Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Векторы — это многомерные встраивания, которые представляют текст, изображения и другое содержимое математически. Поиск с использованием ИИ Azure хранит векторы на уровне поля, позволяя вектору и невекторному содержимому сосуществовать в одном индексе search.
Индекс поиска становится векторным индексом при определении векторных полей и конфигурации вектора. Чтобы заполнить поля векторов, можно отправить предварительно вычисленные вложения в них или использовать интегрированную векторизацию, встроенную возможность Поиск с использованием ИИ Azure, которая создает внедрения во время индексирования.
Во время запроса поля векторов в индексе позволяют выполнять поиск сходства, где система извлекает документы, векторы которых наиболее похожи на векторный запрос. Вы можете использовать векторный поиск для сопоставления сходства в одиночку или гибридного поиска для сочетания сходства и сопоставления ключевых слов.
В этой статье рассматриваются основные понятия для создания и управления векторным индексом, в том числе:
- Шаблоны извлечения векторов
- Содержимое (векторные поля и конфигурация)
- Структура физических данных
- Базовые операции
Подсказка
Хотите начать сразу? См . статью "Создание векторного индекса".
Шаблоны извлечения векторов
Поиск с использованием ИИ Azure поддерживает два шаблона для извлечения векторов:
Классический поиск. Этот шаблон использует панель поиска, ввод запроса и отображение результатов. Во время выполнения запроса поисковая система или код приложения векторизирует входные данные пользователя. Затем выполняется векторный поиск по векторным полям в вашем индексе, затем формулируется ответ, который вы отобразите в клиентском приложении.
В Поиск с использованием ИИ Azure результаты возвращаются как плоский набор строк, и вы можете выбрать поля, которые необходимо включить в ответ. Хотя поисковая система сопоставляет по векторам, ваш индекс должен содержать не векторное, человеко-читаемое содержимое для заполнения результатов поиска. Классический поиск поддерживает как векторные запросы, так и гибридные запросы.
Генерированный поиск. Языковые модели используют данные из Поиск с использованием ИИ Azure для реагирования на запросы пользователей. Уровень оркестрации обычно координирует запросы и поддерживает контекст, перенаправляя результаты поиска в чат-модели, такие как GPT. Этот шаблон основан на архитектуре извлечения-расширенного генерации (RAG), где индекс поиска предоставляет данные для обоснования.
Схема векторного индекса
Для схемы векторного индекса требуется следующее:
- Имя
- Ключевое поле (строка)
- Одно или несколько векторных полей
- Конфигурация вектора
Поля, не являющиеся векторными, не обязательны, но мы рекомендуем включать их для гибридных запросов или для возврата дословного содержимого, которое не обрабатывается языковой моделью. Дополнительные сведения см. в разделе "Создание векторного индекса".
Схема индекса должна отражать шаблон извлечения вектора. В этом разделе в основном рассматривается композиция полей для классического поиска, но она также содержит рекомендации по схеме для создания поиска.
Базовая конфигурация поля вектора
Поля векторов имеют уникальные типы и свойства данных. Вот как выглядит векторное поле в коллекции полей:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Для векторных полей поддерживаются только определенные типы данных . Наиболее распространенным типом является Collection(Edm.Single), но использование узких типов может сэкономить место для хранения.
Поля векторов должны быть доступны для поиска и извлечения, но они не могут быть фильтруемыми, фасетными или сортируемыми. Они также не могут иметь анализаторы, нормализаторы или назначения отображения синонимов.
Для свойства dimensions должно быть задано количество встраиваний, созданных моделью встраиваний. Например, text-embedding-ada-002 создает 1\u00A0536 эмбеддингов для каждого блока текста.
Векторные поля индексируются с помощью алгоритмов, указанных в профиле векторного поиска, который определяется в другом месте индекса, а не показан в этом примере. Дополнительные сведения см. в разделе "Добавление конфигурации векторного поиска".
Коллекция полей для базовых рабочих нагрузок векторов
Для индексов векторов требуется больше, чем просто векторных полей. Например, все индексы должны иметь ключевое поле, которое находится id в следующем примере:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Другие поля, такие как content поле, предоставляют удобочитаемый пользователем эквивалент content_vector поля. Если вы используете языковые модели исключительно для формулировки ответа, можно опустить поля содержимого невектора, но решения, которые помещают результаты поиска непосредственно в клиентские приложения, должны иметь невекторное содержимое.
Поля метаданных полезны для фильтров, особенно если они включают сведения о источнике исходного документа. Хотя вы не можете фильтровать непосредственно по полю вектора, можно задать режимы предварительной фильтрации, постфильтрации или строгой постфильтрации (предварительная версия) для фильтрации до или после выполнения векторного запроса.
Схема, созданная мастером импорта
Мы рекомендуем мастер импорта данных для оценки и проверки концепции. Мастер создает пример схемы в этом разделе.
Мастер разбивает содержимое на небольшие документы поиска, что приносит пользу приложениям RAG, использующим языковые модели для формирования ответов. Разделение на блоки помогает оставаться в пределах ввода языковых моделей и ограничений на количество токенов семантического ранжировщика. Он также повышает точность поиска по сходству путем сопоставления запросов к блокам, извлекаемым из нескольких родительских документов. Для получения дополнительной информации см. раздел "Разделение больших документов для решений векторного поиска".
Для каждого документа поиска в следующем примере существует один идентификатор блока, родительский идентификатор, блок, название и векторное поле. Мастер:
Заполняет поля
chunk_idиparent_idметаданными для большого двоичного объекта, закодированными в формате Base64 (путь).Извлекает поля
chunkиз содержимого BLOB-объекта иtitleиз имени соответственно.Создает поле
vectorпутем вызова модели встраивания Azure OpenAI для векторизации поляchunk. Только поле вектора полностью создается во время этого процесса.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Схема для генеративного поиска
Если вы разрабатываете векторное хранилище для приложений в стиле RAG и чата, можно создать два индекса:
- Один для статического содержимого, индексированного и векторизованного.
- Один для бесед, которые можно использовать в потоках запросов.
В целях иллюстрации в этом разделе используется chat-with-your-data-solution-accelerator для создания индексов chat-index и conversations.
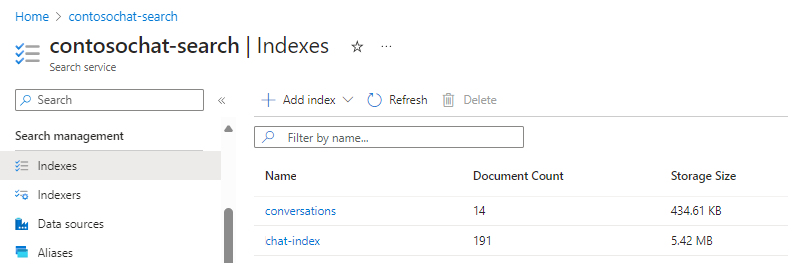
Следующие поля из chat-index поддерживают генеративные поисковые возможности:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Следующие поля из conversations поддерживают оркестрацию и историю чатов:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
На следующем снимке экрана показаны результаты conversations поиска в обозревателе поиска:
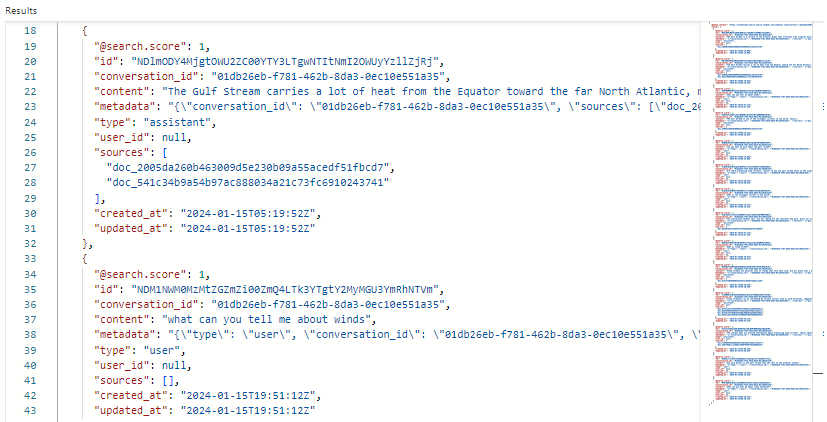
В нашем примере оценка поиска составляет 1,00, так как поиск неквалифицированный. Несколько полей поддерживают оркестрацию и потоки запросов:
-
conversation_idопределяет каждый сеанс чата. -
typeуказывает, является ли содержимое от пользователя или помощника. -
created_atиupdated_atудаляют чаты из истории.
Физическая структура и размер
В Поиск с использованием ИИ Azure физическая структура индекса в значительной степени является внутренней реализацией. Вы можете получить доступ к своей схеме, загрузить и запросить его содержимое, отслеживать его размер и управлять его емкостью. Однако Microsoft управляет инфраструктурой и физическими структурами данных, хранящимися в службе поиска.
Размер и вещество индекса определяются следующими способами:
Количество и состав документов.
Атрибуты для отдельных полей. Например, для фильтруемых полей требуется больше хранилища.
Конфигурация индекса, включая конфигурацию вектора, которая указывает, как создаются внутренние структуры навигации. Вы можете выбрать HNSW или исчерпывающий KNN для поиска сходства.
Поиск с использованием ИИ Azure накладывает ограничения на хранилище векторов, что помогает поддерживать сбалансированную и стабильную систему для всех рабочих нагрузок. Чтобы помочь вам оставаться в установленных пределах, использование векторов отслеживается и отдельно сообщается на портале Azure и в автоматизированном режиме через статистику служб и индексов.
На следующем снимке экрана показана служба S1, настроенная с одним разделом и одной репликой. Эта служба имеет 24 небольших индексов, каждый из которых имеет среднее значение одного векторного поля, состоящего из 1536 внедрения. На второй плитке показана квота и использование векторных индексов. Так как векторный индекс является внутренней структурой данных, созданной для каждого векторного поля, хранилище для векторных индексов всегда является частью общего хранилища, используемого индексом. Невекторные поля и другие структуры данных используют остальные.
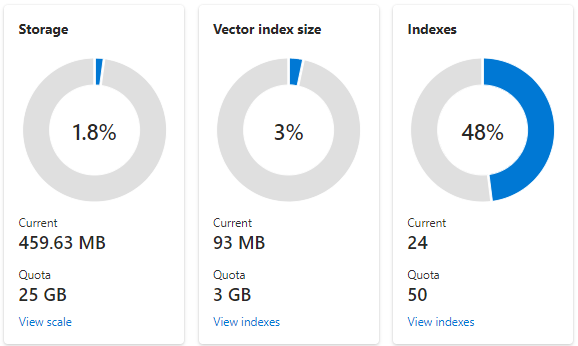
Ограничения и оценки векторных индексов рассматриваются в другой статье, но следует подчеркнуть два пункта: максимальное хранилище зависит от даты создания и от ценовой категории службы поиска. Более новые службы одного уровня имеют значительно больше емкости для векторных индексов. По этим причинам вам следует:
Проверьте дату создания службы поиска. Если услуга была создана до 3 апреля 2024 г., возможно, вы сможете обновить её для увеличения вместимости.
Выберите масштабируемый уровень , если вы ожидаете колебания требований к хранилищу векторов. Для старых служб поиска уровень "Базовый" зафиксирован на одном разделе. Рассмотрим стандарт 1 (S1) и выше для повышения гибкости и повышения производительности. Вы также можете переключаться между уровнями "Базовый" и "Стандартный" (S1, S2 и S3).
Основные операции и взаимодействие
В этом разделе приводятся операции среды выполнения векторов, включая подключение к одному индексу и защиту.
Примечание.
Нет поддержки портала или API для перемещения или копирования индекса. Как правило, вы либо указываете развертывание приложения на другую службу поиска (используя то же имя индекса), либо изменяете имя, чтобы создать копию в текущей службе поиска, а затем развернуть ее.
Изоляция индекса
В Поиск с использованием ИИ Azure одновременно работаете с одним индексом. Все операции, связанные с индексом, предназначены для одного индекса. Нет концепции связанных индексов или присоединения независимых индексов для индексирования или запроса.
Непрерывная доступность
Индекс сразу же доступен для запросов, как только первый документ индексируется, но он не полностью работает, пока все документы не индексируются. Внутри системы индекс распределяется по разделам и запускается на репликах. Физический индекс управляется внутренне. Вы управляете логическим индексом.
Индекс постоянно доступен и не может быть приостановлен или отключен. Так как он предназначен для непрерывной работы, обновления его содержимого и дополнения к самому индексу происходят в режиме реального времени. Если запрос совпадает с обновлением документа, запросы могут временно возвращать неполные результаты.
Непрерывность запросов существует для операций с документами, таких как обновление или удаление, а также для изменений, которые не влияют на существующую структуру или целостность индекса, например добавление новых полей. Структурные обновления, такие как изменение существующих полей, обычно управляются с помощью процесса удаления и восстановления в среде разработки или путем создания новой версии индекса в производственной службе.
Чтобы избежать перестроения индекса, некоторые клиенты, внося небольшие изменения, "версионируют" поле, создавая новое, которое сосуществует с предыдущей версией. Со временем это приводит к осиротевшему содержимому из-за устаревших полей и устаревших определений пользовательских анализаторов, особенно в производственном индексе, репликация которого обходится дорого. Эти проблемы можно устранить во время запланированных обновлений индекса в рамках управления жизненным циклом индекса.
Подключение к конечной точке
Все запросы индексирования и поисковые запросы направлены на индекс. Конечные точки обычно являются одним из следующих:
| Конечная точка | Управление подключением и доступом |
|---|---|
<your-service>.search.windows.net/indexes |
Нацелено на коллекцию индексов. Используется при создании, перечислении или удалении индекса. Права администратора необходимы для этих операций и доступны через ключи API администратора или роль участника поиска. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Ориентировано на коллекцию документов одного индекса. Используется при запросе индекса или обновления данных. Для запросов достаточно прав на чтение, которые доступны с помощью ключей API для запросов или роли чтения данных. Для обновления данных требуются права администратора. |
Подключение к Поиск с использованием ИИ Azure
Убедитесь, что у вас есть разрешения или ключ доступа к API. Если вы не запрашиваете существующий индекс, вам нужны права администратора или назначение роли участника для управления и просмотра содержимого в службе поиска.
Начните с портала Azure. Пользователь, создавший службу поиска, может просматривать и управлять им, включая предоставление доступа другим пользователям на странице управления доступом (IAM).
Перейдите к другим клиентам для программного доступа. Для первых шагов рекомендуется Quickstart: поиск вектора с помощью REST и репозитория azure-search-vector-samples.
Управление хранилищами векторов
Azure предоставляет платформу monitoring, которая включает ведение журнала диагностики и оповещения. Примите во внимание следующие рекомендации.
- Включите ведение журнала диагностики.
- Настройте оповещения.
- Анализ производительности запросов и индексов.
Безопасный доступ к векторным данным
Поиск с использованием ИИ Azure реализует шифрование данных, частные подключения для сценариев без Интернета и назначения ролей для безопасного доступа через Microsoft Entra ID. Дополнительные сведения о функциях корпоративной безопасности см. в разделе "Данные", "Конфиденциальность" и встроенные средства защиты.