Мониторинг и диагностика для Azure Service Fabric
В статье представлен обзор мониторинга и диагностики в Azure. Мониторинг и диагностика критически важны для разработки, тестирования и развертывания рабочих нагрузок в любой облачной среде. Например, вы можете отслеживать использование приложений, действия, предпринимаемые платформой Service Fabric, использование ресурсов (с помощью счетчиков производительности) и общую работоспособность кластера. Эту информацию можно использовать для диагностики и устранения проблем, а также для предотвращения их возникновения в будущем. В следующих разделах мы кратко расскажем о каждой области мониторинга Service Fabric для производственных рабочих нагрузок.
Примечание.
Сведения из данной статьи были недавно обновлены. Теперь вместо термина "Log Analytics" используется термин "журналы Azure Monitor". Данные журнала по-прежнему хранятся в рабочей области Log Analytics, собираются и анализируются той же службой Log Analytics. Целью обновления терминологии является лучшее отражение роли журналов в Azure Monitor. Дополнительные сведения см. в статье Изменения фирменной символики Azure Monitor.
Мониторинг приложений
В процессе мониторинга приложений фиксируются особенности использования возможностей и компонентов приложения. Он позволяет перехватить проблемы, влияющие на пользователей. Ответственность за мониторинг приложения лежит на пользователях, разрабатывающих приложение и его службы, так как он привязан к бизнес-логике приложения. Мониторинг приложений может оказаться полезным в следующих случаях.
- Какой трафик моего приложения? — Нужно ли масштабировать службы для удовлетворения потребностей пользователей или устранения потенциального узкого места в приложении?
- Выполняются и отслеживаются ли вызовы между службами?
- Какие действия предпринимают пользователи моего приложения? — При разработке новых функций и выявлении ошибок в приложении можно ориентироваться на данные телеметрии.
- Выдает ли мое приложение необработанные исключения?
- Что происходит в службах, выполняющихся в моих контейнерах?
Самое замечательное в мониторинге приложений — это то, что разработчики могут использовать любые инструменты и платформы, так как он выполняется в контексте приложения! Дополнительные сведения о решении Azure для мониторинга приложений с помощью Аналитика приложения Azure Monitor см. в разделе "Анализ событий" с помощью приложения Аналитика. У нас также есть руководство по настройке мониторинга для приложений .NET. Это руководство содержит инструкции по установке нужных инструментов и просмотру данных диагностики и телеметрии приложения на портале Azure, а также пример написания собственной телеметрии в приложении.
Мониторинг платформы (кластера)
Пользователь контролирует, какие данные телеметрии поступают из его приложения, так как он сам пишет код, но что насчет данных диагностики с платформы Service Fabric? Одна из целей создания Service Fabric — это обеспечение работы приложения в случае сбоев оборудования. Это достигается благодаря способности системных служб платформы обнаруживать проблемы с инфраструктурой и быстро выполнять отработку отказа рабочих нагрузок на другие узлы в кластере. Но в этом случае, что делать, если в самих системных службах есть проблемы? Или если при попытке развертывания или перемещения рабочей нагрузки нарушаются правила размещения служб? Диагностика Service Fabric обеспечит вас информацией об этих и других действиях, происходящих в вашем кластере. Примеры сценариев для мониторинга кластера:
Service Fabric предоставляет широкий набор готовых событий. Доступ к событиям Service Fabric можно получить через EventStore или операционный канал (канал событий, предоставляемый платформой).
Канал событий Service Fabric. В Windows доступ к событиям Service Fabric можно получить от одного поставщика трассировки событий Windows с набором соответствующих фильтров
logLevelKeywordFilters, использующихся для переключения между каналами "Рабочая среда" и "Данные и обмен сообщениями". Так отделяются исходящие события Service Fabric для фильтрации нужным образом. В Linux все события Service Fabric проходят через LTTng и помещаются в одну таблицу службы хранения, в которой они могут быть отфильтрованы нужным образом. Эти каналы содержат проверенные структурированные события, которые помогают лучше понять состояние вашего кластера. Диагностика включается по умолчанию в момент создания кластера, и при этом создается таблица службы хранилища Azure, в которую отправляются события, поступающие из всех каналов для последующего запроса.EventStore — это функция, предлагаемая этой платформой. Она предоставляет события платформы Service Fabric, доступные в Service Fabric Explorer, а также через REST API. Вы можете просмотреть моментальный снимок происходящих действий в кластере для каждой сущности, например для узла, службы или приложения, а также отправить запрос с учетом времени возникновения события. Вы также можете получить дополнительные сведения об EventStore, ознакомившись со статьей Общие сведения о службе EventStore.
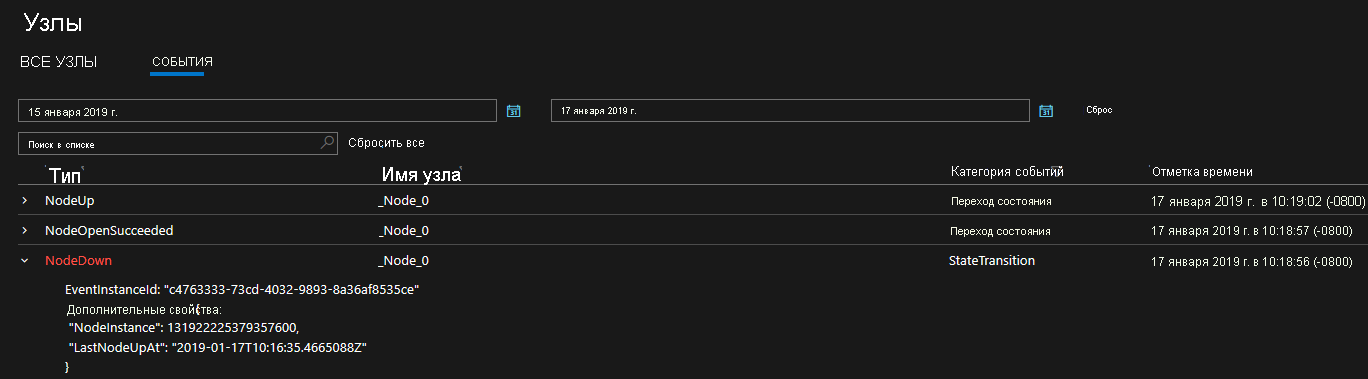
Предоставляемые данные диагностики имеют форму исчерпывающего набора событий. Эти события Service Fabric иллюстрируют действия, выполняемые платформой в различных сущностях, таких как узлы, приложения, службы, секции и т. д. В последнем из приведенных выше сценариев в случае остановки узла платформа выдаст событие NodeDown, и вы можете немедленно получить уведомление от выбранного средства мониторинга. Также во время отработки отказа часто издаются события ApplicationUpgradeRollbackStarted и PartitionReconfigured. Эти события доступны как для кластеров Windows, так и для кластеров Linux.
События отправляются по стандартным каналам как в Windows, так и в Linux и могут считываться любым средством мониторинга, которое их поддерживает. Решение Azure Monitor — журналы Azure Monitor. Вы можете узнать больше об интеграции журналов Azure Monitor, которая включает специальную панель мониторинга для кластера и примеры запросов, из которых можно создавать оповещения. Узнайте больше о создании событий и журналов на уровне платформы.
Мониторинг работоспособности
Платформа Service Fabric включает модель работоспособности, которая обеспечивает расширяемую отчетность о состоянии работоспособности сущностей в кластере. Каждый узел, приложение, служба, секция, реплика или экземпляр имеют постоянно обновляемое состояние работоспособности, которое может иметь значение "ОК", "Предупреждение" или "Ошибка". Думайте о событиях Service Fabric как о командах, выполняемых кластером с различными объектами, а о работоспособности как о характеристике каждого объекта. Событие также издается при каждом изменении работоспособности объекта. Таким образом, вы можете настроить запросы и оповещения для событий работоспособности в выбранном вами инструменте мониторинга, как и любое другое событие.
Кроме того, мы разрешаем пользователям переопределять работоспособность объектов. Если после обновления ваше приложение не проходит проверочные тесты, вы можете написать об этом в Service Fabric Health, используя API работоспособности, и Service Fabric автоматически откатит обновление! Чтобы узнать больше о модели работоспособности, прочитайте этот обзор.
Модули наблюдения
Как правило, модуль наблюдения является отдельной службой, которая может отслеживать работоспособность и нагрузку в службах, проверять связь с конечными точками и сообщать о непредвиденных событиях работоспособности в кластере. Он позволяет предотвратить ошибки, которые невозможно обнаружить только на основе производительности отдельной службы. В модулях наблюдения также удобно размещать код, выполняющий корректирующие действия, не требующие участия пользователя (например, очистку файлов журнала в хранилище через определенные интервалы времени). Если вам нужна полностью реализованная служба наблюдения Servie Fabric c открытым кодом, которая включает в себя простую в использовании модель расширяемости модулей наблюдения и работает в кластерах Windows и Linux, см. проект FabricObserver. FabricObserver — это готовое к использованию программное обеспечение. Мы рекомендуем развертывать FabricObserver в тестовых и рабочих кластерах и расширять его в соответствии с потребностями либо через модель подключаемых модулей, либо создав вилку и добавив собственные встроенные наблюдатели. Рекомендуется использовать первый подход (подключаемые модули).
Мониторинг инфраструктуры (производительности)
Теперь, когда мы рассмотрели диагностику в приложении и платформу, рассмотрим мониторинг оборудования. Мониторинг базовой инфраструктуры является ключевым в понимании состояния кластера и использовании ресурсов. Измерение производительности системы зависит от многих факторов, которые могут быть субъективными в зависимости от рабочих нагрузок. Эти факторы обычно измеряется с помощью счетчиков производительности. Они могут получать информацию из различных источников, включая операционную систему, платформу .NET Framework или платформу Service Fabric. Сценарии, в которых они будут полезны:
- Эффективно ли я использую свое оборудование? Вы хотите использовать оборудование на 90% или на 10% ресурсов ЦП? Это полезно при масштабировании кластера или оптимизации процессов приложения.
- Можно ли прогнозировать проблемы с инфраструктурой? — Возникновению многих проблем предшествуют внезапные изменения (снижения) производительности, поэтому для прогнозирования и диагностики таких проблем можно использовать счетчики производительности, такие как сетевые операции ввода-вывода и использование ЦП.
Список счетчиков производительности, которые необходимо собрать на уровне инфраструктуры, можно найти в статье Метрики производительности.
Service Fabric также предоставляет набор счетчиков производительности для моделей программирования Reliable Services и Reliable Actors. Если вы используете одну из этих моделей, эти счетчики производительности помогут гарантировать правильное развертывание и свертывание субъектов или достаточно быструю обработку запросов к надежным службам. Дополнительные сведения см. в разделе Счетчики производительности статьи "Диагностика и мониторинг производительности в модели Reliable Service Remoting" и разделе Счетчики производительности статьи "Диагностика и мониторинг производительности в Reliable Actors".
Решение Azure Monitor для сбора этих данных, как и для мониторинга на уровне платформы, — журналы Azure Monitor. Для сбора данных с соответствующих счетчиков производительности и их просмотра в журналах Azure Monitor используйте агент Log Analytics.
Рекомендуемые настройки
Теперь, когда мы рассмотрели каждую область мониторинга и примеры сценариев, перечислим инструменты мониторинга Azure с настройками, необходимыми для мониторинга всех указанных выше областей.
- Мониторинг приложений с помощью Application Insights
- Мониторинг кластеров с помощью агента диагностики и журналов Azure Monitor
- Мониторинг инфраструктуры с помощью журналов Azure Monitor
Для автоматизации развертывания всех необходимых ресурсов и агентов также можно использовать и изменять расположенный здесь шаблон ARM.
Другие решения для ведения журнала
Несмотря на то, что оба рекомендуемых решения — журналы Azure Monitor и Application Insights — обладают встроенными средствами интеграции с Service Fabric, регистрация многих событий производится поставщиками решений для трассировки событий Windows, и при этом их функциональность можно расширять с помощью других решений для регистрации событий в журналах. Стоит также обратить внимание на Elastic Stack (особенно если кластер будет выполняться в автономной среде), Dynatrace или любую другую платформу по вашему выбору. Здесь есть список интегрированных партнерских решений.
Основные моменты, на которые следует обратить внимание при выборе платформы: удобство пользовательского интерфейса, возможности запроса данных, доступные визуализации и панели мониторинга, а также наличие дополнительных инструментов для улучшения мониторинга.
Следующие шаги
- Сведения по инструментальному контролю приложений см. в статье Ведение журналов на уровне приложений и служб.
- Выполните процедуру настройки Application Insights для приложения, следуя указаниям в разделе Руководство. Мониторинг и диагностика приложения ASP.NET Core в Service Fabric.
- Дополнительные сведения о мониторинге платформы и событиях, предоставляемых Service Fabric, см. в статье Мониторинг кластера и платформы.
- Настройте интеграцию журналов Azure Monitor с Service Fabric: Настройка журналов Azure Monitor для кластера.
- Узнайте, как настроить журналы Azure Monitor для мониторинга контейнеров: Мониторинг контейнеров Windows в Service Fabric с помощью Azure Monitor.
- Примеры проблем и решений диагностики с помощью Service Fabric см. в описании диагностики типичных сценариев.
- Ознакомьтесь с другими продуктами диагностики, которые интегрируются с Service Fabric, в списке партнерских решений диагностики Service Fabric.
- Ознакомьтесь с общими рекомендациями по мониторингу ресурсов Azure в статье Мониторинг и диагностика.