Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как разработать скрипт обучения с помощью записной книжки на облачной рабочей станции Машинного обучения Azure. В этом руководстве рассматриваются основные шаги, которые необходимы, чтобы начать работу.
- Установите и настройте облачную рабочую станцию. Облачная рабочая станция работает на вычислительной инстанции Azure Machine Learning, которая предварительно сконфигурирована с окружениями для поддержки ваших потребностей в разработке моделей.
- Используйте облачные среды разработки.
- Используйте MLflow для отслеживания метрик модели.
Необходимые компоненты
Чтобы использовать Машинное обучение Azure, вам нужна рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
Внимание
Если в рабочей области Машинное обучение Azure настроена управляемая виртуальная сеть, может потребоваться добавить правила для исходящего трафика, чтобы разрешить доступ к общедоступным репозиториям пакетов Python. Дополнительные сведения см. в статье "Сценарий: доступ к общедоступным пакетам машинного обучения".
Создание или запуск вычислений
Вычислительные ресурсы можно создать в разделе "Вычисления " в рабочей области. Вычислительный экземпляр — это облачная рабочая станция, полностью управляемая машинным обучением Azure. В этом руководстве используется вычислительный экземпляр. Его также можно использовать для запуска собственного кода, а также для разработки и тестирования моделей.
- Войдите в Студию машинного обучения Azure.
- Выберите рабочую область, если она еще не открыта.
- В левой области выберите "Вычисления".
- Если у вас нет вычислительного экземпляра, вы увидите Новый в середине страницы. Выберите "Создать " и заполните форму. Вы можете использовать все значения по умолчанию.
- Если у вас есть вычислительный экземпляр, выберите его из списка. Если он остановлен, нажмите кнопку "Пуск".
Открытие Visual Studio Code (VS Code)
После запуска вычислительного экземпляра вы можете получить доступ к нему различными способами. В этом руководстве описывается использование вычислительного экземпляра из Visual Studio Code. Visual Studio Code предоставляет полную интегрированную среду разработки (IDE) для создания вычислительных экземпляров.
В списке вычислительных экземпляров выберите ссылку VS Code (Web) или VS Code (Desktop) для используемого вычислительного экземпляра. Если выбрать VS Code (Desktop), может появиться сообщение с просьбой открыть приложение.

Этот экземпляр Visual Studio Code подключен к вашему вычислительному узлу и файловой системе рабочей области. Даже если открыть его на рабочем столе, файлы, которые отображаются в рабочей области, являются файлами.
Настройка новой среды для создания прототипов
Чтобы скрипт выполнялся, необходимо работать в среде, настроенной с учетом зависимостей и библиотек, которые ожидает код. В этом разделе показано, как создать среду, адаптированную к коду. Чтобы создать новое ядро Jupyter, к которому подключается записная книжка, используйте YAML-файл, определяющий зависимости.
Отправка файла.
Отправленные файлы хранятся в общей папке Azure, и эти файлы подключены к каждому вычислительному экземпляру и совместно используются в рабочей области.
Перейдите к azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Скачайте файл среды Conda workstation_env.yml на компьютер, нажав кнопку с многоточием (...) в правом верхнем углу страницы, а затем нажмите кнопку "Скачать".
Перетащите файл с компьютера в окно Visual Studio Code. Файл передается в рабочую область.
Переместите файл в папку имени пользователя.
Выберите файл для предварительного просмотра. Просмотрите зависимости, которые он указывает. Вы должны увидеть примерно следующее:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibСоздайте ядро.
Теперь используйте терминал для создания нового ядра Jupyter, основанного на файле workstation_env.yml .
- В меню в верхней части Visual Studio Code выберите терминал > "Новый терминал".
Просмотр текущих сред Conda. Активная среда помечена звездочкой (*).
conda env listИспользуйте
cdдля перехода к папке, в которой вы отправили файл workstation_env.yml . Например, если вы загрузили его в папку пользователя, используйте следующую команду:cd Users/myusernameУбедитесь, что workstation_env.yml находится в папке.
lsСоздайте среду на основе предоставленного файла Conda. Создание среды занимает несколько минут.
conda env create -f workstation_env.ymlАктивируйте новую среду.
conda activate workstation_envПримечание.
Если вы видите CommandNotFoundError, следуйте инструкциям для запуска
conda init bash, закройте терминал и откройте новый. Затем повторитеconda activate workstation_envкоманду.Убедитесь, что правильная среда активна, снова проверьте среду, помеченную как *.
conda env listСоздайте новое ядро Jupyter, основанное на активной среде.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Закройте окно терминала.
Теперь у вас есть новое ядро. Затем откройте блокнот и используйте это ядро.
Создание записной книжки
- В меню в верхней части Visual Studio Code выберите Файл > Новый файл.
- Назовите новый файл develop-tutorial.ipynb (или используйте другое имя). Обязательно используйте расширение IPYNB .
Задание ядра
- В правом верхнем углу нового файла выберите "Выбрать ядро".
- Выберите вычислительный экземпляр Машинного обучения Azure (computeinstance-name).
- Выберите созданное ядро: Учебная рабочая станция Env. Если ядро не отображается, нажмите кнопку обновления над списком.
Разработка скрипта обучения
В этом разделе описан сценарий обучения Python, который прогнозирует платежи по умолчанию кредитной карты с помощью подготовленных тестовых и обучающих наборов данных из набора данных UCI.
Этот код использует sklearn для обучения и MLflow для ведения журнала метрик.
Начните с кода, который импортирует пакеты и библиотеки, которые будут использоваться в скрипте обучения.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitЗатем загрузите и обработайте данные для эксперимента. В этом руководстве вы считываете данные из файла в Интернете.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Подготовьте данные для обучения.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesДобавьте код для запуска автологирования с помощью MLflow, чтобы отслеживать метрики и результаты. Благодаря итеративному характеру разработки моделей, MLflow помогает регистрировать параметры моделей и результаты. Чтобы сравнить и понять, как работает ваша модель, ознакомьтесь с результатами разных запусков. Журналы также предоставляют контекст для перехода с этапа разработки на этап обучения рабочих процессов в Машинное обучение Azure.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()обучение моделей.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Примечание.
Предупреждения MLflow можно игнорировать. Необходимые результаты по-прежнему будут отслеживаться.
Выберите Выполнить всё наверху для выполнения кода.
Выполнение итерации
Теперь, когда у вас есть результаты модели, измените что-то и снова запустите модель. Например, попробуйте использовать другой метод классификации:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Примечание.
Предупреждения MLflow можно игнорировать. Необходимые результаты по-прежнему будут отслеживаться.
Выберите Выполнить все, чтобы запустить модель.
Изучение результатов
Теперь, когда вы пробовали две разные модели, используйте результаты, отслеживаемые MLFfow, чтобы решить, какая модель лучше. Вы можете ссылаться на такие метрики, как точность или другие индикаторы, которые наиболее важны для ваших сценариев. Дополнительные сведения об этих результатах можно просмотреть, просмотрев задания, созданные MLflow.
Вернитесь в рабочую область в Студия машинного обучения Azure.
В левой области выберите "Задания".
Выберите "Учебник по разработке в облаке".
Показаны два задания, по одному для каждой из пробных моделей. Имена создаются автоматически. Если вы хотите переименовать задание, наведите указатель мыши на имя и нажмите кнопку карандаша рядом с ним.
Выберите ссылку для первого задания. Имя отображается в верхней части страницы. Его также можно переименовать с помощью кнопки карандаша.
На странице показаны сведения о задании, такие как свойства, выходные данные, теги и параметры. В разделе "Теги" отображается estimator_name, описывающая тип модели.
Перейдите на вкладку "Метрики" , чтобы просмотреть метрики, зарегистрированные MLflow. (Результаты будут отличаться, так как у вас есть другой набор обучения.)
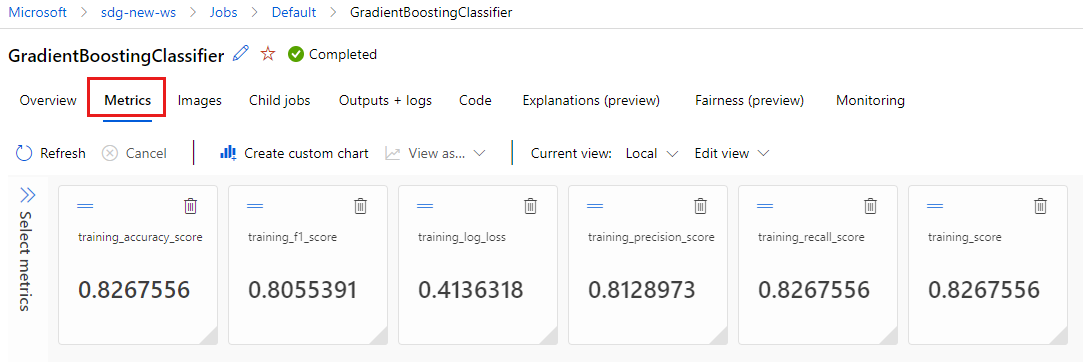
Перейдите на вкладку "Изображения" , чтобы просмотреть изображения, созданные MLflow.
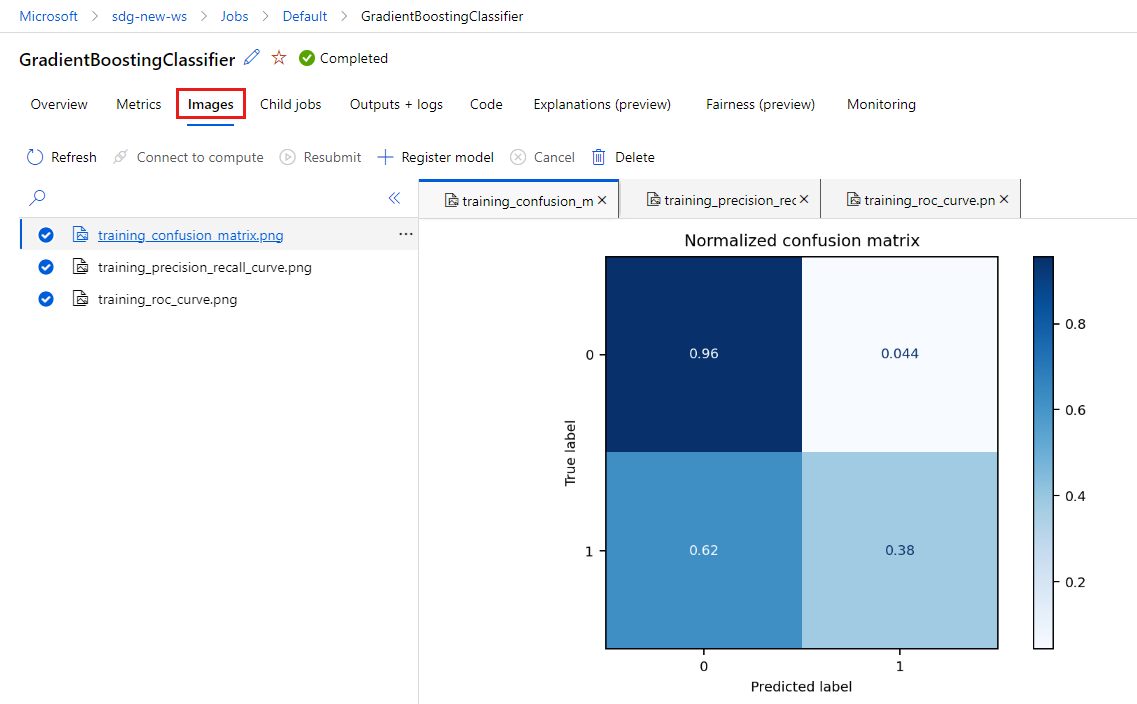
Вернитесь и просмотрите метрики и изображения для другой модели.

Создание скрипта Python
Теперь вы создадите скрипт Python из записной книжки для обучения модели.
В Visual Studio Code щелкните правой кнопкой мыши имя файла записной книжки и выберите "Импортировать записную книжку в скрипт".
Выберите "Сохранить файл > ", чтобы сохранить новый файл скрипта. Вызовите его train.py.
Просмотрите файл и удалите код, который не требуется в скрипте обучения. Например, сохраните код для модели, которую вы хотите использовать, и удалите код для модели, которую вы не хотите использовать.
- Обязательно сохраните код, который запускает автозалогирование (
mlflow.sklearn.autolog()). - При интерактивном запуске скрипта Python (при выполнении здесь) можно сохранить строку, определяющую имя эксперимента (
mlflow.set_experiment("Develop on cloud tutorial")). Кроме того, вы можете присвоить ему другое имя, чтобы увидеть его как другую запись в разделе "Задания ". Но при подготовке скрипта для задания обучения эта строка не применяется и должна быть опущена: определение задания включает имя эксперимента. - При обучении одной модели линии запуска и окончания запуска (
mlflow.start_run()иmlflow.end_run()) не нужны (они не имеют эффекта), но их можно оставить.
- Обязательно сохраните код, который запускает автозалогирование (
Завершив редактирование, сохраните файл.
Теперь у вас есть скрипт Python для обучения предпочитаемой модели.
выполнение скрипта Python.
Теперь вы запускаете этот код в вычислительном экземпляре, который является вашей средой разработки Машинное обучение Azure. Руководство по обучению модели показывает, как выполнять скрипт обучения в более масштабируемом виде для более мощных вычислительных ресурсов.
Выберите среду, созданную ранее в этом руководстве, в качестве версии Python (workstations_env). В правом нижнем углу ноутбука вы увидите имя среды. Выберите ее, а затем выберите среду в верхней части Visual Studio Code.
Запустите скрипт Python, нажав кнопку "Запустить все " над кодом.


Примечание.
Предупреждения MLflow можно игнорировать. Вы по-прежнему получите все метрики и изображения из автологирования.
Изучение результатов скрипта
Вернитесь к заданиям в рабочей области в Студия машинного обучения Azure, чтобы просмотреть результаты скрипта обучения. Помните, что обучающие данные изменяются с каждым разбиением, поэтому результаты отличаются в каждом запуске.
Очистка ресурсов
Если вы планируете продолжить работу с другими учебниками, перейдите к следующим шагам.
Остановка вычислительной операции
Если вы сейчас не планируете использовать вычислительный экземпляр, остановите его, выполнив следующие действия:
- В студии в левой области выберите "Вычисления".
- В верхней части страницы выберите Экземпляры вычисления.
- В списке выберите вычислительный экземпляр.
- В верхней части страницы нажмите кнопку "Остановить".
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
Введите имя группы ресурсов. Затем выберите Удалить.
Следующие шаги
Дополнительные сведения можно найти на следующих ресурсах:
- Артефакты и модели в MLflow
- Использование Git со службой "Машинное обучение Microsoft Azure".
- Запуск записных книжек Jupyter в рабочей области
- Работа с терминалом вычислительного экземпляра в рабочей области
- Управление сеансами записной книжки и терминала
В этом руководстве показаны ранние шаги по созданию модели и разработке прототипа на том же компьютере, на котором находится код. В рабочей среде вы узнаете, как использовать этот скрипт обучения для более мощных удаленных вычислительных ресурсов: