Автоматизированное машинное обучение (AutoML)?
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
Автоматизированное машинное обучение, которое также называется автоматизированным ML или AutoML, представляет собой процесс автоматизации трудоемких и многократно повторяющихся задач разработки моделей машинного обучения. С его помощью специалисты по обработке и анализу данных могут создавать модели машинного обучения с высокой масштабируемостью, эффективностью и производительностью, сохраняя при этом качество модели. В основе автоматизированного ML в машинном обучении Azure лежат передовые разработки исследовательского подразделения корпорации Майкрософт.
Традиционная разработка моделей машинного обучения занимает много ресурсов, требует значительного объема знаний в предметной области и времени для создания и сравнения десятков моделей. С помощью автоматизированного машинного обучения вы ускоряете получение готовых к работе моделей машинного обучения, делая этот процесс простым и эффективным.
Использование AutoML в Машинном обучении Azure
Машинное обучение Azure предлагает два варианта взаимодействия с автоматизированным ML: Сведения о доступности возможности в каждом интерфейсе (версия 1) см. в следующих разделах.
Клиенты, которые предпочитают работать с кодом, могут воспользоваться пакетом SDK Python для Машинного обучения Azure. Начните работу со статьи Руководство по использованию автоматизированного машинного обучения для прогнозирования тарифов на такси (версия 1).
Клиенты, которые хотят минимально применять код или обойтись без него, могут воспользоваться Студией машинного обучения Azure по адресу https://ml.azure.com. Начните работу с указанных ниже материалов.
Параметры эксперимента
Следующие параметры позволяют настроить эксперимент по автоматизированному ML.
| Пакет SDK для Python | Веб-интерфейс студии | |
|---|---|---|
| Разделение данных на наборы для обучения и проверки | ✓ | ✓ |
| Поддержка задач ML: классификация, регрессия и &прогнозирование | ✓ | ✓ |
| Поддерживает задачи компьютерного зрения: классификация изображений, сегментация экземпляров обнаружения & объектов | ✓ | |
| Оптимизация на основе основной метрики | ✓ | ✓ |
| Поддерживает вычисление Машинного обучения Azure в качестве целевого объекта вычислений | ✓ | ✓ |
| Настройка горизонта прогнозирования, целевых задержек & целевого скользящего интервала | ✓ | ✓ |
| Задание критериев выхода | ✓ | ✓ |
| Задание одновременных итераций | ✓ | ✓ |
| Удаление столбцов | ✓ | ✓ |
| Блочные алгоритмы | ✓ | ✓ |
| Перекрестная проверка | ✓ | ✓ |
| Поддержка обучения в кластерах Azure Databricks | ✓ | |
| Просмотр имен спроектированных функций | ✓ | |
| Сводка по конструированию признаков | ✓ | |
| Конструирование признаков для сплошности | ✓ | |
| Уровни детализации файла журнала | ✓ |
Параметры модели
Эти параметры можно применить к наилучшей модели, полученной в результате эксперимента по автоматизированному ML.
| Пакет SDK для Python | Веб-интерфейс студии | |
|---|---|---|
| Регистрация, развертывание и объяснение наилучшей модели | ✓ | ✓ |
| Использование коллективных моделей &на основе голосования и распределения | ✓ | ✓ |
| Отображение наилучшей модели на основе метрики, отличной от основной | ✓ | |
| Включение или отключение совместимости с моделью ONNX | ✓ | |
| Тестирование модели | ✓ | ✓ (предварительная версия) |
Параметры управления заданием
Эти параметры позволяют просматривать и контролировать задания эксперимента и его дочерние задания.
| Пакет SDK для Python | Веб-интерфейс студии | |
|---|---|---|
| Сводная таблица по заданиям | ✓ | ✓ |
| Отмена заданий и дочерних заданий | ✓ | ✓ |
| Получение ограничений | ✓ | ✓ |
| Приостановка и возобновление заданий | ✓ |
Когда следует использовать AutoML: классификация, регрессия, прогнозирование, компьютерное зрение & NLP
Примените автоматизированное ML, если вы хотите использовать Машинное обучение Azure для обучения и настройки модели с использованием указанных целевых метрик. Автоматизированное ML делает процесс разработки модели машинного обучения более демократичным и предоставляет пользователям возможность организовать комплексный поток машинного обучения для любой проблемы, невзирая на имеющиеся навыки пользователей в области обработки и анализа данных.
Специалисты по машинному обучению и разработчики в разных отраслях могут использовать автоматизированное ML для следующего:
- Реализации решений ML без обширных знаний в области программирования.
- Экономии времени и ресурсов.
- Использования рекомендаций по обработке и анализу данных.
- Обеспечения гибкого подхода к решению проблем.
Классификация
Классификация — это распространенная задача для машинного обучения. Классификация представляет собой тип контролируемого обучения, в котором обучение моделей происходит с помощью обучающих данных, после чего полученные знания применяются к новым данным. Машинное обучение Azure предлагает возможность конструирования признаков специально для таких задач, как, например, конструкторы признаков текста для классификации с помощью глубокой нейронной сети. Узнайте подробнее о параметрах конструирования признаков (версия 1).
Основной целью моделей классификации является прогнозирование того, к каким категориям будут относиться новые данные в зависимости от результатов изучения обучающих данных. К общим примерам классификации относятся обнаружение мошенничества, распознавание рукописного текста и обнаружение объектов. Дополнительные сведения см. в примере по созданию модели классификации с помощью автоматизированного ML (версия 1).
Ознакомьтесь с примерами классификации и автоматизированного машинного обучения в следующих записных книжках по Python: Обнаружение мошенничества, Маркетинговое прогнозирование и Классификация данных группы новостей
Регрессия
Аналогично классификации, регрессия также является распространенной задачей контролируемого обучения.
В отличие от классификации, при которой прогнозируемые выходные значения упорядочиваются по категориям, модели регрессии прогнозируют числовые выходные значения на основе независимых прогностических факторов. В случае регрессии цель заключается в том, чтобы установить связь между этими независимыми переменными прогнозирования, оценивая, как одна переменная влияет на другие. Например, стоимость автомобиля зависит от таких факторов, как расход топлива, уровень безопасности и т. д. Узнайте дополнительные сведения и ознакомьтесь с примером регрессии с помощью автоматизированного машинного обучения (версия 1).
Ознакомьтесь с примерами регрессии и автоматизированного машинного обучения для прогнозирования в следующих записных книжках по Python: Прогнозирование производительности ЦП.
Прогнозирование временных рядов
Создание прогнозов является неотъемлемой частью любого бизнеса, будь то прогнозирование дохода, инвентаризация, продажи или спрос. Вы можете использовать автоматизированное ML для объединения методов и подходов и получения рекомендуемого, высококачественного прогноза временных рядов. Дополнительные сведения об этом см. в статье Автоматизированное машинное обучение для прогнозирования временных рядов (версия 1).
Эксперимент по прогнозированию временных рядов рассматривается как многовариантная задача регрессии. Прошлые значения временных рядов "сводятся" для создания дополнительных измерений для регрессии вместе с другими прогностическими факторами. Данный подход, в отличие от классических методов временных рядов, имеет преимущество, поскольку изначально включает несколько контекстных переменных и их связь друг с другом во время обучения. Автоматизированное ML изучает одну, но зачастую разветвленную модель для всех элементов в наборе данных и горизонтах прогнозирования. Поэтому доступно больше данных для оценки параметров модели, а также становится возможным обобщение невидимых рядов.
Конфигурация расширенного прогнозирования включает следующее:
- Контроль сплошности и конструирование признаков.
- Временные ряды и средства обучения DNN (Auto-ARIMA, Prophet, ForecastTCN).
- Поддержка многих моделей путем группирования.
- Перекрестная проверка последовательного происхождения
- Настраиваемые задержки.
- Признаки для скользящих агрегатов значений окна.
Ознакомьтесь с примерами регрессии и автоматизированного машинного обучения для прогнозирования в следующих записных книжках по Python: Прогнозирование продаж, Прогнозирование спроса и Прогнозирование количества активных пользователей GitHub за сутки.
компьютерное зрение;
Поддержка задач компьютерного зрения позволяет легко создавать модели, обученные по данным изображений, для таких сценариев, как классификация изображений и обнаружение объектов.
Используя эти параметры, вы можете выполнять такие задачи:
- Простая интеграция с возможностью добавления меток к данным Машинного обучения Azure
- Использование помеченных данных для создания моделей изображений
- Оптимизация производительности модели путем указания алгоритма модели и настройки гиперпараметров.
- Загрузка или развертывание полученной модели в качестве веб-службы в Машинное обучение Azure.
- Ввод в эксплуатацию в большом масштабе, используя возможности Машинного обучения Azure MLOps и Конвейеры ML (версия 1).
Создание моделей AutoML для задач визуального распознавания поддерживается с помощью пакета SDK Python для Машинного обучения Azure. Доступ к результатам экспериментальных заданий, моделям и выходным данным можно получить из пользовательского интерфейса Студии машинного обучения Azure.
Узнайте, как настроить обучение AutoML для моделей компьютерного зрения.

Автоматизированное машинное обучение поддерживает для изображений следующие задачи компьютерного зрения.
| Задача | Описание |
|---|---|
| Многоклассовая классификация изображений | Задачи, в которых каждому изображению присваивается одна метка из набора классов, например, каждое изображение классифицируется как "кошка", "собака" или "утка". |
| Классификация изображений с несколькими метками | Задачи, в которых каждому изображению могут быть присвоены одна или несколько меток из набора, например, одно изображение может получить одновременно метки "кошка" или "собака". |
| Обнаружение объектов | Задачи, позволяющие обнаружить объекты на изображении и обозначить каждый обнаруженный объект ограничивающим прямоугольником, например, для поиска всех собак и кошек на изображении с координатами ограничивающего прямоугольника вокруг каждого из них. |
| Сегментация экземпляров | Задачи, позволяющие обнаружить на изображении объекты на уровне пикселов с отрисовкой многоугольника вокруг каждого обнаруженного объекта. |
Обработка естественного языка: NLP
Поддержка задач обработки естественного языка (NLP) в автоматизированном машинном обучении позволяет легко создавать модели, обученные по текстовым данным, для классификации текста и сценариев распознавания именованных сущностей. Создавать модели NLP, обученные с помощью автоматизированного машинного обучения, можно с использованием пакета SDK Python для Машинного обучения Azure. Доступ к результатам экспериментальных заданий, моделям и выходным данным можно получить из пользовательского интерфейса Студии машинного обучения Azure.
NLP поддерживает следующие возможности:
- Комплексное обучение NLP глубоким нейронным сетям с помощью последних предварительно обученных моделей BERT
- Простая интеграция с возможностью маркировки данных Машинного обучения Azure
- Использование помеченных данных для создания моделей NLP
- Многоязычная поддержка, включающая 104 языка
- Распределенное обучение с использованием Horovod
Узнайте, как настроить обучение AutoML для моделей NLP (версия 1).
Принцип работы автоматизированного ML
Во время обучения Машинное обучение Azure создает несколько параллельных конвейеров, проверяющих разные алгоритмы и параметры. Служба выполняет итерацию по алгоритмам машинного обучения, связанным с выбором признаков, где каждая итерация создает модель с оценкой обучения. Чем выше оценка, тем лучше модель "подходит" для ваших данных. Процесс будет остановлен после того, как он достигнет критерия выхода, определенного в эксперименте.
С помощью Машинного обучения Azure вы можете проектировать и запускать эксперименты по использованию автоматизированного ML.
Определите проблему машинного обучения , которую необходимо решить: классификацию, прогнозирование, регрессию или компьютерное зрение.
Выберите, будете ли вы использовать пакет SDK для Python или веб-интерфейс студии. Узнайте подробнее о сравнении пакета SDK для Python и веб-интерфейса студии.
- Если вы предпочитаете не вдаваться в подробности программирования, воспользуйтесь веб-интерфейсом студии Машинного обучения Azure по адресу https://ml.azure.com.
- Разработчикам Python рекомендуется ознакомиться с пакетом SDK для Python для Машинного обучения Azure (версия 1).
Укажите источник и формат для обучающих данных: массивы Numpy или кадры данных Pandas.
Настройте целевой объект вычислений для обучения модели, например локальный компьютер, Вычислительные среды Машинного обучения Azure, удаленные виртуальные машины или Azure Databricks с пакетом SDK версии 1.
Настройте параметры автоматизированного машинного обучения, определяющие количество итераций по различным моделям, настройки гиперпараметров, расширенную предварительную обработку/конструирование признаков, а также метрики, которые следует использовать при определении наиболее подходящей модели.
Отправьте задание обучения.
Проверьте результаты.
Этот процесс представлен на схеме ниже.
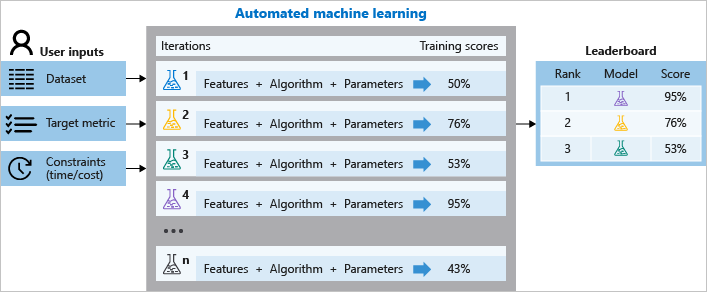
Вы также можете просмотреть записанные данные обучающего задания, содержащие метрики, собранные во время выполнения задания. В результате выполнения обучающего задании создается объект сериализации Python (файл с расширением .pkl), содержащий модель и предварительную обработку данных.
Несмотря на то, что создание модели автоматизировано, можно также узнать, насколько важны признаки или насколько они подходят для создаваемых моделей.
Руководство по локальным и удаленным управляемым целевым объектам вычислений машинного обучения
Веб-интерфейс для автоматизированного ML всегда использует удаленный целевой объект вычислений. Однако при использовании пакета SDK для Python потребуется выбрать локальный или удаленный целевой объект вычислений для автоматизированного обучения ML.
- Локальное вычисление: обучение выполняется на локальном ноутбуке или на виртуальной машине.
- Удаленное вычисление: обучение выполняется на кластерах Машинного обучения Azure.
Выбор целевого объект вычислений
При выборе целевого объекта вычислений учитывайте следующие факторы.
- Выберите локальное вычисление: если ваш сценарий относится к начальным исследованиям или демонстрациям с использованием небольших данных и короткого обучения (т. е. секунды или несколько минут на дочернее задание), обучение на локальном компьютере может быть лучшим вариантом. Нет необходимости в настройке, а ресурсы инфраструктуры (ваш компьютер или виртуальная машина) доступны напрямую.
- Выберите удаленный вычислительный кластер машинного обучения. Если обучение ведется на больших наборах данных, например, при создании моделей для обучения в производственной среде, требующих более длительного обучения, то удаленное вычисление обеспечит более высокую производительность, т. к.
AutoMLбудет параллельно вести обучение на узлах кластера. При удаленном вычислении время запуска внутренней инфраструктуры увеличится приблизительно на 1,5 минуты на каждое дочернее задание, плюс еще несколько минут для кластерной инфраструктуры, если виртуальные машины еще не запущены.
Преимущества и недостатки
При выборе локального и удаленного вычисления учитывайте следующие преимущества и недостатки.
| Преимущества | Недостатки | |
|---|---|---|
| Локальный целевой объект вычислений | ||
| Удаленные вычислительные кластеры ML |
Доступность функций
При использовании удаленного вычисления доступны дополнительные функции, как показано в таблице ниже.
| Компонент | Remote | Local |
|---|---|---|
| Потоковая передача данных (поддержка больших наборов данных, до 100 ГБ) | ✓ | |
| Конструирование признаков текста и обучение на основе DNN-BERT | ✓ | |
| Встроенная поддержка GPU (обучение и вывод) | ✓ | |
| Поддержка классификации и маркировки изображений | ✓ | |
| Модели Auto-ARIMA, Prophet и ForecastTCN для прогнозирования | ✓ | |
| Несколько параллельных заданий и итераций | ✓ | |
| Создание моделей с возможностями интерпретации в пользовательском интерфейсе веб-интерфейса студии AutoML Studio | ✓ | |
| Настройка проектирования функций в пользовательском интерфейсе веб-интерфейса студии | ✓ | |
| Настройка гиперпараметров Машинного обучения Azure | ✓ | |
| Поддержка рабочих процессов конвейера машинного обучения Azure | ✓ | |
| Продолжение задания | ✓ | |
| Прогнозирование | ✓ | ✓ |
| Создание и запуск экспериментов в записных книжках | ✓ | ✓ |
| Регистрация и визуализация сведений и метрик экспериментов в пользовательском интерфейсе | ✓ | ✓ |
| Проверки данных | ✓ | ✓ |
Обучение, проверка и тестирование данных
Предоставление обучающих данных для обучения моделей машинного обучения и указание типа проверки моделей выполняется с помощью автоматизированного машинного обучения. Автоматизированное машинное обучение выполняет проверку модели в рамках обучения. Таким образом, автоматизированное машинное обучение использует данные проверки для настройки гиперпараметров модели на основе примененного алгоритма, чтобы найти наилучшее сочетание для обучающих данных. Использование одних и тех же данных проверки для каждой итерации настройки может привести к смещению оценки модели, поскольку модель продолжает улучшаться и соответствует данным проверки.
Чтобы такой сдвиг не произошел при оценке окончательной рекомендуемой модели, автоматизированное машинное обучение использует проверочные данные для оценки окончательной модели, рекомендуемой автоматизированным машинным обучением по завершении эксперимента. При предоставлении проверочных данных в рамках конфигурации эксперимента AutoML рекомендуемая модель проверяется по умолчанию в конце эксперимента (предварительная версия).
Важно!
Тестирование моделей с помощью тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
Узнайте, как использовать проверочные данные для настройки экспериментов AutoML (предварительная версия) с помощью пакета SDK (версия 1) или Студии машинного обучения Azure.
Предоставив собственные проверочные данные или часть обучающих данных, вы также можете протестировать любую существующую модель автоматизированного машинного обучения (предварительную версию 1), включая модели из дочерних заданий.
Проектирование признаков
Конструирование признаков — это создание функций, которые помогают алгоритмам машинного обучения обучаться быстрее. При этом используется база данных предметной области. Чтобы упростить конструирование признаков в машинном обучении Azure применяются методики масштабирования и нормализации. В совокупности эти методы и функции, описанные выше, называются конструированием признаков.
Для автоматических экспериментов c машинным обучением конструирование признаков применяется автоматически. Но этот процесс также можно настроить под ваши данные. Узнайте больше о конструировании признаков (версия 1) и о том, как с помощью AutoML предотвратить появление лжевзаимосвязи и несбалансированных данных в моделях.
Примечание
Шаги конструирования признаков автоматизированного машинного обучения (нормализация признаков, обработка недостающих данных, преобразование текста в числовой формат и т. д.) становятся частью базовой модели. При использовании модели прогнозирования те же этапы конструирования признаков, которые выполнялись во время обучения, автоматически выполняются для входных данных.
Настройка конструирования признаков
Также доступны дополнительные методы конструирования признаков, такие как, кодирование и преобразования.
Включить этот параметр можно следующими способами:
Студия машинного обучения Azure: включите параметр Автоматическое конструирование признаков в разделе Просмотреть дополнительную конфигурацию, как описано здесь (версия 1).
Пакет SDK для Python: укажите
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'в объекте AutoMLConfig. Дополнительные сведения о включении конструирования признаков (версия 1).
Коллективные модели
Автоматизированное машинное обучение поддерживает коллективные модели, которые включены по умолчанию. Коллективное обучение улучшает результаты машинного обучения и точность прогнозов, объединяя несколько моделей в отличие от использования отдельных моделей. Коллективные итерации отображаются в виде окончательных итераций задания. Для комбинирования моделей в автоматизированном машинном обучении используются методы голосования и распределения.
- Голосование: прогноз формируется на основе взвешенного среднего вероятности прогнозируемых классов (для задач классификации) или целевых объектов прогнозируемой регрессии (для задач регрессии).
- Распределение: объединение разнородных моделей и обучение метамодели на основе выходных данных отдельных моделей. Текущие метамодели по умолчанию — LogisticRegression для задач классификации и ElasticNet для задач регрессии/прогнозирования.
Алгоритм коллективного выбора с отсортированной коллективной инициализацией используется для выбора используемых моделей. На высоком уровне этот алгоритм инициализирует сочетание до пяти моделей с наилучшими отдельными оценками и проверяет, что эти модели входят в 5 % наилучшей оценки, чтобы избежать недостаточно подходящего сочетания. Затем для каждой коллективной итерации в существующее сочетание добавляется новая модель и вычисляется результирующая оценка. Если новая модель улучшила существующую оценку сочетания, сочетание обновляется для включения новой модели.
Ознакомьтесь с инструкциями (версия 1) по изменению параметров сочетаний по умолчанию в автоматизированном машинном обучении.
AutoML & ONNX
С помощью Машинного обучения Azure AutoML можно использовать для создания модели Python и преобразования ее в формат ONNX. После преобразования моделей в формат ONNX их можно запускать на различных платформах и устройствах. Узнайте подробнее об ускорении моделей ML с помощью ONNX.
Сведения о том, как преобразовать модель в формат ONNX, см. в этом примере Jupyter Notebook. Узнайте, какие алгоритмы поддерживаются в ONNX (версия 1).
Среда выполнения ONNX также поддерживает C#, поэтому вы можете автоматически использовать созданную модель в приложениях C# без необходимости перекодирования или любых сетевых задержек, которые имеются на конечных точках REST. Дополнительные сведения об использовании модели AutoML ONNX в приложении .NET с ML.NET и работу с моделями ONNX с помощью API языка C# среды выполнения ONNX.
Дальнейшие действия
Есть несколько ресурсов, которые помогут вам приступить к работе с AutoML.
Практические руководства и другие учебные материалы
Руководства — это полный вводный пример в сценарии AutoML.
Сведения о первом запуске кода см. в руководстве по обучению регрессивной модели с помощью AutoML и Python (версия 1).
Сведения о создании моделей без кода или с малым количеством кода см. в руководстве по обучению моделей классификации AutoML без кода с помощью Студии машинного обучения Azure.
Сведения об использовании AutoML для обучения моделей компьютерного зрения см. в руководстве по обучению модели обнаружения объектов с помощью AutoML и Python (версия 1).
В обучающих статьях приводятся дополнительные сведения о возможностях автоматизированного ML. Например,
Настройка параметров для автоматических обучающих экспериментов
Узнайте, как обучить модели прогнозирования на основе данных временных рядов (версия 1).
Узнайте, как обучить модели компьютерного зрения с помощью Python (версия 1).
узнайте, как просмотреть созданный код на основе моделей автоматизированного машинного обучения.
Примеры записной книжки Jupyter
Изучите подробные примеры кода и варианты использования в репозитории записных книжек GitHub для автоматизированных примеров машинного обучения.
Справочник по пакету SDK для Python
Узнайте больше о конструктивных шаблонах SDK и спецификациях классов в справочной документации по классу AutoML.
Примечание
Автоматизированное машинное обучение также доступно в других решениях Майкрософт, например, ML.NET, HDInsight, Power BI и SQL Server