Преобразование данных в облаке с помощью действия Spark в фабрике данных Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве вы создадите конвейер фабрики данных Azure с помощью портала Azure. Конвейер преобразует данные с помощью действия Spark и связанной службы Azure HDInsight по запросу.
В этом руководстве вы выполните следующие шаги:
- Создали фабрику данных.
- Создание конвейера, использующего действие Spark.
- Активация выполнения конвейера.
- Осуществили мониторинг выполнения конвейера.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предварительные требования
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Сведения о начале работы см. в статье "Установка Azure PowerShell". Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
- Учетная запись хранения Azure. Нужно создать входной файл и сценарий Python и передать их в службу хранилища Azure. Выходные данные программы Spark хранятся в этой учетной записи хранения. Кластер Spark по запросу использует ту же учетную запись хранения, что и его основное хранилище.
Примечание.
HDInsight поддерживает только учетные записи хранения общего назначения с ценовой категорией "Стандартный". Убедитесь, что используете не учетную запись ценовой категории "Премиум" и не учетную запись только для большого двоичного объекта.
- Azure PowerShell. Следуйте инструкциям по установке и настройке Azure PowerShell.
Отправка скрипта Python в учетную запись хранилища BLOB-объектов
Создайте файл Python с именем WordCount_Spark.py со следующим содержимым:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Замените свойство <storageAccountName> именем своей учетной записи хранения Azure. Затем сохраните файл.
В хранилище BLOB-объектов Azure создайте контейнер с именем adftutorial, если он не существует.
Создайте папку с именем spark.
Создайте вложенную папку с именем script в папке spark.
Отправьте файл WordCount_Spark.py во вложенную папку script.
Отправка входного файла
- Создайте файл с определенным текстом и назовите его minecraftstory.txt. Программа Spark подсчитывает количество слов в этом тексте.
- Создайте вложенную папку с именем inputfiles в папке spark.
- Отправьте файл minecraftstory.txt во вложенную папку inputfiles.
Создание фабрики данных
Выполните действия, описанные в кратком руководстве по созданию фабрики данных с помощью портал Azure для создания фабрики данных, если у вас еще нет этой фабрики данных.
Создание связанных служб
Создайте две связанные службы в этом разделе:
- Связанную службу хранилища Azure, которая связывает учетную запись хранения Azure с фабрикой данных. Это хранилище используется кластером HDInsight по запросу. В нем также содержится скрипт Spark для выполнения.
- Связанную службу HDInsight по запросу. Фабрика данных Azure автоматически создает кластер HDInsight и запускает программу Spark. Кластер Hadoop удаляется, если он не используется в течение заданного времени.
Создание связанной службы хранилища Azure
На домашней странице перейдите на вкладку Управление на панели слева.
В нижней части окна выберите Подключения, а затем + Создать.
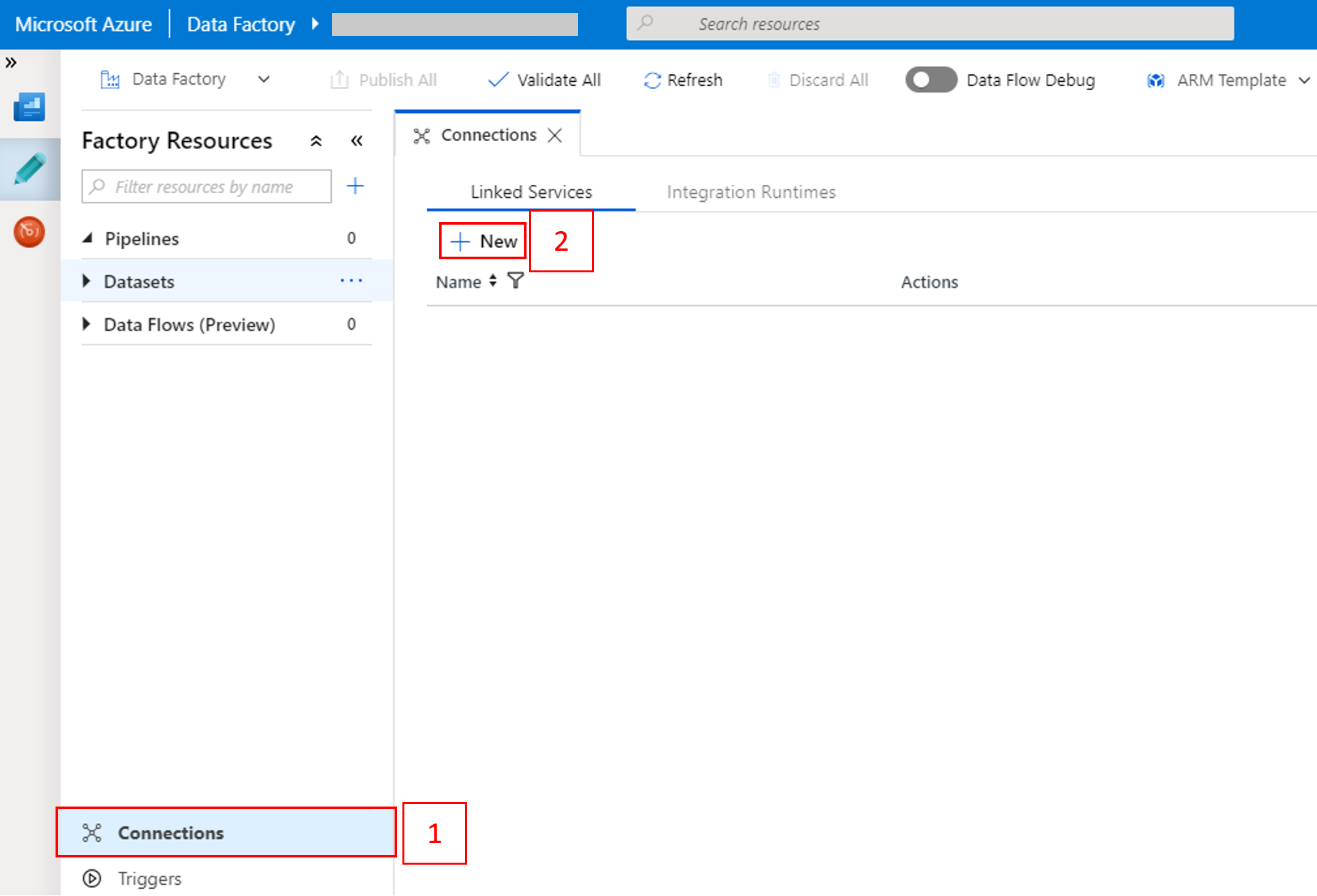
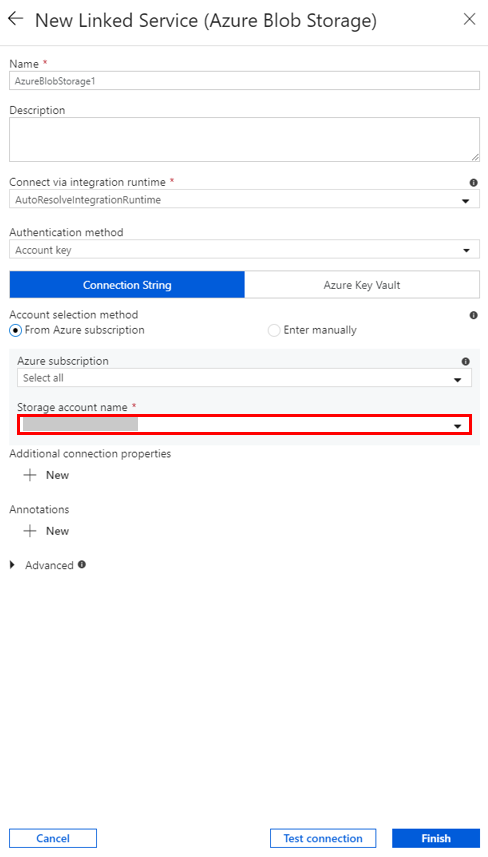
В окне New Linked Service (Новая связанная служба) выберите Хранилище данных>Хранилище BLOB-объектов Azure и щелкните Продолжить.

Выберите имя из списка в поле Имя учетной записи хранения, а затем щелкните Сохранить.
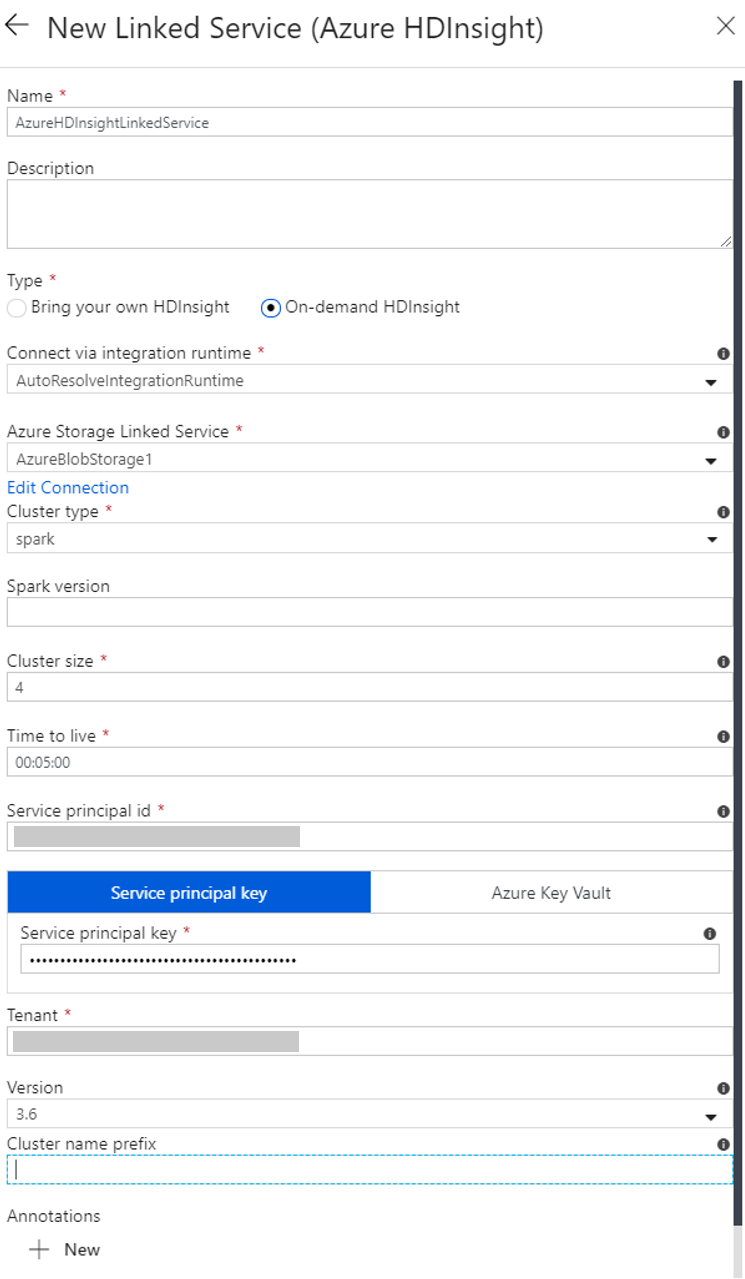
Создание связанной службы HDInsight по запросу
Снова нажмите кнопку + Создать, чтобы создать еще одну связанную службу.
В окне New Linked Service (Новая связанная служба) выберите Среда выполнения приложений>Azure HDInsight, а затем выберите Continue (Продолжить).

В окне New Linked Service (Новая связанная служба) сделайте следующее:
a. В поле Name (Имя) введите AzureHDInsightLinkedService.
b. Убедитесь, что в поле Type (Тип) выбран вариант On-demand HDInsight (HDInsight по запросу).
c. Для параметра Azure Storage Linked Service (Связанная служба хранилища Azure) выберите AzureStorage1. Эта та связанная служба, которую вы создали ранее. Если было использовано другое имя, укажите его в этом поле.
d. В качестве типа кластера выберите spark.
д) В поле Идентификатор субъекта-службы введите идентификатор субъекта-службы, имеющего права на создание кластера HDInsight.
Этому субъекту-службе должна быть назначена роль участника подписки или группы ресурсов, в которой создается кластер. Дополнительные сведения см. в статье "Создание приложения Microsoft Entra" и субъекта-службы. Идентификатор субъекта-службы —это эквивалент идентификатора приложения, а ключ субъекта-службы — значения секрета клиента.
f. Введите ключ в поле Ключ субъекта-службы.
ж. В качестве группы ресурсов выберите ту же группу ресурсов, которая была использована при создании фабрики данных. В этой группе ресурсов будет создан кластер HDInsight.
h. Разверните список Тип ОС.
i. Введите имя пользователя кластера.
j. Введите пароль кластера для этого пользователя.
k. Выберите Готово.
Примечание.
Azure HDInsight ограничивает общее количество ядер, которые можно использовать в каждом поддерживаемом регионе Azure. Для связанной службы HDInsight по требованию создается кластер HDInsight в расположении хранилища Azure, используемом в качестве основного хранилища. Убедитесь, что имеется достаточное количество квот ядра для успешного создания кластера. Дополнительные сведения см. в статье Установка кластеров в HDInsight с использованием Hadoop, Spark, Kafka и других технологий.
Создание конвейера
Нажмите кнопку + (плюс) и в меню выберите Pipeline (Конвейер).
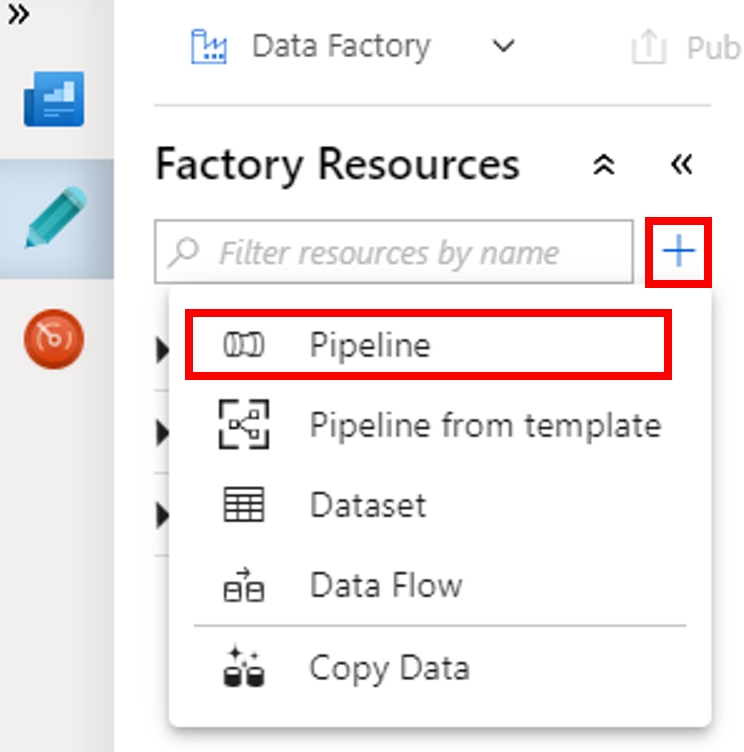
На панели элементов Действия разверните узел HDInsight. Перетащите действие Spark с панели элементов Действия в область конструктора конвейера.
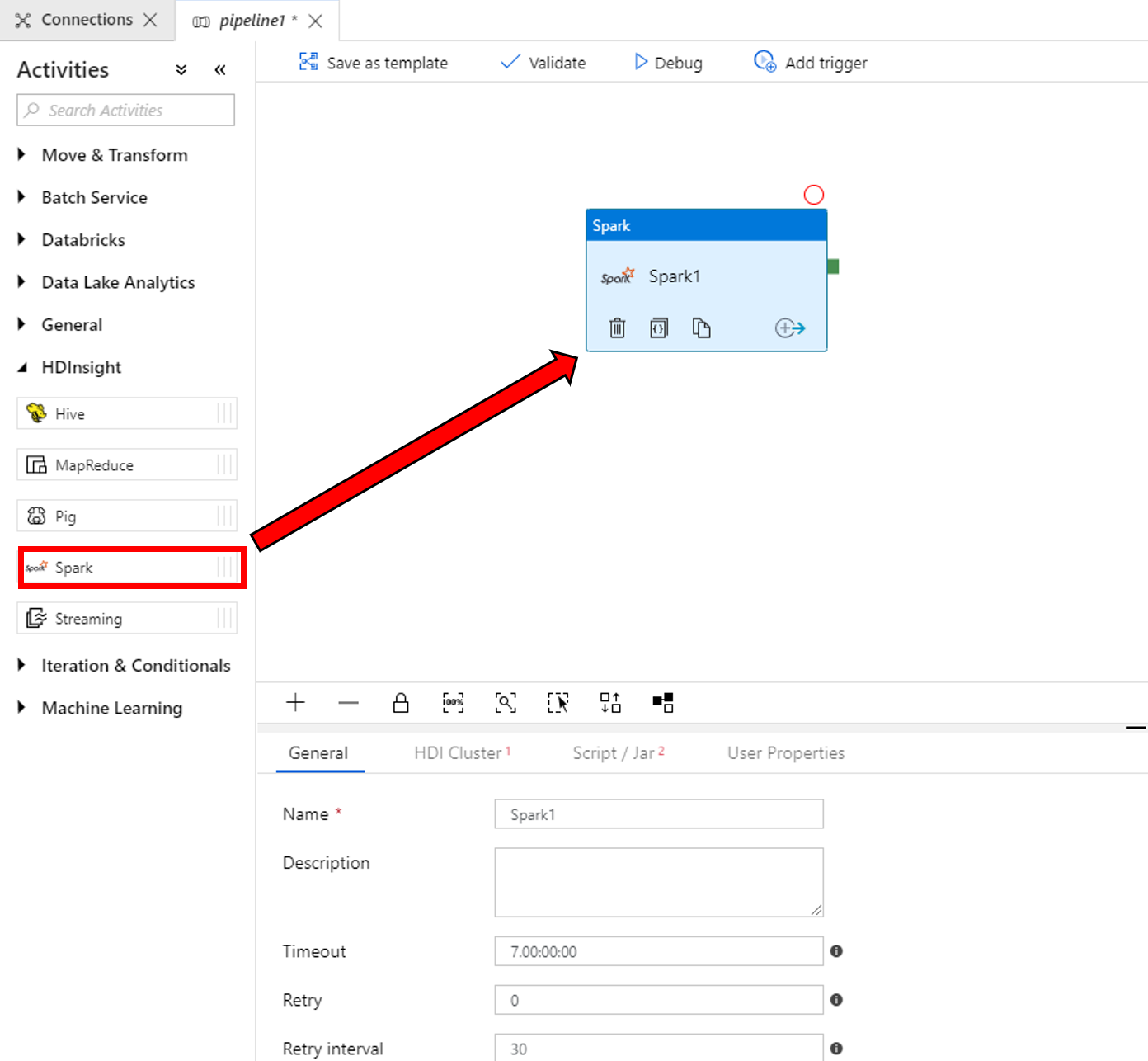
В свойствах для окна действия Spark в нижней части страницы завершите следующие действия:
a. Перейдите на вкладку HDI Cluster (Кластер HDI).
b. Выберите службу AzureHDInsightLinkedService (созданную в приведенной выше процедуре).
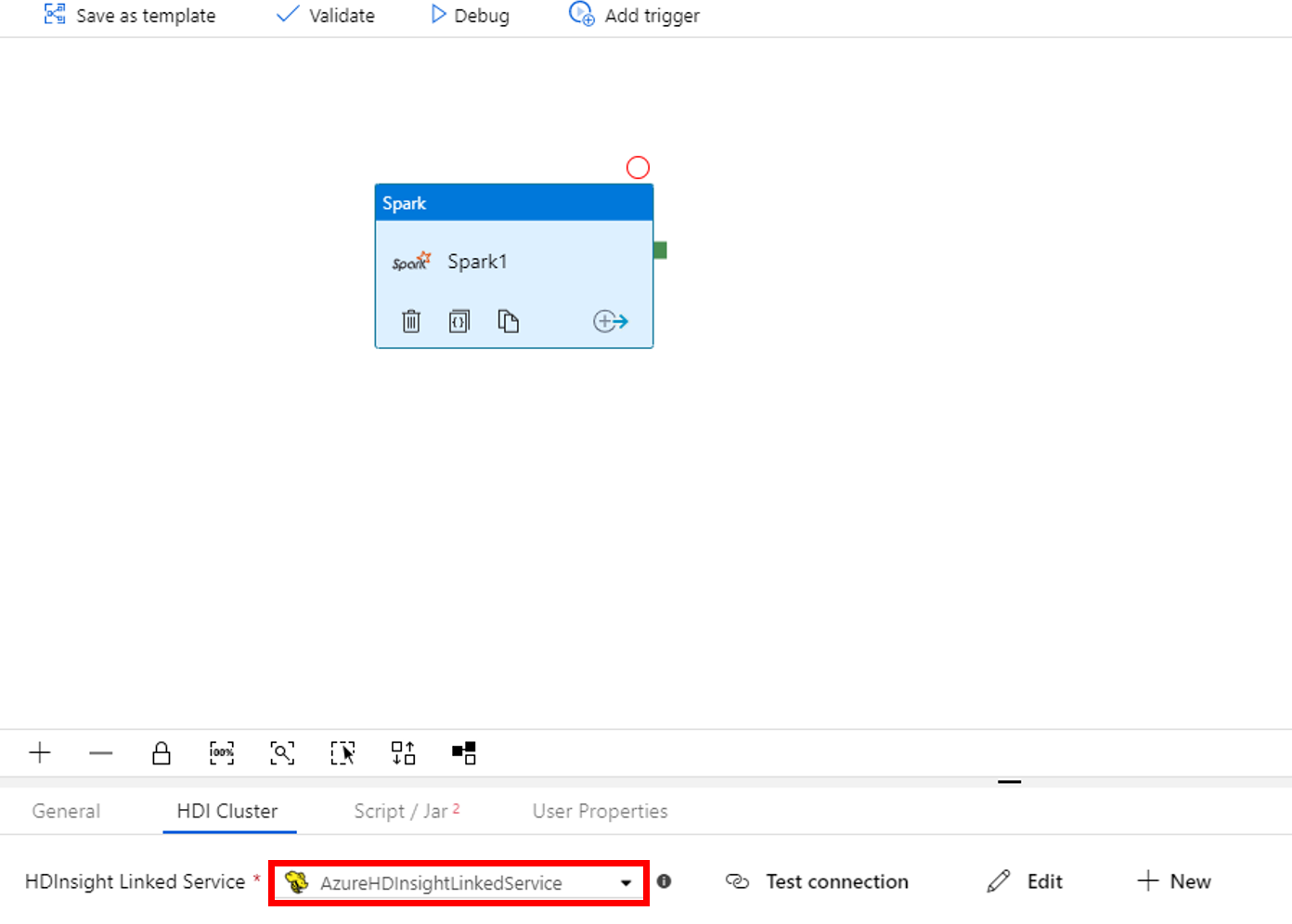
Перейдите на вкладку Script/Jar (Скрипт или JAR-файл) и выполните следующие действия:
a. Для параметра Job Linked Service (Связанная служба задания) выберите значение AzureStorage1.
b. Выберите Поиск в хранилище.

c. Перейдите к папке adftutorial/spark/script, выберите в ней файл WordCount_Spark.py, а затем выберите Готово.
Чтобы проверить работу конвейера, нажмите кнопку Проверка на панели инструментов. Чтобы закрыть окно проверки, нажмите кнопку >>Стрелка вправо.
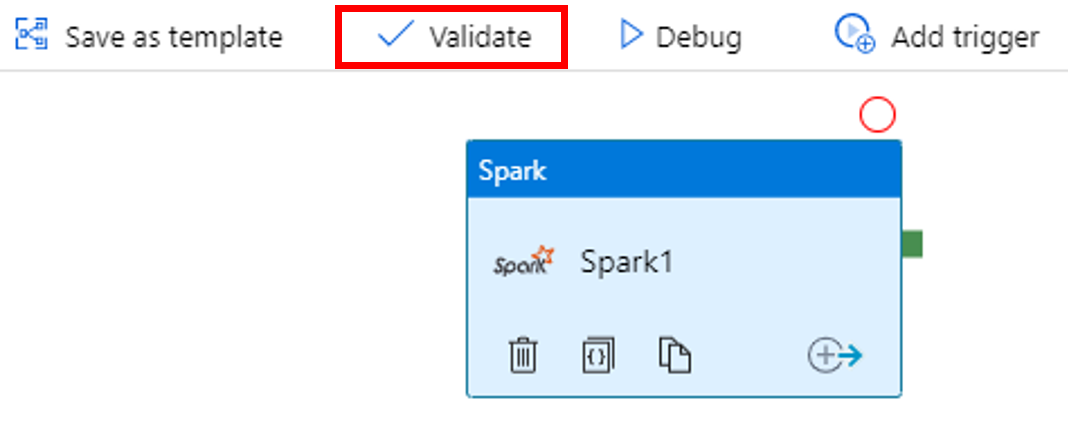
Выберите Опубликовать все. Пользовательский интерфейс фабрики данных опубликует сущности (связанные службы и конвейер) в службе фабрики данных Azure.
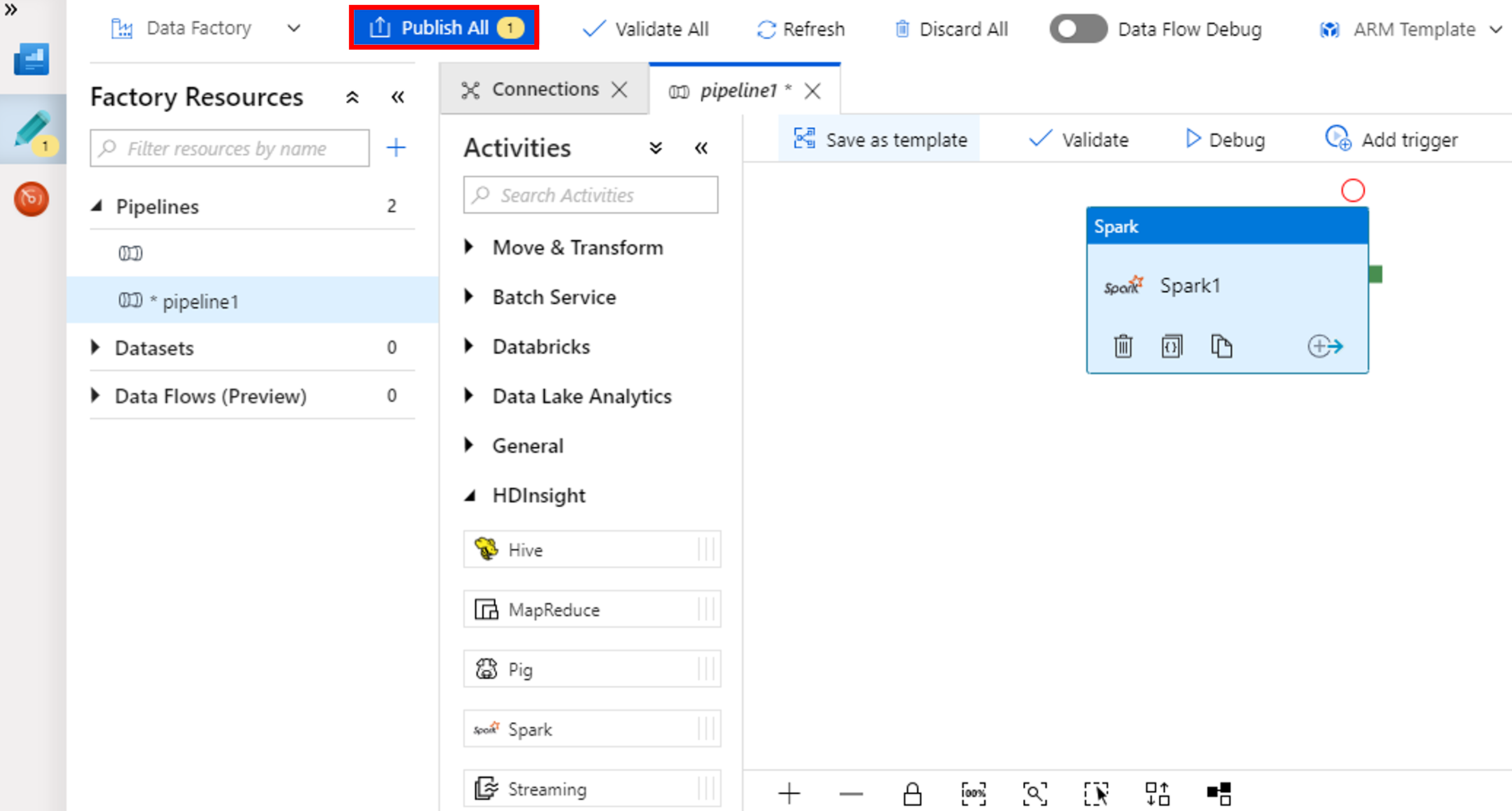
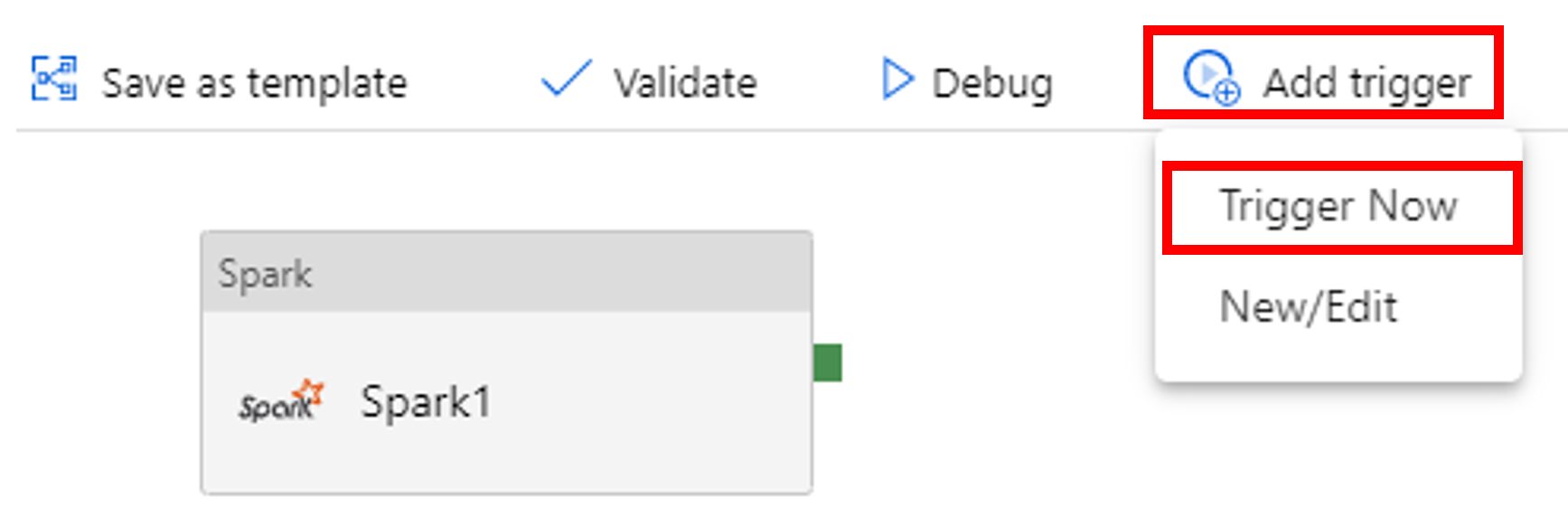
Активация выполнения конвейера
Выберите Добавить триггер на панели инструментов, а затем Trigger Now (Запустить сейчас).
Мониторинг конвейера
Перейдите на вкладку "Монитор ". Убедитесь, что вы видите запуск конвейера. Создание кластера Spark занимает около 20 минут.
Периодически нажимайте Обновить, чтобы контролировать состояние выполнения конвейера.
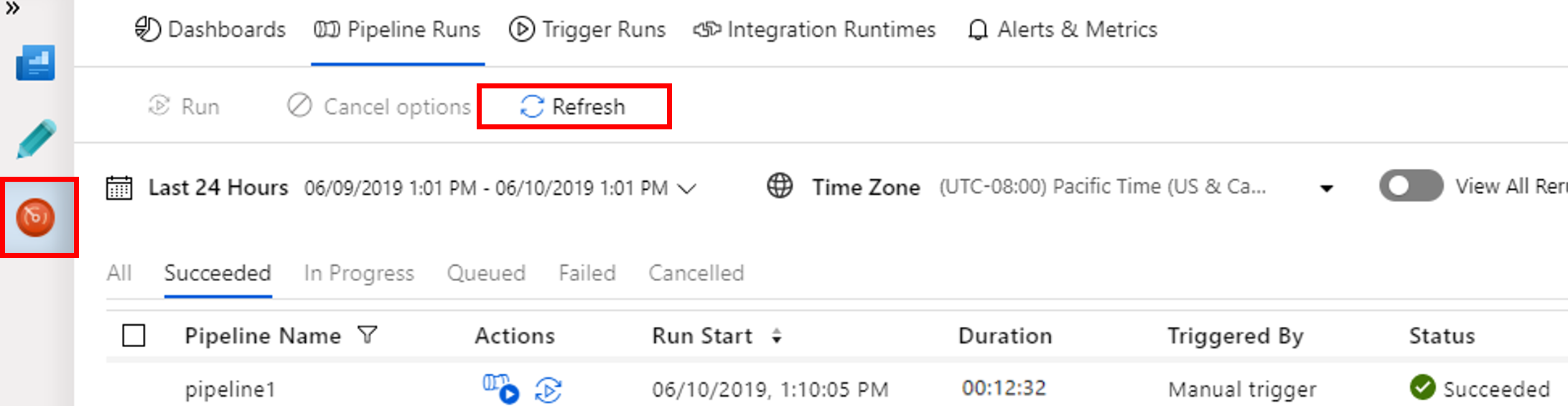
Чтобы увидеть выполнение действий, связанных с выполнением конвейера, выберите View Activity Runs (Просмотр выполнения действий) в столбце Действия.
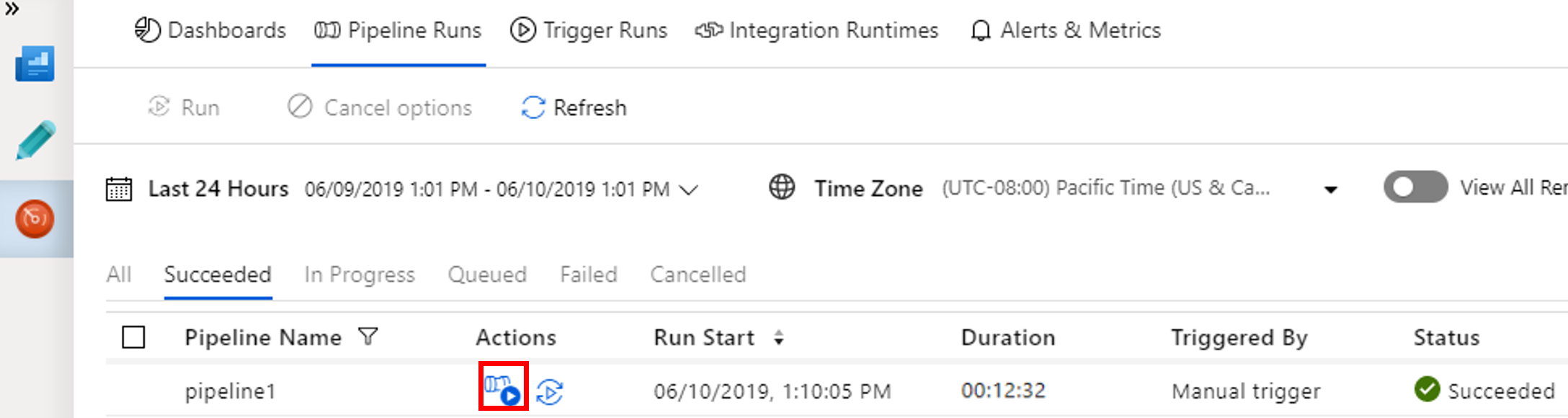
Чтобы вернуться в режим просмотра запусков конвейера, выберите ссылку All Pipeline Runs (Все запуски конвейера).
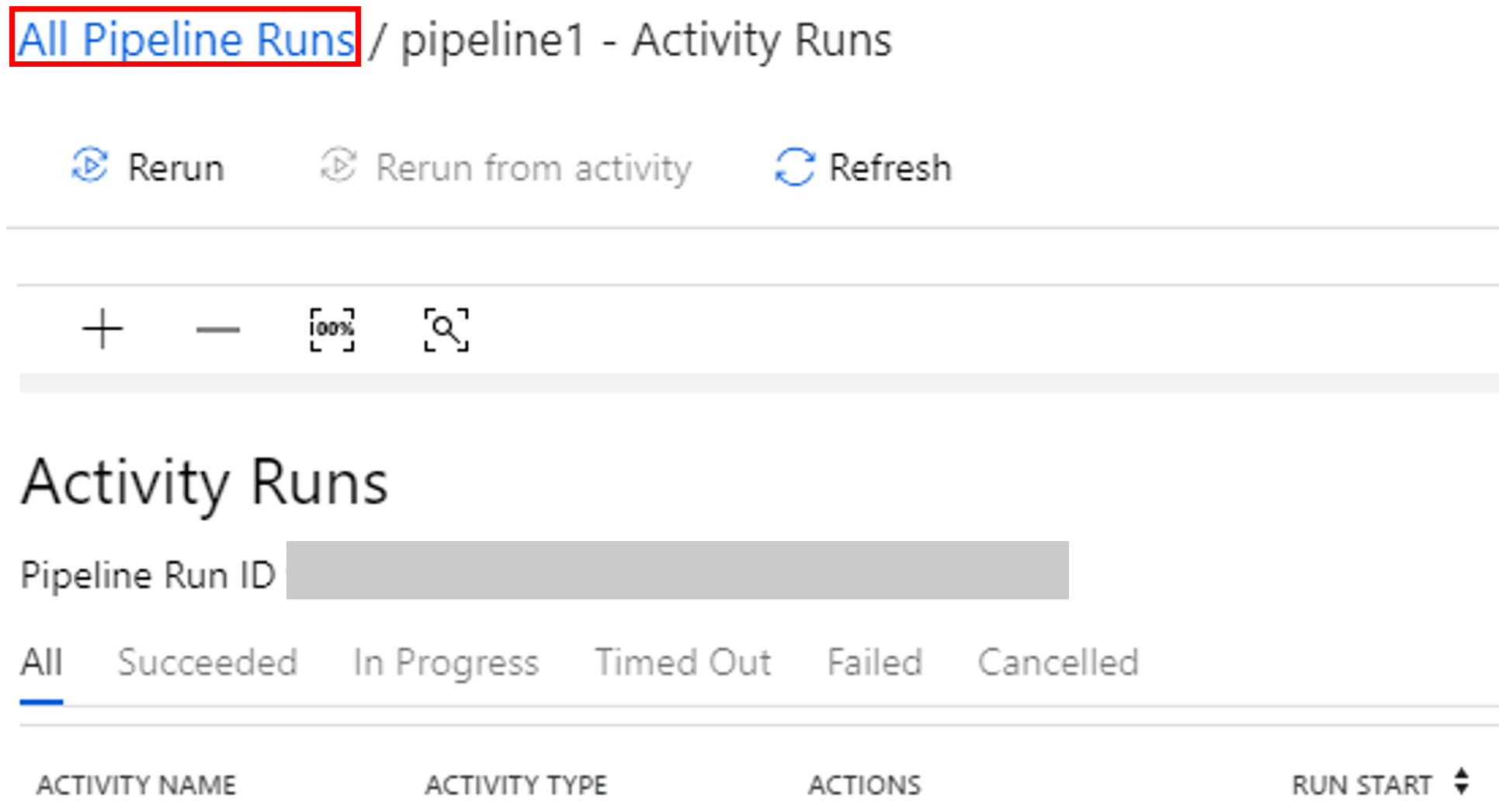
Проверка выходных данных
Убедитесь, что целевой файл создается в папке spark/otuputfiles/wordcount для контейнера adftutorial.
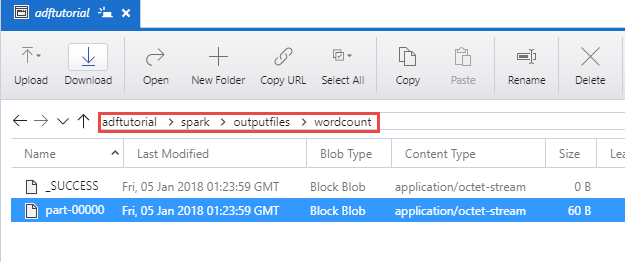
В этом файле должны содержаться все слова из входного текстового файла и число, обозначающее количество таких слов в этом файле. Например:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Связанный контент
Конвейер из этого примера преобразует данные с помощью действия Spark и связанной службы HDInsight по запросу. Вы научились выполнять следующие задачи:
- Создали фабрику данных.
- Создание конвейера, использующего действие Spark.
- Активация выполнения конвейера.
- Осуществили мониторинг выполнения конвейера.
Чтобы узнать, как преобразовать данные, запустив сценарий Hive в кластере Azure HDInsight, который находится в виртуальной сети, ознакомьтесь со следующим руководством:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по