Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье вы узнаете, как изменить существующую базу данных Lake в Azure Synapse с помощью конструктора баз данных. Конструктор баз данных позволяет легко создавать и развертывать базы данных без написания кода.
Предварительные требования
- Для создания базы данных Lake необходимо получить разрешения администратора или участника Synapse в рабочей области Synapse.
- Требуются разрешения "Участник для данных BLOB-объектов хранилища" для озера данных при использовании варианта создания таблицы Из озера данных.
Изменение свойств баз данных
В Главном концентраторе рабочей области Azure Synapse Analytics откройте вкладку Данные слева. Откроется вкладка Данные, на которой отобразится список баз данных, которые уже существуют в рабочей области.
Наведите указатель мыши на раздел Базы данных и нажмите кнопку с многоточием ... рядом с базой данных, которую необходимо изменить, а затем выберите Открыть.
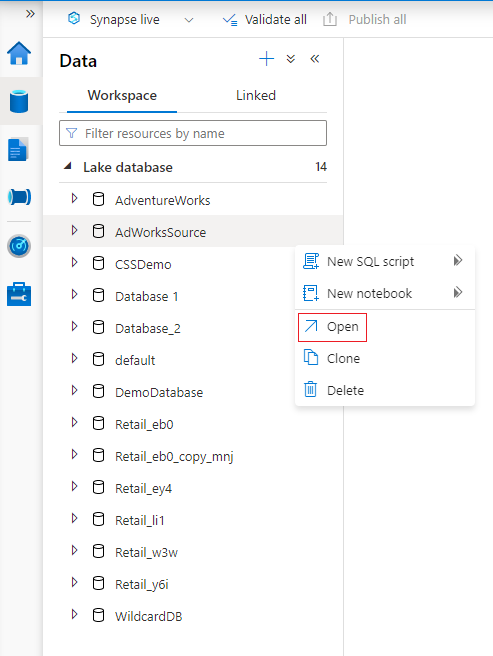
Откроется вкладка "Конструктор баз данных" с выбранной базой данных, загруженной на холст.
В конструкторе баз данных есть панель Свойств , которую можно открыть, щелкнув значок Свойства в правом верхнем углу вкладки.
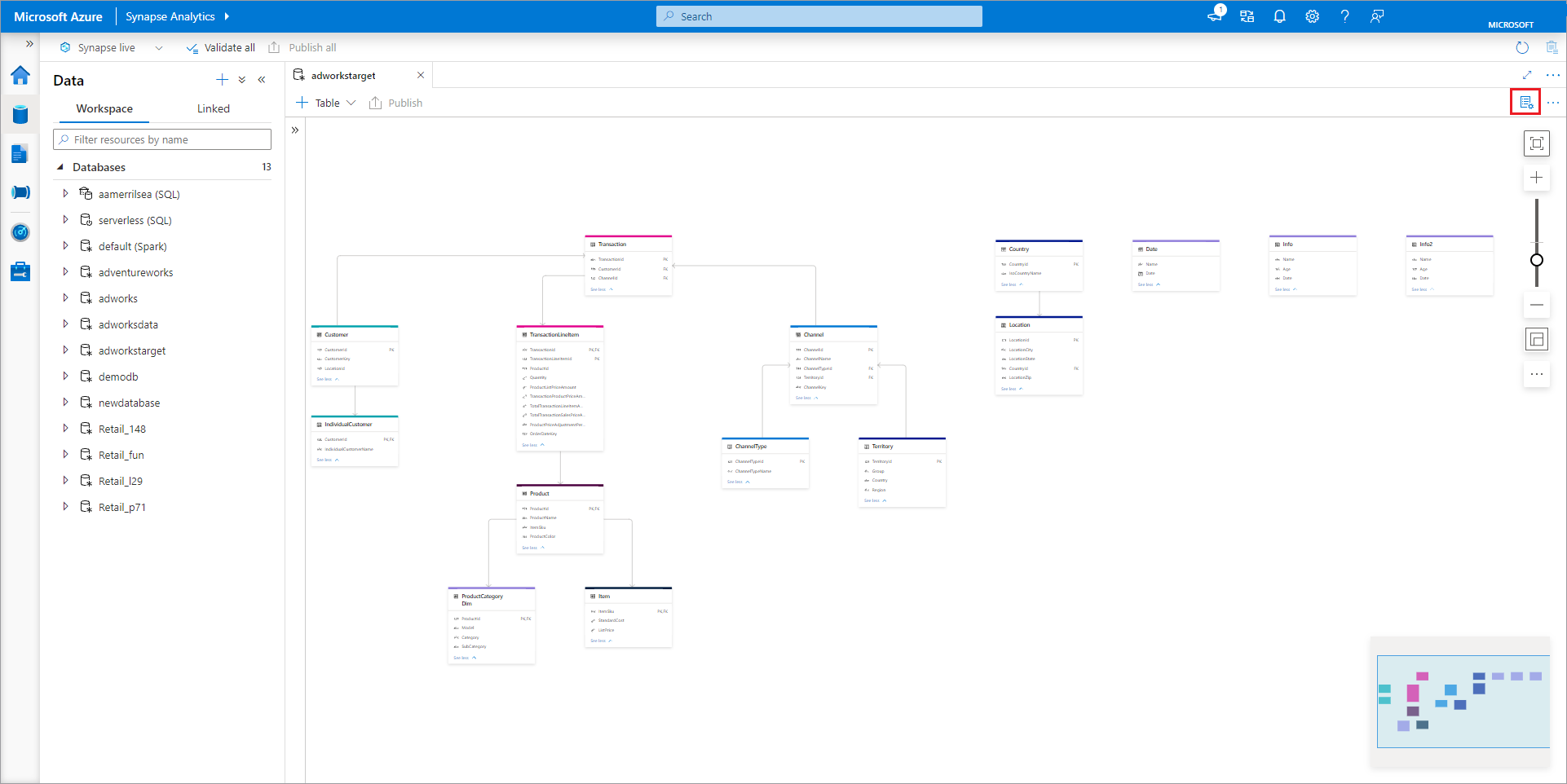
- Имя — имена не могут быть изменены после публикации базы данных, поэтому убедитесь, что имя выбрано правильно.
- Описание — указание описания базы данных является необязательным, но позволяет пользователям понять назначение базы данных.
- Параметры хранилища для базы данных — это раздел, содержащий сведения о хранилище по умолчанию для таблиц в базе данных. Параметры по умолчанию применяются к каждой таблице в базе данных, если она не переопределена в самой таблице.
- Связанная служба — это связанная служба по умолчанию, используемая для хранения данных в Azure Data Lake Storage. Отобразится служба по умолчанию, связанная с рабочей областью Synapse, но связанную службу можно изменить на любую учетную запись хранения ADLS.
- Входная папка, используемая для задания контейнера по умолчанию и пути к папке в связанной службе с использованием браузера файлов либо ручного изменения пути с помощью значка карандаша.
- Формат данных — базы данных Lake в Azure Synapse поддерживают Parquet и текст с разделителями в качестве форматов хранения данных.
Чтобы добавить таблицу в базу данных, нажмите кнопку + Таблица.
- Пользовательский — добавляет новую таблицу на холст.
- В шаблоне — открывается коллекция, в которой можно выбрать шаблон базы данных для использования при добавлении новой таблицы. Дополнительные сведения см. в разделе Создание базы данных Lake из шаблона базы данных.
- Из Data Lake позволяет импортировать схему таблицы с помощью данных, уже имеющихся в папке Lake.
Выберите Пользовательский. На холсте появится новая таблица с именем Table_1.
Затем можно настроить Table_1, включая имя таблицы, ее описание, параметры хранилища, столбцы и отношения. См. раздел "Настройка таблиц" в базе данных ниже.
Добавьте новую таблицу из Data Lake, выбрав + Таблица, а затем Из Data Lake.
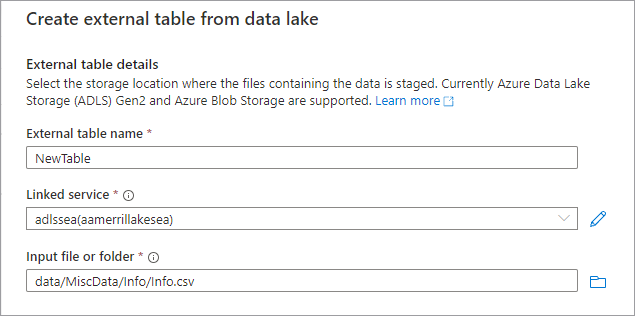
Появится панель Создание внешней таблицы из Data Lake. Укажите в панели приведенные ниже данные и выберите Продолжить.
- Имя внешней таблицы — имя, которое нужно присвоить создаваемой таблице.
- Связанная служба — связанная служба, содержащая расположение файла данных в Azure Data Lake Storage.
-
Входной файл или папка — используйте браузер файлов для перехода к файлу в Lake, с помощью которого нужно создать таблицу, и его выбора.
- На следующем экране можно выполнить предварительный просмотр файла в Azure Synapse и определить схему.
- Будет выполнен переход на страницу Новая внешняя таблица, где можно обновить все параметры, связанные с форматом данных, и Просмотр данных, чтобы проверить правильность определения файла в Azure Synapse.
- После установки необходимых параметров нажмите кнопку Создать.
- На холст будет добавлена новая таблица с выбранным именем, а в разделе Параметры хранилища для таблицы отобразится указанный файл.
Теперь, когда база данных настроена, ее можно опубликовать. Если вы используете интеграцию Git с рабочей областью Synapse, необходимо зафиксировать изменения и объединить их в ветвь совместной работы. Дополнительные сведения об управлении исходным кодом в Azure Synapse. Если вы используете режим Synapse Live, можно выбрать "Опубликовать".
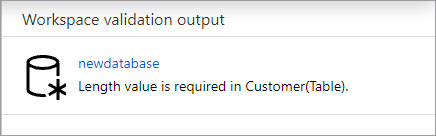
Перед публикацией база данных будет проверена на наличие ошибок. Все найденные ошибки отображаются на вкладке уведомлений с инструкциями по их устранению.
При публикации будет создана схема базы данных в Azure Synapse Metastore. После публикации объекты базы данных и таблицы будут видны другим службам Azure и будут обеспечивать передачу метаданных из базы данных в такие приложения, как Power BI и Microsoft Purview.
Настройка таблиц в базе данных
Конструктор баз данных позволяет настраивать все параметры таблиц в базе данных. При выборе таблицы доступны три вкладки, каждая из которых содержит параметры, связанные со схемой или метаданными таблицы.
Общие сведения
Вкладка Общие содержит сведения, относящиеся к самой таблице.
Имя — название таблицы. В качестве имени таблицы можно указать любое уникальное значение в пределах базы данных. Несколько таблиц с одинаковыми именами не допускаются.
Наследуется от (необязательно) это значение будет указано, если таблица создана из шаблона базы данных. Оно не может быть изменено и содержит информацию о том, на основе какого шаблона была создана данная таблица.
Описание — описание таблицы. Если таблица создана из шаблона базы данных, то это поле будет содержать описание концепции, используемой для этой таблицы. Это поле доступно для редактирования и может быть изменено в соответствии с описанием, которое соответствует вашим бизнес-требованиям.
Папка "Отображение" — имя папки бизнес-области, в которую помещена эта таблица как компонент шаблона базы данных. Для пользовательских таблиц в этом поле будет указано значение "Другое".
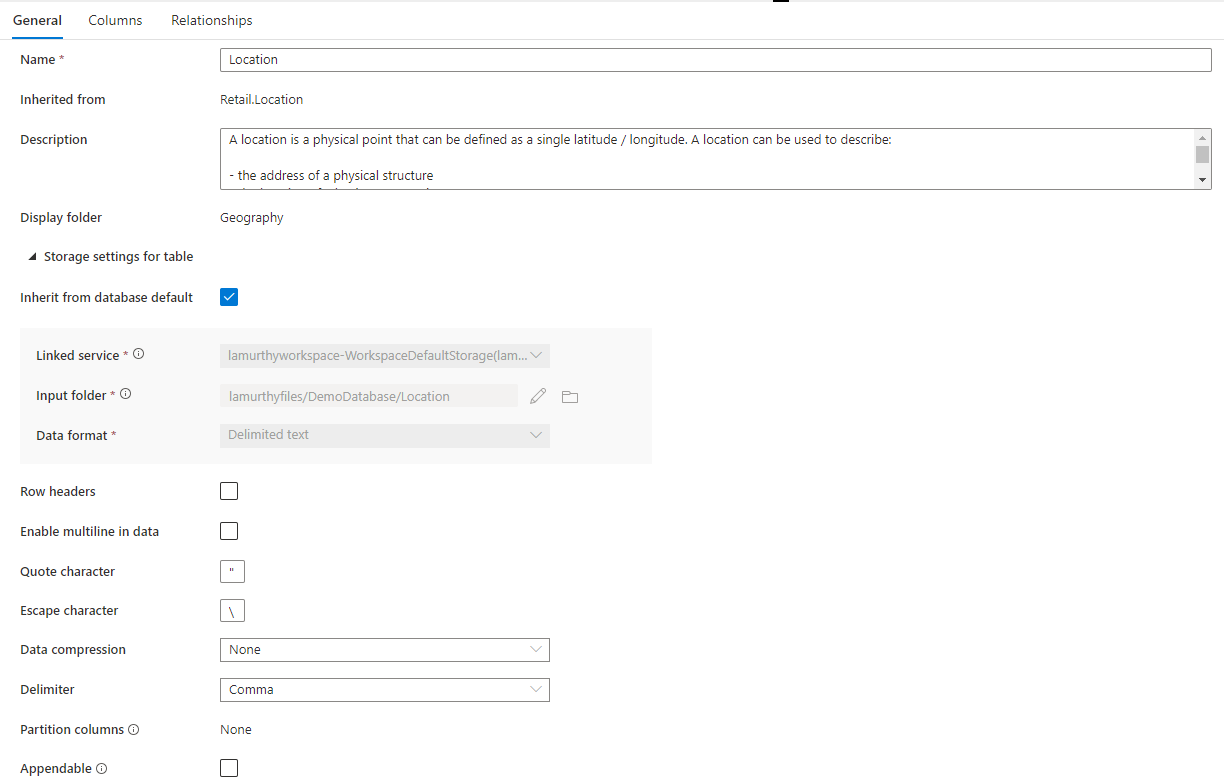
Кроме того, существует свертываемая область с именем Параметры хранения для таблицы, содержащая параметры для базовых сведений о хранилище, используемых в таблице.
Наследовать от базы данных по умолчанию — флажок, который определяет, наследуются ли приведенные ниже параметры хранилища от значений, заданных на вкладке Свойства базы данных, или должны быть заданы по отдельности. Если вы хотите установить собственные значения хранилища, снимите этот флажок.
- Связанная служба — это связанная служба по умолчанию, используемая для хранения данных в Azure Data Lake Storage. Измените это значение, чтобы выбрать другую учетную запись ADLS.
- Входная папка — папка в ADLS, куда будут помещены данные, загруженные в эту таблицу. Можно либо просмотреть расположение папки, либо изменить его вручную, используя значок карандаша.
- Формат данных — формат данных во Входной папке; в качестве форматов хранения данных в базах данных Lake в Azure Synapse можно использовать Parquet и текст с разделителями. Если формат данных не соответствует данным в папке, запросы к таблице завершатся ошибкой.
Если для параметра Формат данных задано значение "Текст с разделителями", доступны дополнительные параметры:
- Заголовки строк — установите этот флажок, если в данных есть заголовки строк.
- Включить многострочный режим данных — установите этот флажок, если данные содержат несколько строк в строковом столбце.
- Символ кавычек задает настраиваемый символ кавычек для текстового файла с разделителями.
- Escape-символ задает настраиваемый escape-символ для текстового файла с разделителями.
- Сжатие данных — тип сжатия, используемый для данных.
- Разделитель — разделитель полей, используемый в файлах данных. Поддерживаемые значения: запятая (,), знак табуляции (\t) и вертикальная черта (|).
- Столбцы секционирования — здесь отобразится список столбцов секционирования.
- Пополняемый — установите этот флажок, если вы запрашиваете данные Dataverse из бессерверной среды SQL.
Для данных Parquet доступны следующие параметры:
- Сжатие данных — тип сжатия, используемый для данных.
Столбцы
На вкладке Столбцы отображаются столбцы таблицы, которые можно изменить. На этой вкладке представлены два списка столбцов: Стандартные столбцы и Столбцы секционирования.
Стандартные столбцы — это любые столбцы, в которых хранятся данные, например первичный ключ, и которые не используются для секционирования данных. В Столбцах секционирования также хранятся данные, но они используются для секционирования базовых данных на папки на основе значений, содержащихся в столбцах. У каждого столбца есть следующие свойства.
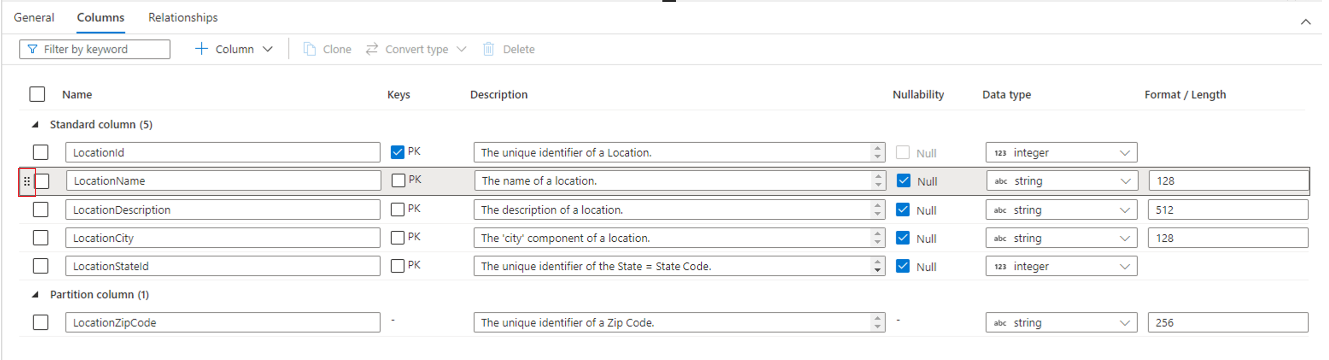
- Имя — название столбца. Должно быть уникальным внутри таблицы.
- Ключи указывает, является ли столбец первичным ключом (PK) и/или внешним ключом (FK) для таблицы. Неприменимо к столбцам секционирования.
- Описание — описание столбца. Если столбец был создан из шаблона базы данных, будет отображаться описание концепции, используемой для этого столбца. Это поле доступно для редактирования и может быть изменено в соответствии с описанием, которое соответствует вашим бизнес-требованиям.
- Допустимость значений NULL — указывает, допустимы ли в этом столбце значения NULL. Неприменимо к столбцам секционирования.
- Тип данных — задает тип данных для столбца на основе доступного списка типов данных Spark.
- Формат / длина — позволяет настраивать формат или максимальную длину столбца в зависимости от типа данных. Для типов данных "дата" и "метка времени" доступны раскрывающиеся списки с вариантами форматов, а другие типы, такие как "строка", ограничены в длине поля. Не все типы данных имеют значение, так как некоторые типы имеют фиксированную длину. В верхней части вкладки Столбцы находится панель команд, которую можно использовать для работы со столбцами.
- Фильтр по ключевому слову — фильтрует список столбцов для вывода элементов, соответствующих заданному ключевому слову.
-
+ Столбец — позволяет добавить новый столбец. Доступно три варианта.
- Создать столбец — создает новый настраиваемый стандартный столбец.
- Из шаблона — открывает панель просмотра и позволяет выбрать столбцы из шаблона базы данных для включения в таблицу. Если база данных создана без использования шаблона базы данных, этот параметр отображаться не будет.
- Столбец секционирования — добавляет новый пользовательский столбец секционирования.
- Клонировать — дублирует выбранный столбец. Клонированные столбцы всегда имеют тот же тип, что и выбранный столбец.
- Преобразовать тип — используется для изменения выбранного стандартного столбца на столбец секционирования и наоборот. Этот параметр будет неактивен, если выбрано несколько столбцов разных типов или если выбранный столбец недоступен для преобразования из-за установленного для столбца флажка PK или Допустимость значений NULL.
- Удалить — удаляет выбранные столбцы из таблицы. Это действие необратимо.
Вы также можете переупорядочить столбцы с помощью перетаскивания, используя двойные вертикальные многоточия, которые отображаются слева от имени столбца при наведении указателя мыши на столбец или при щелчке столбца, как показано на рисунке выше.
Столбцы секционирования
Столбцы секционирования используются для секционирования физических данных в базе данных на основе значений в этих столбцах. Столбцы секционирования позволяют легко распределять данные на диске в более эффективные блоки. Столбцы секционирования в Azure Synapse всегда находятся в конце схемы таблицы. Кроме того, при создании папок секционирования они используются в порядке сверху вниз. Например, если столбцы секционирования — Year и Month, то в итоге структура в ADLS будет иметь следующий вид:
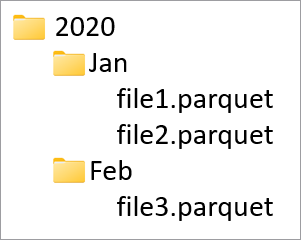
Где file1 и file2 содержали все строки, в которых значениями столбцов Year и Month были 2020 и Jan соответственно. По мере добавления в таблицу дополнительных столбцов секционирования в эту иерархию также будут добавляться файлы, что позволит уменьшить общий размер файлов разделов.
Azure Synapse не применяет или не создает эту иерархию путем добавления столбцов секционирования в таблицу. Чтобы создать структуру разделов, необходимо загрузить данные в таблицу с помощью Synapse Pipelines или записной книжки Spark.
Отношения
На вкладке "Отношения" можно указывать отношения между таблицами в базе данных. Отношения в конструкторе баз данных предназначены для информации и не накладывает ограничений на базовые данные. Их считывают другие приложения Майкрософт, которые можно использовать для ускорения преобразований или предоставления бизнес-пользователям сведений о способах подключения таблиц. Панель "Отношения" содержит следующие сведения.
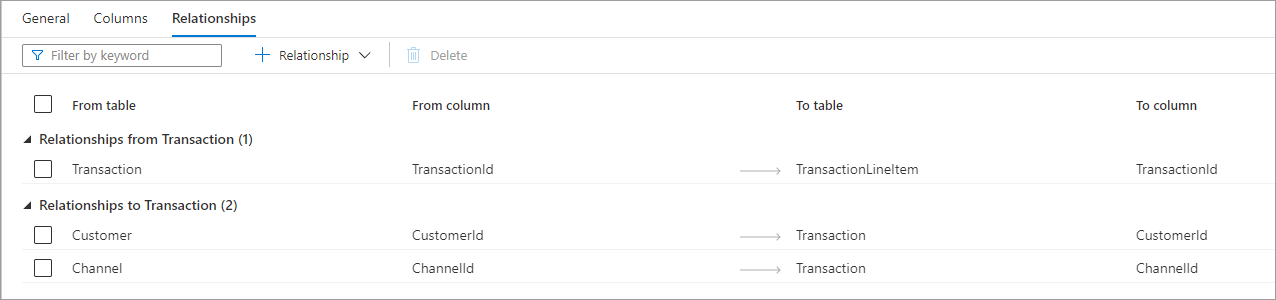
- Исходящие отношения (таблицы) — когда в одной или нескольких таблицах есть внешние ключи, подключенные к этой таблице. Иногда это отношение называется родительским.
- Входящие отношения (таблица) — когда таблица содержит внешний ключ и подключена к другой таблице. Иногда это отношение называется дочерним.
- Оба типа отношений имеют следующие свойства.
- Исходная таблица — родительская таблица в отношении или сторона "один".
- Исходный столбец — столбец в родительской таблице, на основе которого построено отношение.
- Целевая таблица — дочерняя таблица в отношении или сторона "многие".
- Целевой столбец — столбец в дочерней таблице, на основе которого построено отношение. В верхней части вкладки Отношения находится панель команд, которую можно использовать для работы с отношениями
- Фильтр по ключевому слову — фильтрует список столбцов для вывода элементов, соответствующих заданному ключевому слову.
-
+ Связь позволяет добавить новое отношение. Существует два варианта.
- Исходная таблица — создает новое отношение из таблицы, над которой вы работаете, с другой таблицей.
- Целевая таблица — создает новое отношение из другой таблицы с той, над которой вы работаете.
- Исходный шаблон — открывает панель просмотра и позволяет выбрать отношения в шаблоне базы данных для включения в базу данных. Если база данных создана без использования шаблона базы данных, этот параметр отображаться не будет.
Следующие шаги
Продолжайте изучение возможностей конструктора баз данных, используя приведенные ниже ссылки.