Копирование данных из SAP HANA с помощью Фабрики данных Azure или Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в Фабрике данных Azure и конвейерах Synapse Analytics копировать данные из таблицы SAP HANA. Это продолжение статьи об обзоре действия копирования, в которой представлены общие сведения о действии копирования.
Совет
Сведения об общей поддержке сценария интеграции данных SAP см. в технической документации по интеграции данных SAP, где приводятся подробная информация, сравнение и рекомендации для каждого соединителя SAP.
Поддерживаемые возможности
Соединитель таблиц SAP HANA поддерживает следующие возможности:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/приемник) | (2) |
| Действие поиска | (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, см. в таблице Поддерживаемые хранилища данных и форматы.
В частности, этот соединитель SAP HANA поддерживает:
- Копирование данных из всех версий базы данных SAP HANA.
- Копирование данных из информационных моделей HANA (например, представлений "Аналитика" и "Вычисление") и таблиц со строками и столбцами.
- копирование данных с использованием базовой проверки подлинности или проверки подлинности Windows.
- Параллельное копирование из источника SAP HANA. Дополнительные сведения см. в разделе Параллельное копирование из SAP HANA.
Совет
Чтобы скопировать данные в хранилище данных SAP HANA, используйте универсальный соединитель ODBC. Дополнительные сведения см. в разделе Приемник SAP HANA. Обратите внимание, что связанные службы для соединителя SAP HANA и соединитель ODBC нельзя использовать повторно, так как они имеют разные типы.
Необходимые компоненты
Чтобы использовать этот соединитель SAP HANA, сделайте следующее:
- Настроить локальную среду выполнения интеграции. Дополнительные сведения см. в статье Создание и настройка локальной среды выполнения интеграции.
- Установите на компьютере среды выполнения интеграции драйвер ODBC SAP HANA. Драйвер ODBC для SAP HANA можно скачать на странице SAP Software Download Center (Центр загрузки программного обеспечения SAP). Выполните поиск по ключевой фразе SAP HANA CLIENT for Windows.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
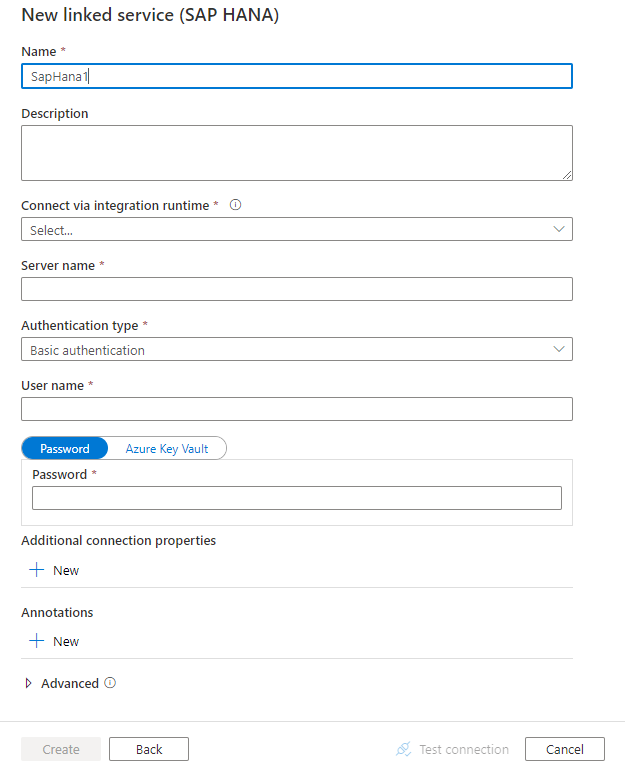
Создание связанной службы для SAP HANA с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для SAP HANA с помощью пользовательского интерфейса на портале Azure.
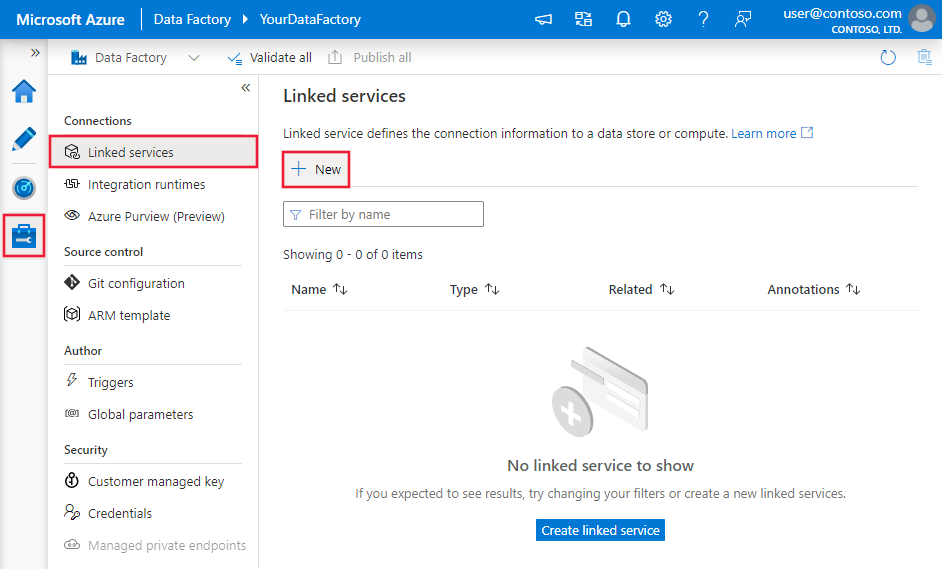
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Найдите SAP и выберите соединитель SAP HANA.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
В следующих разделах содержатся сведения о свойствах, которые используются для определения сущностей фабрики данных, относящихся к соединителю SAP HANA.
Свойства связанной службы
Для связанной службы SAP HANA поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение SapHana | Да |
| connectionString | Укажите сведения, необходимые для подключения к SAP HANA с помощью обычной проверки подлинности или проверки подлинности Windows. Ознакомьтесь с приведенными ниже примерами. В строке подключения параметр "сервер/порт" является обязательным (порт по умолчанию — 30015), а имя пользователя и пароль являются обязательными при использовании обычной проверки подлинности. Дополнительные расширенные параметры см. в разделе Свойства подключения SAP HANA ODBC Вы можете поместить пароль в хранилище Azure Key Vault и извлечь конфигурацию пароля из строки подключения. Дополнительные сведения см. в статье Хранение учетных данных в Azure Key Vault. |
Да |
| userName | При использовании проверки подлинности Windows укажите имя пользователя. Пример: user@domain.com |
No |
| password | Укажите пароль для учетной записи пользователя. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | No |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Требуется локальная среда IR, как упоминалось в разделе Предварительные требования. | Да |
Пример: использование обычной проверки подлинности
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование проверки подлинности Windows
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Если вы раньше использовали связанную службу SAP HANA с перечисленными ниже полезными данными, такая система пока поддерживается и не требует изменений, но мы рекомендуем при любом удобном случае перейти на новую версию.
Пример:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных SAP HANA.
Для копирования данных из SAP HANA поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо задать значение SapHanaTable | Да |
| schema | Имя схемы в базе данных SAP HANA. | Нет (если свойство query указано в источнике действия) |
| table | Имя таблицы в базе данных SAP HANA. | Нет (если свойство query указано в источнике действия) |
Пример:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Если вы ранее использовали типизированный набор данных RelationalTable, он пока поддерживается и не требует изменений, но мы рекомендуем при любом удобном случае перейти на новую версию.
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником SAP HANA.
SAP HANA в качестве источника
Совет
Чтобы эффективно получать данные из SAP HANA с использованием секционирования данных, изучите дополнительные сведения в разделе Параллельное копирование из SAP HANA.
Для копирования данных из SAP HANA в разделе источник действия копирования поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение SapHanaSource | Да |
| query | Указывает SQL-запрос для чтения данных из экземпляра SAP HANA. | Да |
| partitionOptions | Задает параметры секционирования данных, используемые для получения данных из SAP HANA. Дополнительные сведения см. в разделе Параллельное копирование из SAP HANA. Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и SapHanaDynamicRange. Дополнительные сведения см. в разделе Параллельное копирование из SAP HANA. PhysicalPartitionsOfTable может использоваться только при копировании данных из таблицы, но не из запроса. Если параметр секционирования включен (любое значение кроме None), степень параллелизма для параллельной загрузки данных из SAP HANA задается параметром parallelCopies в действии копирования. |
Ложный |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение SapHanaDynamicRange. |
Ложный |
| partitionColumnName | Укажите имя столбца источника, который будет использоваться секцией для параллельного копирования. Если значение не указано, автоматически определяется индекс или первичный ключ таблицы и используется в качестве столбца секционирования. Применяется, если параметр секции имеет значение SapHanaDynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfHanaDynamicRangePartitionCondition в предложении WHERE. Пример см. в разделе Параллельное копирование из SAP HANA. |
Да при использовании SapHanaDynamicRange секции. |
| packetSize | Указывает размер сетевого пакета (в килобайтах) для разбиения данных на несколько блоков. При наличии большого объема данных для копирования увеличение размера пакета может в большинстве случаев повысить скорость чтения из SAP HANA. При изменении размера пакета рекомендуется выполнить тест производительности. | № Значение по умолчанию — 2048 (2 МБ). |
Пример:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Если прежде использовался типовой источник RelationalSource, он пока поддерживается как есть, но мы рекомендуем в дальнейшем использовать более новую версию.
Параллельное копирование из SAP HANA
Соединитель SAP HANA предоставляет встроенную функцию секционирования данных для параллельного копирования из SAP HANA. Параметры секционирования данных можно найти в исходной таблице для действия копирования.
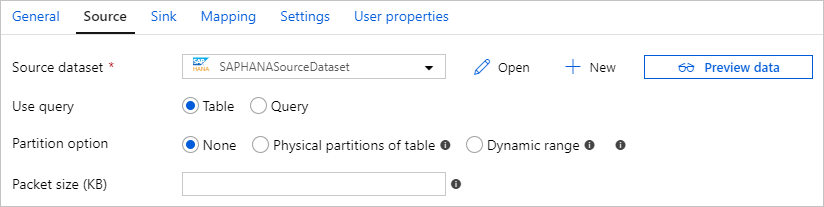
Если включено копирование с секционированием, служба выполняет параллельные запросы к источнику SAP HANA для получения данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если задать для parallelCopies значение 4, служба одновременно генерирует и запускает четыре запроса на основе указанного вами параметра и настроек раздела, и каждый запрос извлекает часть данных из SAP HANA.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при получении большого объема данных из SAP HANA. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически обнаруживает тип физической секции указанной таблицы SAP HANA и выбирает соответствующую стратегию секционирования: - Секционирование по диапазону: получите столбцы секции и диапазоны секции, определенные для таблицы, а затем скопируйте данные по диапазону. - Хэш-секционирование: используйте ключ хэш-секции в качестве столбца секции, а затем разделите и скопируйте данные на основе вычисленных службой диапазонов. - Секционирование с циклическим перебором или Без секции: используйте первичный ключ в качестве столбца секции, а затем разбейте и скопируйте данные на основе вычисленных службой диапазонов. |
| Для загрузки больших объемов данных используйте пользовательский запрос. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Столбец секции: укажите столбец для секции динамического диапазона. В процессе выполнения служба сначала вычисляет диапазоны значений указанного столбца секции, равномерно распределяя строки в ряде контейнеров в соответствии с количеством различных значений столбцов секций и параметром параллельного копирования, а затем заменяет ?AdfHanaDynamicRangePartitionCondition на фильтрацию диапазона значений столбцов секций для каждой секции и отправляет его в SAP HANA.Если необходимо использовать несколько столбцов в качестве столбца секции, можно объединить значения каждого столбца в один столбец в запросе и указать его в качестве столбца секции, например SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Пример: запрос с физическими секциями таблицы
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Сопоставление типов данных для SAP HANA
При копировании данных из SAP HANA используются следующие сопоставления типов данных SAP HANA с промежуточными типами данных, используемых службой для внутренних целей. Дополнительные сведения о том, как действие копирования сопоставляет исходную схему и типы данных для приемника, см. в статье Сопоставление схем в действии копирования.
| Тип данных SAP HANA | Промежуточный тип данных службы |
|---|---|
| ALPHANUM | Строка |
| BIGINT | Int64 |
| BINARY | Byte[] |
| BINTEXT | Строка |
| BLOB-объект | Byte[] |
| BOOL | Байт |
| CLOB | Строка |
| DATE | Дата/время |
| DECIMAL | Decimal |
| DOUBLE | Двойной |
| FLOAT | Двойной |
| INTEGER | Int32 |
| NCLOB | Строка |
| NVARCHAR | Строка |
| real | Одна |
| SECONDDATE | Дата/время |
| SHORTTEXT | Строка |
| SMALLDECIMAL | Десятичное число |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| ТЕКСТ | Строка |
| TIME | TimeSpan |
| TINYINT | Байт |
| VARCHAR | Строка |
| TIMESTAMP | Дата/время |
| VARBINARY | Byte[] |
Приемник SAP HANA
В настоящее время соединитель SAP HANA не поддерживается в качестве приемника, в то время как для записи данных в SAP HANA можно использовать универсальный соединитель ODBC с драйвером SAP HANA.
Выполните Предварительные требования для настройки локальной среды выполнения интеграции и сначала установите драйвер ODBC для SAP HANA. Создайте связанную службу ODBC для подключения к хранилищу данных SAP HANA, как показано в следующем примере, а затем создайте набор данных и приемник действия копирования с соответствующим типом ODBC. Дополнительные сведения см. в статье Соединитель ODBC.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Связанный контент
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.