Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
CI/CD (непрерывная интеграция и непрерывная доставка) — это автоматизированный процесс разработки, развертывания, мониторинга и обслуживания приложений. Автоматив сборку, тестирование и развертывание кода, команды разработчиков могут предоставлять выпуски чаще и надежно, чем процессы вручную, которые по-прежнему распространены во многих командах по проектированию и обработке и анализу данных. CI/CD для машинного обучения объединяет методы MLOps, DataOps, ModelOps и DevOps.
В этой статье описывается, как Databricks поддерживает CI/CD для решений машинного обучения. В приложениях машинного обучения CI/CD важно не только для артефактов кода, но также применяется к конвейерам данных, включая как входные данные, так и результаты, генерируемые моделью.
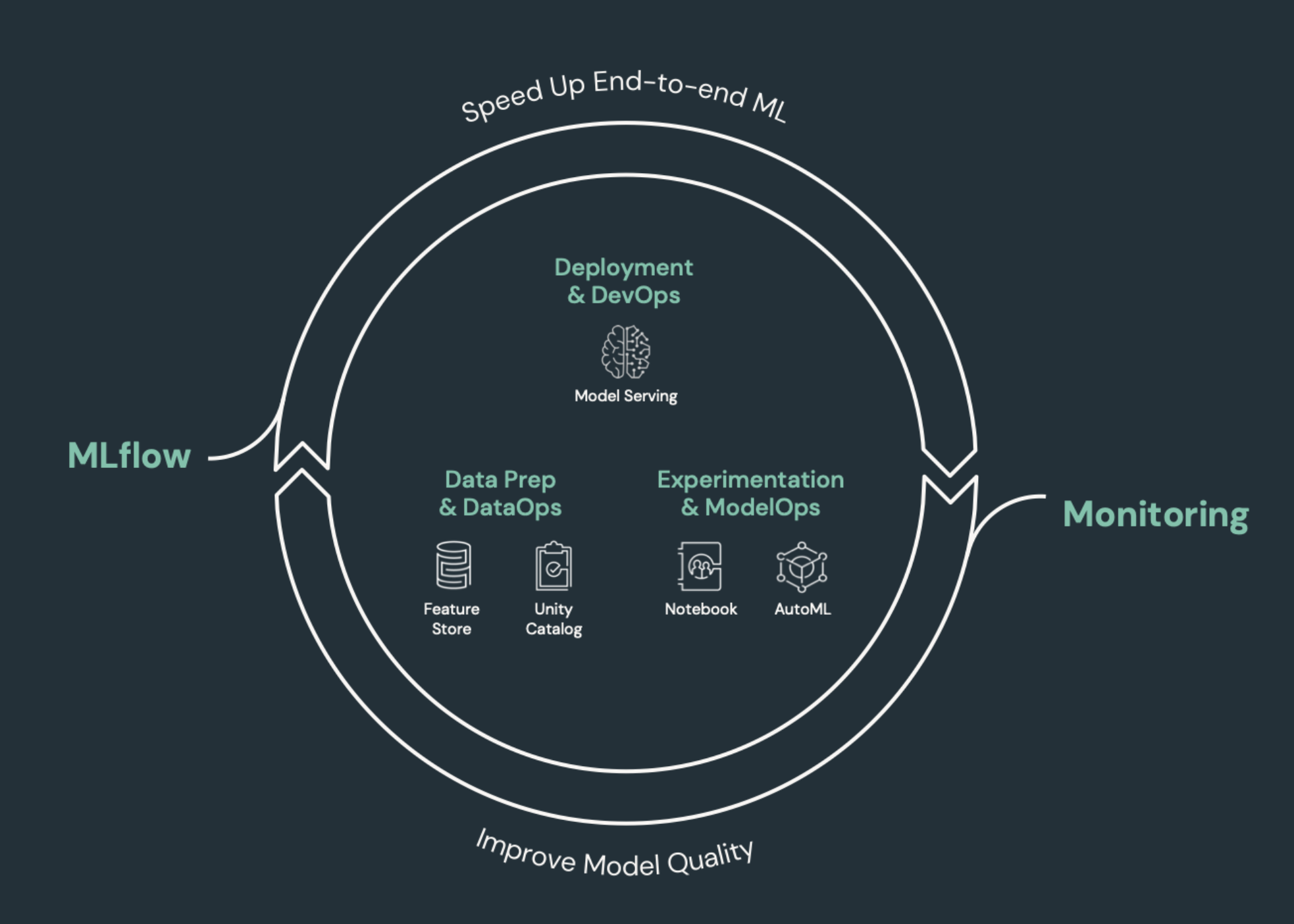
Элементы машинного обучения, требующие CI/CD
Одной из задач разработки машинного обучения является то, что разные команды имеют разные части процесса. Команды могут полагаться на различные инструменты и иметь разные графики выпусков. Azure Databricks предоставляет единую единую платформу данных и машинного обучения с интегрированными средствами для повышения эффективности команд и обеспечения согласованности и повторяемости конвейеров данных и машинного обучения.
Как правило, для задач машинного обучения необходимо отслеживать следующие действия в автоматизированном рабочем процессе CI/CD:
- Обучающие данные, включая качество данных, изменения схемы и изменения распределения.
- Конвейеры входных данных.
- Код для обучения, проверки и обслуживания модели.
- Прогнозирование модели и производительность.
Интегрируйте Databricks в ваши процессы CI/CD
MLOps, DataOps, ModelOps и DevOps относятся к интеграции процессов разработки с "операциями", что делает процессы и инфраструктуру предсказуемыми и надежными. В этом наборе статей описывается интеграция принципов операций (ops) в рабочие процессы машинного обучения на платформе Databricks.
Databricks включает все компоненты, необходимые для жизненного цикла машинного обучения, включая средства для создания "конфигурации в виде кода", чтобы обеспечить воспроизводимость и "инфраструктуру в виде кода" для автоматизации подготовки облачных служб. Она также включает в себя службы ведения журнала и оповещений, помогающие обнаруживать и устранять проблемы при их возникновении.
DataOps: надежные и безопасные данные
Хорошие модели машинного обучения зависят от надежных конвейеров данных и инфраструктуры. С помощью Платформы аналитики данных Databricks весь конвейер данных от приема данных к выходным данным из обслуживаемой модели находится на одной платформе и использует тот же набор инструментов, который упрощает производительность, воспроизводимость, общий доступ и устранение неполадок.

Задачи и средства DataOps в Databricks
В таблице перечислены распространенные задачи и средства DataOps в Databricks:
| Задача DataOps | Инструмент в Databricks |
|---|---|
| Прием и преобразование данных | Автозагрузчик и Apache Spark |
| Отслеживание изменений в данных, включая версионирование и родословную данных. | дельта-таблиц |
| Создание, управление и мониторинг конвейеров обработки данных | Декларативные конвейеры Lakeflow |
| Обеспечение безопасности и управления данными | каталог Unity |
| Анализ аналитических данных и панели мониторинга | Databricks SQL, панели мониторинга, и записные книжки Databricks |
| Общее кодирование | Databricks SQL и записные книжки Databricks |
| Планирование конвейеров данных | Задания Lakeflow |
| Автоматизация общих рабочих процессов | Задания Lakeflow |
| Создание, хранение, управление и обнаружение функций для обучения модели | Хранилище признаков в Databricks |
| Мониторинг данных | Мониторинг Lakehouse |
ModelOps: разработка моделей и жизненный цикл
Для разработки модели требуется ряд экспериментов и способ отслеживания и сравнения условий и результатов этих экспериментов. Платформа интеллектуального анализа данных Databricks включает MLflow для отслеживания разработки моделей и Реестр моделей MLflow для управления жизненным циклом модели, включая этапы размещения, сервинга и хранения артефактов модели.
После выпуска модели в рабочую среду многие вещи могут измениться, которые могут повлиять на ее производительность. Помимо мониторинга производительности прогнозирования модели, необходимо также отслеживать входные данные для изменений качества или статистических характеристик, которые могут потребовать повторного обучения модели.
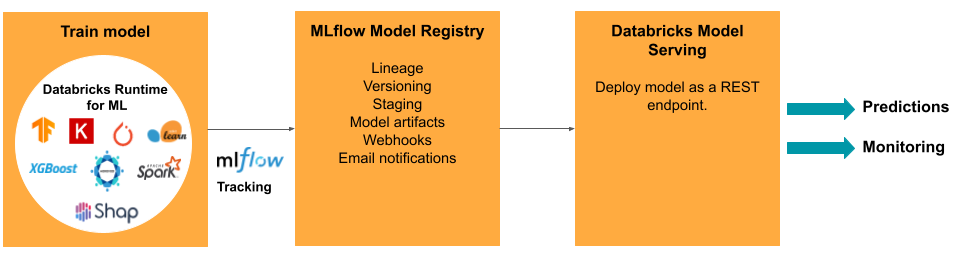
Задачи и средства ModelOps в Databricks
В таблице перечислены распространенные задачи и средства ModelOps, предоставляемые Databricks:
| Задача ModelOps | Инструмент в Databricks |
|---|---|
| Отслеживание разработки модели | Отслеживание моделей MLflow |
| Управление жизненным циклом модели | модели в каталоге Unity |
| Управление версиями кода модели и совместное использование | Git-папки Databricks |
| Разработка модели без кода | AutoML |
| Мониторинг моделей | Мониторинг Lakehouse |
DevOps: производство и автоматизация
Платформа Databricks поддерживает модели машинного обучения в рабочей среде следующим образом:
- Полное происхождение данных и моделей: от моделей в производственной среде до исходных необработанных данных на той же платформе.
- Обслуживание модели в производственной среде: автоматически масштабируется на основе бизнес-потребностей.
- Задания. Автоматизация заданий и создание запланированных рабочих процессов машинного обучения.
- Папки Git: управление версиями кода и совместное использование из рабочей области помогают командам следовать передовым практикам программной инженерии.
- Пакеты ресурсов Databricks: автоматизирует создание и развертывание ресурсов Databricks, таких как задания, зарегистрированные модели и конечные точки обслуживания.
- Провайдер Databricks Terraform: автоматизирует развертывание инфраструктуры в облаках для заданий по выводу моделей машинного обучения, обслуживания конечных точек и заданий по созданию признаков.
Сервис для работы с моделью
Для развертывания моделей в продакшн-среду MLflow значительно упрощает процесс, предоставляя развертывание либо одним щелчком в качестве пакетного задания для больших объемов данных, либо в качестве REST-эндпоинта в кластере автомасштабирования. Интеграция Хранилища признаков Databricks с MLflow также обеспечивает согласованность признаков для обучения и обслуживания. Кроме того, модели MLflow могут автоматически искать признаки из Хранилища признаков, даже для онлайн-обслуживания с низкой задержкой.
Платформа Databricks поддерживает множество вариантов развертывания моделей:
- Код и контейнеры.
- Пакетная обработка.
- Низкая задержка в обслуживании онлайн.
- На устройстве или на периферии.
- Например, в мультиоблачной среде можно обучать модель на одном облаке и развертывать её на другом.
Для получения дополнительной информации см. Mosaic AI Model Serving.
Работы
Задания Lakeflow позволяют автоматизировать и планировать любую рабочую нагрузку, от ETL до машинного обучения. Databricks также поддерживает интеграцию с популярными сторонними оркестраторами, такими как Airflow.
Папки Git
Платформа Databricks включает Git в рабочую область, чтобы помочь командам следовать рекомендациям по проектированию программного обеспечения, выполняя операции Git через пользовательский интерфейс. Администраторы и инженеры DevOps могут использовать API для настройки автоматизации с помощью любимых средств CI/CD. Databricks поддерживает любое развертывание Git, включая частные сети.
Дополнительные сведения о рекомендациях по разработке кода с помощью папок Databricks Git см. в разделе рабочие процессы CI/CD с интеграцией Git и папками Databricks Git и Используйте CI/CD. Эти методы вместе с REST API Databricks позволяют создавать автоматизированные процессы развертывания с помощью GitHub Actions, конвейеров Azure DevOps или заданий Jenkins.
Каталог Unity для управления и безопасности
Платформа Databricks включает Unity Catalog, что позволяет администраторам настраивать детальное управление доступом, политики безопасности и управление и контроль всеми данными и ресурсами ИИ в Databricks.