Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Потоки данных Power BI — это решение подготовки данных, ориентированное на предприятие, которое позволяет экосистеме данных, готовых к использованию, повторному использованию и интеграции. В этой статье представлены некоторые распространенные сценарии, ссылки на статьи и другие сведения, которые помогут вам понять и использовать потоки данных в полной мере.
Получение доступа к функциям потоков данных класса Premium
Потоки данных Power BI в емкостях Premium предоставляют множество ключевых функций, которые помогают повысить масштаб и производительность потоков данных, например:
- Расширенные вычислительные ресурсы, которые ускоряют производительность ETL и предоставляют возможности DirectQuery.
- Добавочное обновление, которое позволяет загружать данные, измененные из источника.
- Связанные сущности, которые можно использовать для ссылки на другие потоки данных.
- Вычисляемые сущности, которые можно использовать для создания составных стандартных блоков потоков данных, содержащих больше бизнес-логики.
По этим причинам рекомендуется использовать потоки данных в емкости Premium по возможности. Потоки данных, используемые в лицензии Power BI Pro, можно использовать для простых, небольших вариантов использования.
Решение
Доступ к этим функциям потоков данных класса Premium можно получить двумя способами:
- Назначьте емкость Premium для данной рабочей области и приведите собственную лицензию Pro для создания потоков данных здесь.
- Принесите собственную лицензию Premium на пользователя (PPU), которая требует, чтобы другие члены рабочей области также имели лицензию PPU.
Потоки данных PPU (или другое содержимое) нельзя использовать вне среды PPU (например, в классах Premium или других номерах SKU или лицензиях).
Для емкостей Premium потребители потоков данных в Power BI Desktop не нуждаются в явных лицензиях для использования и публикации в Power BI. Но для публикации в рабочей области или совместного использования результирующей семантической модели требуется по крайней мере лицензия Pro.
Для PPU каждый пользователь, создающий или использующий содержимое PPU, должен иметь лицензию PPU. Это требование зависит от остальной части Power BI в том, что необходимо явно лицензировать всех пользователей с PPU. Вы не можете смешивать емкости Free, Pro или Premium с содержимым PPU, если вы не переносите рабочую область в емкость Premium.
Выбор модели обычно зависит от размера и целей вашей организации, но применяются следующие рекомендации.
| Тип команды | Premium по емкости | Premium на пользователя |
|---|---|---|
| >5 000 пользователей | ✔ | |
| <5 000 пользователей | ✔ |
Для небольших команд PPU может преодолеть разрыв между Free, Pro и Premium на емкость. Если у вас есть более крупные потребности, использование емкости Premium с пользователями, имеющими лицензии Pro, является лучшим подходом.
Создание потоков данных пользователей с применением безопасности
Представьте, что необходимо создать потоки данных для потребления, но у вас есть требования к безопасности:
В этом сценарии, скорее всего, есть два типа рабочих областей:
Внутренние рабочие области, в которых вы разрабатываете потоки данных и создаете бизнес-логику.
Рабочие области пользователей, в которых требуется предоставить некоторые потоки данных или таблицы определенной группе пользователей для использования:
- Рабочая область пользователя содержит связанные таблицы, указывающие на потоки данных в серверной рабочей области.
- Пользователи имеют доступ к рабочей области потребителя и не имеют доступа к внутренней рабочей области.
- Когда пользователь использует Power BI Desktop для доступа к потоку данных в рабочей области пользователя, он может видеть поток данных. Но поскольку поток данных отображается пустым в навигаторе, связанные таблицы не отображаются.
Общие сведения о связанных таблицах
Связанные таблицы — это просто указатель на исходные таблицы потоков данных, и они наследуют разрешение источника. Если Power BI разрешила связанной таблице использовать разрешение назначения, любой пользователь может обойти разрешение источника, создав связанную таблицу в назначении, которая указывает на источник.
Решение. Использование вычисляемых таблиц
Если у вас есть доступ к Power BI Premium, вы можете создать вычисляемую таблицу в назначении, которая ссылается на связанную таблицу, которая содержит копию данных из связанной таблицы. Можно удалить столбцы через проекции и удалить строки с помощью фильтров. Пользователь с разрешением на целевую рабочую область может получить доступ к данным через эту таблицу.
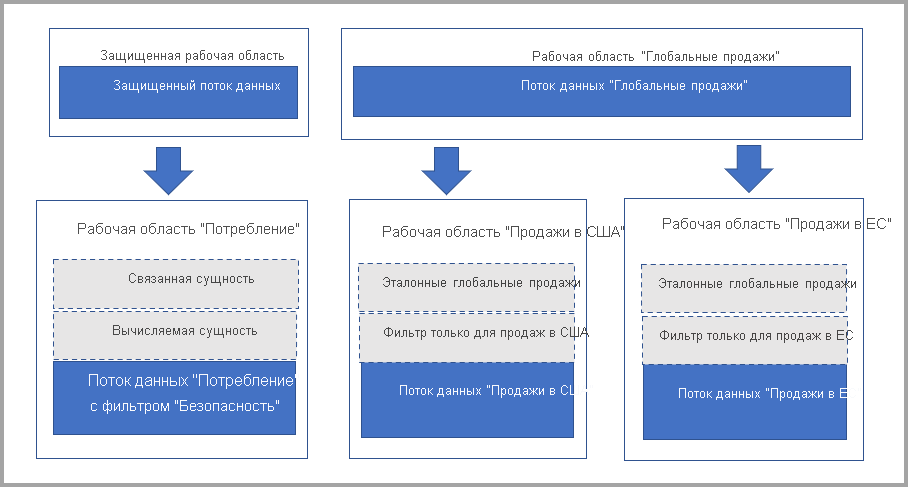
Строка для привилегированных пользователей также отображает указанную рабочую область и позволяет пользователям полностью понять родительский поток данных. Для тех пользователей, которые не являются привилегированными, конфиденциальность по-прежнему уважается. Отображается только имя рабочей области.
На следующей схеме показана эта настройка. Слева — это архитектурный шаблон. Справа показан пример разделения и защиты данных о продажах по регионам.
Сокращение времени обновления для потоков данных
Представьте, что у вас есть большой поток данных, но вы хотите создать семантические модели из этого потока данных и уменьшить время, необходимое для обновления. Как правило, обновление занимает много времени, чтобы завершить работу из источника данных в потоки данных в семантику модели. Длительные обновления трудно управлять или поддерживать.
Решение. Использование таблиц с параметром Enable Load явно настроено для ссылочных таблиц и не отключает нагрузку
Power BI поддерживает простую оркестрацию потоков данных, как определено в определении и оптимизации обновлений потоков данных. Для использования преимуществ оркестрации требуется явное наличие всех подчиненных потоков данных, настроенных для включения загрузки.
Отключение нагрузки обычно подходит только в том случае, если затраты на загрузку дополнительных запросов отменяют преимущество сущности, с помощью которой вы разрабатываете.
Хотя отключение нагрузки означает, что Power BI не оценивает этот запрос при использовании в качестве ингредиентов, то есть, на которые ссылаются другие потоки данных, это также означает, что Power BI не обрабатывает его как существующую таблицу, в которой можно указать указатель и выполнять оптимизацию свертывания и запроса. В этом смысле выполнение преобразований, таких как соединение или слияние, — это просто соединение или слияние двух запросов источника данных. Такие операции могут негативно повлиять на производительность, так как Power BI должна полностью перезагрузить уже вычисляемую логику, а затем применить любую более логику.
Чтобы упростить обработку запросов потока данных и убедиться, что выполняются все оптимизации подсистемы, включите нагрузку и убедитесь, что вычислительный модуль в потоках данных Power BI Premium установлен в параметре по умолчанию, который оптимизирован.
Включение загрузки также позволяет сохранить полное представление происхождения, так как Power BI рассматривает не включенный поток данных в качестве нового элемента. Если для вас важно, не отключите нагрузку для сущностей или потоков данных, подключенных к другим потокам данных.
Сокращение времени обновления для семантических моделей
Представьте, что у вас есть большой поток данных, но вы хотите создать семантические модели из него и уменьшить оркестрацию. Обновление занимает много времени, чтобы завершить работу из источника данных в потоки данных в семантические модели, что повышает задержку.
Решение. Использование потоков данных DirectQuery
DirectQuery можно использовать всякий раз, когда параметр расширенной вычислительной подсистемы рабочей области (ECE) настраивается явным образом в значение On. Этот параметр полезен, если у вас есть данные, которые не нужно загружать непосредственно в модель Power BI. Если вы впервые настраиваете функцию "Включено" ДЛЯ СИСТЕМЫ, изменения, позволяющие DirectQuery выполнять во время следующего обновления. При включении изменения необходимо обновить его немедленно. Обновление начальной нагрузки потока данных может быть медленнее, так как Power BI записывает данные как в хранилище, так и в управляемый обработчик SQL.
Чтобы свести итог, с помощью DirectQuery с потоками данных можно улучшить процессы Power BI и потоков данных:
- Избегайте отдельных расписаний обновления: DirectQuery подключается непосредственно к потоку данных, что удаляет необходимость создания импортированной семантической модели. Таким образом, с помощью DirectQuery с потоками данных больше не требуется отдельное расписание обновления для потока данных и семантической модели, чтобы убедиться, что данные синхронизированы.
- Фильтрация данных: DirectQuery полезна для работы с отфильтрованным представлением данных внутри потока данных. Если вы хотите отфильтровать данные и таким образом работать с меньшим подмножеством данных в потоке данных, вы можете использовать DirectQuery (и ЕКЕ) для фильтрации данных потока данных и работы с отфильтрованным подмножеством.
Как правило, использование DirectQuery торгует актуальными данными в семантической модели с более медленной производительностью отчета по сравнению с режимом импорта. Рассмотрим этот подход только в том случае, если:
- В вашем случае требуется низкая задержка данных, поступающих из потока данных.
- Данные потока данных большие.
- Импорт будет слишком трудоемким.
- Вы готовы торговать кэшируемыми производительностью для актуальных данных.
Решение. Использование соединителя потоков данных для включения свертывания запросов и добавочного обновления для импорта
Соединитель унифицированных потоков данных может значительно сократить время оценки для шагов, выполняемых над вычисляемыми сущностями, такими как выполнение соединений, отдельных, фильтров и группирования по операциям. Существует два конкретных преимущества:
- Подчиненные пользователи, подключающиеся к соединителю потоков данных в Power BI Desktop, могут воспользоваться преимуществами повышения производительности в сценариях разработки, так как новый соединитель поддерживает свертывание запросов.
- Операции обновления семантической модели также могут сложиться в расширенный вычислительный механизм, что означает, что даже добавочное обновление из семантической модели может сложиться в поток данных. Эта возможность повышает производительность обновления и потенциально уменьшает задержку между циклами обновления.
Чтобы включить эту функцию для любого потока данных класса Premium, убедитесь, что подсистема вычислений явно задана в значение On. Затем используйте соединитель потоков данных в Power BI Desktop. Для использования этой функции необходимо использовать версию Power BI Desktop за август 2021 г. или более позднюю версию.
Чтобы использовать эту функцию для существующих решений, необходимо использовать подписку Premium или Premium на пользователя. Также может потребоваться внести некоторые изменения в поток данных, как описано в разделе "Использование расширенного вычислительного модуля". Чтобы использовать новый соединитель, необходимо обновить все существующие запросы Power Query, заменив PowerBI.Dataflows его в ".
Сложный процесс разработки потока данных в Power Query
Представьте, что у вас есть поток данных, который представляет собой миллионы строк данных, но вы хотите создать сложную бизнес-логику и преобразования с ним. Вы хотите следовать рекомендациям по работе с большими потоками данных. Для быстрого выполнения предварительных версий потоков данных также требуются предварительные версии потока данных. Но у вас есть десятки столбцов и миллионы строк данных.
Решение. Использование представления схемы
Вы можете использовать представление схемы, которое предназначено для оптимизации потока при работе с операциями на уровне схемы путем размещения сведений о столбцах запроса в переднем и центре. Представление схемы обеспечивает контекстное взаимодействие для формирования структуры данных. Представление схемы также предоставляет операции с меньшей задержкой, так как требует вычисления только метаданных столбца, а не полных результатов данных.
Работа с большими источниками данных
Представьте, что вы выполняете запрос в исходной системе, но вы не хотите предоставлять прямой доступ к системе или демократизировать доступ. Вы планируете поместить его в поток данных.
Решение 1. Использование представления для запроса или оптимизация запроса
Использование оптимизированного источника данных и запроса — это лучший вариант. Часто источник данных лучше всего работает с запросами, предназначенными для него. Power Query перемещает возможности свертывания запросов для делегирования этих рабочих нагрузок. Power BI также предоставляет индикаторы свертывания шагов в Power Query Online. Дополнительные сведения о типах индикаторов см. в документации по индикаторам пошагового свертывания.
Решение 2. Использование собственного запроса
Вы также можете использовать функцию Value.NativeQuery() M. В третьем параметре задано значение EnableFolding=true . Собственный запрос задокументирован на этом веб-сайте для соединителя Postgres. Он также работает для соединителя SQL Server.
Решение 3. Разорвать поток данных на прием и потоки данных потребления, чтобы воспользоваться преимуществами СЛУЖБЕ и связанных сущностей.
Разбив поток данных в отдельные потоки данных приема и потребления, вы можете воспользоваться преимуществами служб "ЕХЕ" и "Связанные сущности". Дополнительные сведения об этом шаблоне и других возможностях см. в документации по рекомендациям.
Убедитесь, что клиенты используют потоки данных всякий раз, когда это возможно
Представьте, что у вас есть множество потоков данных, которые служат общим целям, таким как соответствующие измерения, такие как клиенты, таблицы данных, продукты и географические регионы. Потоки данных уже доступны на ленте для Power BI. В идеале клиенты хотят, чтобы клиенты в основном использовали созданные потоки данных.
Решение. Использование подтверждения для сертификации и повышения уровня потоков данных
Дополнительные сведения о том, как работает подтверждение, см. в статье "Одобрение" — продвижение и сертификация содержимого Power BI.
Программирование и автоматизация в потоках данных Power BI
Представьте, что у вас есть бизнес-требования для автоматизации импорта, экспорта или обновления, а также для более оркестрации и действий за пределами Power BI. Для этого можно включить несколько вариантов, как описано в следующей таблице.
| Тип | Механизм |
|---|---|
| Используйте шаблоны Power Automate. | Нет кода |
| Используйте сценарии автоматизации в PowerShell. | Скрипты автоматизации |
| Создайте собственную бизнес-логику с помощью API. | Rest API (Интерфейс программирования приложений на основе REST) |
Дополнительные сведения об обновлении см. в разделе "Общие сведения о обновлении потоков данных и оптимизации".
Убедитесь, что вы защищаете ресурсы данных ниже
Метки конфиденциальности можно использовать для применения классификации данных и любых правил, настроенных на подчиненных элементах, которые подключаются к потокам данных. Дополнительные сведения о метках конфиденциальности см. в разделе меток конфиденциальности в Power BI. Сведения о наследовании см. в разделе "Наследование меток конфиденциальности" в Power BI.
Поддержка нескольких регионов
Многие клиенты сегодня должны соответствовать требованиям к независимости данных и месту проживания. Вы можете выполнить настройку вручную в рабочей области потоков данных, чтобы быть несколькими географическими.
Потоки данных поддерживают использование нескольких регионов при использовании функции создания собственной учетной записи хранения. Эта функция описана в разделе "Настройка хранилища потоков данных для использования Azure Data Lake 2-го поколения". Рабочая область должна быть пустой перед присоединением этой возможности. С помощью этой конкретной конфигурации можно хранить данные потока данных в определенных географических регионах.
Защита ресурсов данных за виртуальной сетью
Многие клиенты сегодня должны защитить ресурсы данных за частной конечной точкой. Для этого используйте виртуальные сети и шлюз для поддержания соответствия требованиям. В следующей таблице описывается текущая поддержка виртуальной сети и объясняется, как использовать потоки данных для обеспечения соответствия и защиты ресурсов данных.
| Сценарий | Состояние |
|---|---|
| Чтение источников данных виртуальной сети через локальный шлюз. | Поддерживается через локальный шлюз |
| Запись данных в учетную запись метки конфиденциальности за виртуальной сетью с помощью локального шлюза. | Пока не поддерживается. |
Связанный контент
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.
- Введение в потоки данных и самостоятельную подготовку данных
- Создание потока данных
- Настройка и использование потока данных
- Функции потоков данных уровня "Премиум"
- Планирование реализации Power BI — интеграция с другими службами
- Рекомендации и ограничения, касающиеся потоков данных
- Рекомендации по потокам данных