Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Использование действия Список строк для получения сразу нескольких строк из Microsoft Dataverse со структурированным запросом.
Получение списка строк
Выполните следующие действия, чтобы добавить действие Список строк для вашего потока, чтобы вернуть до 5000 учетных записей из таблицы Учетные записи в Dataverse.
Power Automate позволяет использовать новый конструктор или классический конструктор для настройки облачного потока. Шаги схожи в обоих конструкторах. Подробнее (с примерами) см. в статье Определение различий между новым конструктором и классическим конструктором.
- Выберите знак плюса (+) >Добавить действие.
- На экране Добавить действие введите список строк в поле Поиск.
- В разделе Microsoft Dataverse выберите Список строк (предварительная версия).
- На вкладке Параметры слева выберите Организации в раскрывающемся меню Имя таблицы.
- Закройте экран, выбрав (<<).
Включите разбиение на страницы, чтобы запрашивать более 5000 строк
Чтобы автоматически получать более 5000 строк из запроса, включите функцию Разбиение на страницы в разделе Параметры.
Если задана разбивка на страницы и количество строк превышает установленное пороговое значение, ответ не будет включать параметр @odata.nextLink для запроса следующего набора строк. Отключите разбивку на страницы, чтобы ответ включал параметр @odata.nextLink, который можно использовать для запроса следующего набора строк. Перейдите в раздел Игнорируемый токен, чтобы узнать, как его использовать.
Ограничения пропускной способности контента и ограничения на размер сообщения применяются для обеспечения общих гарантий обслуживания.
Выберите карточку Список строк.
На панели слева выберите вкладку Настройки>Сеть.
Переместите ползунок Разбиение на страницы в положение Вкл., если оно еще не включен.
Введите Порог, укажите максимальное количество зарегистрированных строк. Максимальный настраиваемый порог — 100 000.
Внутренне это число округляется с шагом, равным размеру страницы по умолчанию. Например, если размер страницы составляет 5000, а вы вводите 7000, количество возвращаемых строк будет равно 10 000.
Дополнительные параметры
Расширенные параметры для действие Список строк позволяет сортировать, фильтровать, упорядочивать и расширять результаты запроса.
Вы можете установить параметры на панели конфигурации действий.
Чтобы увидеть параметры, выберите карточку Список строк.
На вкладке Параметры выберите дополнительные параметры в раскрывающемся списке Добавить новые параметры.
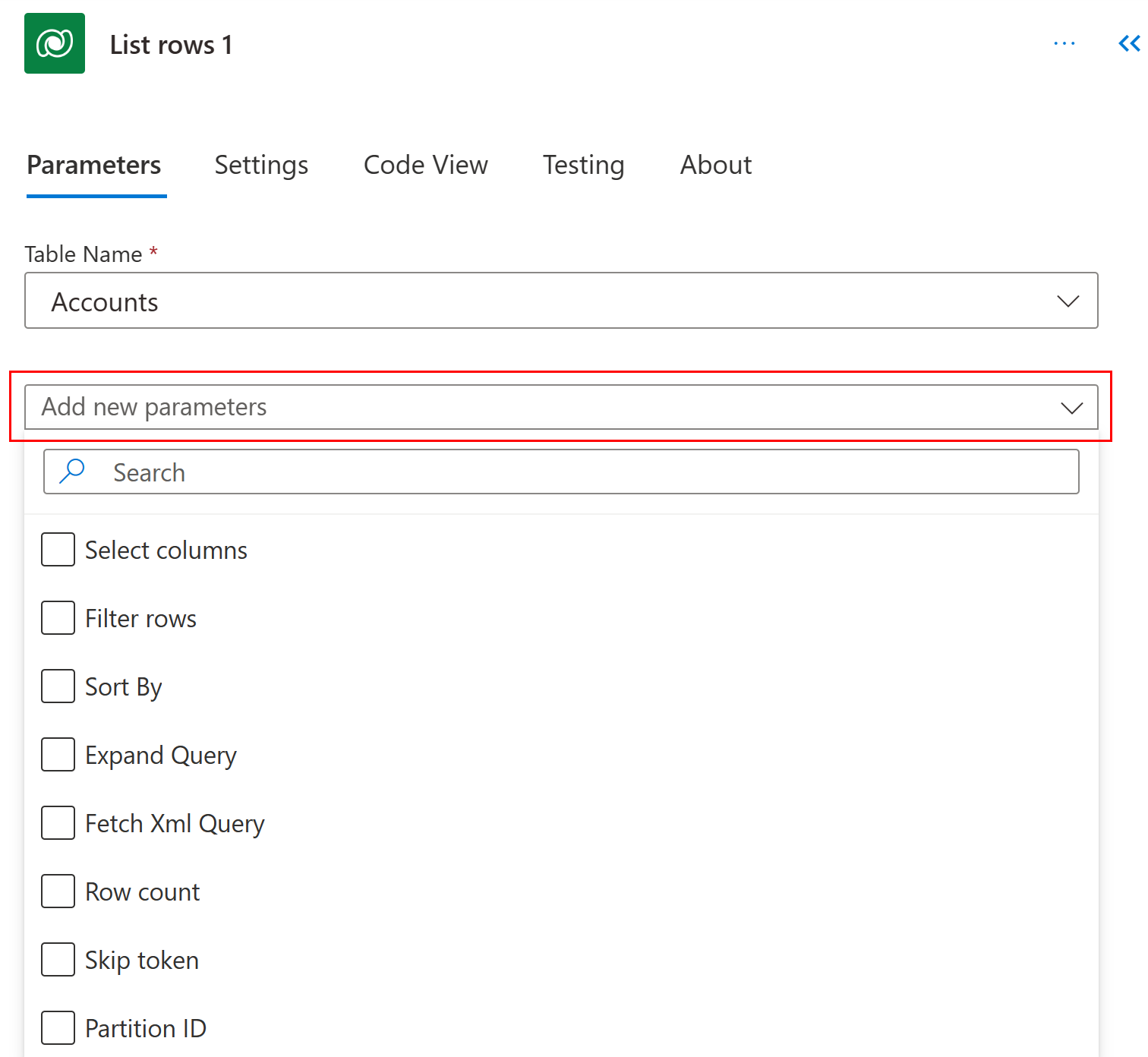
Выбор столбцов
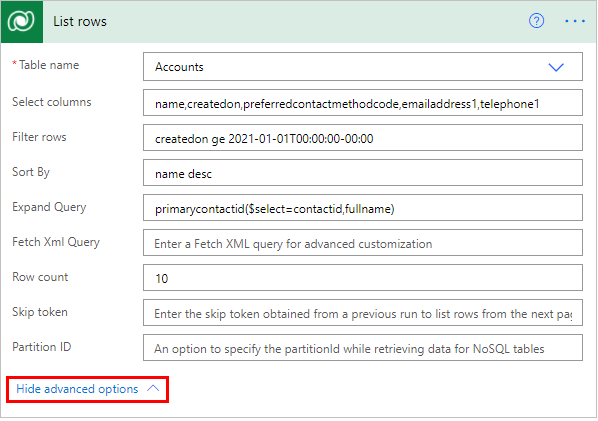
Введите список возвращаемых столбцов, разделенных запятыми, например «name,createdon,preferredcontactmethodcode,emailaddress1,telephone1» для таблицы «Организация».
Фильтровать строки
Используйте для определения выражения фильтра в стиле OData, чтобы сузить набор строк, которые возвращает Dataverse, например "createdon ge 2021-01-01T00:00:00-00:00" для строк, где значение createdon больше или равно 2021 году.
Узнайте, как использовать стандартные операторы фильтра и функции запроса для создания выражений Запрос на фильтрацию.
Некоторые символы, такие как &, # и +, необходимо заменить их эквивалентом в URL-кодировке. Дополнительная информация: URL-кодирование специальных символов
Внимание
Выражения фильтра не могут содержать эту строку $filter=, потому что это применимо только тогда, когда вы напрямую используете API-интерфейс.
Сортировать по
Используйте для определения выражения в стиле OData, которое определяет порядок, в котором возвращаются элементы, например «name desc». Используйте суффикс asc или desc для обозначения порядка возрастания или убывания соответственно. По умолчанию используется восходящий порядок.
Развернуть запрос
Используйте для указания выражения в стиле OData, определяющего данные, которые возвращает Dataverse из связанных таблиц, таких как primarycontactid($select=contactid,fullname) для использования primarycontactid организации для получения столбца fullname из связанного контакта с кодом contactid в ответе.
Есть два типа свойств навигации, которые вы можете использовать в Развернуть запрос:
Свойства навигации Однозначный соответствуют столбцам подстановки, которые поддерживают отношения "многие к одному" и позволяют установить ссылку на другую таблицу.
Свойства навигации Значение коллекции соответствуют отношениям "один ко многим" или "многие ко многим".
Если вы включите только имя свойства навигации, вы получите все свойства для связанных строк. Чтобы узнать больше, см. Получение строк связанных таблиц с запросом.
Чтобы использовать его в шаге потока, введите это выражение Odata в поле Развернуть запрос: primarycontactid(contactid,fullname). Здесь показано, как получить столбцы contactid и fullname для primarycontactid каждой организации.
Количество строк
Используйте, чтобы указать конкретное количество строк, которые возвращает Dataverse. Вот пример, который показывает, как запросить 10 строк.
Запрос FetchXML
Запросы агрегирования в настоящее время не поддерживаются при использовании действия Список строк с запросами FetchXML. Однако отдельные операторы поддерживаются.
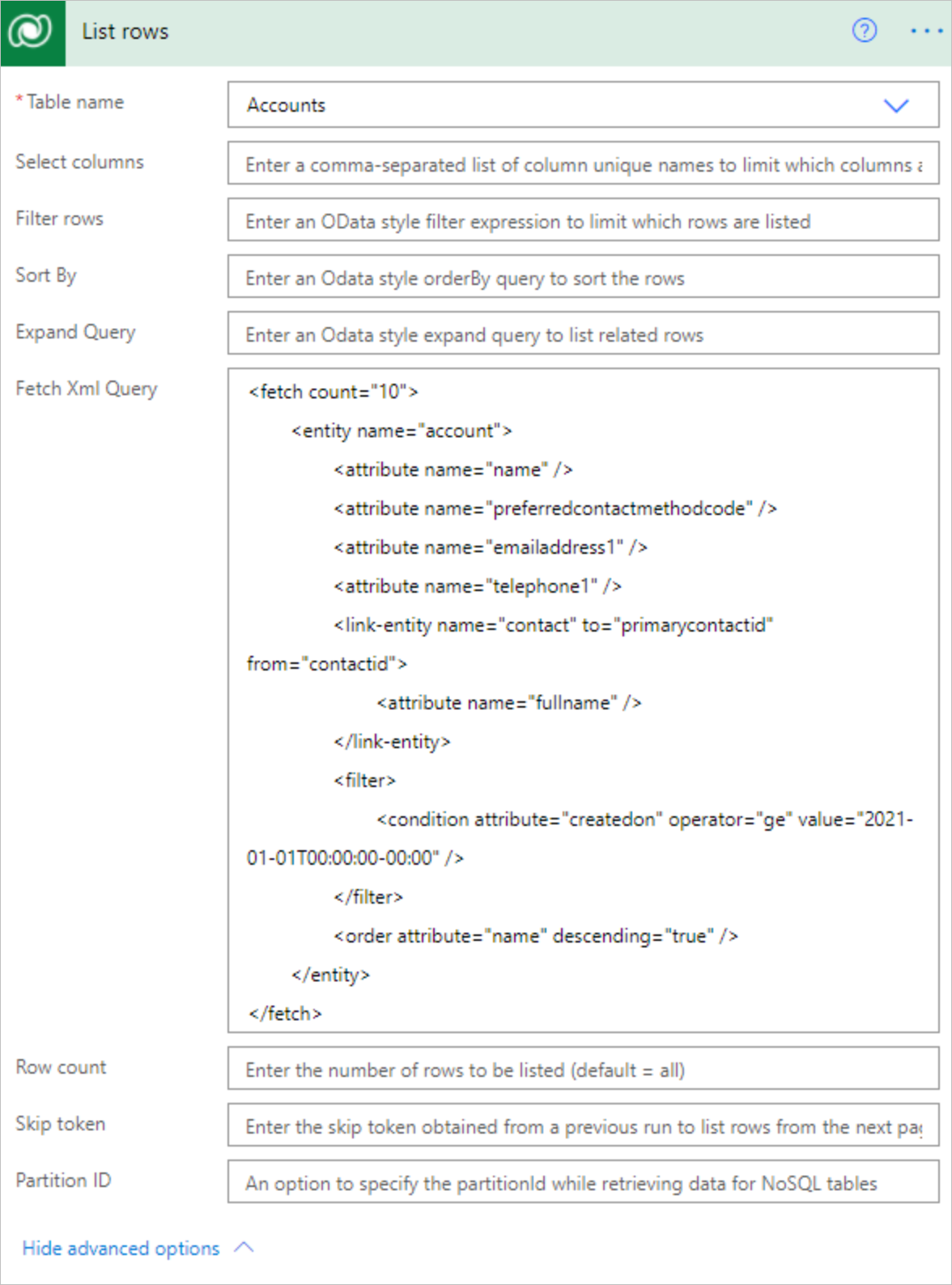
Используйте запрос FetchXML в стиле Dataverse, что обеспечивает больше гибкости при создании пользовательских запросов. Эти запросы могут быть полезны при работе с таблицей, имеющей несколько связанных таблиц, или при обработке разбиения на страницы. На следующем снимке экрана показано, как использовать FetchXML.
Пример запроса FetchXML для таблицы учетных записей:
<fetch count="10">
<entity name="account">
<attribute name="name" />
<attribute name="preferredcontactmethodcode" />
<attribute name="emailaddress1" />
<attribute name="telephone1" />
<link-entity name="contact" to="primarycontactid" from="contactid">
<attribute name="fullname" />
</link-entity>
<filter>
<condition attribute="createdon" operator="ge" value="2021-01-01T00:00:00-00:00" />
</filter>
<order attribute="name" descending="true" />
</entity>
</fetch>
Поскольку отдельный оператор в настоящее время не поддерживается напрямую в запросах FetchXML из действия списка строк, функцию объединения можно использовать для удаления повторяющихся строк. Например, вы можете использовать Выберите действие, чтобы преобразовать ответ соединения строк списка в нужный вам формат массива, затем создайте переменную с выражением union(body(‘Select’),body(‘Select’)), чтобы получить массив с отдельными строками.
Игнорируемый токен
Поскольку Power Automate применяет ограничения пропускной способности контента и ограничения на размер сообщения для обеспечения общих гарантий службы, часто бывает полезно использовать разбивку на страницы, чтобы вернуть меньшее количество строк в пакете, а не ограничения на количество возвращаемых строк таблиц по умолчанию.
Ограничение страницы по умолчанию в 5000 строк применяется, если вы не используете разбиение на страницы.
Чтобы использовать ее, реализуйте цикл для анализа значения odata.nextLink в ответе JSON, извлеките игнорируемый токен, затем отправьте еще один запрос, пока не будет перечислено необходимое количество строк.
HTTP/1.1 200 OK
Content-Type: application/json; odata.metadata=minimal
OData-Version: 4.0
Content-Length: 402
Preference-Applied: odata.maxpagesize=3
{
"@odata.context":"[Organization URI]/api/data/v9.1/$metadata#accounts(name)",
"value":[
{
"@odata.etag":"W/\"437194\"",
"name":"Fourth Coffee (sample)",
"accountid":"7d51925c-cde2-e411-80db-00155d2a68cb"
},
{
"@odata.etag":"W/\"437195\"",
"name":"Litware, Inc. (sample)",
"accountid":"7f51925c-cde2-e411-80db-00155d2a68cb"
},
{
"@odata.etag":"W/\"468026\"",
"name":"Adventure Works (sample)",
"accountid":"8151925c-cde2-e411-80db-00155d2a68cb"
}
],
"@odata.nextLink":"[Organization URI]/api/data/v9.1/accounts?$select=name&$skiptoken=%3Ccookie%20pagenumber=%222%22%20pagingcookie=%22%253ccookie%2520page%253d%25221%2522%253e%253caccountid%2520last%253d%2522%257b8151925C-CDE2-E411-80DB-00155D2A68CB%257d%2522%2520first%253d%2522%257b7D51925C-CDE2-E411-80DB-00155D2A68CB%257d%2522%2520%252f%253e%253c%252fcookie%253e%22%20/%3E"
}
ИД раздела
Параметр для задания partitionId при извлечении данных для таблиц NoSQL. Чтобы узнать больше, см. раздел Повышение производительности с помощью разделов хранилища при доступе к данным таблицы.