Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Синхронизированные таблицы позволяют обслуживать данные озерохранилища с помощью Lakebase Postgres. Таблицы каталога Unity синхронизируются с Postgres, чтобы приложения могли запрашивать данные lakehouse непосредственно с низкой задержкой. Этот процесс обычно называется обратным ETL. Lakehouse оптимизирован для аналитики и обогащения, а Lakebase предназначен для операционных рабочих нагрузок, требующих быстрого поиска запросов и согласованности транзакций.
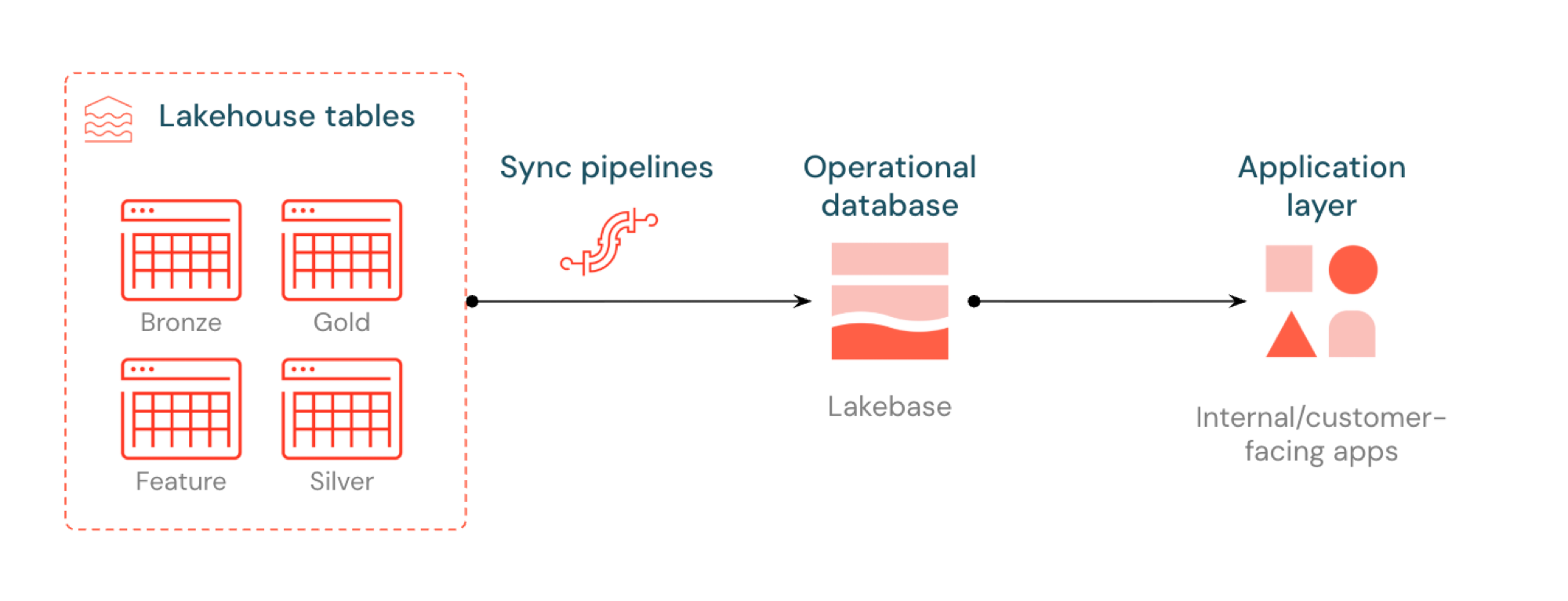
Что такое синхронизированные таблицы?
Синхронизированные таблицы позволяют обслуживать данные аналитики из каталога Unity через Lakebase Postgres, что делает его доступным для приложений, которым требуются запросы с низкой задержкой и полные транзакции ACID. Они перекрывают разрыв между аналитическим хранилищем и операционными системами, сохраняя ваши данные готовыми к использованию в приложениях в режиме реального времени.
Поддерживаемые источники
Синхронизированные таблицы поддерживают следующие типы источников каталога Unity:
- Управляемые и внешние таблицы Delta
- Управляемые и внешние таблицы Iceberg
- Представления и материализованные представления
Принцип работы
Синхронизированные таблицы Databricks создают управляемую копию данных каталога Unity в Lakebase. При создании синхронизированной таблицы вы получите следующее:
- Синхронизированная таблица в каталоге Unity, ссылающаяся на конвейер синхронизации
- Таблица Postgres в Lakebase (доступная только для чтения, запрашиваемая приложениями)
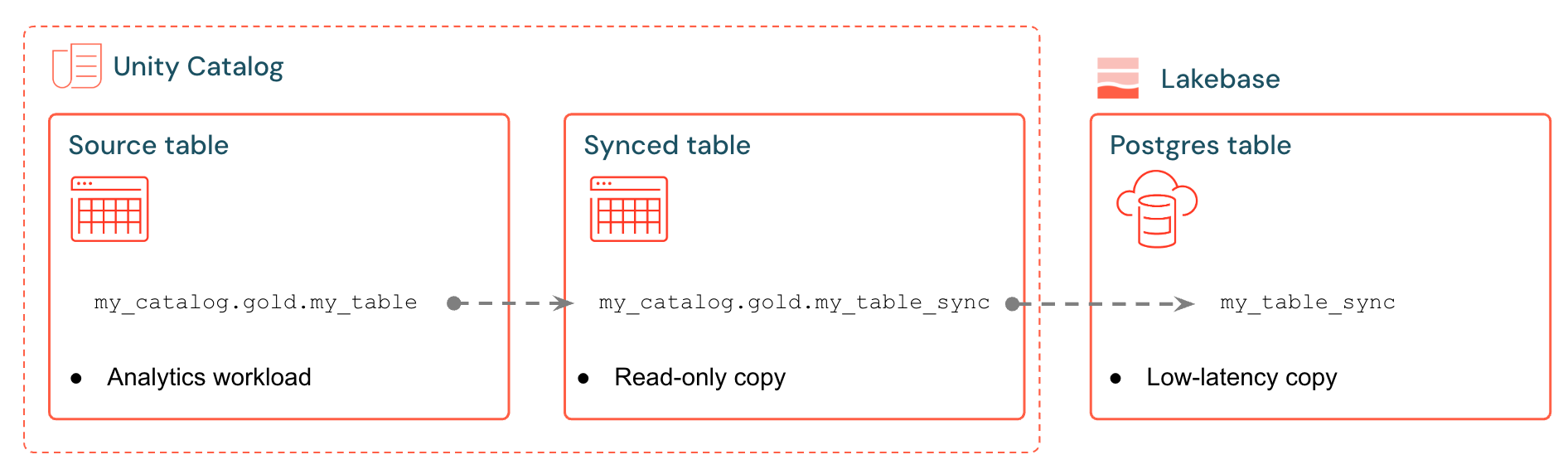
Например, можно синхронизировать золотые таблицы, встроенные функции или выходные данные машинного обучения в analytics.gold.user_profiles новую синхронизированную таблицу analytics.gold.user_profiles_synced. В Postgres имя схемы каталога Unity становится именем схемы Postgres, поэтому это выглядит следующим образом gold.user_profiles_synced:
SELECT * FROM gold.user_profiles_synced WHERE user_id = 12345;
Приложения подключаются к стандартным драйверам Postgres и запрашивают синхронизированные данные вместе с собственным рабочим состоянием.
Предупреждение
Хотя можно изменить синхронизированную таблицу непосредственно в Postgres, Azure Databricks строго рекомендует выполнять только запросы на чтение для защиты целостности данных с помощью источника. Поддерживаемые операции с синхронизированными таблицами см. в разделе "Операции, разрешенные для синхронизированных таблиц в Postgres".
Конвейеры синхронизации используют управляемые Lakeflow Spark Declarative Pipelines для непрерывного обновления как синхронизированной таблицы Unity Catalog, так и таблицы Postgres с изменениями из исходной таблицы. Каждая синхронизация может использовать до 16 подключений к базе данных Lakebase.
Lakebase Postgres поддерживает до 1000 одновременных подключений с гарантиями транзакций, чтобы приложения могли считывать обогащенные данные, а также обрабатывать вставки, обновления и удаления в той же базе данных.
Режимы синхронизации
Выберите правильный режим синхронизации в зависимости от потребностей приложения:
| Режим | Описание | Когда использовать | Производительность |
|---|---|---|---|
| Моментальный снимок | Однократная копия всех данных | Изменения в источнике >10% строк за цикл или источник не поддерживает CDF (представления, таблицы Iceberg) | 10x более эффективно при изменении >10% исходных данных |
| Запущено | Запланированные обновления, которые выполняются по требованию или через интервалы | Исходные строки изменяются по известному графику. Вставки, обновления и удаления распространяются каждый раз при обновлении. | Хороший баланс затрат и задержки. Дорого, если запускать с интервалами в <5 минут |
| Непрерывный | Потоковая передача в режиме реального времени с задержкой в секундах | Изменения должны отображаться в Lakebase практически в режиме реального времени | Низкая задержка, самая высокая стоимость. Минимальные 15-секундные интервалы |
Триггерный и непрерывный режимы требуют включения канала данных изменений (CDF) в вашей исходной таблице. Если CDF не включен, вы увидите предупреждение в пользовательском интерфейсе с точной ALTER TABLE командой для выполнения. Дополнительные подробности о канале данных об изменениях см. в разделе "Использование канала данных об изменениях Delta Lake на Databricks".
Замечание
Источники, которые не поддерживают CDF (например, представления, материализованные представления и таблицы Iceberg), можно синхронизировать только в режиме моментального снимка . Для режима Snapshot источник должен поддерживать SELECT *.
Примеры вариантов использования
Синхронизированные таблицы можно использовать для таких вариантов использования, как:
- Подсистемы персонализации, которые служат новым профилям пользователей в приложениях Databricks
- Приложения, обслуживающие прогнозы модели или значения признаков, вычисляемые в lakehouse
- Панели мониторинга, обслуживающие ключевые показатели эффективности в режиме реального времени
- Службы обнаружения мошенничества, которые предоставляют оценки рисков для принятия немедленных мер
- Средства поддержки, которые служат обогащенным записям клиентов из данных Lakehouse
Создание синхронизированной таблицы
Необходимые условия
Тебе нужно:
- Рабочая область Databricks с активированной функцией Lakebase.
- Проект Lakebase (см. раздел "Создание проекта").
- Таблица каталога Unity для синхронизации.
- Разрешения на создание синхронизированных таблиц. Вам потребуется USE_SCHEMA и CREATE_TABLE для любой используемой схемы.
Для режимов триггерного или непрерывного типа транслирование изменений данных должно быть включено в исходной таблице.
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Сведения о планировании емкости и совместимости типов данных см. в разделе "Типы данных" и "Планирование емкости".
Пользовательский интерфейс
Перейдите в каталог на боковой панели рабочей области и выберите таблицу каталога Unity, которую вы хотите синхронизировать.
Щелкните "Создать>синхронизированную таблицу " в представлении сведений о таблице.
В диалоговом окне создания синхронизированной таблицы :
Списки каталогов и схем включают только схемы каталога Unity, в которых текущий пользователь имеет USE_SCHEMAи CREATE_TABLE привилегии. Если вы не видите схему, которую вы ожидаете, подтвердите разрешения с помощью администратора каталога.
Имя таблицы: введите имя синхронизированной таблицы (она создается в том же каталоге и схеме, что и исходная таблица). При этом создается синхронизированная таблица каталога Unity и таблица Postgres, которые можно запрашивать.
Тип базы данных: выберите Lakebase Serverless (автомасштабирование).
Режим синхронизации: выберите моментальный снимок, триггер или непрерывный в зависимости от ваших потребностей (см. режимы синхронизации выше).
Настройте выбор проекта, ветви и базы данных.
Проверьте правильность первичного ключа (обычно автоматическое обнаружение).
Это важно
Столбцы в первичном ключе не могут принимать значение NULL в синхронизированной таблице. Строки со значениями NULL в столбцах первичного ключа исключаются из синхронизации.
(Необязательно) Если две строки в исходной таблице могут иметь один и тот же первичный ключ, выберите ключ временных рядов, чтобы настроить дедупликацию. При указании ключа таймерии синхронизированная таблица содержит только строку с последним значением ключа таймерии для каждого первичного ключа. Режим сбоя без ключа таймерии см. в разделе "Повторяющиеся ключи".
Если вы выбрали триггерный или непрерывный режим и еще не включили канал изменений данных, вы увидите предупреждение с точной командой для запуска. Вопросы о совместимости типов данных см. в разделе "Типы данных" и "Совместимость".
Нажмите кнопку "Создать", чтобы создать синхронизированную таблицу.
Отслеживайте синхронизированную таблицу в каталоге. На вкладке "Обзор" отображается состояние синхронизации, конфигурация, состояние конвейера и метка времени последней синхронизации. Теперь используйте синхронизацию для обновления вручную.
пакет SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
SyncedTable,
SyncedTableSyncedTableSpec,
SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy,
)
w = WorkspaceClient()
synced_table = w.postgres.create_synced_table(
synced_table=SyncedTable(spec=SyncedTableSyncedTableSpec(
source_table_full_name="main.sales.orders",
branch="projects/my-project/branches/production",
primary_key_columns=["order_id"],
scheduling_policy=SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.SNAPSHOT,
postgres_database="mydb",
create_database_objects_if_missing=True,
)),
synced_table_id="my-catalog.sales.orders",
).wait()
print(f"Synced table created: {synced_table.name}")
Объект synced_table_id использует формат catalog.schema.table и становится именем синхронизированной таблицы в Unity Catalog. В Postgres таблица {table} создается в схеме {schema}, в базе данных, которую вы задаете с помощью postgres_database (здесь, mydb).
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import java.util.List;
WorkspaceClient w = new WorkspaceClient();
SyncedTable syncedTable = w.postgres().createSyncedTable(
new CreateSyncedTableRequest()
.setSyncedTableId("my-catalog.sales.orders")
.setSyncedTable(new SyncedTable()
.setSpec(new SyncedTableSyncedTableSpec()
.setSourceTableFullName("main.sales.orders")
.setBranch("projects/my-project/branches/production")
.setPrimaryKeyColumns(List.of("order_id"))
.setSchedulingPolicy(SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.SNAPSHOT)
.setPostgresDatabase("mydb")
.setCreateDatabaseObjectsIfMissing(true))))
.waitForCompletion();
System.out.println("Synced table created: " + syncedTable.getName());
завиток
curl -X POST "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables?synced_table_id=my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"source_table_full_name": "main.sales.orders",
"branch": "projects/my-project/branches/production",
"primary_key_columns": ["order_id"],
"scheduling_policy": "SNAPSHOT",
"postgres_database": "mydb",
"create_database_objects_if_missing": true
}
}'
Это возвращает длительную операцию. Проверяйте возвращаемое name поле до done: true. См. долговременные операции. Сведения о настройке проверки подлинности см. в разделе "Проверка подлинности".
Планирование или активация последующих синхронизаций
При создании начальный снимок выполняется автоматически. Для режимов моментального снимка и триггеров последующие синхронизации должны запускаться явным образом. Непрерывный режим самоуправляющийся.
Задача конвейера синхронизации таблиц базы данных
Задача конвейера синхронизации таблиц базы данных в заданиях Lakeflow выполняет конвейер синхронизированной таблицы в качестве шага рабочего процесса. Настройте задание с помощью триггера обновления таблицы или расписания.
Триггер обновлений исходной таблицы
Запускает задание при обновлении исходной таблицы каталога Unity. В триггерном режиме новые изменения применяются инкрементально, обеспечивая свежесть данных почти в реальном времени и без постоянных затрат, присущих непрерывному режиму.
- На боковой панели щелкните "Рабочие процессы".
- Нажмите кнопку "Создать задание " или откройте существующее задание.
- На вкладке "Задачи " нажмите кнопку +Добавить другой тип задачи.
- В разделе "Прием и преобразование" выберите конвейер синхронизации таблиц базы данных.
- В поле конвейера выберите конвейер, связанный с синхронизированной таблицей.
- В разделе "Расписания и триггеры" нажмите кнопку "Добавить триггер".
- Выберите "Обновление таблицы " в качестве типа триггера.
- В разделе "Таблицы" выберите исходную таблицу каталога Unity для мониторинга.
- Нажмите кнопку Сохранить.
Триггер, действующий по расписанию
Выполняет синхронизацию с фиксированной частотой. Хорошо подходит для режима моментального снимка, где ежедневное или еженедельное полное обновление обычно является наиболее эффективным способом.
- Выполните действия 1–5 выше, чтобы добавить задачу конвейера синхронизации таблиц базы данных в задание.
- В разделе "Расписания и триггеры" нажмите кнопку "Добавить триггер".
- Выберите "Запланированный " в качестве типа триггера.
- Задайте расписание и часовой пояс cron, а затем нажмите кнопку "Сохранить".
Проверка состояния синхронизации
Чтобы проверить текущее состояние и время последней синхронизации синхронизированной таблицы:
Пользовательский интерфейс
В каталоге перейдите к синхронизированной таблице и перейдите на вкладку "Обзор ". В нем отображается текущее состояние синхронизации, состояние конвейера и метка времени последней синхронизации.
пакет SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
table = w.postgres.get_synced_table("synced_tables/my-catalog.sales.orders")
print(f"State: {table.status.detailed_state}")
print(f"Last sync: {table.status.last_sync_time}")
print(f"Message: {table.status.message}")
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.SyncedTable;
WorkspaceClient w = new WorkspaceClient();
SyncedTable table = w.postgres().getSyncedTable("synced_tables/my-catalog.sales.orders");
System.out.println("State: " + table.getStatus().getDetailedState());
System.out.println("Last sync: " + table.getStatus().getLastSyncTime());
System.out.println("Message: " + table.getStatus().getMessage());
завиток
curl "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
Типы данных и совместимость
Типы данных каталога Unity сопоставляются с типами Postgres при создании синхронизированных таблиц. Сложные типы (ARRAY, MAP, STRUCT) хранятся в формате JSONB в Postgres.
| Тип исходного столбца | Тип столбца Postgres |
|---|---|
| БИГИНТ | БИГИНТ |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | ЧИСЛОВОЙ |
| ДВОЙНОЙ | ДВОЙНАЯ ТОЧНОСТЬ |
| FLOAT | РЕАЛЬНЫЙ |
| INT | ЦЕЛОЕ ЧИСЛО |
| INTERVAL | INTERVAL |
| СМОЛЛИНТ | СМОЛЛИНТ |
| СТРУНА | ТЕКСТ |
| TIMESTAMP | Метка времени с часовым поясом |
| TIMESTAMP_NTZ | МЕТКА ВРЕМЕНИ БЕЗ ЧАСОВОГО ПОЯСА |
| TINYINT | СМОЛЛИНТ |
| ARRAY<типЭлемента |
JSONB |
| MAP<тип_ключа,тип_значения> | JSONB |
| Имя поля STRUCT<:fieldType[, ...]> | JSONB |
Замечание
Типы GEOGRAPHY, GEOMETRY, VARIANT и OBJECT не поддерживаются.
Обработка недопустимых символов
Некоторые символы, такие как нулевые байты (0x00), разрешены в столбцах каталога Unity STRING, ARRAY, MAP или STRUCT, но не поддерживаются в столбцах Postgres TEXT или JSONB. Это может привести к сбоям синхронизации с такими ошибками:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
- Первая ошибка возникает, когда байт null отображается в строковом столбце верхнего уровня, который сопоставляется непосредственно с Postgres
TEXT. - Вторая ошибка возникает, когда байт null отображается в строке, вложенной внутри сложного типа (
STRUCTилиARRAYMAP), который сериализуется какJSONB. Во время сериализации все строки привязываются к PostgresTEXT, где\u0000запрещено.
Решения:
Очистка строковых полей: удалите неподдерживаемые символы перед синхронизацией. Для нулевых байтов (NULL) в столбцах STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableПреобразование в BINARY: для столбцов STRING, в которых необходимо сохранить необработанные байты, преобразуйте в тип BINARY.
Планирование емкости
При планировании реализации синхронизированных таблиц рассмотрите следующие требования к ресурсам:
- Использование подключений: Каждая синхронизированная таблица использует до 16 подключений к базе данных Lakebase, что засчитывается в совокупный лимит подключения экземпляра.
- Ограничения размера: общий объем логических данных во всех синхронизированных таблицах составляет 8 ТБ. Отдельные таблицы не имеют ограничений, но Databricks рекомендует не превышать 1 ТБ для таблиц, требующих обновлений.
- Размер полного обновления: при активации полного обновления старая версия в Postgres не удаляется до завершения новой синхронизации. Обе версии временно засчитываются в счет лимита размера логической базы данных во время обновления.
- Таблиц на источник: для одной исходной таблицы можно синхронизировать до 20 таблиц.
-
Требования к именованию: имена баз данных, схем и таблиц могут содержать только буквенно-цифровые символы и символы подчеркивания (
[A-Za-z0-9_]+). - Руководство по идентификатору источника. Избегайте использования прописных букв или специальных символов в именах столбцов или таблиц в исходной таблице каталога Unity. Если вы их оставите, то при обращении к ним в Postgres необходимо заключать эти идентификаторы в кавычки.
- Эволюция схемы. Для триггерных и непрерывных режимов поддерживаются только изменения аддитивной схемы (например, добавление столбцов).
- Повторяющиеся ключи: если две строки имеют один и тот же первичный ключ в исходной таблице, конвейер синхронизации завершается ошибкой, если не настроить дедупликацию с помощью ключа таймерии.
- Идемпотентность API: API синхронизированных таблиц являются идемпотентными, поэтому повторите попытку при временных ошибках, чтобы обеспечить своевременные операции.
- Частота обновления: для автомасштабирования Lakebase конвейер синхронизации поддерживает непрерывную запись и запись по триггеру со скоростью примерно 150 строк в секунду на единицу мощности (CU), а запись снимков — до 2 000 строк в секунду на CU.
Операции, разрешенные для синхронизированных таблиц в Postgres
Azure Databricks рекомендует выполнять только следующие операции в Postgres для синхронизированных таблиц, чтобы предотвратить случайные перезаписи или несоответствия данных:
- Запросы только для чтения
- Создание индексов
- Удаление таблицы (чтобы освободить место после удаления синхронизированной таблицы из каталога Unity)
Хотя можно изменить синхронизированные таблицы в Postgres другими способами, он вмешивается в конвейер синхронизации.
Владение и разрешения
Если вы создаете новую базу данных Postgres, схему или таблицу, свойство Postgres устанавливается следующим образом:
- Право владения назначается пользователю, создающему базу данных, схему или таблицу, если их имя входа в Azure Databricks существует в качестве ролью в Postgres. Чтобы добавить в Postgres роль удостоверения Azure Databricks, см. раздел Роли Postgres.
- В противном случае владение назначается владельцу родительского объекта в Postgres (обычно
databricks_superuser).
Управление доступом к синхронизированной таблице
После создания синхронизированной таблицы databricks_superuser может читать синхронизированную таблицу из Postgres. Этот databricks_superuserpg_read_all_dataпараметр позволяет считывать эту роль из всех таблиц. Он также имеет привилегию pg_write_all_data , которая позволяет этой роли записывать все таблицы. Это означает, что databricks_superuser можно также записывать в синхронизированную таблицу в Postgres. Lakebase поддерживает это поведение записи в случае, если необходимо внести срочные изменения в целевую таблицу. Однако Azure Databricks рекомендует вносить исправления в исходную таблицу.
Кроме того,
databricks_superuserэти привилегии можно предоставить другим пользователям:GRANT USAGE ON SCHEMA synced_table_schema TO user;GRANT SELECT ON synced_table_name TO user;databricks_superuserможет отозвать эти привилегии:REVOKE USAGE ON SCHEMA synced_table_schema FROM user;REVOKE {SELECT | INSERT | UPDATE | DELETE} ON synced_table_name FROM user;
Управление синхронизированными операциями таблицы
databricks_superuser может управлять тем, какие пользователи уполномочены выполнять конкретные операции в синхронизированной таблице. Поддерживаемые операции для синхронизированных таблиц:
CREATE INDEXALTER INDEXDROP INDEXDROP TABLE
Все остальные операции DDL запрещены для синхронизированных таблиц.
Чтобы предоставить этим привилегиям дополнительным пользователям, databricks_superuser сначала необходимо создать расширение в databricks_auth:
CREATE EXTENSION IF NOT EXISTS databricks_auth;
databricks_superuser Затем пользователь может добавить пользователя для управления синхронизированной таблицей:
SELECT databricks_synced_table_add_manager('"synced_table_schema"."synced_table"'::regclass, '[user]');
databricks_superuser может удалить пользователя из управления синхронизированной таблицей.
SELECT databricks_synced_table_remove_manager('[table]', '[user]');
databricks_superuser может просматривать всех руководителей:
SELECT * FROM databricks_synced_table_managers;
Удаление синхронизированной таблицы
При удалении синхронизированной таблицы из каталога Unity также удаляется соответствующая таблица Postgres.
Пользовательский интерфейс
В каталоге найдите синхронизированную таблицу, щелкните ![]() Меню и нажмите кнопку "Удалить".
Меню и нажмите кнопку "Удалить".
пакет SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.postgres.delete_synced_table("synced_tables/my-catalog.sales.orders").wait()
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteSyncedTable("synced_tables/my-catalog.sales.orders").waitForCompletion();
завиток
curl -X DELETE "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
Узнать больше
| задачи | Описание |
|---|---|
| Создание проекта | Настройка проекта Lakebase |
| Подключение к базе данных | Сведения о параметрах подключения для Lakebase |
| Регистрация базы данных в каталоге Unity | Сделать данные Lakebase видимыми в каталоге Unity для унифицированного управления и кросс-исходных запросов |
| Интеграция каталога Unity | Общие сведения об управлении и разрешениях |
Интеграция с каталогом
- Дублирование каталога: Создание синхронизированной таблицы в стандартном каталоге, предназначенной для базы данных Postgres, которая также зарегистрирована в качестве отдельного каталога базы данных, приводит к тому, что синхронизированная таблица будет отображаться в каталоге Unity как в стандартном, так и в каталогах баз данных.
Другие варианты
Сведения о решениях Partner Connect по обратному ETL для синхронизации данных с системами, отличными от Databricks, см. таких, как Census или Hightouch.