSQL выберите "Ввод вручную", чтобы указать сведения о учетной записи Cosmos DB и использовать конечную точку документа учетной записи (например: ) вместо конечной точки MongoDB (например: https://[your-database-account-uri].documents.azure.com:443/mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Необходимые компоненты
- Существующая учетная запись Azure Cosmos DB.
- Если у вас есть подписка Azure, создайте новую учетную запись.
- Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
- Кроме того, перед фиксацией можно воспользоваться бесплатной службой Azure Cosmos DB.
Включение аналитического хранилища
Сначала включите Azure Synapse Link на уровне учетной записи и включите аналитическое хранилище для контейнеров, подходящих для рабочей нагрузки.
Включение Azure Synapse Link: включение Azure Synapse Link для учетной записи Azure Cosmos DB
Включите аналитическое хранилище для контейнеров:
Вариант Руководство Включение для конкретного нового контейнера Включение Azure Synapse Link для новых контейнеров Включение для конкретного существующего контейнера Включение Azure Synapse Link для существующих контейнеров
Создание целевого ресурса Azure с помощью потоков данных
Функция отслеживания измененных данных аналитического хранилища доступна через функцию потока данных Фабрика данных Azure или Azure Synapse Analytics. В этом руководстве используйте Фабрика данных Azure.
Внимание
Вы также можете использовать Azure Synapse Analytics. Сначала создайте рабочую область Azure Synapse, если у вас еще нет. В созданной рабочей области выберите вкладку "Разработка ", выберите "Добавить новый ресурс" и выберите поток данных.
Создайте Фабрика данных Azure, если у вас еще нет.
Совет
По возможности создайте фабрику данных в том же регионе, где находится учетная запись Azure Cosmos DB.
Запустите только что созданную фабрику данных.
В фабрике данных выберите вкладку "Потоки данных" и выберите "Создать поток данных".
Присвойте только что созданному потоку данных уникальное имя. В этом примере поток данных называется
cosmoscdc.

Настройка параметров источника для контейнера аналитического хранилища
Теперь создайте и настройте источник для потоков данных из аналитического хранилища учетной записи Azure Cosmos DB.
Выберите Добавить источник.
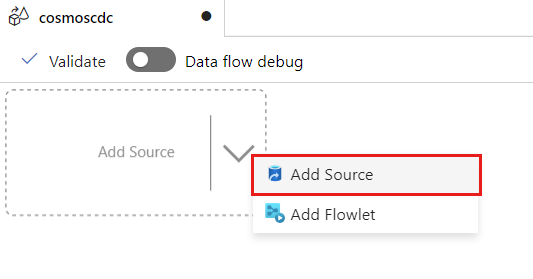
В поле имени потока вывода введите cosmos.
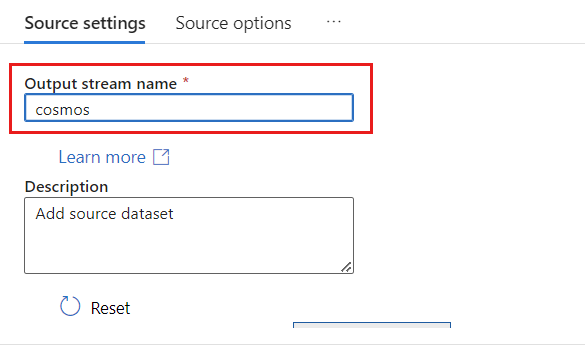
В разделе "Тип источника" выберите "Встроенный".
В поле набора данных выберите Azure — Azure Cosmos DB для NoSQL.
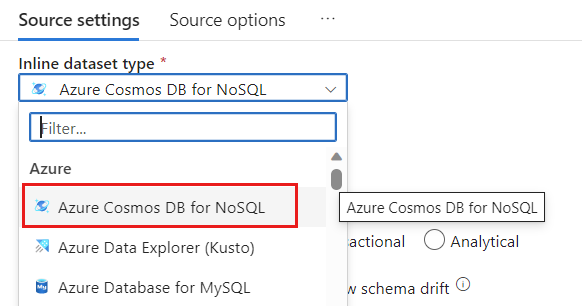
Создайте связанную службу для учетной записи с именем cosmoslinkedservice. Выберите имеющуюся учетную запись Azure Cosmos DB для NoSQL в всплывающем окне "Новая связанная служба " и нажмите кнопку "ОК". В этом примере мы выбираем уже существующую учетную запись Azure Cosmos DB для NoSQL и базу данных с именем
msdocs-cosmos-sourcecosmicworks.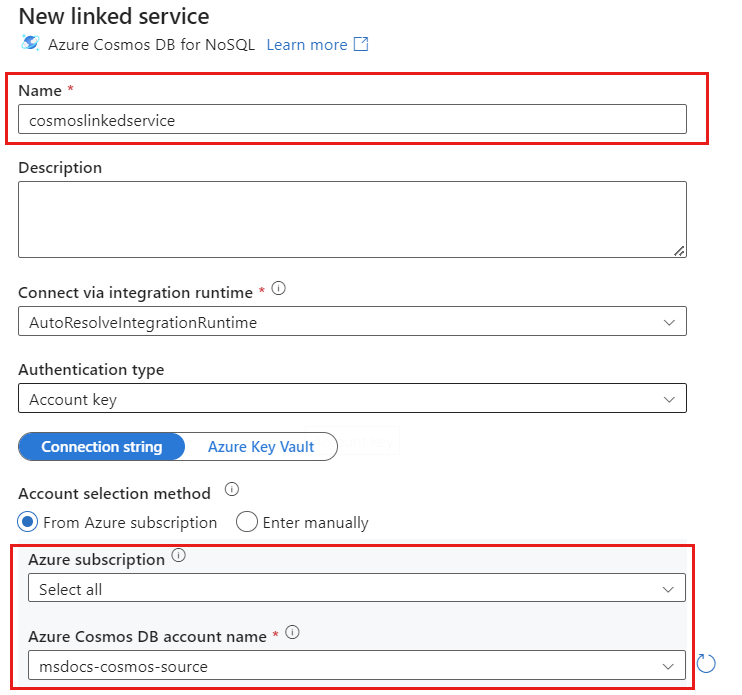
Выберите "Аналитический " для типа хранилища.
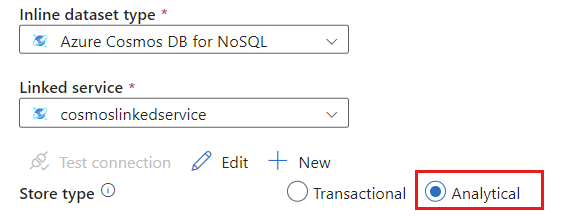
Перейдите на вкладку " Параметры источника".
В параметрах источника выберите целевой контейнер и включите отладку потока данных. В этом примере контейнер называется
products.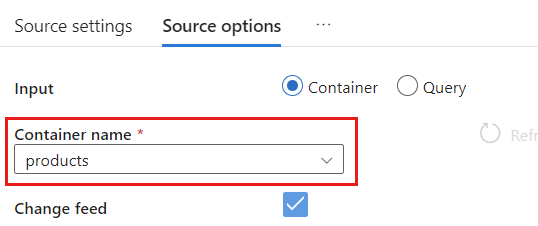
Выберите отладку потока данных. Во всплывающем диалоговом окне отладки потока данных сохраните параметры по умолчанию и нажмите кнопку "ОК".
Вкладка " Параметры источника" также содержит другие параметры, которые вы можете включить. В этой таблице описаны следующие параметры:
| Вариант | Описание |
|---|---|
| Запись промежуточных обновлений | Включите этот параметр, если вы хотите записать журнал изменений в элементы, включая промежуточные изменения между считываниями измененных данных. |
| Удаление записей | Включите этот параметр для записи записей, удаленных пользователем, и примените их к приемнику. Удаление невозможно применить к Azure Data Explorer и приемникам Azure Cosmos DB. |
| Сбор списков TTL хранилища транзакций | Включите этот параметр для записи удаленных записей транзакций Azure Cosmos DB (время в реальном времени) и применения к приемнику. TTL-deletes нельзя применять к приемникам Azure Data Explorer и Azure Cosmos DB. |
| Пакетная обработка в байтах | Этот параметр фактически имеет гигабайты. Укажите размер в гигабайтах, если вы хотите пакетировать веб-каналы отслеживания измененных данных |
| Дополнительные конфигурации | Дополнительные конфигурации аналитического хранилища Azure Cosmos DB и их значения. (например: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Работа с параметрами источника
При проверке любого из Capture intermediate updatesCapture Deltesпараметров и Capture Transactional store TTLs параметров процесс CDC создаст и заполняет __usr_opType поле в приемнике следующими значениями:
| значение | Описание | Вариант |
|---|---|---|
| 1 | UPDATE | Запись промежуточных обновлений |
| 2 | ВСТАВИТЬ | Параметр вставки отсутствует, он включен по умолчанию |
| 3 | USER_DELETE | Удаление записей |
| 4 | TTL_DELETE | Сбор списков TTL хранилища транзакций |
Если необходимо отличить удаленные записи TTL от документов, удаленных пользователями или приложениями, проверьте оба Capture intermediate updates варианта Capture Transactional store TTLs . Затем необходимо адаптировать процессы ИЛИ приложения ИЛИ запросы CDC для использования __usr_opType в соответствии с потребностями бизнеса.
Совет
Если для конечных потребителей требуется восстановить порядок обновлений с параметром "захват промежуточных обновлений", поле метки времени _ts системы можно использовать в качестве поля упорядочивания.
Создание и настройка параметров приемника для операций обновления и удаления
Сначала создайте простой приемник Хранилище BLOB-объектов Azure, а затем настройте приемник для фильтрации данных только для определенных операций.
Создайте учетную запись Хранилище BLOB-объектов Azure и контейнер, если у вас еще нет учетной записи. В следующих примерах мы будем использовать учетную запись с именем
msdocsblobstorageи контейнером с именемoutput.Совет
Если это возможно, создайте учетную запись хранения в том же регионе, где находится учетная запись Azure Cosmos DB.
Еще в Фабрика данных Azure создайте приемник для измененных данных, полученных из
cosmosисточника.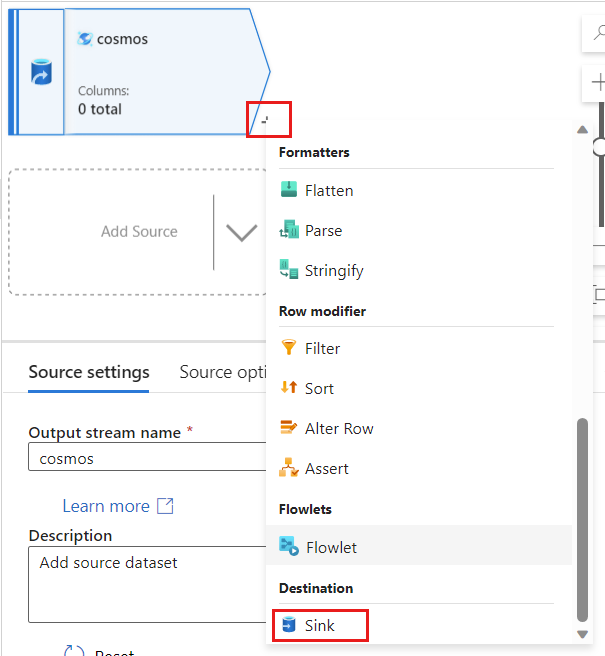
Присвойте приемнику уникальное имя. В этом примере приемник называется
storage.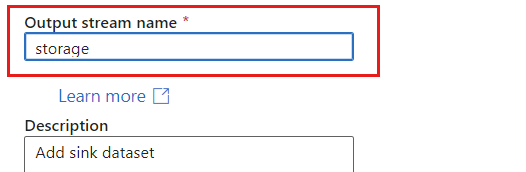
В разделе "Тип приемника" выберите "Встроенный". В поле набора данных выберите Delta.
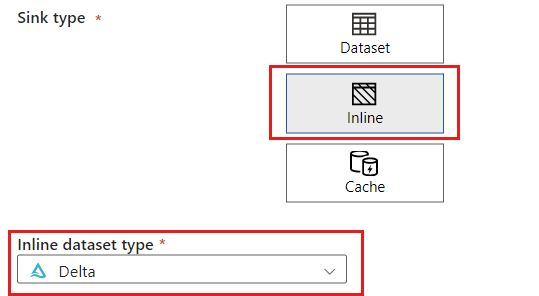
Создайте связанную службу для учетной записи с помощью Хранилище BLOB-объектов Azure именованной службы storagelinkedservice. Выберите существующую учетную запись Хранилище BLOB-объектов Azure в всплывающем окне "Новая связанная служба" и нажмите кнопку "ОК". В этом примере мы выбираем уже существующую учетную запись Хранилище BLOB-объектов Azure с именем
msdocsblobstorage.
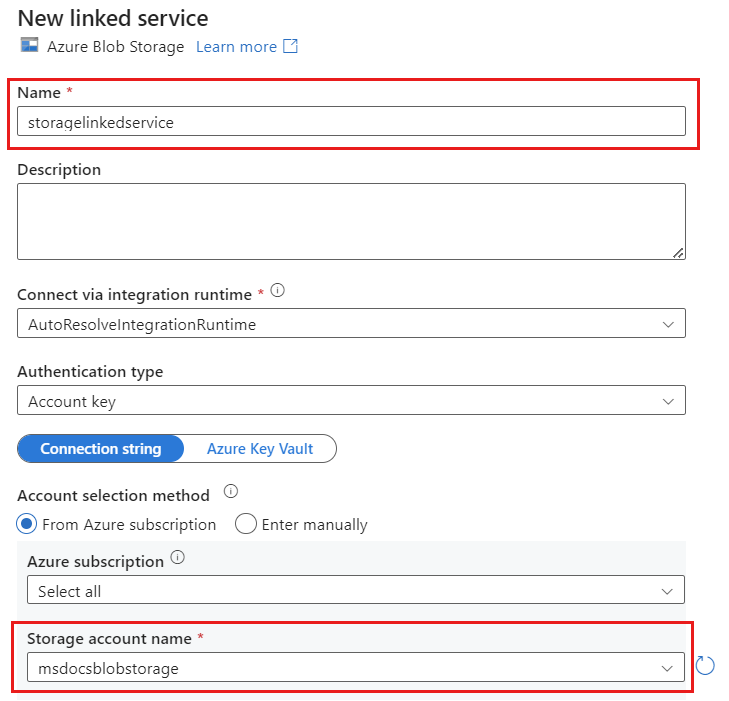
Выберите вкладку Параметры.
В параметрах задайте путь к папке имени контейнера BLOB-объектов. В этом примере имя контейнера —
output.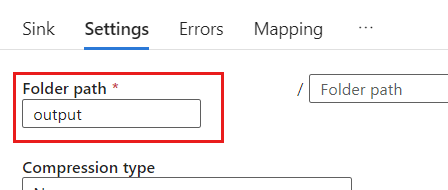
Найдите раздел метода Update и измените выбранные параметры, чтобы разрешить только операции удаления и обновления. Кроме того, укажите ключевые столбцы в виде списка столбцов, используя поле
{_rid}в качестве уникального идентификатора.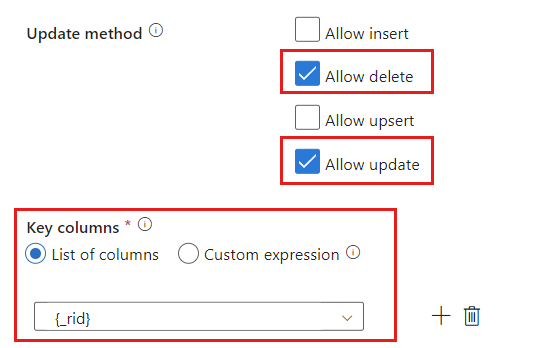
Выберите "Проверить" , чтобы убедиться, что вы не сделали никаких ошибок или упущений. Затем выберите "Опубликовать ", чтобы опубликовать поток данных.
Планирование выполнения отслеживания измененных данных
После публикации потока данных можно добавить новый конвейер для перемещения и преобразования данных.
Создание нового конвейера. Присвойте конвейеру уникальное имя. В этом примере конвейер называется
cosmoscdcpipeline.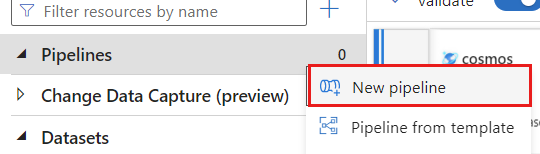
В разделе "Действия" разверните параметр перемещения и преобразования, а затем выберите поток данных.
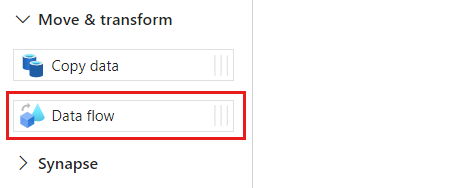
Присвойте действию потока данных уникальное имя. В этом примере действие называется
cosmoscdcactivity.На вкладке "Параметры" выберите поток данных, созданный
cosmoscdcранее в этом руководстве. Затем выберите размер вычислительных ресурсов на основе тома данных и требуемой задержки для рабочей нагрузки.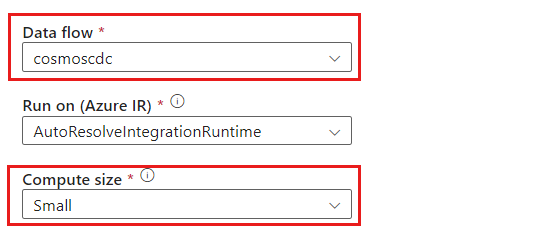
Совет
Для добавочных размеров данных больше 100 ГБ рекомендуется использовать настраиваемый размер с числом ядер 32 (+16 ядер драйверов).
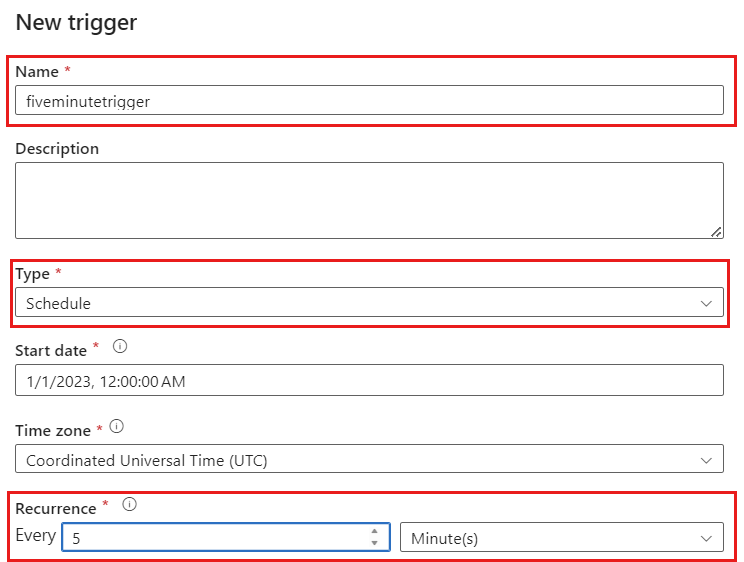
Выберите " Добавить триггер". Запланируйте выполнение этого конвейера по курсу, который имеет смысл для рабочей нагрузки. В этом примере конвейер настраивается для выполнения каждые пять минут.
Примечание.
Минимальное окно повторения для выполнения отслеживания измененных данных составляет одну минуту.
Выберите "Проверить" , чтобы убедиться, что вы не сделали никаких ошибок или упущений. Затем выберите "Опубликовать ", чтобы опубликовать конвейер.
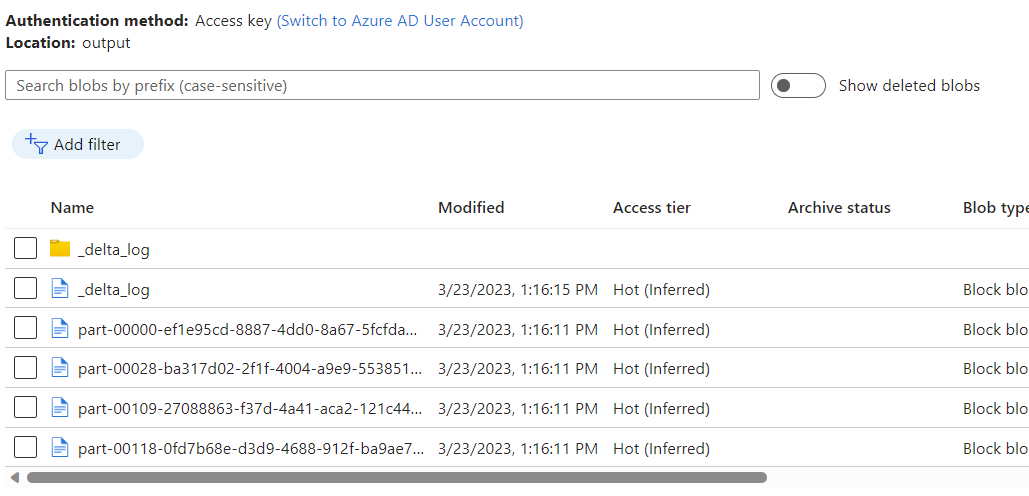
Просмотрите данные, помещенные в контейнер Хранилище BLOB-объектов Azure в качестве выходных данных потока данных с помощью аналитического хранилища Azure Cosmos DB для отслеживания измененных данных.
Примечание.
Время запуска начального кластера может занять до трех минут. Чтобы избежать времени запуска кластера в последующих выполнениях записи измененных данных, настройте время запуска кластера dataflow для динамического значения. Дополнительные сведения о среде выполнения и TTL см. в Фабрика данных Azure среды выполнения интеграции.
Параллельно работающие задания
Размер пакета в исходных параметрах или ситуациях, когда приемник замедляет прием потока изменений, может привести к одновременному выполнению нескольких заданий. Чтобы избежать этой ситуации, задайте для параметра параллелизма значение 1 в параметрах конвейера, чтобы убедиться, что новые выполнения не активируются до завершения текущего выполнения.