Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование "Условное разбиение" направляет строки данных в различные потоки на основе условий соответствия. Преобразование "Условное разбиение" аналогично применению структуры решения CASE в языке программирования. Преобразование вычисляет выражения, и на основе результатов направляет строку данных в указанный поток.
Настройка
Параметр Разбить по определяет, передается ли строка данных в первый соответствующий поток или в каждый поток, которому она соответствует.
С помощью построителя выражений потока данных введите выражение для условия разбиения. Чтобы добавить новое условие, щелкните значок "плюс" в существующей строке. Для строк, которые не соответствуют никаким условиям, можно также добавить поток по умолчанию.
Скрипт потока данных
Синтаксис
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Пример
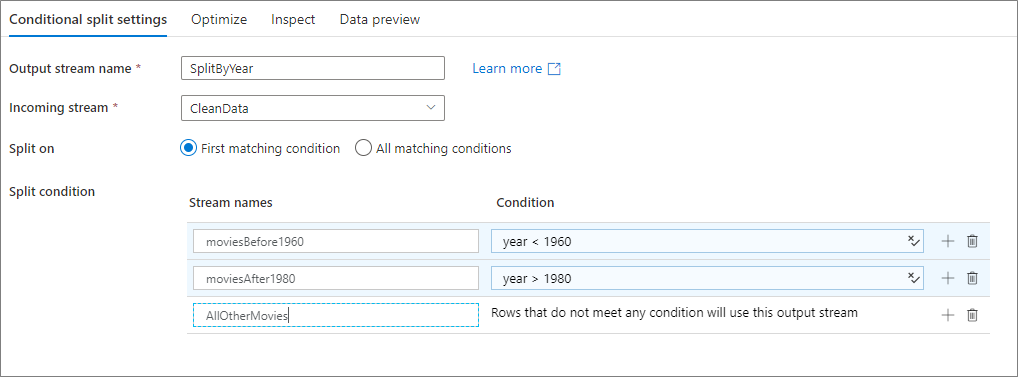
Ниже приведен пример преобразования "Условное разбиение" с именем SplitByYear, которое принимает входной поток CleanData. Это преобразование имеет два условия разделения — year < 1960 и year > 1980. disjoint имеет значение false, так как для данных применяется первое соответствующее условие, а не все соответствия сразу. Каждая строка, соответствующая первому условию, переходит в выходной поток moviesBefore1960. Все оставшиеся строки, соответствующие второму условию, переходят в выходной поток moviesAFter1980. Все остальные строки проходят через поток по умолчанию AllOtherMovies.
В пользовательском интерфейсе службы это преобразование выглядит следующим образом:
Скрипт потока данных для этого преобразования представлен в следующем фрагменте кода:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Связанный контент
В число распространенных преобразований потока данных, используемых с условным разбиением, входят преобразование "Соединение", преобразование "Уточняющий запрос" и преобразование "Выбор".