Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
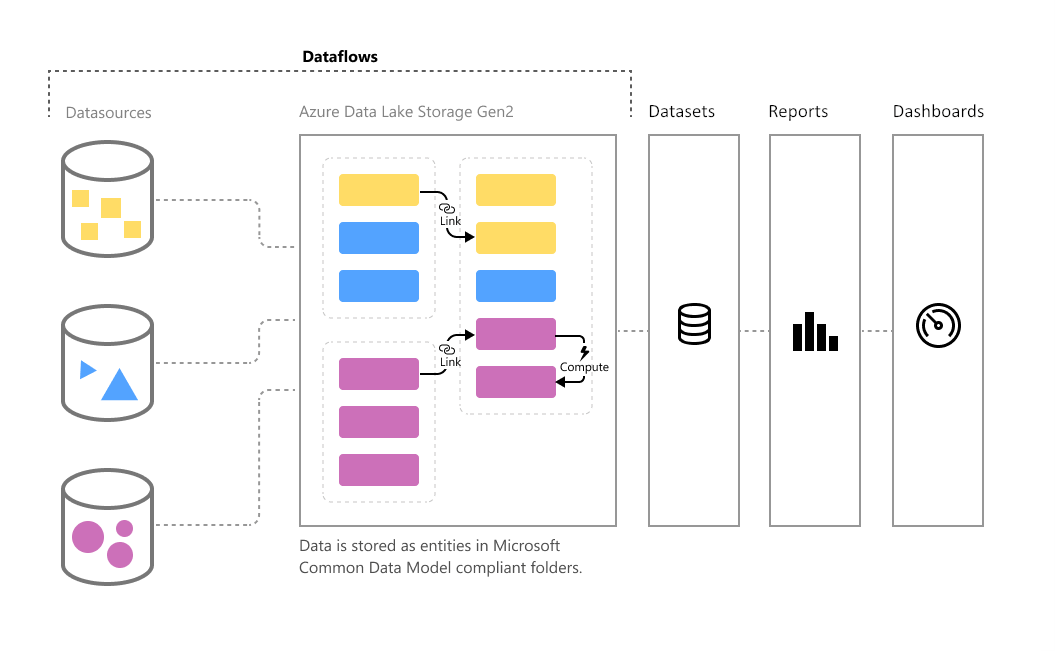
Поскольку объем данных продолжает расти, задача их упорядочивания для получения хорошо структурированной и действенной информации становится всё более сложной. Мы хотим, чтобы данные, готовые для аналитики, могли заполнять визуальные элементы, отчеты и панели мониторинга, чтобы мы могли быстро превращать объемы данных в полезные инсайты. С помощью самостоятельной подготовки данных для больших данных в Power BI можно перейти от данных к аналитике Power BI с помощью нескольких действий.
Совет
Power BI Dataflow 1-го поколения теперь находится в устаревшем состоянии и не получит новых инвестиций в функции. Для премиум-клиентов с доступом к Fabric, Dataflow Gen2 является рекомендуемым решением, предлагая улучшения в производительности, масштабируемости, надежности, функциональности и встроенном ИИ. Клиенты Pro/PPU могут продолжать использовать Gen1, так как руководства по Gen2 для этих сценариев всё ещё разрабатываются. См. статью Обновление с Dataflow Gen1 до Dataflow Gen2 для получения инструкций по обновлению.
Потоки данных предназначены для поддержки следующих сценариев:
Создайте логику повторного использования преобразования, которую многие семантические модели и отчеты могут совместно использовать в Power BI. Потоки данных повышают повторное использование базовых элементов данных, предотвращая необходимость создания отдельных подключений к облачным или локальным источникам данных.
Сохраняйте данные в собственном хранилище Azure Data Lake 2-го поколения, что позволяет предоставлять их другим службам Azure за пределами Power BI.
Создайте единую версию данных, полученную из необработанных данных на основе отраслевых стандартов, настроенную для работы с другими службами и продуктами в Power Platform. Поощряйте их, удаляя доступ аналитиков к базовым источникам данных.
Повышение безопасности в базовых источниках данных путем предоставления данных создателям отчетов в потоках данных. Этот подход позволяет ограничить доступ к базовым источникам данных, уменьшая нагрузку на исходные системы, и дает администраторам более точное управление операциями обновления данных.
Если вы хотите работать с большими объемами данных и выполнять ETL в большом масштабе, потоки данных с помощью Power BI Premium масштабируется более эффективно и обеспечивают большую гибкость. Потоки данных поддерживают широкий спектр облачных и локальных источников.
Вы можете использовать Power BI Desktop и служба Power BI с потоками данных для создания семантических моделей, отчетов, панелей мониторинга и приложений, использующих общую модель данных. Из этих ресурсов вы можете получить подробные сведения о бизнес-действиях. Планирование обновления потока данных управляется непосредственно из рабочей области, в которой был создан поток данных, как и в семантических моделях.
Примечание.
Потоки данных могут быть недоступны в сервисе Power BI для всех клиентов Министерства обороны США. Дополнительные сведения о доступных и недоступных функциях см. в разделе о доступности функций Power BI для клиентов государственных организаций США.
Связанный контент
В этой статье представлен обзор подготовки данных самообслуживания для больших данных в Power BI, а также множество способов его использования.
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.
- Создание потока данных
- Настройка и использование потока данных
- Настройка хранилища потока данных для использования Azure Data Lake 2-го поколения
- Функции потоков данных уровня "Премиум"
- Рекомендации и ограничения, касающиеся потоков данных
- Рекомендации по потокам данных
- Сценарии использования Power BI: самостоятельная подготовка данных
Для получения дополнительной информации о Common Data Model вы можете прочитать ее обзорную статью: