Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Используйте Python в записной книжке Azure Databricks для выполнения анализа аналитических данных (EDA): загрузки и очистки набора данных, изучения его характеристик и визуализации тенденций для создания аналитических сведений.
Записная книжка, используемая в этом руководстве, изучает глобальные данные о энергии и выбросах и демонстрирует загрузку, очистку и изучение данных.
Вы можете использовать пример записной книжки , или создать собственную записную книжку с нуля.
Что такое EDA?
Анализ аналитических данных (EDA) является критически важным шагом в процессе обработки и анализа данных, который включает в себя анализ и визуализацию данных в следующих целях:
- Выявить его основные характеристики.
- Определение шаблонов и тенденций.
- Обнаружение аномалий.
- Общие сведения о связях между переменными.
EDA предоставляет аналитические сведения о наборе данных, упрощая обоснованные решения о дальнейших статистических анализах или моделировании.
С помощью записных книжек Azure Databricks специалисты по обработке и анализу данных могут выполнять EDA с помощью знакомых средств. Например, в этом руководстве используются некоторые распространенные библиотеки Python для обработки и построения данных, в том числе:
- Numpy: фундаментальная библиотека для числовых вычислений, обеспечивающая поддержку массивов, матриц и широкий спектр математических функций для работы с этими структурами данных.
- pandas: мощная библиотека для обработки и анализа данных, построенная на основе NumPy, которая предлагает структуры данных, такие как DataFrame, для эффективного управления структурированными данными.
- Plotly: интерактивная библиотека построения графиков, которая позволяет создавать высококачественные интерактивные визуализации для анализа и представления данных.
- Matplotlib: комплексная библиотека для создания статических, анимированных и интерактивных визуализаций в Python.
Azure Databricks также предоставляет встроенные функции для изучения данных в результатах записной книжки, таких как фильтрация и поиск данных в таблицах, а также увеличение визуализаций. Вы также можете использовать Код Genie для написания кода для EDA.
Перед началом работы
Для работы с этим руководством вам потребуется следующее:
- Необходимо иметь разрешение на использование существующего вычислительного ресурса или создать новый вычислительный ресурс. См. Вычислить.
- [Необязательно] В этом руководстве описывается, как использовать Genie Code для создания кода. Дополнительные сведения см. в разделе «Использование кода Genie».
Скачивание набора данных и импорт CSV-файла
В этом руководстве демонстрируются методы EDA, изучая глобальные данные о энергии и выбросах. Чтобы следовать, скачайте набор данных о потреблении энергии от Our World in Data с Kaggle. В этом руководстве используется файл owid-energy-data.csv.
Чтобы импортировать набор данных в рабочую область Azure Databricks, выполните следующие действия.
На боковой панели рабочей области нажмите Рабочая область, чтобы открыть обозреватель рабочей области.
Перетащите CSV-файл
owid-energy-data.csvв рабочую область.Это открывает модальное окно импорта. Обратите внимание на целевую папку , указанную здесь. Этот параметр устанавливается в текущую папку в браузере рабочей области и становится назначением импортированного файла.
Щелкните на Импорт. Файл должен отображаться в целевой папке в рабочей области.
Вам потребуется путь к файлу для загрузки файла в записную книжку позже. Найдите файл в браузере рабочей области. Чтобы скопировать путь к файлу в буфер обмена, щелкните правой кнопкой мыши имя файла, а затем выберите Копировать URL-адрес или путь>полный путь.
Создание записной книжки
Чтобы создать новую записную книжку в домашней папке пользователя, щелкните ![]() Новый на боковой панели и выберите Записная книжка в меню.
Новый на боковой панели и выберите Записная книжка в меню.
Вверху рядом с именем записной книжки выберите Python в качестве языка по умолчанию для записной книжки.
Дополнительные сведения о создании записных книжек и управлении ими см. в статье Управление записными книжками.
Добавьте каждый пример кода в эту статью в новую ячейку в записной книжке. Или используйте пример блокнота , предоставленный для следования за руководством.
Загрузка CSV-файла
В новой ячейке записной книжки загрузите CSV-файл. Для этого импортируйте numpy и pandas. Это полезные библиотеки Python для обработки и анализа данных.
Создайте DataFrame pandas на основе набора данных для упрощения обработки и визуализации. Замените указанный ниже путь к файлу тем, который вы скопировали ранее.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
Запустите ячейку. Результатом должен быть DataFrame из библиотеки Pandas, который включает список каждого столбца и его типа.
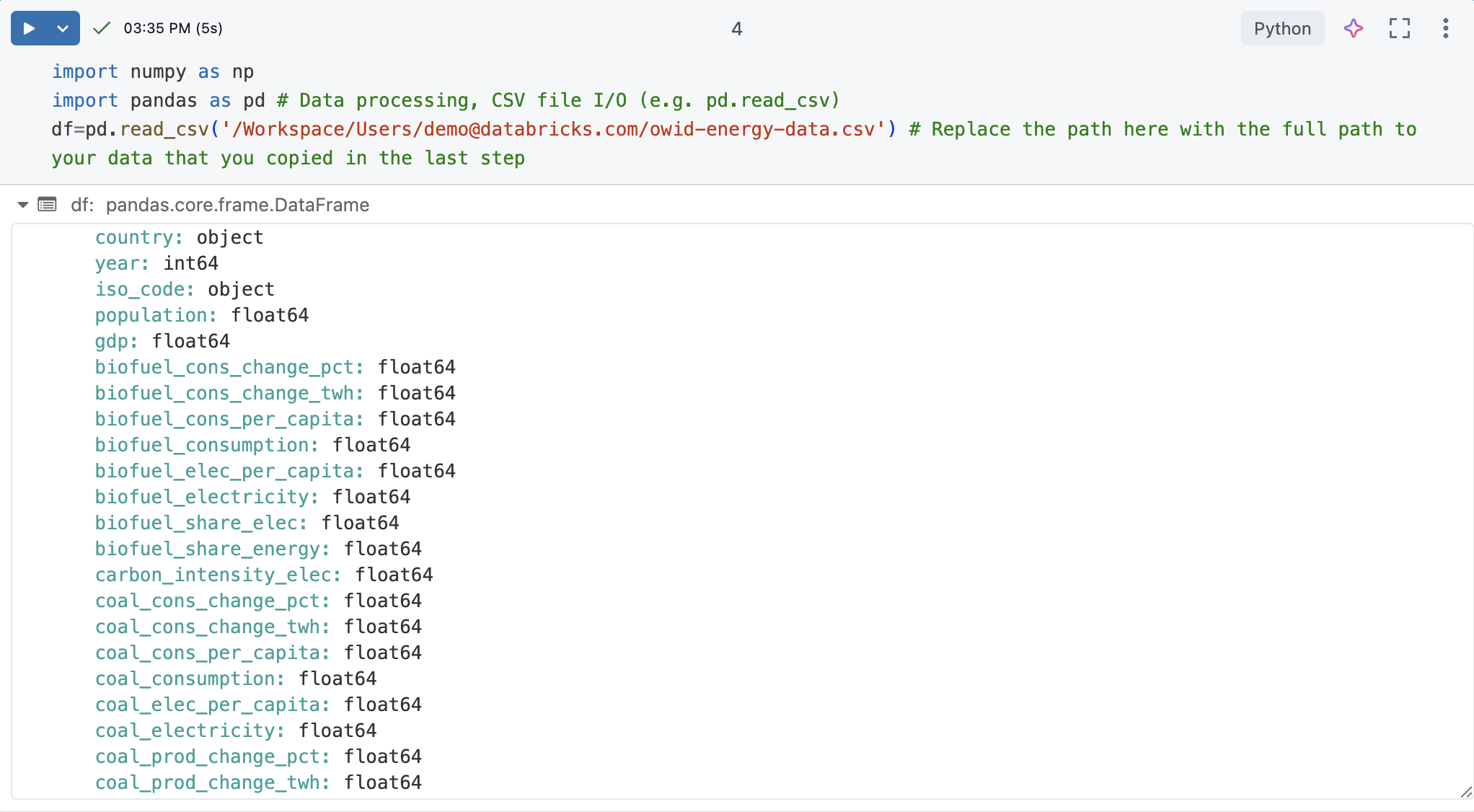
Общие сведения о данных
Понимание основных принципов набора данных имеет решающее значение для любого проекта обработки и анализа данных. Он включает в себя знакомство со структурой, типами и качеством имеющихся данных.
В записной книжке Azure Databricks можно использовать команду display(df) для отображения набора данных.
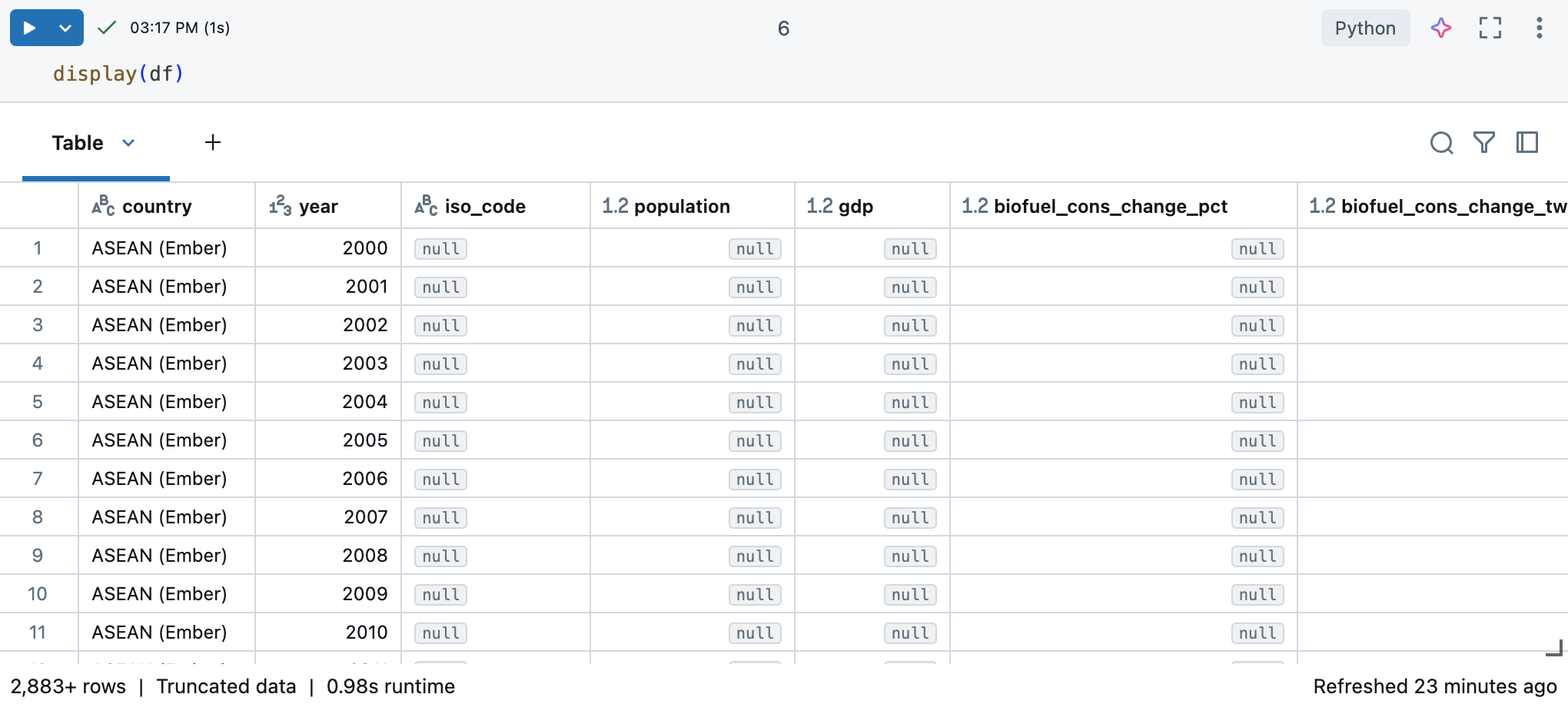
Так как набор данных имеет более 10 000 строк, эта команда возвращает усеченный набор данных. Слева от каждого столбца можно увидеть тип данных столбца. Дополнительные сведения см. в разделе Форматирование столбцов.
Используйте pandas для получения данных
Чтобы эффективно понять набор данных, используйте следующие команды pandas:
Команда
df.shapeвозвращает размеры таблицы данных, предоставляя краткий обзор количества строк и столбцов.
Команда
df.dtypesпредоставляет типы данных каждого столбца, помогая понять тип данных, с которыми вы работаете. Вы также можете увидеть тип данных для каждого столбца в таблице результатов.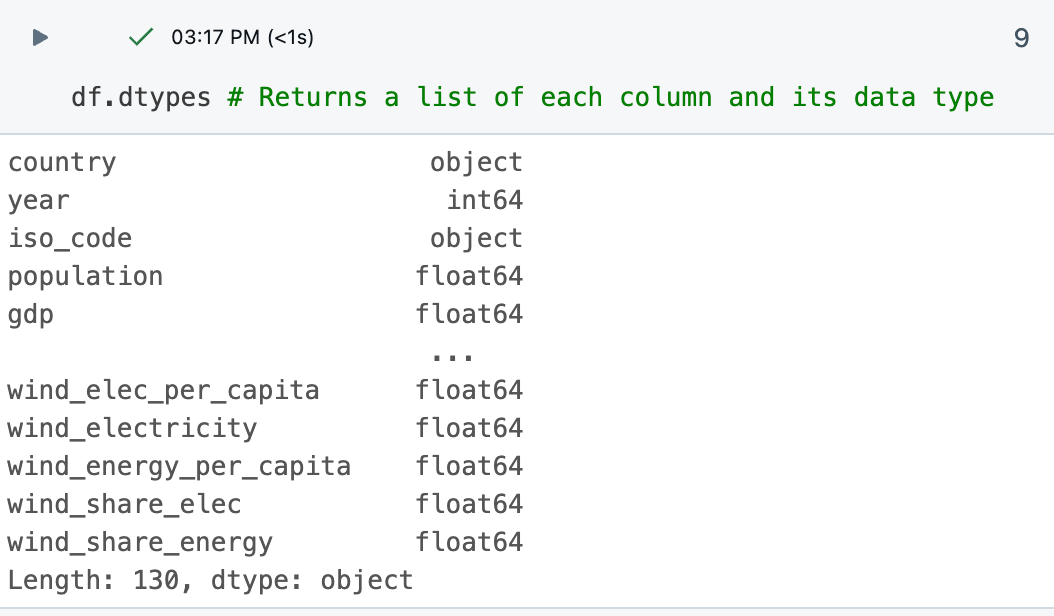
Команда
df.describe()создает описательную статистику для числовых столбцов, таких как среднее, стандартное отклонение и процентили, которые помогут вам определить закономерности, обнаружить аномалии и понять распределение данных. Используйте это сdisplay()для просмотра сводной статистики в табличном формате, с которым можно взаимодействовать. Исследуйте данные, используя выходную таблицу записной книжки Databricks.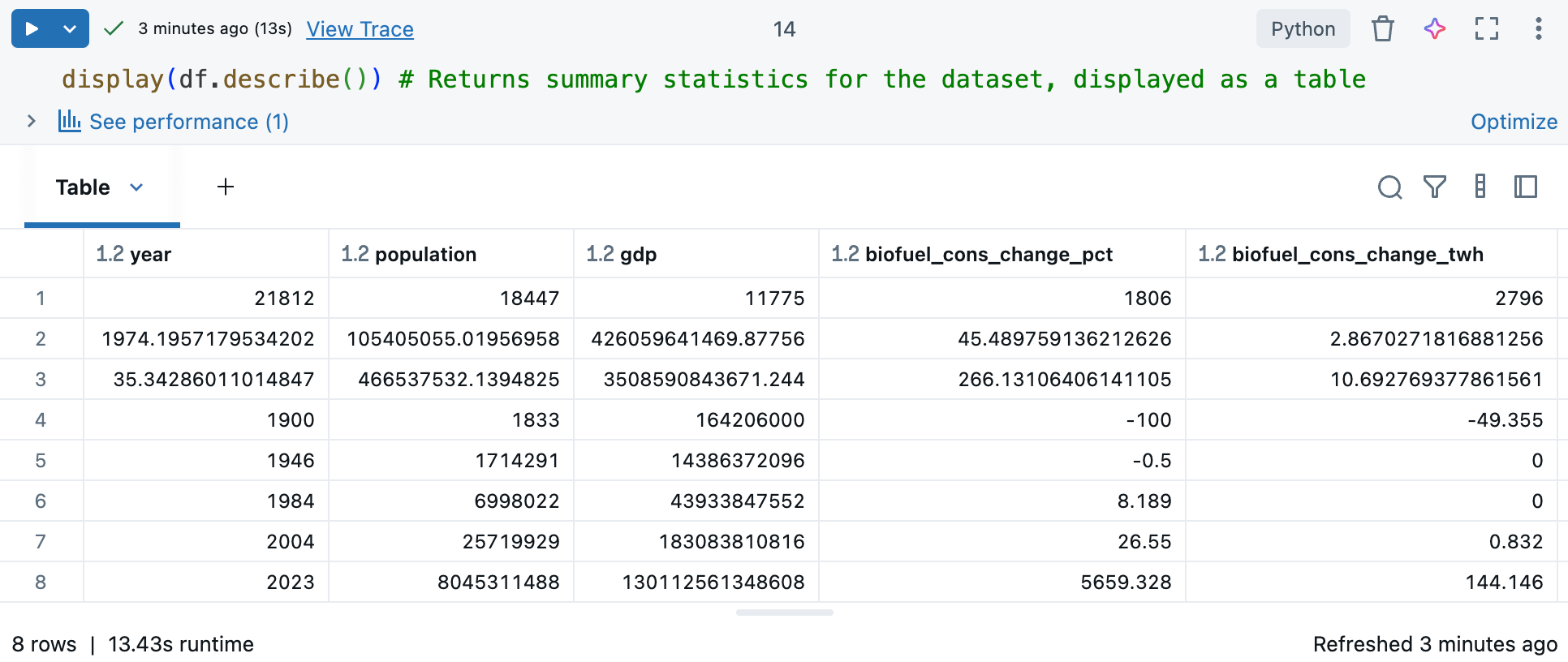
Создание профиля данных
Замечание
Доступно в Databricks Runtime 9.1 LTS и более поздних версиях.
Azure Databricks ноутбуки имеют встроенные функции профилирования данных. При просмотре DataFrame с помощью функции display в Azure Databricks, можно сгенерировать профиль данных из вывода таблицы.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
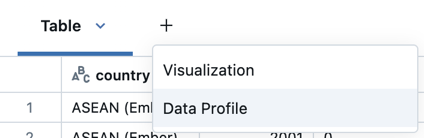
Щелкните +>Профиль данных рядом с Таблицей на выходе. При этом выполняется новая команда, которая создает профиль данных в DataFrame.
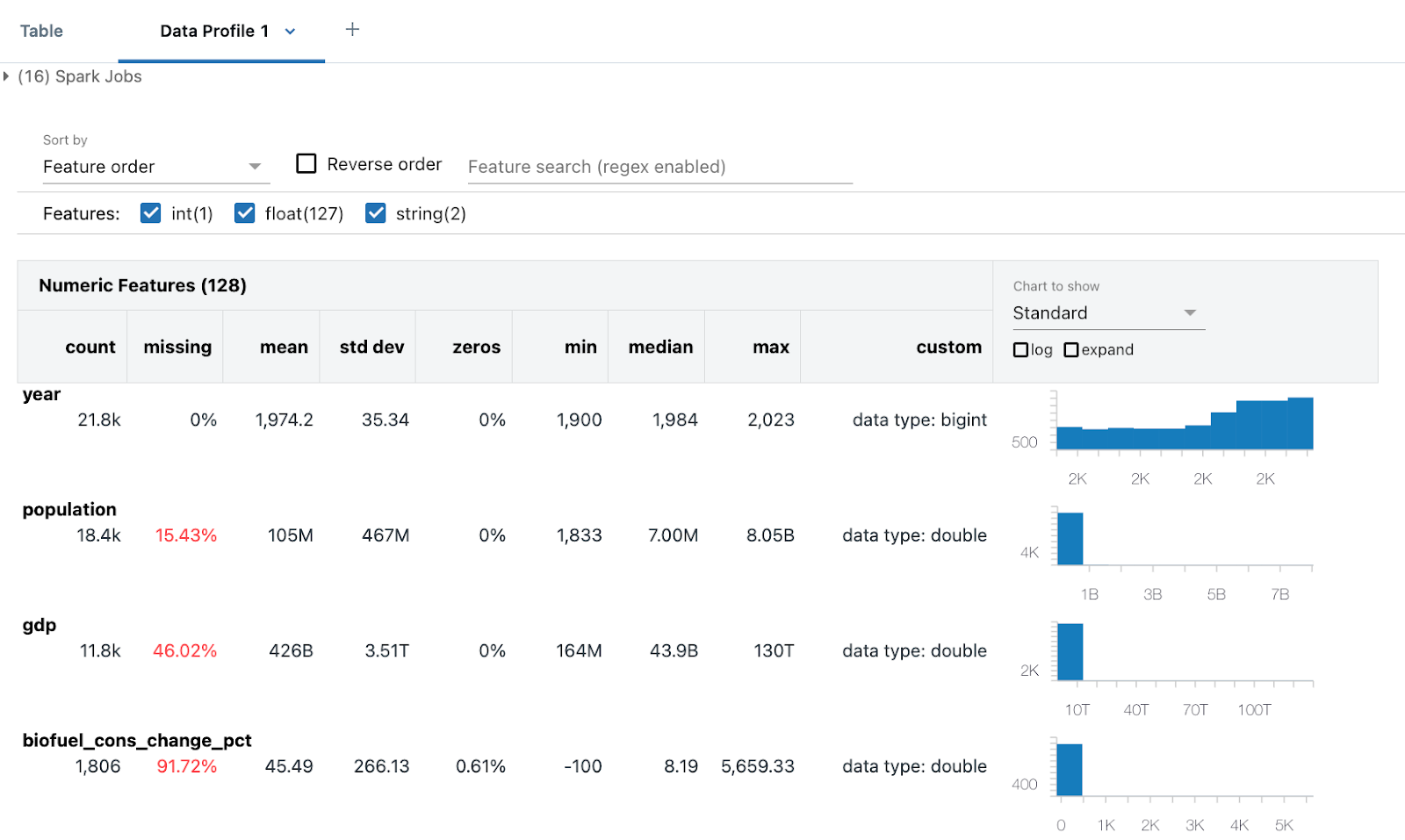
Профиль данных содержит сводную статистику для числовых, строковых и датовых столбцов, а также гистограммы распределения значений для каждого столбца. Вы также можете создавать профили данных программным способом; см. команды сводки (dbutils.data.summarize).
Очистка данных
Очистка данных является важным шагом в EDA, чтобы убедиться, что набор данных является точным, согласованным и готовым к понятному анализу. Этот процесс включает в себя несколько ключевых задач, чтобы обеспечить готовность данных к анализу, в том числе:
- Определение и удаление повторяющихся данных.
- Обработка отсутствующих значений, которые могут включать замену их определенным значением или удаление затронутых строк.
- Стандартизация типов данных (например, преобразование строк в
datetime) через преобразования и трансформации для обеспечения согласованности. Вы также можете преобразовать данные в формат, с которым проще работать.
Этот этап очистки необходим, так как он улучшает качество и надежность данных, обеспечивая более точный и аналитический анализ.
Совет. Использование Genie Code для помощи в задачах очистки данных
Вы можете использовать Код Genie для создания кода. Создайте новую ячейку кода и щелкните ссылку создания или используйте значок Кода Genie в правом верхнем углу, чтобы открыть Genie Code. Введите запрос к Коду Genie. Код Genie может генерировать код на Python или SQL или создавать текстовое описание. Для разных результатов нажмите сгенерировать заново.
Например, попробуйте использовать код Genie, чтобы очистить данные:
- Проверьте, содержит ли
dfповторяющиеся столбцы или строки. Печать дубликатов. Затем удалите дубликаты. - Какой формат имеют столбцы дат? Измените его на
'YYYY-MM-DD'. - Я не собираюсь использовать
XXXстолбец. Удалите его.
Посмотрите Получи помощь по программированию от Genie Code.
Удаление повторяющихся данных
Проверьте, имеют ли данные повторяющиеся строки или столбцы. Если да, удалите их.
Совет
Используйте Genie Code для создания кода.
Попробуйте ввести запрос: "Проверьте, содержит ли df любые повторяющиеся столбцы или строки. Печать дубликатов. Затем удалите дубликаты". Код Genie может создать код, как показано ниже.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
В этом случае набор данных не имеет повторяющихся данных.
Обработка значений NULL или отсутствующих значений
Распространенный способ обработки значений NaN или NULL — заменить их на 0 для упрощения математической обработки.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Это гарантирует, что отсутствующие данные в кадре данных заменяются значением 0, что может быть полезно для последующих шагов анализа данных или обработки, когда отсутствующие значения могут вызвать проблемы.
Переформатируйте даты
Даты часто форматируются различными способами в разных наборах данных. Они могут находиться в формате даты, строках или целых числах.
Для этого анализа следует рассматривать столбец year как целое число. Следующий код является одним из способов сделать это:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Это обеспечивает, что столбец year содержит только целочисленные значения годов, а любые недопустимые записи преобразуются в NaT (Not a Time).
Исследуйте данные, используя выходную таблицу Databricks ноутбука
Azure Databricks предоставляет встроенные функции для изучения данных с помощью выходной таблицы.
В новой ячейке используйте display(df) для отображения набора данных в виде таблицы.
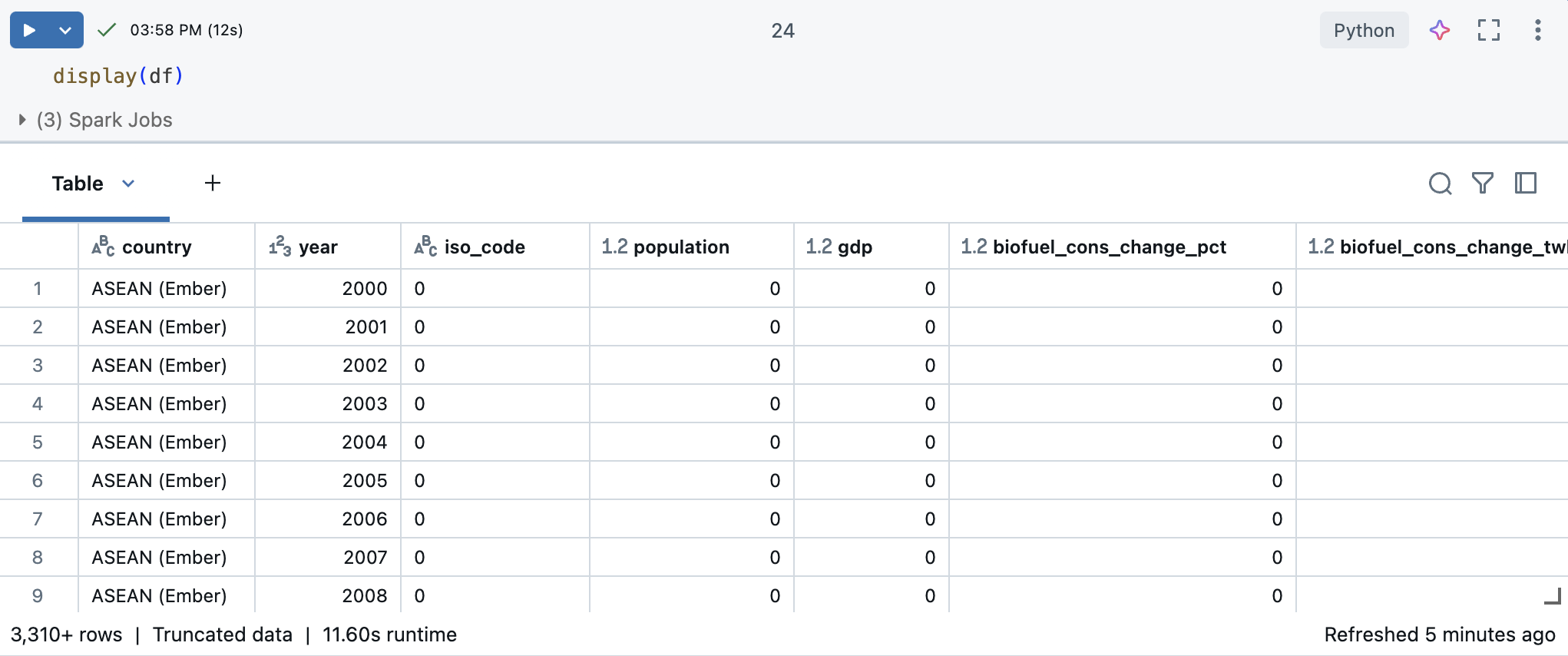
Используя выходную таблицу, вы можете просматривать данные несколькими способами:
- Поиск данных для определенной строки или значения
- Фильтр для определенных условий
- Создание визуализаций с помощью набора данных
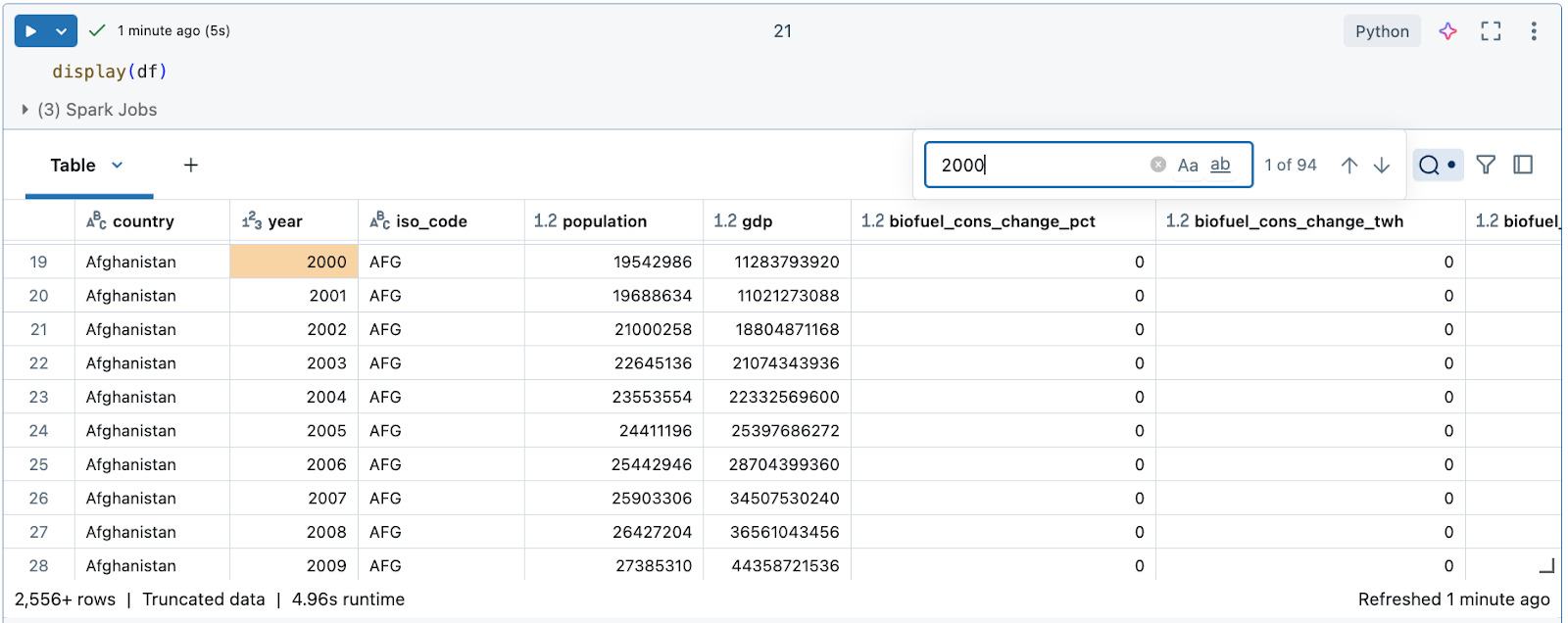
Поиск данных для определенной строки или значения
Щелкните значок поиска в правом верхнем углу таблицы и введите поиск.
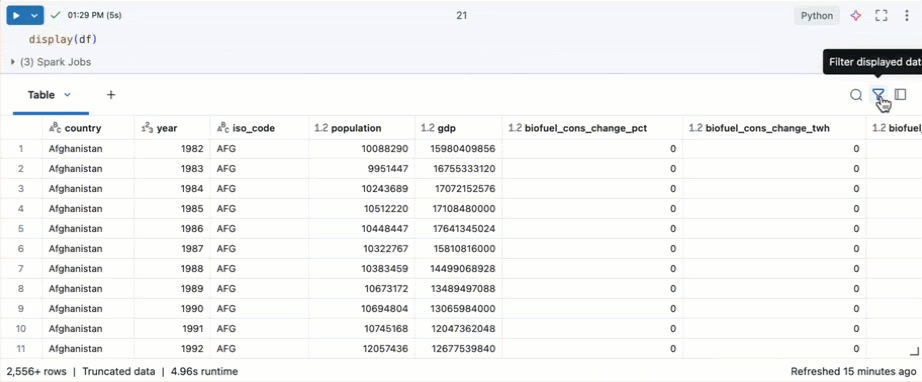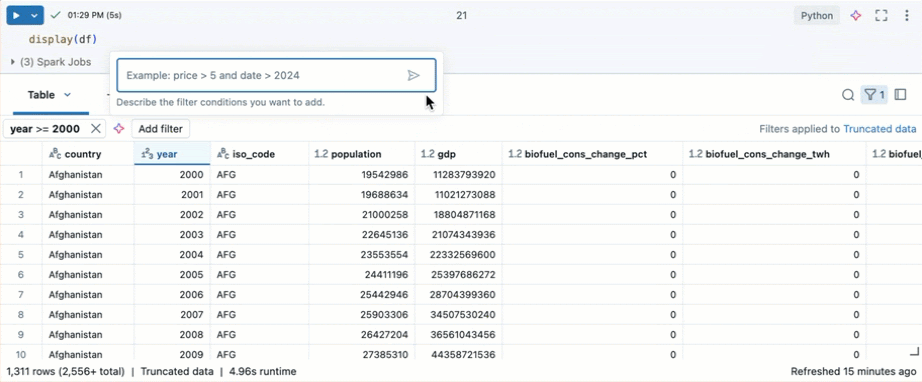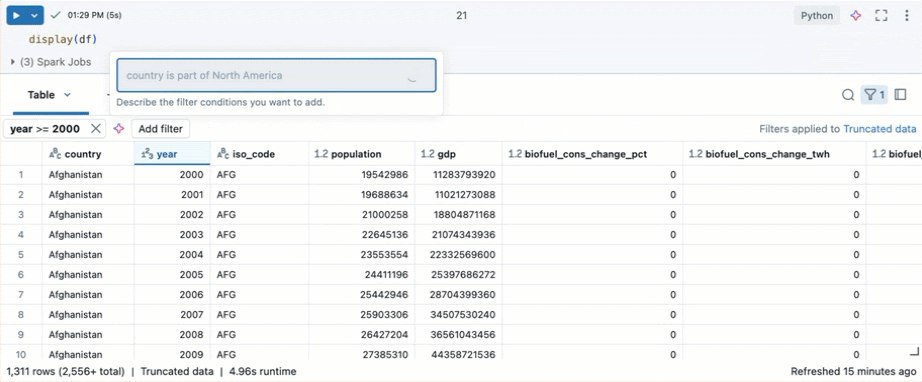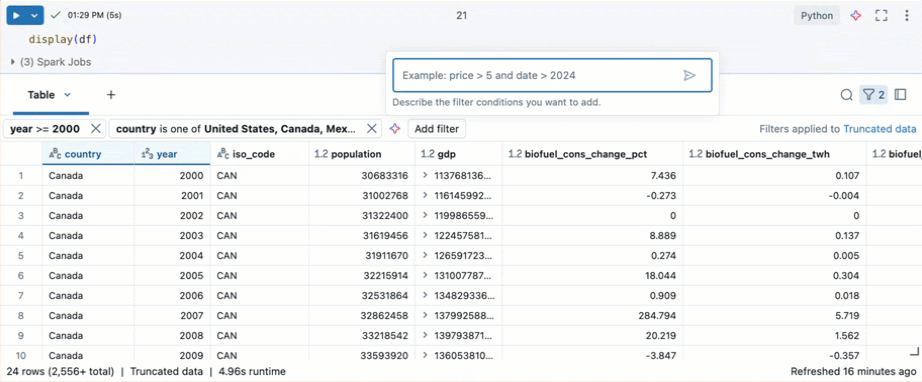
Фильтрация по определенным условиям
Встроенные фильтры таблиц можно использовать для фильтрации столбцов для определенных условий. Существует несколько способов создания фильтра. См. результаты фильтрации.
Совет
Используйте Genie Code для создания фильтров. Щелкните значок фильтра в правом верхнем углу таблицы. Введите условие фильтра. Genie Code автоматически создает фильтр для вас.
Создание визуализаций с помощью набора данных
Наверху таблицы вывода щелкните +>Визуализация, чтобы открыть редактор визуализации.
Выберите тип визуализации и столбцы, которые вы хотите визуализировать. В редакторе отображается предварительная версия диаграммы на основе вашей конфигурации. Например, на рисунке ниже показано, как добавить несколько графиков для просмотра потребления различных возобновляемых источников энергии с течением времени.
Щелкните Сохранить, чтобы добавить визуализацию как вкладку в вывод ячейки.
См. создание новой визуализации.
Изучение и визуализация данных с помощью библиотек Python
Изучение данных с помощью визуализаций является основным аспектом EDA. Визуализации помогают выявить закономерности, тенденции и связи в данных, которые могут быть не сразу очевидны только с помощью числового анализа. Используйте такие библиотеки, как Plotly или Matplotlib, для распространенных методов визуализации, включая точечные диаграммы, столбчатые диаграммы, линейные графики и гистограммы. Эти визуальные инструменты позволяют специалистам по обработке и анализу данных определять аномалии, понимать распределения данных и наблюдать корреляции между переменными. Например, диаграммы рассеивания могут выделить выбросы, а графики временных рядов могут выявить тенденции и сезонность.
- Создание массива для уникальных стран
- Диаграмма тенденций выбросов для 10 крупнейших стран-эмитентов (2000-2022)
- Фильтруйте и отображайте выбросы по регионам
- Вычисление и график роста доли возобновляемых источников энергии
- Точечный график: показать влияние возобновляемых источников энергии на крупнейшие источники выбросов
- Модели прогнозируемого глобального потребления энергии
Создание массива для уникальных стран
Изучите страны, включенные в набор данных, создав массив для уникальных стран. Создание массива отображает сущности, перечисленные как country.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
Результат:

Инсайт :
Столбец country включает различные сущности, такие как мир, страны с высоким уровнем дохода, Азия и Соединенные Штаты, которые не всегда можно сопоставить напрямую. Это может быть более полезно для фильтрации данных по регионам.
Построение диаграмм тенденций выбросов для 10 ведущих стран-источников (2000-2022)
Предположим, вы хотите сосредоточить свое расследование на 10 странах с самым высокими выбросами парниковых газов в 2000-х годах. Вы можете отфильтровать данные для тех лет, которые хотите рассмотреть, и для первых 10 стран с наибольшим объемом выбросов, а затем использовать Plotly для создания линейного графика, показывающего их выбросы с течением времени.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
Результат:
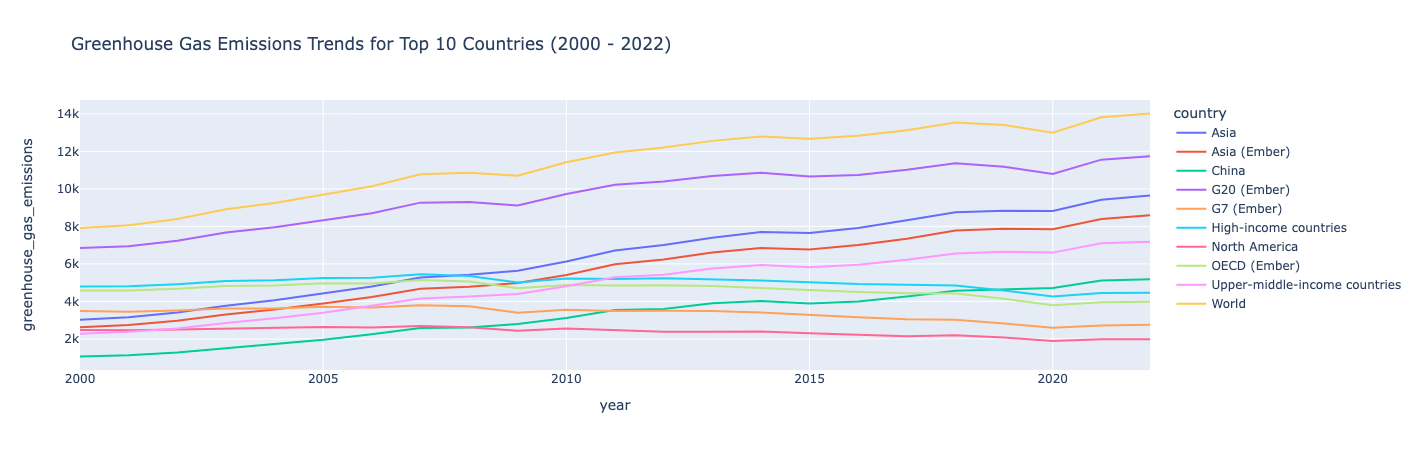
Инсайт :
С 2000 по 2022 год выбросы парниковых газов в целом увеличивались, за исключением нескольких стран, где они оставались относительно стабильными или незначительно снижались в течение этого периода.
Фильтрация и диаграмма выбросов по регионам
Отфильтруйте данные по регионам и вычислите общий объем выбросов для каждого региона. Затем постройте данные в виде столбчатой диаграммы.
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
Результат:
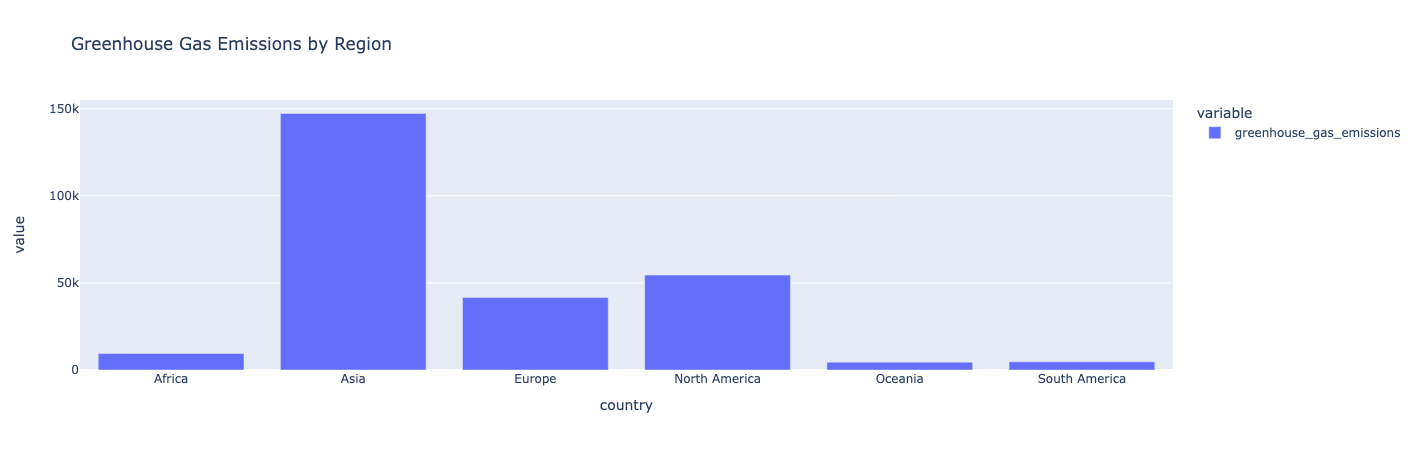
Аналитика:
Азия имеет самые высокие выбросы парниковых газов. Океания, Южная Америка и Африка производят самые низкие выбросы парниковых газов.
Вычисление и граф роста доли возобновляемых источников энергии
Создайте новую функцию или столбец, который вычисляет долю возобновляемых источников энергии как соотношение потребления возобновляемых источников энергии по сравнению с основным потреблением энергии. Затем ранжьте страны на основе их средней доли возобновляемых источников энергии. Для первых 10 стран постройте график их доли возобновляемых источников энергии с течением времени.
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
Результат:
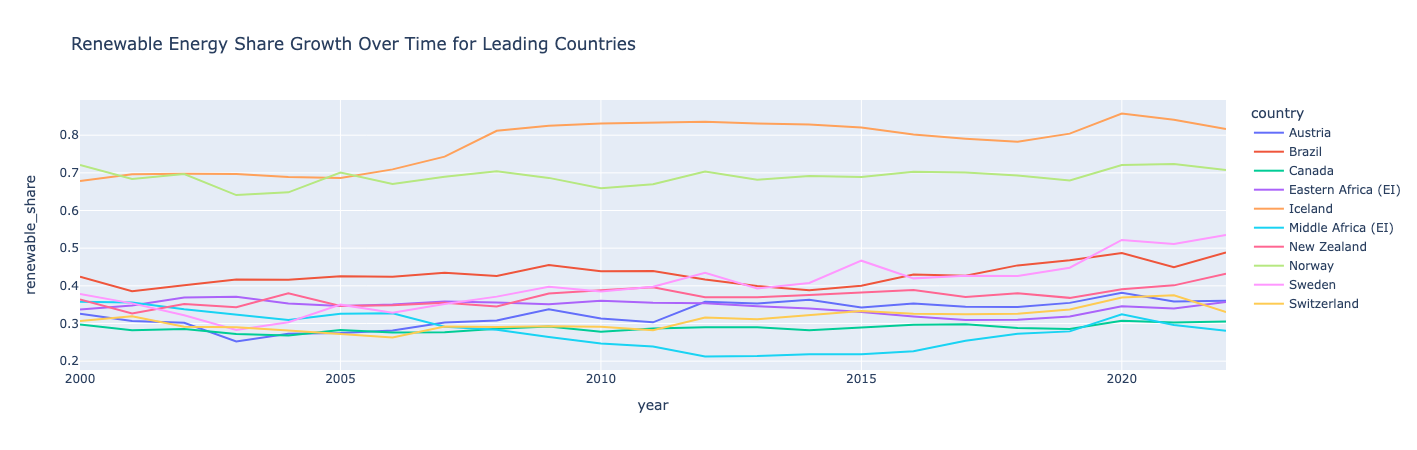
Инсайт :
Норвегия и Исландия являются мировыми лидерами в области возобновляемых источников энергии, где более половины их потребления обеспечивается за счет возобновляемых источников энергии.
Исландия и Швеция видели самый большой рост их доли возобновляемых источников энергии. Все страны видели случайные спады и рост, демонстрируя, как рост доли возобновляемых источников энергии не обязательно линейный. Средняя Африка испытывала спад в начале 2010-х, но восстановилась в 2020 году.
Диаграмма рассеяния: показывает влияние возобновляемых источников энергии для крупнейших источников выбросов
Отфильтруйте данные для лучших 10 источников, а затем используйте точечную диаграмму, чтобы посмотреть на долю возобновляемых источников энергии и выбросы парниковых газов со временем.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
Результат:
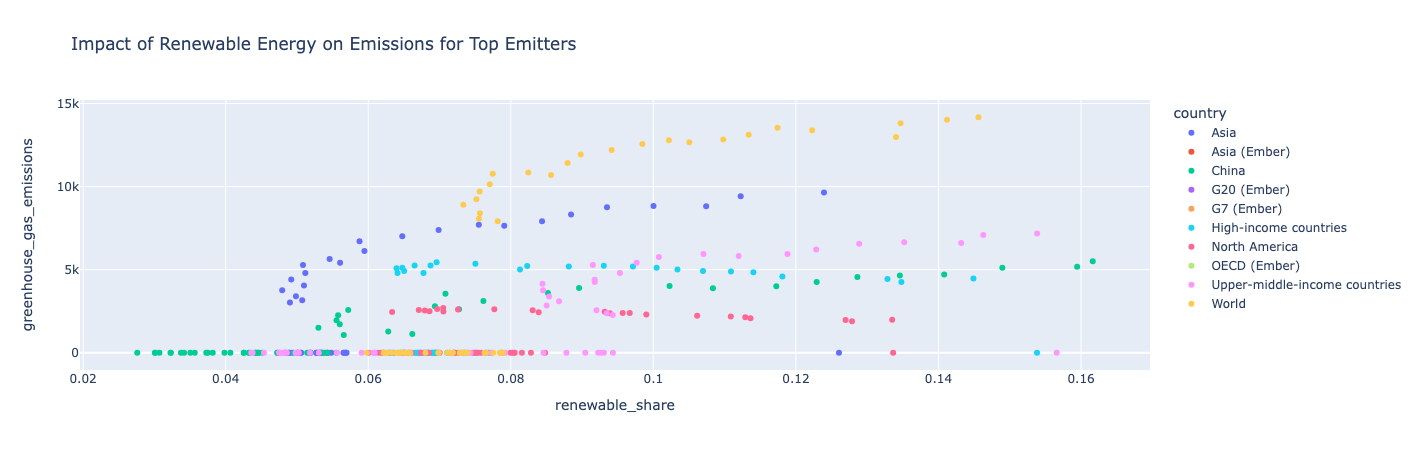
Инсайт :
Как страна использует более возобновляемые источники энергии, она также имеет больше выбросов парниковых газов, что означает, что его общее потребление энергии растет быстрее, чем его возобновляемые источники потребления. Северная Америка является исключением из-за того, что выбросы парниковых газов остаются относительно постоянными в течение многих лет, поскольку его возобновляемый ресурс продолжает увеличиваться.
Модель прогнозируемого глобального потребления энергии
Агрегирование глобального потребления первичной энергии за год, а затем создание модели автоматической статистической интегрированной скользящей средней (ARIMA) для прогнозирования общего глобального потребления энергии в течение следующих нескольких лет. График исторического и прогнозируемого потребления энергии с помощью Matplotlib.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
Результат:
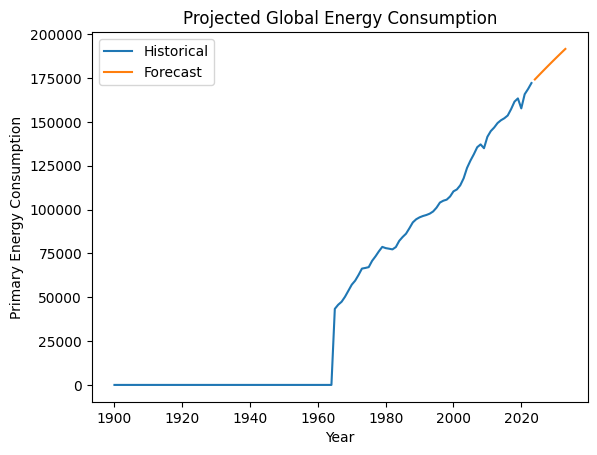
Инсайт :
Эта модель прогнозирует, что глобальное потребление энергии будет продолжать расти.
Пример записной книжки
Выполните действия, описанные в этой статье, используйте следующую записную книжку. Для получения инструкции по импорту записной книжки в рабочую область Azure Databricks см. в статье Импорт записной книжки.
Руководство по EDA с глобальными данными о энергии
Дальнейшие действия
Теперь, когда вы выполнили первоначальный анализ аналитических данных в наборе данных, выполните следующие действия.
- Дополнительные примеры визуализации EDA см. в приложении (в примере записной книжки ).
- Если во время работы с этим руководством возникают ошибки, попробуйте использовать встроенный отладчик для пошагового выполнения кода. См. отладочные блокноты.
- Поделитесь записной книжкой с вашей командой, чтобы они могли познакомиться с вашим анализом. В зависимости от того, какие разрешения вы предоставляете им, они могут помочь разработать код для дальнейшего анализа или добавления комментариев и предложений для дальнейшего изучения.
- Как только вы завершите ваш анализ, создайте панель мониторинга в записной книжке или панель мониторинга AI/BI с ключевыми визуализациями для передачи заинтересованным сторонам.