Преобразования "Уточняющий запрос" в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование "Уточняющий запрос" используется для ссылки на данные из другого источника в потоке данных. Преобразование "Уточняющий запрос" добавляет столбцы из сопоставленных данных в исходные данные.
Преобразование "Уточняющий запрос" похоже на левое внешнее соединение. Все строки из основного потока будут существовать в выходном потоке с дополнительными столбцами из потока уточняющего запроса.
Настройка
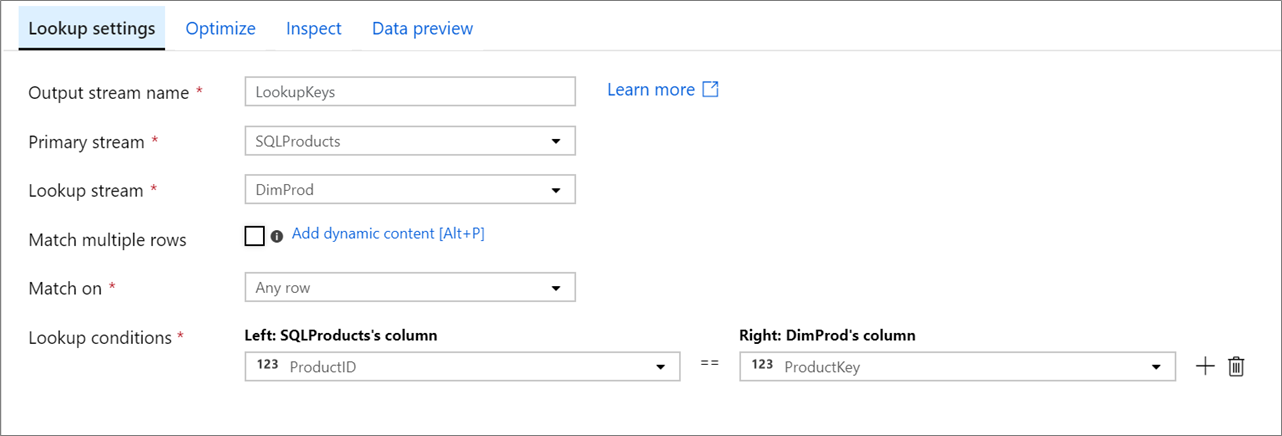
Основной поток: входящий поток данных. Этот поток эквивалентен левой стороне соединения.
Поток подстановки: данные, добавляемые к основному потоку. Добавляемые данные определяются условиями уточняющего запроса. Этот поток эквивалентен правой стороне соединения.
Сопоставление нескольких строк: если включено, строка с несколькими совпадениями в основном потоке вернет несколько строк. В противном случае будет возвращена только одна строка, основанная на условии "Сопоставлять на".
Сопоставлять на: отображается, только если не выбрано "Сопоставлять несколько строк". Выберите, следует ли выполнять поиск по любой строке, по первому совпадению или по последнему совпадению. Рекомендуется поиск по любой строке, так как он выполняется быстрее всего. Если выбрана первая строка или последняя строка, потребуется указать условия сортировки.
Условия подстановки: выберите столбцы для сопоставления. Если условие равенства выполнено, строки будут считаться совпадениями. Наведите указатель мыши на пункт "Вычисляемый столбец", чтобы извлечь значение с помощью языка выражений потока данных.
В выходные данные включаются все столбцы из обоих потоков. Чтобы удалить дублирующиеся или ненужные столбцы, добавьте преобразование "Выбор" после преобразования "Уточняющий запрос". Столбцы также могут быть удалены или переименованы в преобразовании приемника.
Неэквивалентные соединения
Чтобы использовать условный оператор, например "не равно" (!=) или "больше" (>) в условиях уточняющего запроса, измените раскрывающийся список операторов между двумя столбцами. Для неэквивалентных соединений требуется широковещательная рассылка по крайней мере одного из двух потоков с помощью Фиксированного вещания на вкладке Оптимизация.
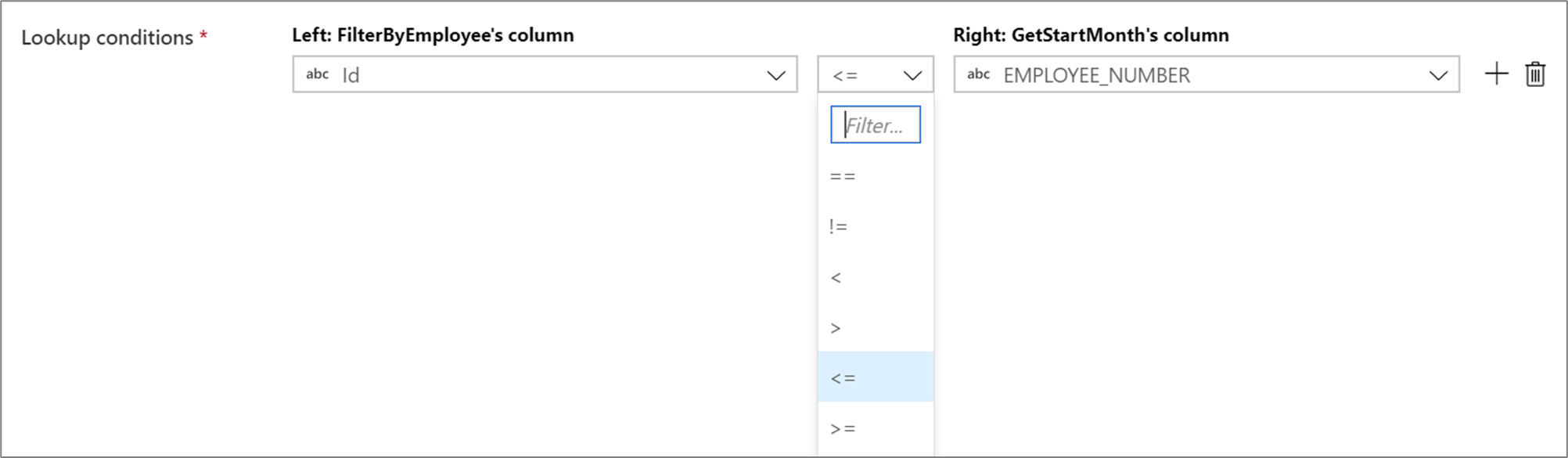
Анализ сопоставленных строк
После преобразования "Уточняющий запрос" функция isMatch() может использоваться для проверки соответствия уточняющего запроса отдельным строкам.
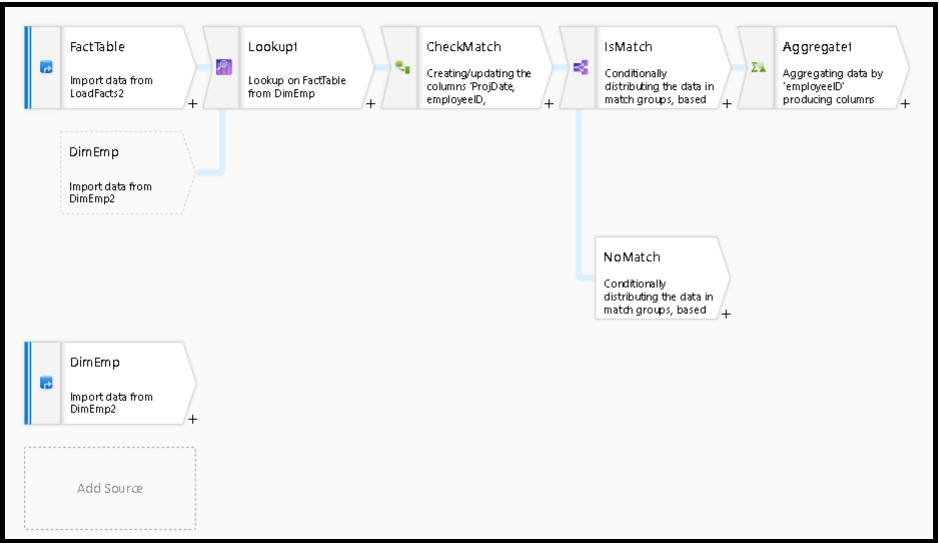
Примером такого шаблона является использование преобразования "Условное разбиение" для разбиения по функции isMatch(). В приведенном выше примере совпадающие строки проходят через верхний поток, а несовпадающие строки — через поток NoMatch.
Проверка условий уточняющего запроса
При тестировании преобразования "Уточняющий запрос" с предварительным просмотром данных в режиме отладки используйте небольшой набор известных данных. При выборке строк из большого набора данных нельзя предсказать, какие строки и ключи будут считываться для тестирования. Результат является недетерминированным, то есть условия соединения могут и не возвратить совпадений.
Оптимизация вещания
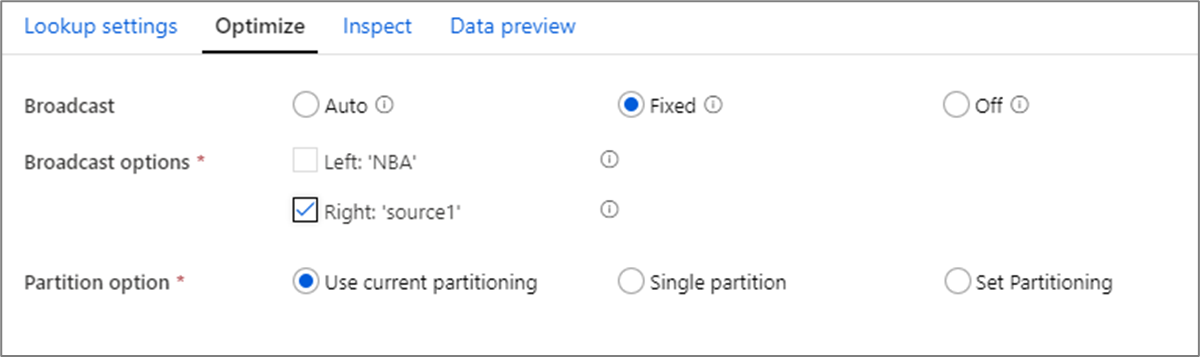
При преобразованиях "Соединения", "Уточняющие запросы" и "Существование", если один или оба потока данных помещаются в память рабочего узла, можно оптимизировать производительность, включив Трансляцию. По умолчанию механизм Spark автоматически решает, следует ли транслировать одну сторону. Чтобы вручную выбрать сторону для трансляции, выберите Фиксированные.
Не рекомендуется отключать широковещательную трансляцию с помощью параметра Выкл., пока соединения не столкнутся с ошибками времени ожидания.
Кэшированный поиск
Если вы выполняете несколько небольших уточняющих запросов в одном источнике, возможно, лучше использовать приемник кэша и кэшированный поиск, чем преобразование "Уточняющий запрос". Распространенные примеры, в которых лучше использовать приемник кэша, — поиск максимального значения в хранилище данных и сопоставление кодов ошибок с базой данных сообщений об ошибках. Дополнительные сведения см. в статье о приемниках кэша и кэшированном поиске.
Скрипт потока данных
Синтаксис
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Пример
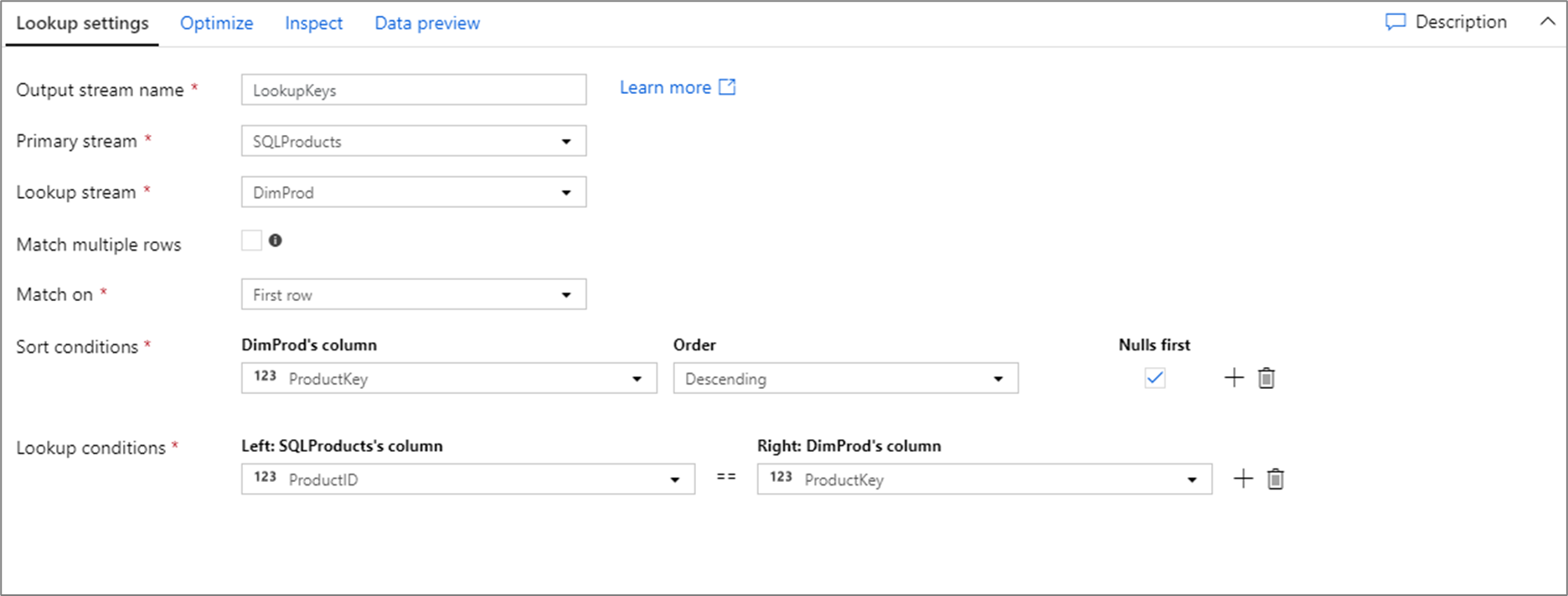
Сценарий потока данных для приведенной выше конфигурации уточняющего запроса находится в следующем фрагменте кода.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Связанный контент
- Преобразования Соединение и Существует принимают несколько входных потоков.
- Используйте преобразование "Условное разбиение" с
isMatch(), чтобы разбить строки на совпадающие и несовпадающие значения.