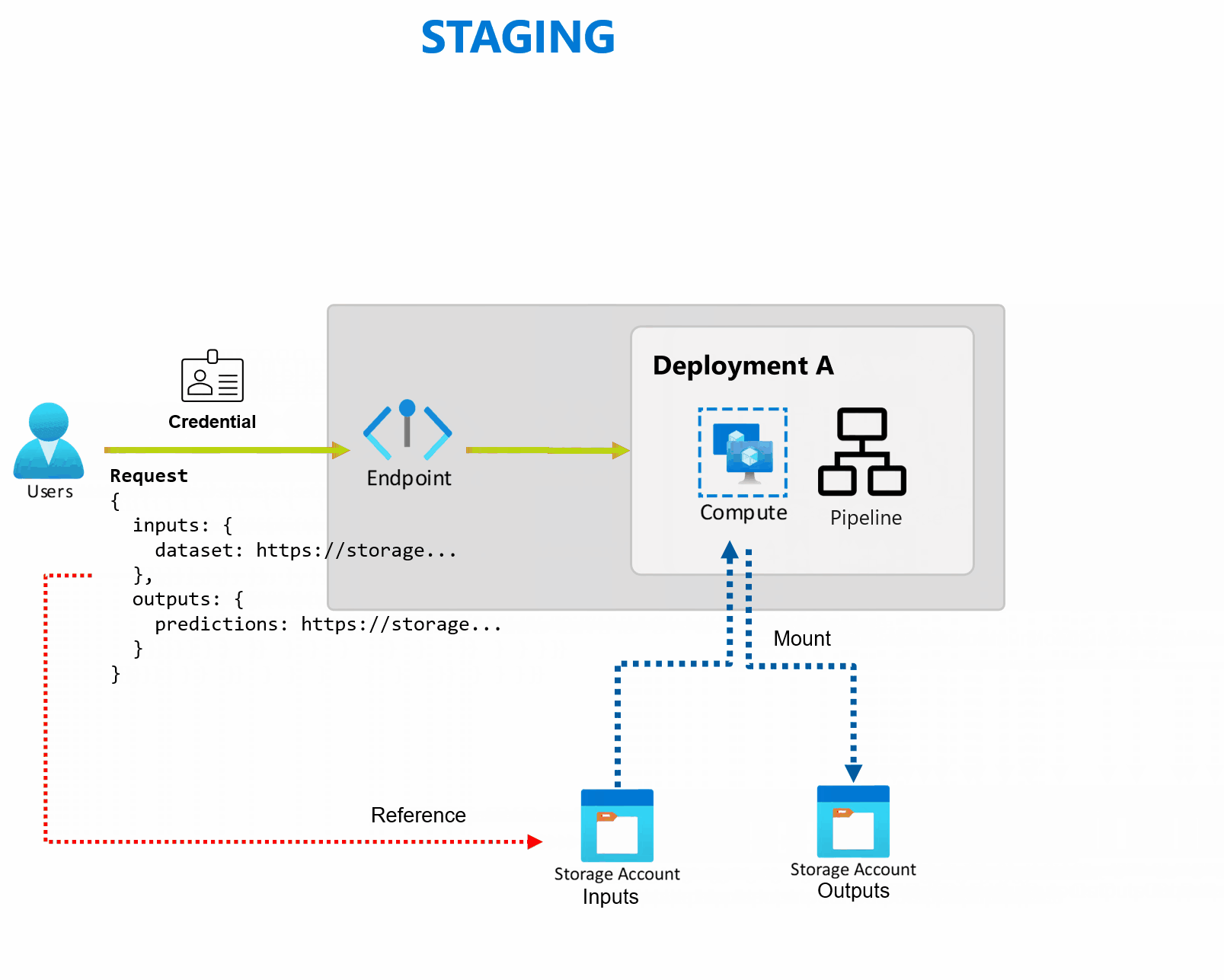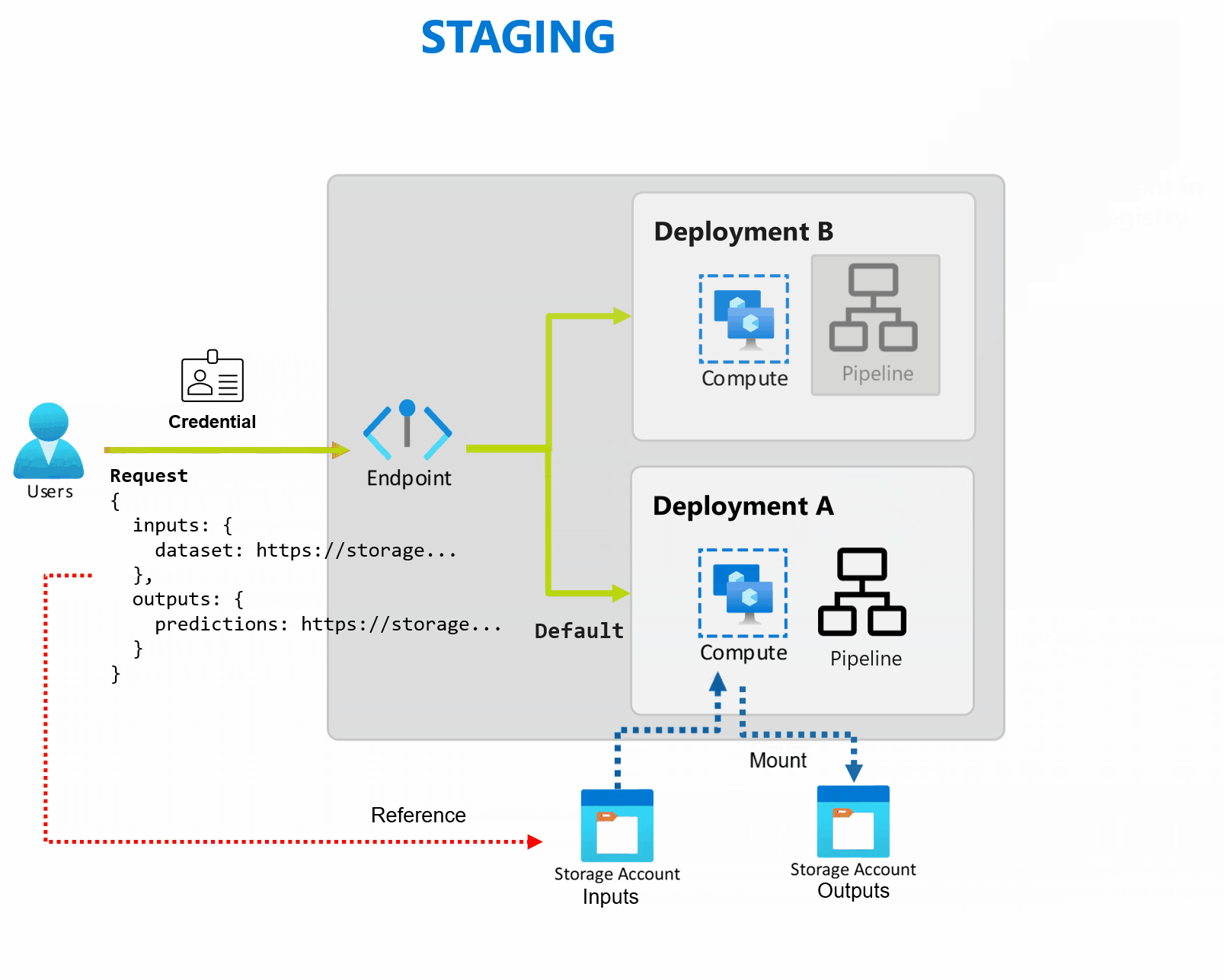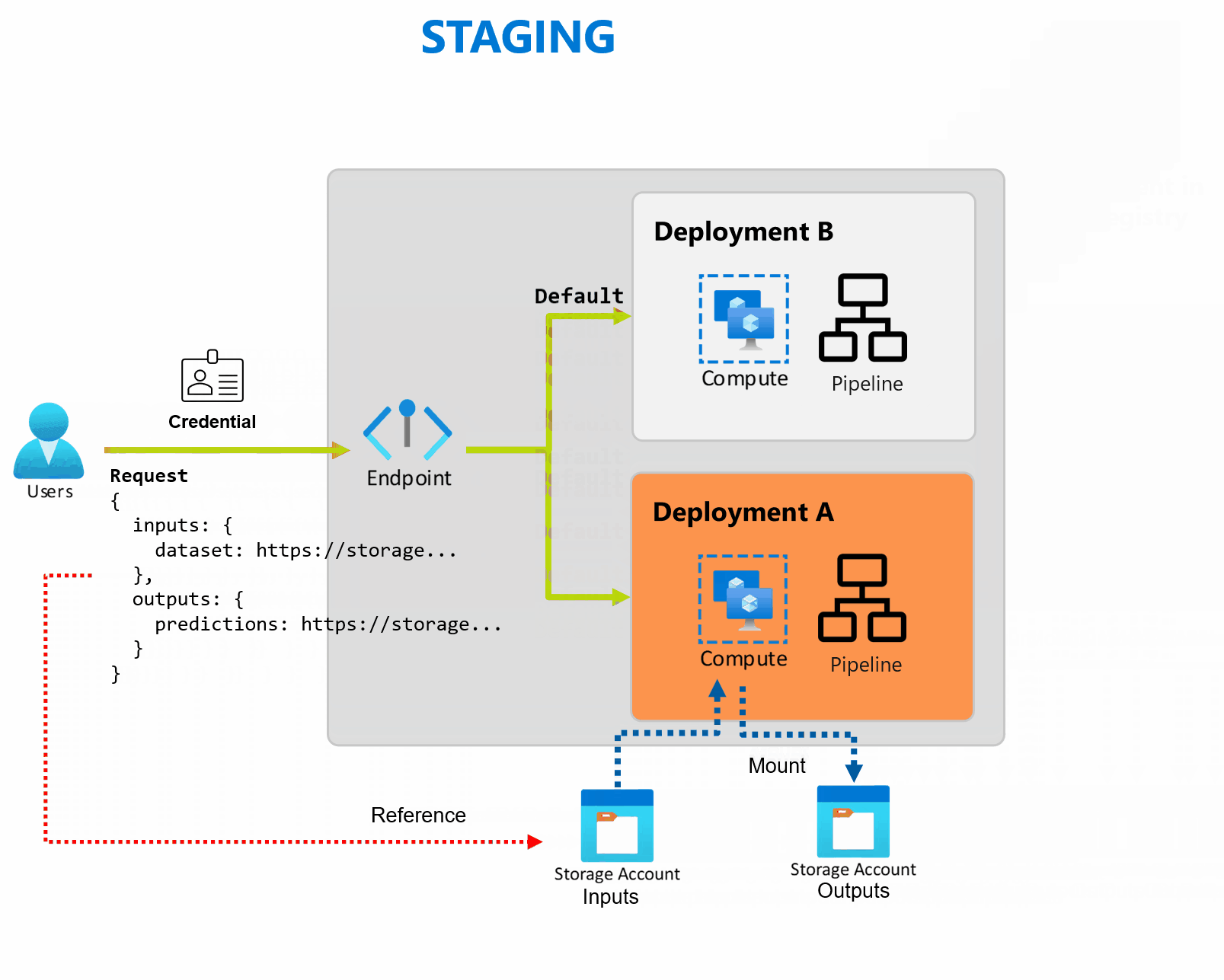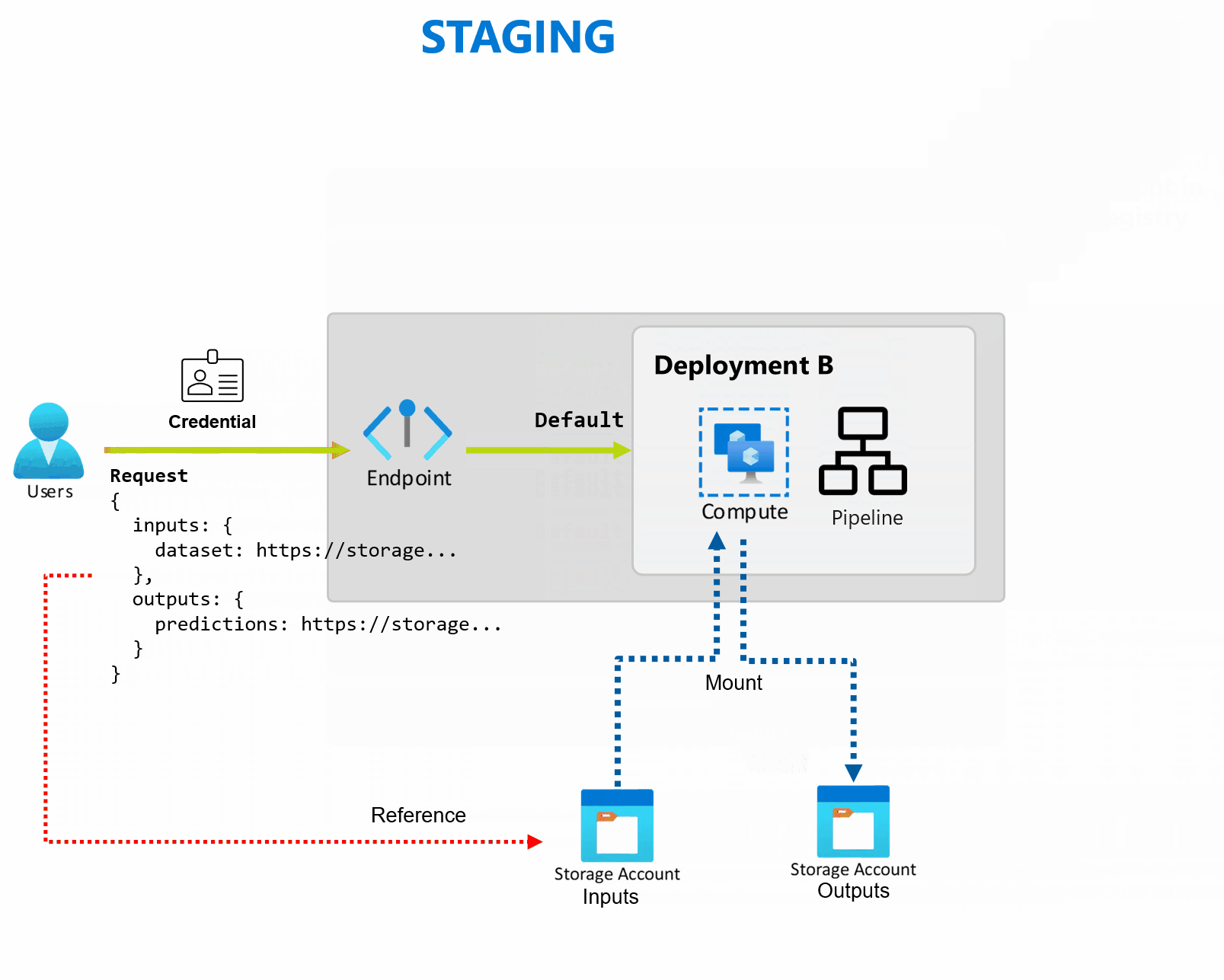
Пакетные конечные точки
Машинное обучение Azure позволяет реализовать конечные точки и развертывания пакетной службы для выполнения длительных асинхронных выводов с помощью моделей машинного обучения и конвейеров. При обучении модели машинного обучения или конвейера необходимо развернуть ее, чтобы другие могли использовать ее с новыми входными данными для создания прогнозов. Этот процесс создания прогнозов с помощью модели или конвейера называется выводом.
Пакетные конечные точки получают указатели на данные и запускают задания асинхронно для параллельной обработки данных в кластерах вычислений. Пакетные конечные точки сохраняют выходные данные в хранилище данных для дальнейшего анализа. Используйте пакетные конечные точки, когда:
- У вас есть дорогие модели или конвейеры, требующие длительного времени выполнения.
- Вы хотите использовать конвейеры машинного обучения и повторно использовать компоненты.
- Необходимо выполнить вывод над большими объемами данных, распределенными в нескольких файлах.
- У вас нет требований к низкой задержке.
- Входные данные модели хранятся в учетной записи служба хранилища или в ресурсе данных машинного обучения Azure.
- Вы можете воспользоваться преимуществами параллелизации.
Пакетные развертывания
Развертывание — это набор ресурсов и вычислений, необходимых для реализации функциональных возможностей, которые предоставляет конечная точка. Каждая конечная точка может размещать несколько развертываний с различными конфигурациями, и эта функция помогает отделить интерфейс конечной точки от сведений о реализации, определенных развертыванием. При вызове конечной точки пакетной службы он автоматически направляет клиент к развертыванию по умолчанию. Это развертывание по умолчанию можно настроить и изменить в любое время.

Два типа развертываний можно использовать в Машинное обучение Azure конечных точках пакетной службы:
Развертывание модели
Развертывание модели позволяет выполнять операции вывода модели в масштабе, что позволяет обрабатывать большие объемы данных в низкой задержке и асинхронном способе. Машинное обучение Azure автоматически инструментирует масштабируемость путем параллелизации процессов вывода между несколькими узлами в вычислительном кластере.
Используйте развертывание модели, когда:
- У вас есть дорогие модели, требующие длительного времени для вывода.
- Необходимо выполнить вывод над большими объемами данных, распределенными в нескольких файлах.
- У вас нет требований к низкой задержке.
- Вы можете воспользоваться преимуществами параллелизации.
Основное преимущество развертываний моделей заключается в том, что вы можете использовать те же ресурсы, которые развертываются для вывода в режиме реального времени в сетевых конечных точках, но теперь их можно запустить в большом масштабе в пакетном режиме. Если для модели требуется простая предварительная обработка или после обработки, можно создать скрипт оценки, выполняющий необходимые преобразования данных.
Чтобы создать развертывание модели в пакетной конечной точке, необходимо указать следующие элементы:
- Модель
- Вычислительный кластер
- Скрипт оценки (необязательно для моделей MLflow)
- Среда (необязательно для моделей MLflow)
Развертывание компонента конвейера
Развертывание компонента конвейера позволяет выполнять операции всех графов обработки (или конвейеров) для выполнения пакетного вывода с низкой задержкой и асинхронным способом.
Используйте развертывание компонента конвейера, если:
- Необходимо выполнить эксплуатацию полных графов вычислений, которые можно разложить на несколько шагов.
- Необходимо повторно использовать компоненты из конвейеров обучения в конвейере вывода.
- У вас нет требований к низкой задержке.
Основным преимуществом развертываний компонентов конвейера является повторное использование компонентов, которые уже существуют в вашей платформе, и возможность операционизировать сложные подпрограммы вывода.
Чтобы создать развертывание компонента конвейера в конечной точке пакетной службы, необходимо указать следующие элементы:
- Компонент конвейера
- Конфигурация вычислительного кластера
Конечные точки пакетной службы также позволяют создавать развертывания компонентов конвейера из существующего задания конвейера. При этом Машинное обучение Azure автоматически создает компонент конвейера из задания. Это упрощает использование таких развертываний. Однако рекомендуется всегда создавать компоненты конвейера явным образом, чтобы упростить практику MLOps.
Управление затратами
При вызове пакетной конечной точки запускается асинхронное пакетное задание вывода. Машинное обучение Azure автоматически подготавливает вычислительные ресурсы при запуске задания и автоматически освобождает их по завершении задания. Таким образом, вы оплачиваете только вычислительные ресурсы при его использовании.
Совет
При развертывании моделей можно переопределить параметры вычислительных ресурсов (например, количество экземпляров) и дополнительные параметры (например, мини-пакетный размер, порог ошибок и т. д.) для каждого отдельного задания вывода пакета. Используя эти конкретные конфигурации, вы можете ускорить выполнение и сократить затраты.
Конечные точки пакетной службы также могут выполняться на виртуальных машинах с низким приоритетом. Конечные точки пакетной службы могут автоматически восстановиться с освобожденных виртуальных машин и возобновить работу, из которой она была оставлена при развертывании моделей вывода. Дополнительные сведения о том, как использовать виртуальные машины с низким приоритетом для уменьшения затрат на рабочие нагрузки пакетного вывода, см. в статье Использование виртуальных машин с низким приоритетом в конечных точках пакетной службы.
Наконец, Машинное обучение Azure не взимает плату за сами конечные точки пакетной службы или пакетные развертывания, чтобы можно было упорядочить конечные точки и развертывания в соответствии с вашим сценарием. Конечные точки и развертывания могут использовать независимые или общие кластеры, поэтому можно добиться точного контроля над вычислительными ресурсами заданий. Используйте масштабирование к нулю в кластерах, чтобы гарантировать, что ресурсы не используются при простое.
Упрощение практики MLOps
Конечные точки пакетной службы могут обрабатывать несколько развертываний в одной конечной точке, что позволяет изменять реализацию конечной точки, не изменяя URL-адрес, используемый потребителями для вызова.
Вы можете добавлять, удалять и обновлять развертывания, не затрагивая саму конечную точку.
Гибкие источники данных и хранилище
Конечные точки пакетной службы считывают и записывают данные непосредственно из хранилища. В качестве входных данных можно указать хранилища данных Машинное обучение Azure, Машинное обучение Azure ресурсы данных или служба хранилища учетные записи. Дополнительные сведения о поддерживаемых параметрах ввода и их указании см. в разделе "Создание заданий и входных данных" для конечных точек пакетной службы.
Безопасность
Конечные точки пакетной службы предоставляют все возможности, необходимые для работы рабочих нагрузок уровня рабочей среды в корпоративном параметре. Они поддерживают частную сеть для защищенных рабочих областей и проверки подлинности Microsoft Entra либо с помощью субъекта-пользователя (например, учетной записи пользователя) или субъекта-службы (например, управляемого или неуправляемого удостоверения). Задания, созданные пакетной конечной точкой, выполняются под удостоверением вызывающего средства, что позволяет реализовать любой сценарий. Дополнительные сведения об авторизации при использовании конечных точек пакетной службы см. в статье "Проверка подлинности в конечных точках пакетной службы".