Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве вы создадите фабрику данных с помощью портала Azure. Затем вы используете средство копирования данных для создания конвейера, который добавочно копирует новые файлы на основе имен файлов с разделением по времени из одного хранилища BLOB-объектов Azure в другое.
Примечание.
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
Вот какие шаги выполняются в этом учебнике:
- Создали фабрику данных.
- Создание конвейера с помощью средства копирования данных.
- Мониторинг конвейера и выполнения действий.
Необходимые компоненты
- Подписка Azure. Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Учетная запись хранения Azure. В этом руководстве в качестве исходного и принимающего хранилища данных используйте хранилище BLOB-объектов. Если у вас нет учетной записи хранения Azure, см. инструкции по ее созданию.
Создание двух контейнеров в Хранилище BLOB-объектов
Подготовьте хранилище BLOB-объектов для выполнения инструкций из этого учебника, выполнив следующие действия.
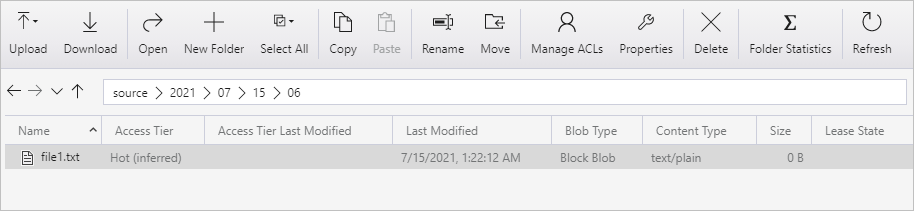
Создайте контейнер с именем source. Создайте путь к папке в контейнере в формате 2021/07/15/06. Создайте пустой текстовый файл и назовите его file1.txt. Загрузите файл file1.txt, указав путь к папке source/2021/07/15/06 в вашей учетной записи хранения. Это можно сделать при помощи таких средств, как обозреватель службы хранилища Azure.
Примечание.
Выполните корректировку имени папки в соответствии со своим временем в формате UTC. Например, если текущее время в формате UTC — 06:10 15 июля 2021 г., можно создать путь к папке в формате source/2021/07/15/06/ согласно правилу source/{Year}/{Month}/{Day}/{Hour}/.
Создайте контейнер с именем destination. Это можно сделать при помощи таких средств, как обозреватель службы хранилища Azure.
Создание фабрики данных
В верхнем меню выберите Создать ресурс>Аналитика>Фабрика данных :
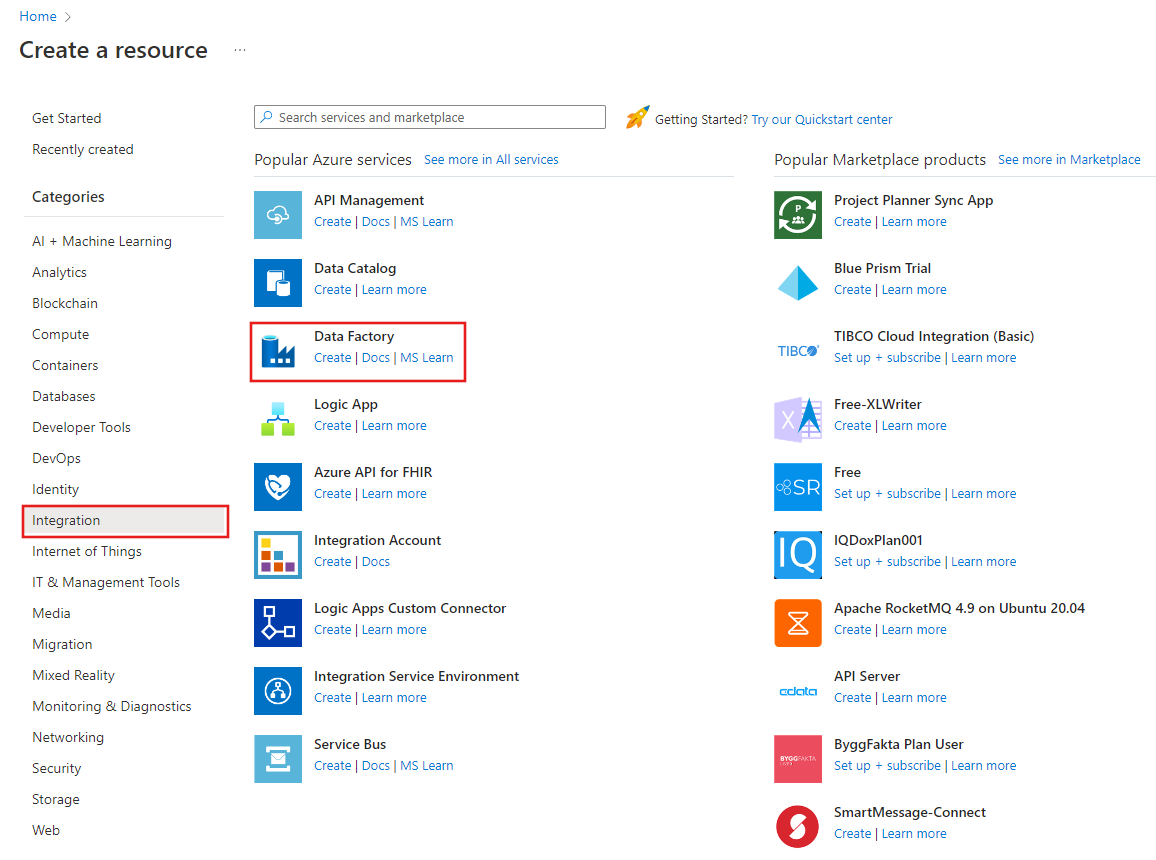
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Имя фабрики данных должно быть глобально уникальным. Вы можете получить следующее сообщение об ошибке.
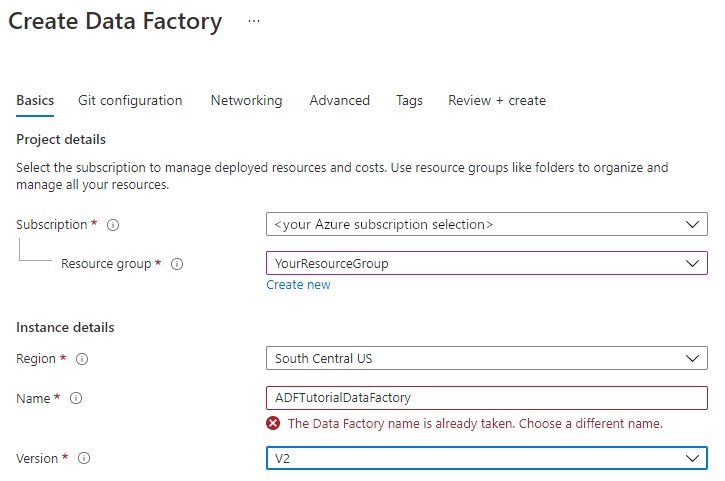
Если вы увидите следующую ошибку касательно значения имени, введите другое имя фабрики данных. Например,ваше_имяADFTutorialDataFactory. Правила именования артефактов службы "Фабрика данных" см. в этой статье.
Выберите подписку Azure, в которой нужно создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
a. Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
б. Выберите Создать новуюи укажите имя группы ресурсов.
Сведения о группах ресурсов см. в статье Общие сведения об Azure Resource Manager.
В качестве версии выберите V2.
В качестве расположения выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, служба хранилища Azure и база данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах или расположениях.
Нажмите кнопку создания.
Когда создание завершится, откроется домашняя страница Фабрика данных.
Чтобы запустить пользовательский интерфейс Фабрики данных Azure на отдельной вкладке, нажмите кнопку Открыть на элементе Open Azure Data Factory Studio (Открыть студию Фабрики данных Azure).

Создание конвейера с помощью средства копирования данных
На домашней странице Фабрики данных Azure выберите Принять, чтобы запустить инструмент копирования данных.
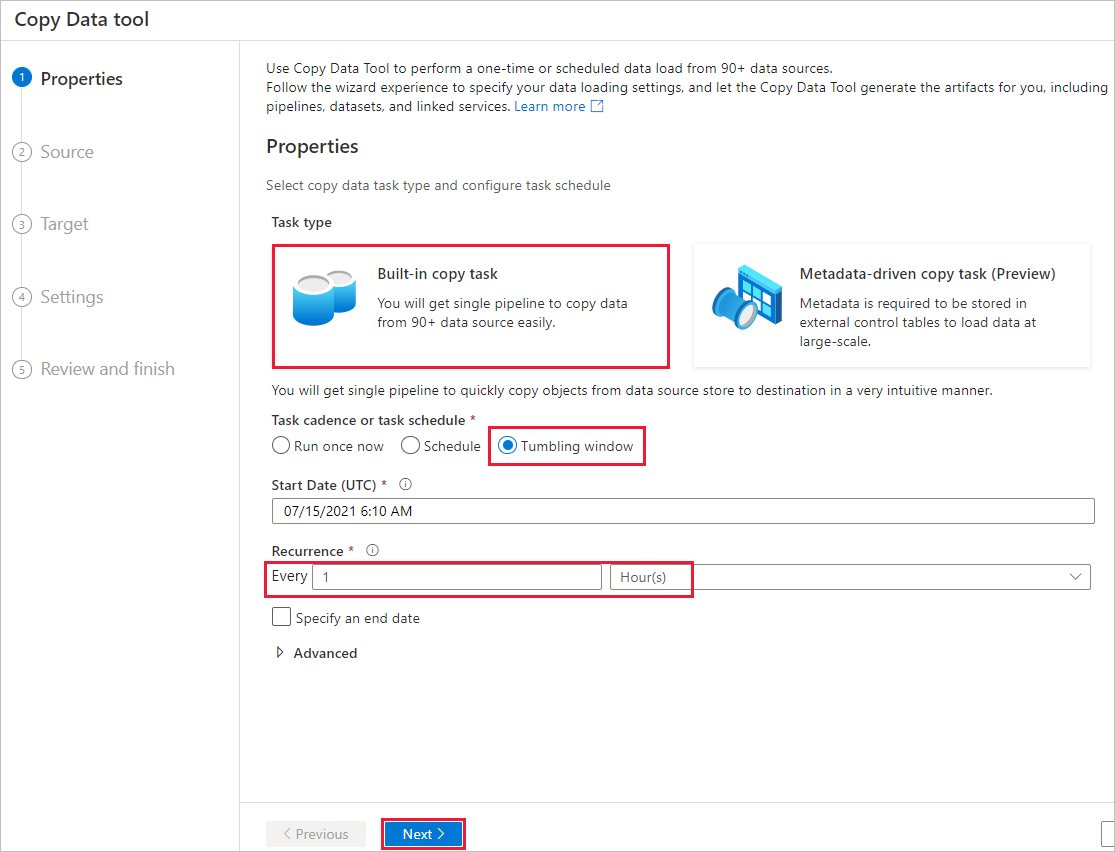
На странице Свойства выполните следующие действия:
В разделе Тип задачи выберите Встроенная задача копирования.
В разделе Периодичность или расписание задач выберите "Переворачивающееся" окно.
В разделе Повторения введите 1 час.
Выберите Далее.
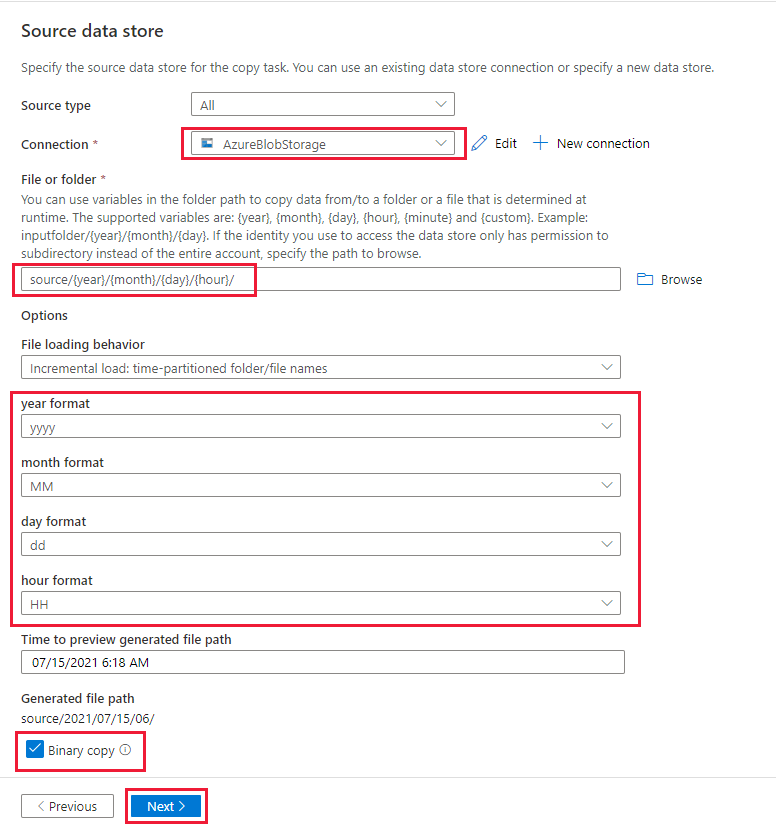
На странице Исходное хранилище данных сделайте следующее:
a. Выберите + Создать подключение, чтобы добавить подключение.
б. В коллекции выберите Хранилище BLOB-объектов Azure и щелкните Продолжить.
с. На странице Новое подключение (Хранилище BLOB-объектов Azure) укажите имя подключения. Выберите подписку Azure и учетную запись хранения из списка Имя учетной записи хранения. Проверьте подключение и выберите Создать.
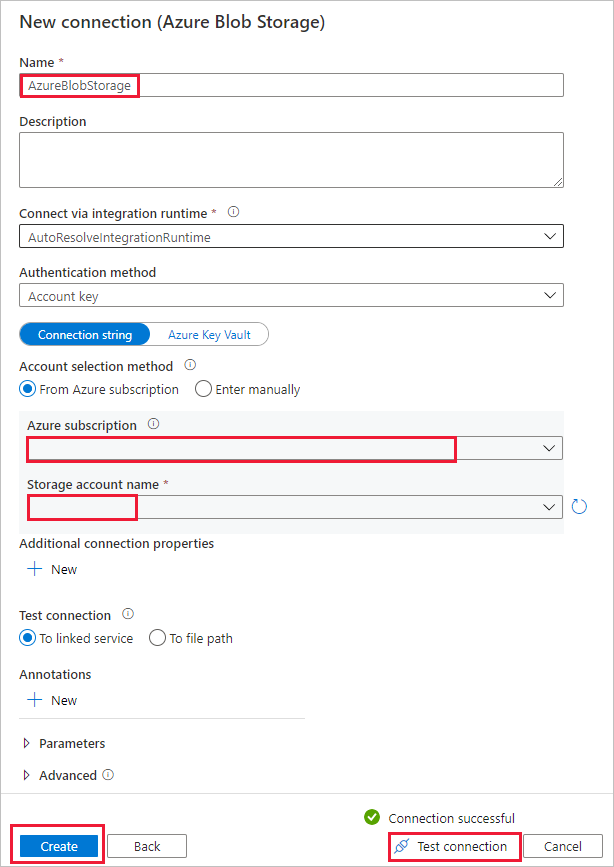
д. На странице Исходное хранилище данных выберите только что созданное подключение в блоке Подключение.
д) В разделе Файл или папка нажмите "Обзор" и выберите исходный контейнер, а затем нажмите ОК.
е) В разделе File loading behavior (Поведение загрузки файлов) выберите Incremental load: time-partitioned folder/file names (Добавочная загрузка: имена папок или файлов, секционированных по времени).
ж. Запишите динамический путь к папке в формате source/{year}/{month}/{day}/{hour}/ и измените формат, как показано на следующем снимке экрана.
х. Установите флажок Двоичное копирование и выберите Далее.
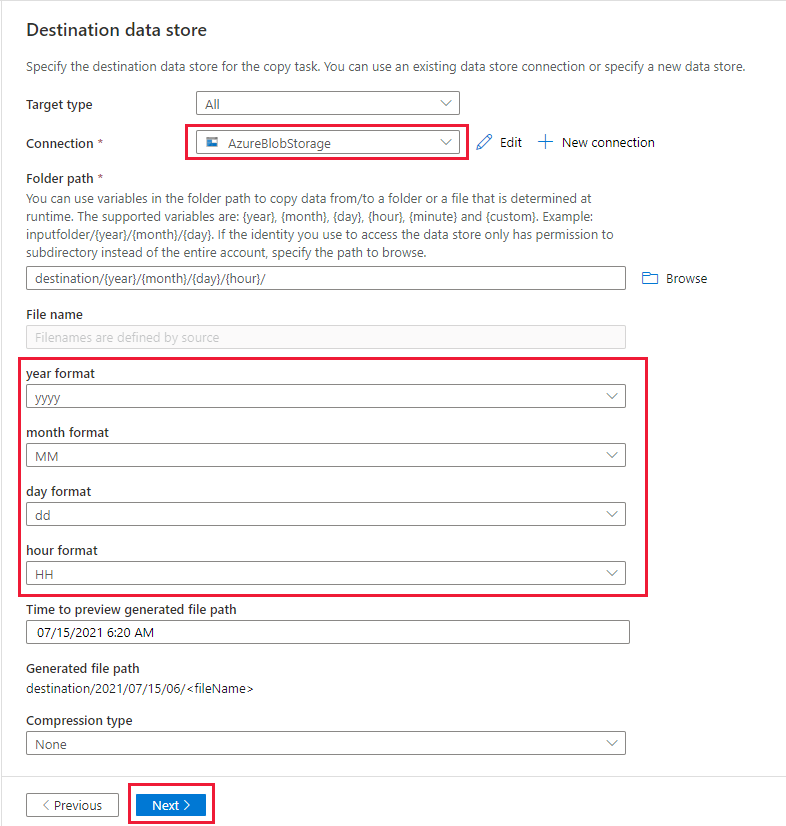
На странице Целевое хранилище данных выполните указанные ниже действия.
Выберите AzureBlobStorage (ту же учетную запись хранения, которая используется для исходного хранилища).
Найдите и выберите папку назначения, а затем щелкните ОК.
Запишите динамический путь к папке в формате destination/{year}/{month}/{day}/{hour}/ и измените формат, как показано на следующем снимке экрана.
Выберите Далее.
На странице Параметры в разделе Имя задачи введите имя CopyFromBlobToSqlPipeline, а затем нажмите кнопку Далее. Пользовательский интерфейс фабрики данных создаст конвейер с указанным именем задачи.
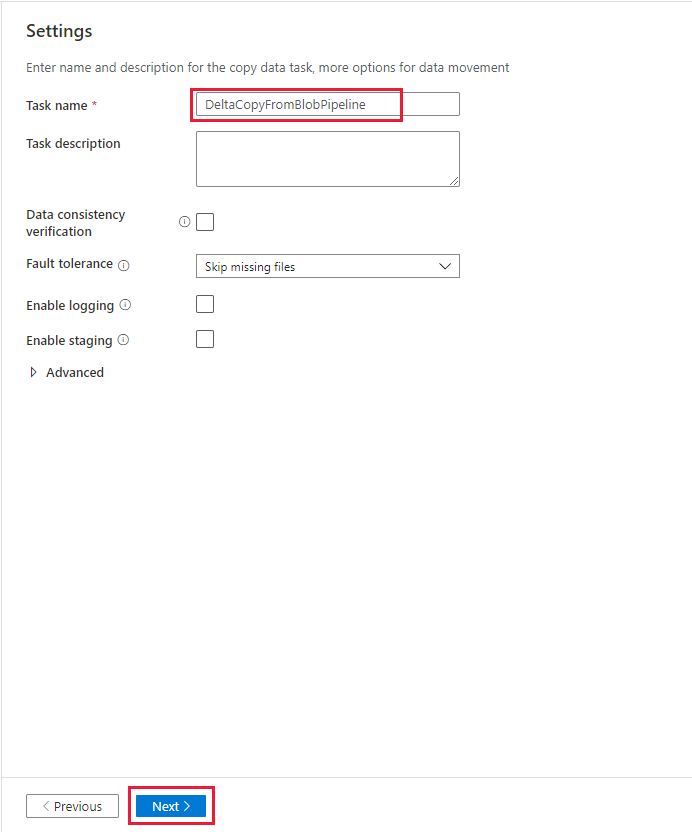
Просмотрите параметры на странице Сводка, а затем нажмите кнопку Далее.
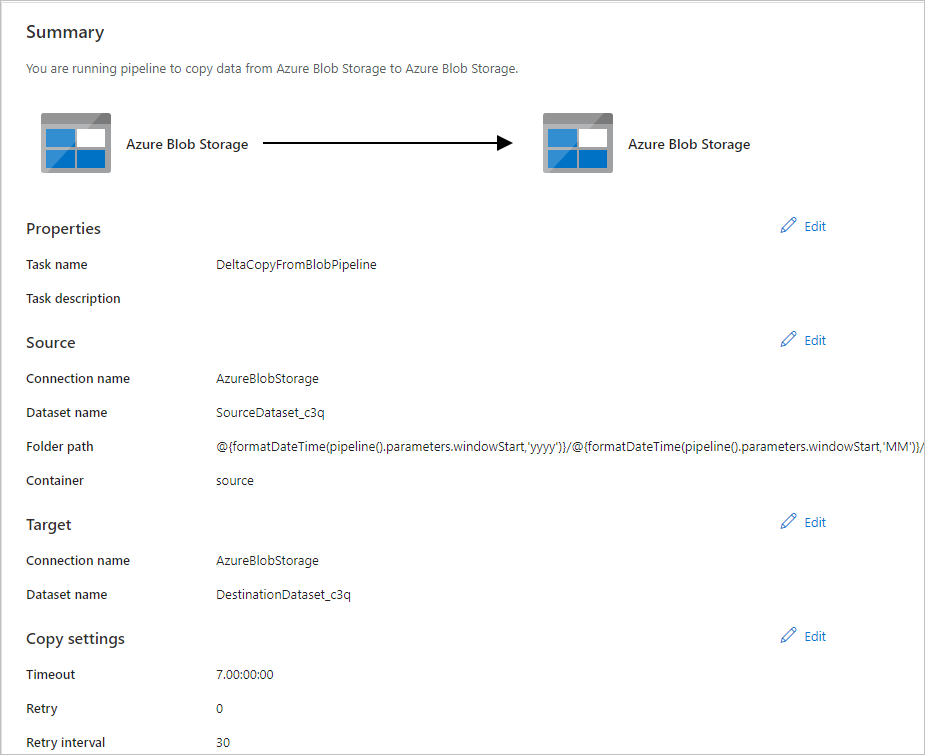
На странице Развертывание выберите Мониторинг, чтобы отслеживать созданный конвейер (задачу).
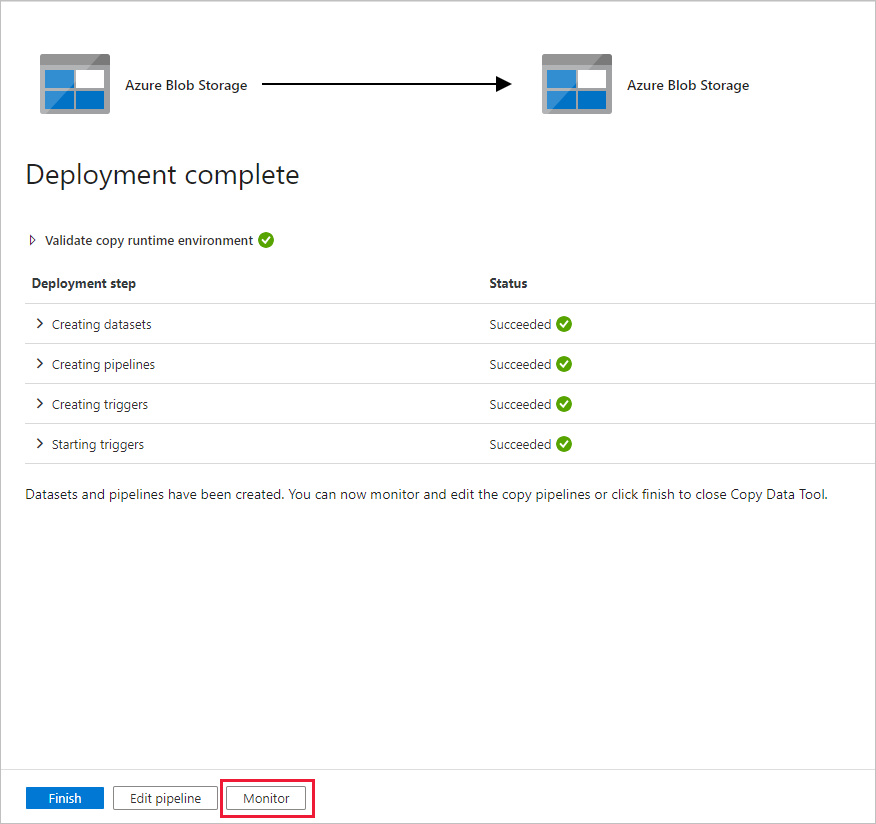
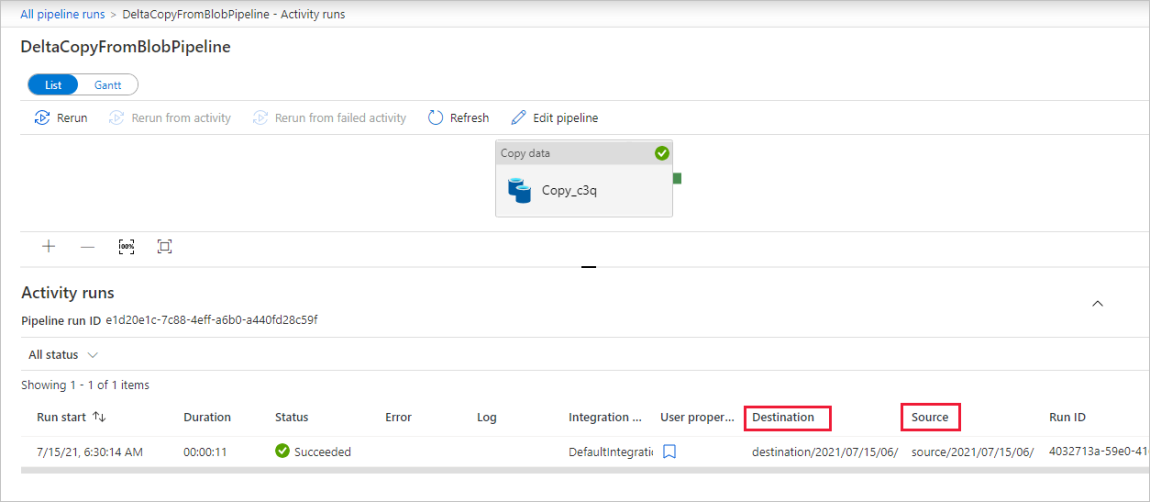
Обратите внимание, что слева автоматически выбирается вкладка Мониторинг. Вам нужно дождаться выполнения конвейера (запускается автоматически примерно через час). Во время его выполнения выберите ссылку с именем конвейера DeltaCopyFromBlobPipeline для просмотра сведений о выполнении действия или перезапустите конвейер. Щелкните Обновить, чтобы обновить список.
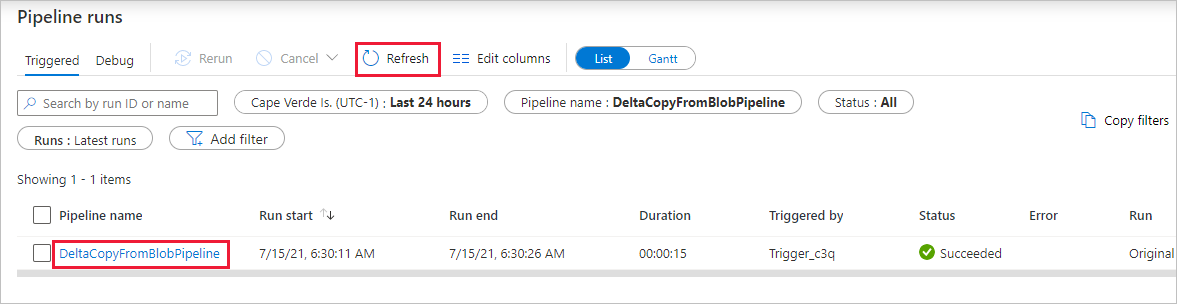
В этом конвейере определено только одно действие (действие копирования), поэтому вы увидите только одну запись. Скорректируйте ширину столбцов Источник и Назначение (при необходимости) для отображения более подробной информации. Вы можете увидеть, что исходный файл (file1.txt) был скопирован из источника source/2021/07/15/06/ в место назначения destination/2021/07/15/06/ с тем же именем.
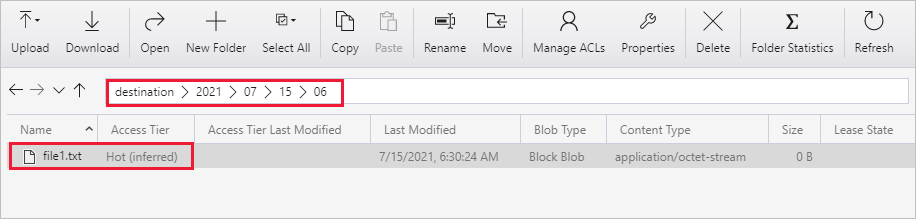
Вы можете выполнить аналогичную проверку с помощью Обозревателя службы хранилища Azure (https://storageexplorer.com/) для сканирования файлов.
Создайте другой пустой текстовый файл с новым именем в формате file2.txt. Загрузите файл file2.txt, указав путь к папке source/2021/07/15/07 в вашей учетной записи хранения. Это можно сделать при помощи таких средств, как обозреватель службы хранилища Azure.
Примечание.
Как вы, вероятно, знаете, необходимо создать путь к папке. Выполните корректировку имени папки в соответствии со своим временем в формате UTC. Например, если текущее время в формате UTC — 07:30 15 июля 2021 г., можно создать путь к папке в формате source/2021/07/15/07/ согласно правилу {Year}/{Month}/{Day}/{Hour}/.
Чтобы вернуться к представлению Выполнения конвейеров, выберите Все выполнения конвейера и подождите, пока тот же конвейер повторно запустится автоматически через один час.
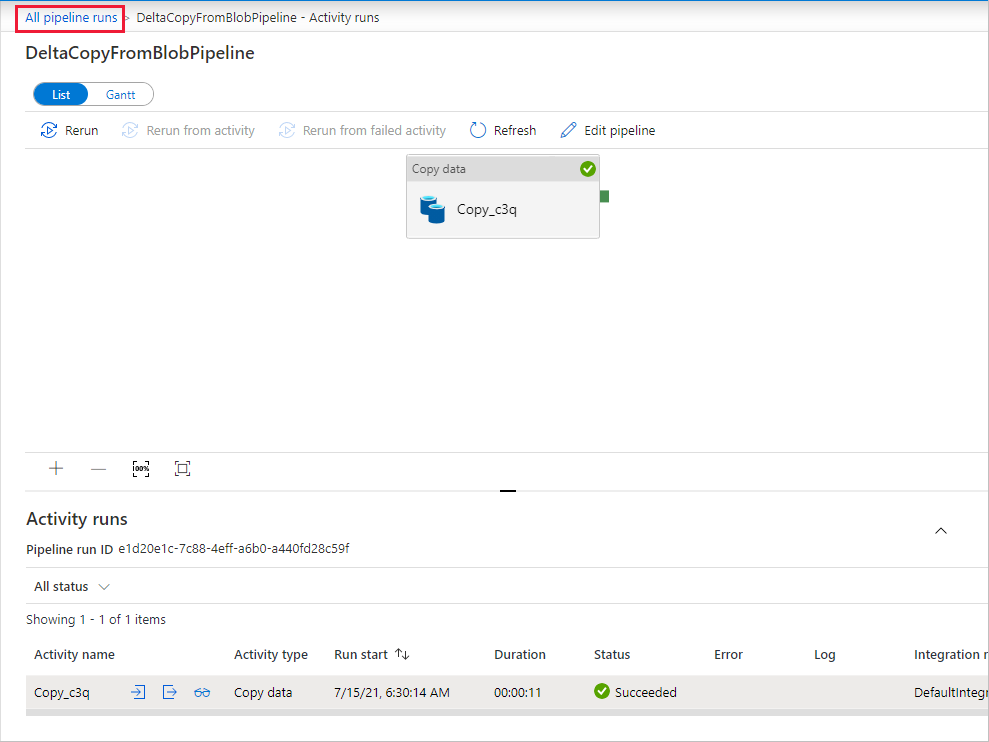
Щелкните новую ссылку DeltaCopyFromBlobPipeline для выполнения другого конвейера, когда она появится, и выполняйте аналогичные действия для просмотра сведений. Вы увидите, что исходный файл (file2.txt) был скопирован из источника source/2021/07/15/07/ в расположение destination/2021/07/15/07/ с тем же именем. Вы можете выполнить аналогичную проверку с помощью Обозревателя службы хранилища Azure (https://storageexplorer.com/) для сканирования файлов в контейнере destination.
Связанный контент
Перейдите к следующему руководству, чтобы узнать о преобразовании данных с помощью кластера Spark в Azure:
Transform data in the cloud by using Spark activity in Azure Data Factory (Преобразование данных в облаке с помощью действий Spark в фабрике данных Azure)