Extract, transform, and load (ETL) at scale (Извлечение, преобразование и загрузка (ETL) в масштабе)
Процесс извлечения, преобразования и загрузки используется для получения данных из разных источников. Он позволяет собрать данные в стандартном расположении, очистить их и обработать. В результате готовые данные помещаются в хранилище данных и становятся пригодны для выполнения запросов по ним. Прежние ETL-процессы дают возможность импортировать данные, очищать их на месте, а затем сохранять в реляционный обработчик данных. Широкий набор компонентов среды Apache Hadoop для Azure HDInsight поддерживает выполнение извлечения, преобразования и загрузки в большом масштабе.
Использование HDInsight в процессах ETL можно кратко описать таким конвейером:
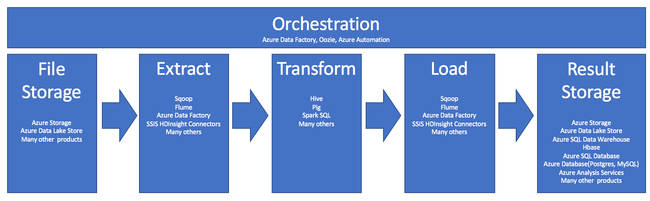
В разделах ниже рассматриваются все этапы ETL и их связанные компоненты.
Оркестрация
Оркестрация охватывает все этапы конвейера ETL. Задания ETL в HDInsight часто включают в себя несколько совместно функционирующих различных продуктов. Например:
- Так, можно применить Apache Hive, чтобы очистить одну часть данных, и Apache Pig для очистки другой части.
- Фабрику данных Azure можно использовать для загрузки данных в базу данных SQL Azure из Azure Data Lake Store.
Оркестрация необходима для запуска соответствующего задания в соответствующее время.
Apache Oozie
Apache Oozie — это система координации рабочих процессов, которая управляет заданиями Hadoop. Oozie работает в кластере HDInsight и интегрирована со стеком Hadoop. Oozie поддерживает задания Apache Hadoop MapReduce, Pig, Hive и Sqoop. Вы можете использовать Oozie для планирования заданий для конкретной системы, например программ Java или сценариев оболочки.
Дополнительные сведения см. в статье Использование Apache Oozie с Apache Hadoop для определения и запуска рабочих процессов в HDInsight под управлением Linux. Также изучите статью Ввод в эксплуатацию конвейера аналитики данных.
Azure Data Factory
Фабрика данных Azure предоставляет возможности оркестрации в формате PaaS (платформа как услуга). Фабрика данных Azure — это облачная служба интеграции данных. Она позволяет создавать управляемые данными рабочие процессы для оркестрации и автоматизации перемещения и преобразования данных.
Применение Фабрики данных Azure:
- Создание и планирование рабочих процессов на основе данных. Эти конвейеры могут принимать данные из разрозненных хранилищ данных.
- Обработка и преобразование данных с помощью вычислительных служб, как например HDInsight и Hadoop. Для этого шага можно также использовать Spark, Azure Data Lake Analytics, пакетную службу Azure или Машинное обучение Azure.
- Публикация выходных данных в хранилища данных (например, Azure Synapse Analytics) для использования приложениями бизнес-аналитики.
Дополнительные сведения о фабрике данных Azure см. в этой статье.
Хранилище файлов приема и хранилище результатов
Исходные файлы данных обычно загружаются в расположение в службе хранилища Azure или Azure Data Lake Storage. Обычно это файлы в неструктурированном формате, например CSV. Но они могут быть в любом формате.
Хранилище Azure
Служба хранилища Azure имеет определенные целевые показатели адаптируемости. Дополнительные сведения см. в статье Целевые показатели масштабируемости и производительности для хранилища BLOB-объектов. Для большинства аналитических узлов эта служба лучше всего масштабируется при использовании множества небольших файлов. Служба хранилища Azure гарантирует одинаковую производительность независимо от количества файлов и их размера, пока соблюдаются ограничения для учетной записи. Вы можете хранить терабайты данных и получать все ту же стабильную производительность. Это справедливо как при работе с некоторым подмножеством, так и для всего объема данных.
Служба хранилища Azure использует несколько типов больших двоичных объектов. Добавочный большой двоичный объект — оптимальный вариант для хранения веб-журналов или данных датчиков.
Несколько больших двоичных объектов можно распределить по множеству серверов, чтобы обеспечить горизонтальное масштабирование доступа к ним. Но каждый большой двоичный объект обслуживается только одним сервером. Большие двоичные объекты могут быть логически сгруппированы в контейнеры, но такая группировка никак не влияет на их распределение по разделам.
Служба хранилища Azure также включает слой API WebHDFS для хранения больших двоичных объектов. Все службы HDInsight могут обращаться к файлам в хранилище BLOB-объектов Azure для очистки и обработки данных. Это похоже на то, как эти службы используют распределенную файловую систему Hadoop (HDFS).
Как правило, данные поступают в службу хранилища Azure через PowerShell, пакет SDK службы хранилища Azure или AzCopy.
Azure Data Lake Storage
Azure Data Lake Storage — это управляемый и гипермасштабируемый репозиторий для данных аналитики. Он совместим с HDFS и использует сходную концепцию архитектуры. Data Lake Storage предоставляет неограниченную адаптируемость емкости и поддержку любого размера отдельных файлов. Это хороший выбор для работы с большими файлами, так как это хранилище позволяет сохранить такие файлы на нескольких узлах. Секционирование данных в Data Lake Storage выполняется в фоновом режиме. Это хранилище обеспечивает колоссальную пропускную способность: более тысячи исполнителей могут одновременно запускать аналитические задания, которые эффективно считывают и записывают тысячи терабайтов данных.
Данные обычно передаются в Data Lake Storage через Фабрику данных Azure. Вы также можете использовать пакеты SDK для Data Lake Storage, службу AdlCopy, Apache DistCp или Apache Sqoop. Выбор службы зависит от того, где находятся данные. Если это существующий кластер Hadoop, можно использовать Apache DistCp, службу AdlCopy или Фабрику данных Azure. Для данных в хранилище больших двоичных объектов Azure можно применить пакет средств разработки .NET для Azure Data Lake Storage, Azure PowerShell или Фабрику данных Azure.
Data Lake служба хранилища оптимизирован для приема событий с помощью Центры событий Azure.
Рекомендации для двух вариантов хранения
Для отправки наборов данных, размер которых измеряется терабайтами, задержки сети могут стать серьезной проблемой. Это особенно важно, если данные поступают из локальной среды. В таких ситуациях будут уместны следующие варианты.
Azure ExpressRoute: создание частных подключений между центрами обработки данных Azure и локальной инфраструктурой. Такое подключение обеспечивает надежный вариант передачи больших объемов данных. Дополнительные сведения см. в техническом обзоре ExpressRoute.
Передача данных с жестких дисков: вы можете использовать службу Azure импорт и экспорт для отправки жестких дисков с данными в центр обработки данных Azure. Данные сначала будут отправлены в хранилище BLOB-объектов Azure. Затем с помощью Фабрики данных Azure или инструмента AdlCopy их можно скопировать из хранилища BLOB-объектов Azure в Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analytics будет хорошим выбором для хранения подготовленных результатов. Можете использовать Azure HDInsight для выполнения этих служб Azure Synapse Analytics.
Azure Synapse Analytics представляет собой хранилище реляционной базы данных, оптимизированное для аналитических рабочих нагрузок. Масштабирование этого хранилища выполняется на основе секционированных таблиц. Таблицы можно секционировать на нескольких узлах. Узлы выбираются во время создания. Затем их можно масштабировать, но для такого активного процесса может потребоваться перемещение данных. Дополнительные сведения см. в разделе Управление вычислительными ресурсами в Azure Synapse Analytics.
Apache HBase
Apache HBase представляет собой хранилище данных типа "ключ — значение", доступное в Azure HDInsight. Это база данных NoSQL с открытым кодом, созданная на основе Hadoop по типу Google BigTable. HBase обеспечивает производительный быстрый доступ и строгую согласованность для больших объемов неструктурированных и полуструктурированных данных.
Поскольку HBase является бессхемной базой данных, вам не придется определять столбцы и типы данных для ее использования. Данные хранятся в строках таблицы и группируются по семействам столбцов.
Открытый код линейно масштабируется, чтобы обрабатывать петабайты данных на тысячах узлов. HBase полагается на избыточность данных, пакетную обработку и другие возможности, предоставляемые распределенными приложениями в среде Hadoop.
Это хорошее место назначения для данных датчиков и журналов, которые потребуются для анализа.
Адаптируемость HBase определяется количеством узлов в кластере HDInsight.
Базы данных SQL Azure
В Azure предлагаются три реляционных базы данных в формате PaaS:
- База данных SQL Azure представляет собой реализацию Microsoft SQL Server. Дополнительные сведения о производительности см. в статье Настройка производительности в Базе данных SQL Azure.
- База данных Azure для MySQL представляет собой реализацию Oracle MySQL.
- База данных Azure для PostgreSQL представляет собой реализацию PostgreSQL.
Добавьте больше ресурсов ЦП и памяти, чтобы увеличить масштаб этих продуктов. Для них также можно использовать диски категории "Премиум", чтобы повысить производительность ввода-вывода.
Azure Analysis Services
Azure Analysis Services — это подсистема аналитических данных, которая используется для поддержки принятия решений и бизнес-аналитики. Она предоставляет аналитические данные для бизнес-отчетов и клиентских приложений, таких как Power BI. Аналитические данные также используются с Excel, отчетами SQL Server Reporting Services и другими средствами визуализации данных.
Масштабируйте кубы анализа, изменяя уровни для каждого отдельного куба. Дополнительные сведения см. на странице цен на службы Azure Analysis Services.
Извлечение и загрузка
Поместив данные в Azure, вы сможете использовать несколько служб для их извлечения и загрузки в другие продукты. HDInsight поддерживает средства Sqoop и Flume.
Apache Sqoop
Apache Sqoop — это средство для эффективной передачи данных между структурированными, полуструктурированными и неструктурированными источниками данных.
Sqoop использует MapReduce для импорта и экспорта данных, чтобы обеспечить параллельное выполнение операций и отказоустойчивость.
Apache Flume
Apache Flume — это распределенная, надежная и доступная служба для эффективного сбора, статистической обработки и перемещения больших объемов данных журнала. Ее гибкая архитектура основана на передаче потоков данных. Это надежная отказоустойчивая служба с настраиваемыми механизмами для обеспечения надежности. Она имеет много возможностей для отработки отказа и восстановления. Flume использует простую модель данных с возможностью расширения, позволяющую применять интерактивное приложение аналитики.
Apache Flume нельзя использовать с Azure HDInsight. Но в локальной версии Hadoop может применять Flume для отправки данных в хранилище BLOB-объектов Azure или Azure Data Lake Storage. Дополнительные сведения см. в записи блога об использовании Apache Flume с HDInsight.
Преобразование
Поместив данные в выбранное расположение, вы должны их очистить, объединить или подготовить для определенного шаблона использования. Hive, Pig и Spark SQL — оптимальные варианты для такой работы. В HDInsight они все поддерживаются.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по