Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве вы используете записные книжки с средой выполнения Spark для преобразования и подготовки необработанных данных в lakehouse.
Prerequisites
Перед началом работы необходимо выполнить предыдущие уроки в этой серии:
- Создание озера
- Прием данных в лейкхаус
- Убедитесь, что схемы Lakehouse включены в ваш Lakehouse.
Подготовка данных
На предыдущих шагах руководства ваши необработанные данные были загружены из источника в разделе «Файлы» в lakehouse. Теперь вы можете преобразовать эти данные и подготовить его к созданию таблиц Delta.
Скачайте блокноты из папки Lakehouse Учебника Исходный код.
В браузере перейдите в рабочую область Fabric на портале Fabric.
Выберите "Импортировать>записную книжку>" на этом компьютере.
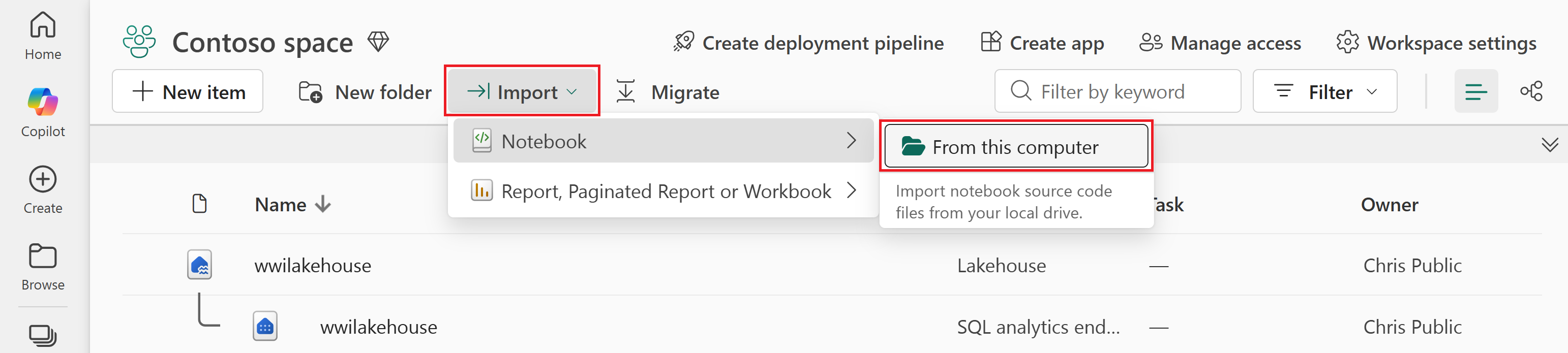
Выберите " Отправить" в области состояния импорта , которая откроется справа от экрана.
Выберите только записную книжку, соответствующую предпочитаемой языку программирования.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Выберите Открыть. Уведомление, указывающее состояние импорта, отображается в правом верхнем углу окна браузера.
После успешного импорта перейдите в представление элементов рабочей области, чтобы проверить импортированную записную книжку.
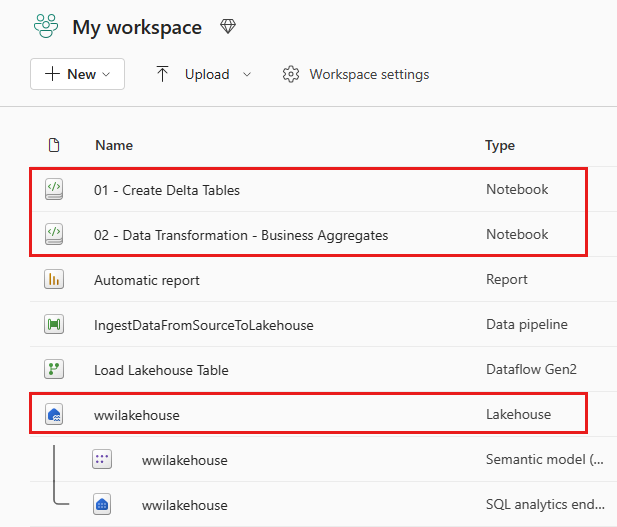
Выберите wwilakehouse, чтобы открыть его, чтобы следующая открытая вами записная книжка была связана с ним.
В верхнем меню навигации выберите "Открыть существующую записную книжку>".
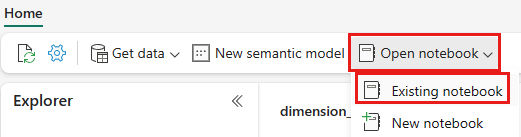
Выберите импортированную записную книжку для PySpark или Spark SQL и нажмите кнопку "Открыть". Записная книжка уже связана с открытым озерохранилищем, как показано в обозревателе озерохранилища.



Теперь вы готовы запустить ячейки в записной книжке, создающие и преобразующие ваши таблицы Delta.
В следующих разделах запускайте ячейки записной книжки последовательно. Чтобы выполнить ячейку, щелкните значок запуска , который отображается слева от ячейки на наведении указателя мыши. Вы также можете выбрать "Выполнить все" на верхней ленте (главная), чтобы запустить все ячейки в последовательности.
Это важно
В этом руководстве требуется включить схемы Lakehouse. Если схемы не включены, код в этом руководстве не будет работать должным образом.
В импортированной записной книжке отображаются разделы "Путь 1 " и "Путь 2 ". В этом руководстве используйте Путь 1 (включены схемы Lakehouse) и игнорируйте Путь 2 (схемы Lakehouse не включены).
Создание таблиц Delta
В этом разделе вы запустите ячейки записной книжки для создания таблиц Delta из необработанных данных.
Таблицы следуют схеме звездочек, которая является общим шаблоном для организации аналитических данных:
- Таблица фактов (
fact_sale) содержит измеримые события бизнеса — в данном случае отдельные сделки с объемами, ценами и прибылью. -
Таблицы измерений (
dimension_city, ,dimension_customer,dimension_datedimension_employeedimension_stock_item) содержат описательные атрибуты, которые дают контекст фактам, таким как место, где произошла продажа, кто сделал это, и когда.
На этой странице руководства выберите вкладку, которая соответствует импортированной записной книжке, и сохраните эту вкладку для всех шагов. Вкладки находятся в этой статье, а не в записной книжке.
Ячейка 1 — конфигурация сеанса Spark. Эта ячейка включает две функции Fabric, которые оптимизируют запись и чтение данных в последующих ячейках. V-order оптимизирует макет файла Parquet для ускорения чтения и улучшения сжатия. Оптимизация записи уменьшает количество записанных файлов и увеличивает размер отдельного файла.
Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
Ячейка 2 - Факт - Продажа. Эта ячейка считывает необработанные данные Parquet из
Files/wwi-raw-data/full/fact_sale_1y_full, добавляет столбцы части даты (Год, Квартал и Месяц), и записываетfact_saleв виде таблицы Delta, разбитой по Году и Кварталу.Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Ячейка 3 — измерения. Эта ячейка считывает пять наборов данных формата parquet по измерениям и записывает их в виде разностных таблиц (
dimension_city,dimension_customer,dimension_date,dimension_employee, иdimension_stock_item) подTables/dbo/....Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
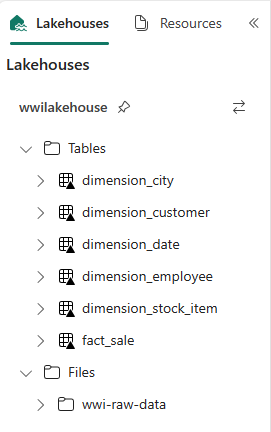
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Чтобы проверить созданные таблицы, щелкните правой кнопкой мыши хранилище данных wwilakehouse в обозревателе и выберите Обновить. Отображаются таблицы.

Преобразование данных для бизнес-агрегатов
В этом разделе вы продолжаете работу в той же записной книжке и запускаете следующие ячейки, чтобы создать агрегированные таблицы из таблиц Delta, созданных в предыдущем разделе.
Убедитесь, что записная книжка по-прежнему связана с wwilakehouse.
Ячейка 4 . Загрузка исходных таблиц для преобразования (только PySpark). Если вы используете записную книжку PySpark, запустите эту ячейку, чтобы загрузить Delta таблицы в DataFrames для последующих шагов агрегирования.
Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
Ячейка 5 — создайте
aggregate_sale_by_date_city. Эта ячейка присоединяет данные о продажах, дате и городе, а затем создает агрегированную таблицу на уровне города.Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Ячейка 6 - Создайте
aggregate_sale_by_date_employee. Эта ячейка присоединяет данные о продажах, дате и сотрудниках, а затем создает агрегированную таблицу уровня сотрудника.Запустите эту ячейку и дождитесь завершения, прежде чем перейти к следующему шагу.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Чтобы проверить созданные таблицы, щелкните правой кнопкой мыши хранилище данных wwilakehouse в обозревателе и выберите Обновить. Отображаются агрегированные таблицы.

В этом руководстве данные записываются в формате файлов Delta Lake. Структура автоматически обнаруживает и регистрирует эти таблицы в хранилище метаданных, поэтому не требуется выполнять отдельные CREATE TABLE инструкции.