Копирование данных из Spark с помощью Фабрики данных Azure или Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в конвейере Фабрики данных Azure и Synapse Analytics копировать данные из Spark. Это продолжение статьи об обзоре действия копирования, в которой представлены общие сведения о действии копирования.
Поддерживаемые возможности
Соединитель Spark поддерживается для перечисленных ниже возможностей.
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | (1) (2) |
| Действие поиска | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
Служба предоставляет встроенный драйвер для обеспечения подключения, поэтому вам не нужно вручную устанавливать какой-либо драйвер с помощью этого соединителя.
Необходимые компоненты
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы для Spark с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Spark с использованием пользовательского интерфейса портала Azure.
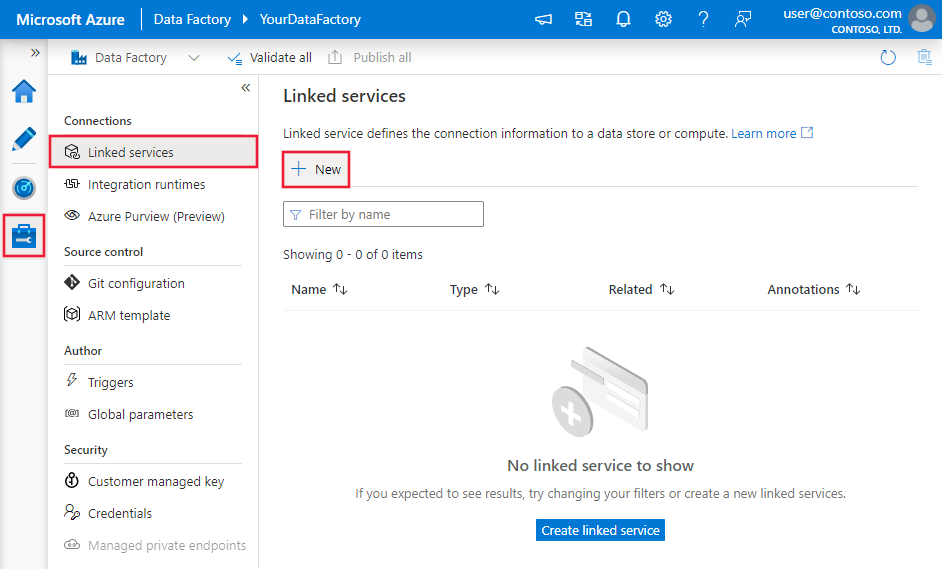
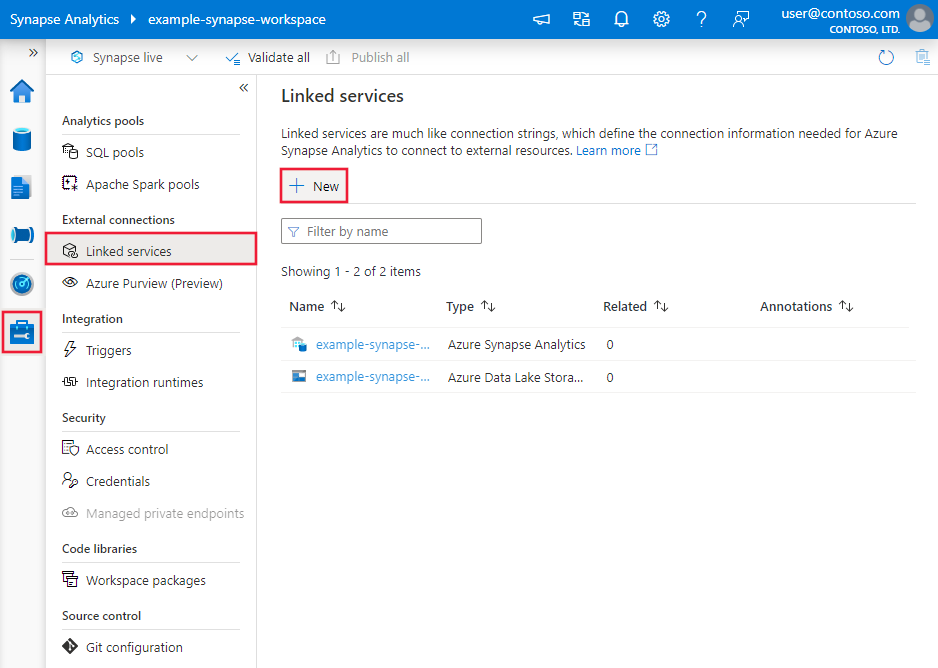
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Spark и выберите соединитель Spark.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах JSON, которые используются для определения сущностей фабрики данных, относящихся к соединителю Spark.
Свойства связанной службы
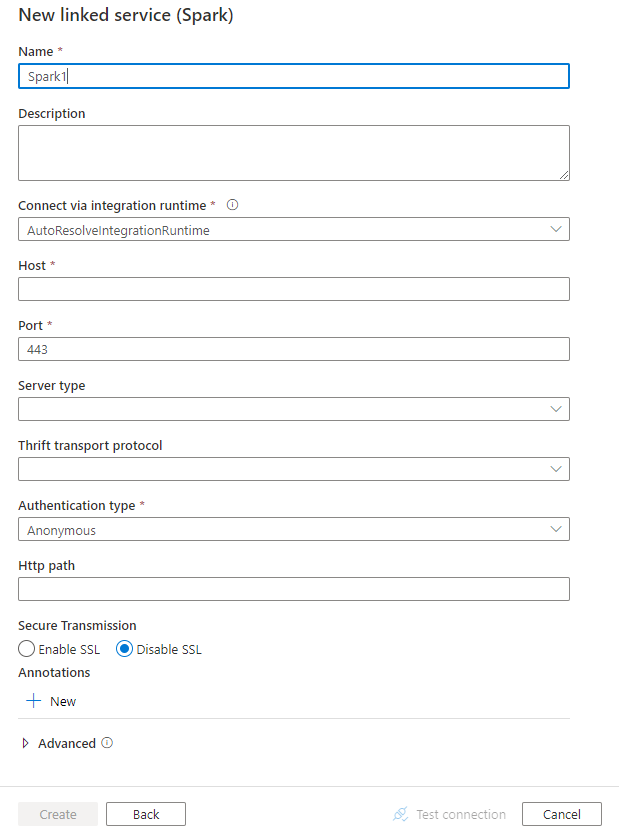
Для связанной службы Spark поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение Spark | Да |
| host | IP-адрес или имя узла сервера Spark | Да |
| port | TCP-порт, используемый сервером Spark для прослушивания клиентских подключений. При подключении к Azure HDInsights укажите порт 443. | Да |
| serverType | Тип сервера Spark. Допустимые значения: SharkServer, SharkServer2, SparkThriftServer. |
No |
| thriftTransportProtocol | Транспортный протокол для использования в слое Thrift. Допустимые значения: Binary, SASL, HTTP |
No |
| authenticationType | Метод аутентификации, используемый для доступа к серверу Spark. Допустимые значения: Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService. |
Да |
| username | Имя пользователя, которое позволяет получить доступ к серверу Spark. | No |
| password | Пароль, соответствующий пользователю. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | No |
| httpPath | Частичный URL-адрес, соответствующий серверу Spark. | No |
| enableSsl | Указывает, шифруются ли подключения к серверу с помощью протокола TLS. По умолчанию используется значение false. | No |
| trustedCertPath | Полный путь к PEM-файлу, который содержит сертификаты доверенного ЦС для проверки сервера при подключении по протоколу TLS. Это свойство можно установить только при использовании TLS в локальных средах выполнения интеграции. Значением по умолчанию является файл cacerts.pem, который устанавливается вместе с IR. | No |
| useSystemTrustStore | Указывает, следует ли использовать сертификат ЦС из доверенного хранилища системы или из указанного PEM-файла. По умолчанию используется значение false. | No |
| allowHostNameCNMismatch | Указывает, следует ли требовать, чтобы имя TLS/SSL-сертификата, выданного ЦС, совпадало с именем узла сервера при подключении по протоколу TLS. По умолчанию используется значение false. | No |
| allowSelfSignedServerCert | Указывает, следует ли разрешить использование самозаверяющих сертификатов с сервера. По умолчанию используется значение false. | No |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | No |
Пример:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Spark.
Чтобы скопировать данные с Spark, установите свойство type набора данных SparkObject. Поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение SparkObject | Да |
| schema | Имя схемы. | Нет (если свойство query указано в источнике действия) |
| table | Имя таблицы. | Нет (если свойство query указано в источнике действия) |
| tableName | Имя таблицы со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новых рабочих нагрузок используйте schema и table. |
Нет (если свойство query указано в источнике действия) |
Пример
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе содержится список свойств, поддерживаемых источником Spark.
Spark в качестве источника
Чтобы скопировать данные из Spark, установите тип источника SparkSource в действии копирования. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение SparkSource. | Да |
| query | Используйте пользовательский SQL-запрос для чтения данных. Например: "SELECT * FROM MyTable". |
Нет (если для набора данных задано свойство tableName) |
Пример:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Связанный контент
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.