Использование записных книжек Jupyter в Azure Data Studio
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook представляет собой веб-приложение с открытым исходным кодом, которое позволяет создавать документы, содержащие код, формулы, визуализации и текстовое описание, и обмениваться этими документами. Использование включает в себя очистку и преобразование данных, числовое моделирование, статистическое моделирование, визуализацию данных и машинное обучение.
Эта статья содержит сведения о создании записной книжки в актуальном выпуске Azure Data Studio и создании собственных записных книжек с помощью разных ядер.
Просмотрите это короткое пятиминутное видео, чтобы ознакомиться с записными книжками в Azure Data Studio.
Создание записной книжки
Создать записную книжку можно разными способами. В каждом случае открывается новый файл с именем Notebook-1.ipynb.
В Azure Data Studio откройте меню Файл и выберите Создать записную книжку.
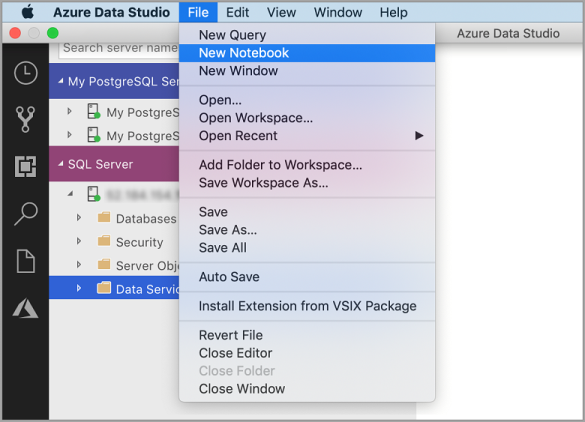
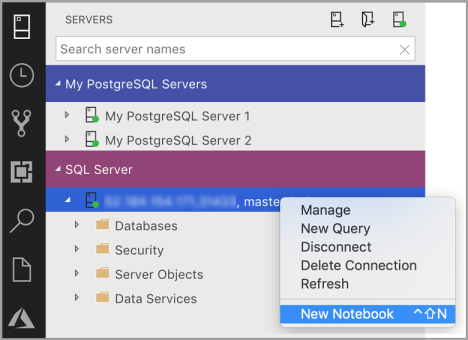
Щелкните правой кнопкой мыши подключение SQL Server и выберите Создать записную книжку.
Откройте палитру команд (CTRL+SHIFT+P), введите "создать записную книжку" и выберите Создать записную книжку.

Подключение к ядру
Записные книжки Azure Data Studio поддерживают ряд различных ядер, в том числе SQL Server, Python, PySpark и др. Каждое ядро поддерживает разные языки в ячейках кода записной книжки. Например, при подключении к ядру SQL Server можно вводить и выполнять инструкции T-SQL в ячейке кода записной книжки.
Параметр Присоединить к предоставляет контекст для ядра. Например, если вы используете ядро SQL, вы можете подключиться к любому из экземпляров SQL Server. Если вы используете ядро Python3, вы подключаетесь к localhost и можете использовать этот ядро для локальной разработки на Python.
Ядро SQL также можно применять для подключения к экземплярам сервера PostgreSQL. Разработчики PostgreSQL, которым требуется подключить записные книжки к серверу PostgreSQL, должны скачать расширение PostgreSQL в магазине расширений Azure Data Studio и подключиться к серверу PostgreSQL.
Если вы подключены к кластеру больших данных SQL Server 2019, то параметр по умолчанию Присоединить к является конечной точкой этого кластера. Вы можете отправить код Python, Scala и R с использованием вычислительных ресурсов Spark кластера.
| Ядро | Description |
|---|---|
| Ядро SQL | Написание кода SQL, предназначенного для реляционной базы данных. |
| Ядро PySpark3 и PySpark | Написание кода Python с использованием вычислительных ресурсов Spark из кластера. |
| Ядро Spark | Написание кода Scala и R с использованием вычислительных ресурсов Spark из кластера. |
| Ядро Python | Написание кода Python для локальной разработки. |
Дополнительные сведения о конкретных ядрах см. в следующих статьях:
- Создание и запуск записной книжки SQL Server
- Создание и запуск записной книжки Python
- Расширение Kqlmagic в Azure Data Studio расширяет возможности ядра Python.
Добавление ячейки кода
Ячейки кода позволяют интерактивно запускать код в записной книжке.
Добавьте новую ячейку кода, щелкнув команду +Ячейка на панели инструментов и выбрав Ячейка кода. Новая ячейка кода добавляется после текущей выбранной ячейки.
Введите код в ячейке для выбранного ядра. Например, если вы используете ядро SQL, в ячейку кода можно ввести команды T-SQL.
Ввод кода с использованием ядра SQL аналогичен редактору SQL-запросов. Ячейка кода поддерживает современные возможности написания кода SQL с использованием встроенных функций, таких как редактор SQL, IntelliSense и встроенные фрагменты кода. Фрагменты кода позволяют формировать правильный синтаксис SQL для создания баз данных, таблиц, представлений, хранимых процедур, а также для обновления существующих объектов базы данных. С помощью фрагментов кода можно быстро создавать копии базы данных для разработки или тестирования, а также генерировать и выполнять сценарии.
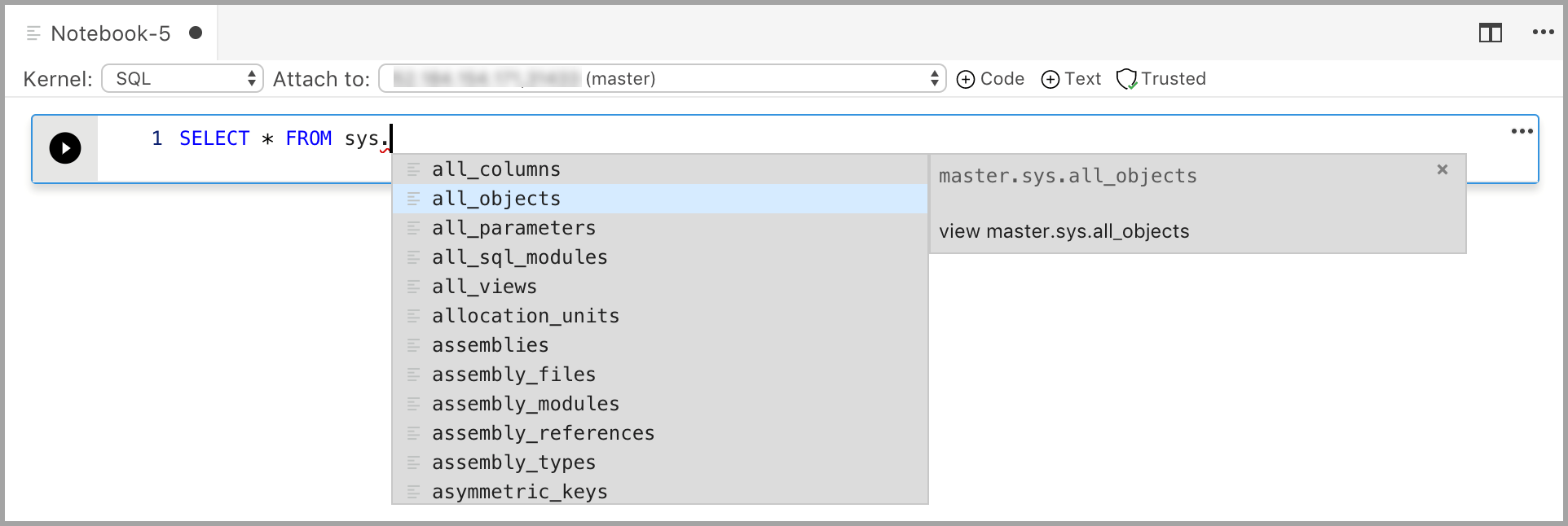
Добавление текстовой ячейки
Текстовые ячейки позволяют документировать код путем добавления блоков текста Markdown между ячейками кода.
Добавьте новую текстовую ячейку, щелкнув команду +Ячейка на панели инструментов и выбрав Текстовая ячейка.
Ячейка запускается в режиме редактирования, в котором можно ввести текст Markdown. По мере ввода отображается показанный ниже предварительный просмотр.
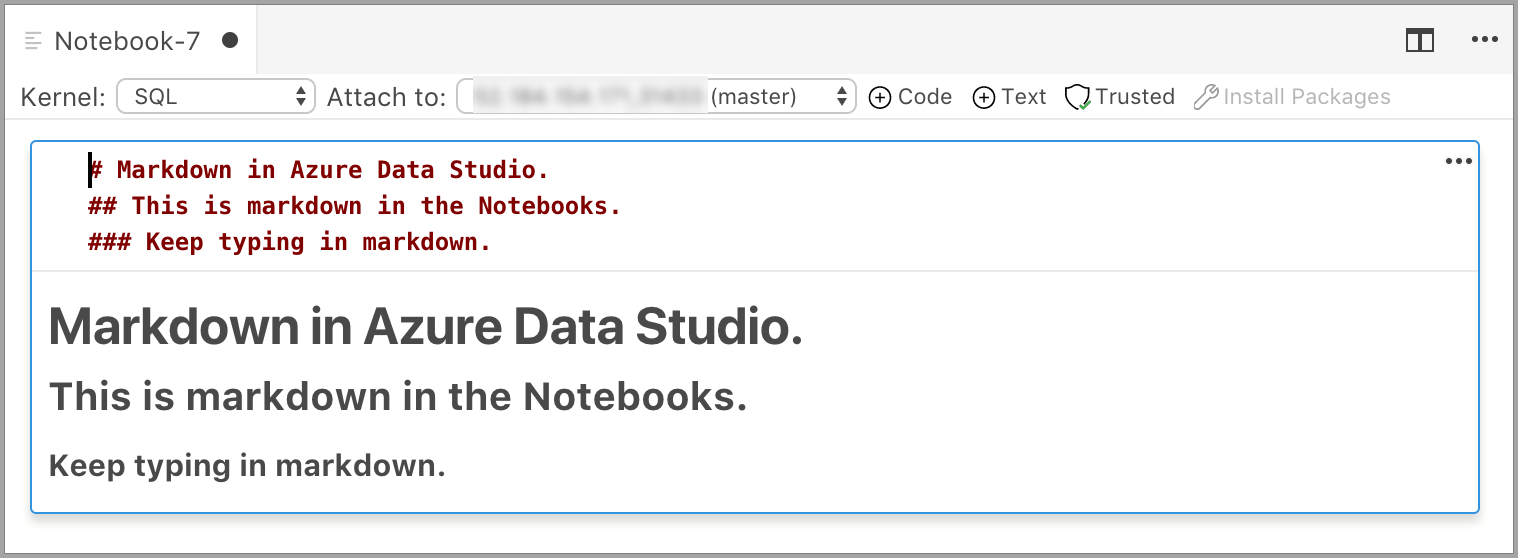
Щелкните вне текстовой ячейки, чтобы отобразить текст с разметкой Markdown.
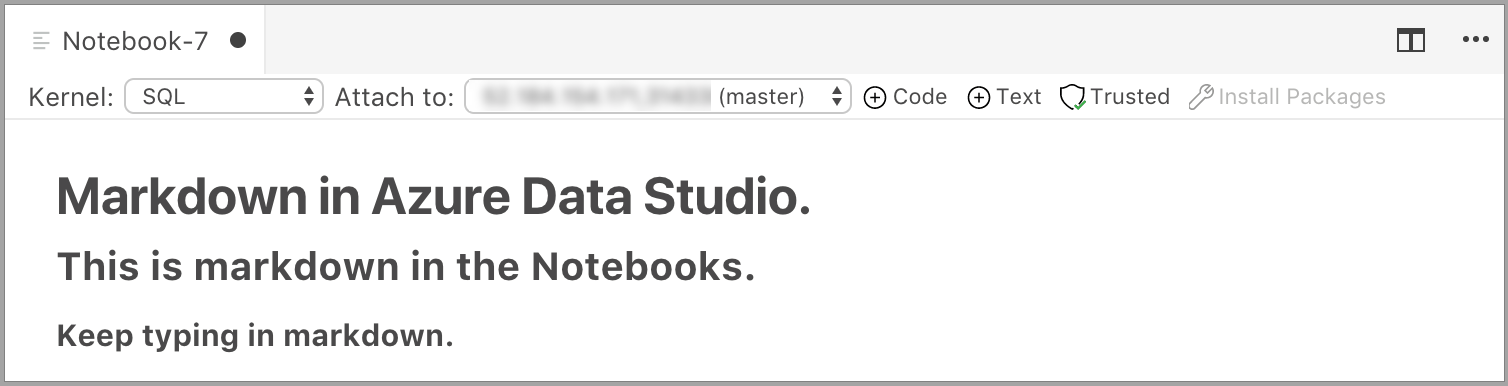
Если щелкнуть текстовую ячейку еще раз, она перейдет в режим редактирования.
Выполнение ячейки
Чтобы выполнить одну ячейку, щелкните Выполнить ячейку (скругленная черная стрелка) слева от ячейки либо выделите ячейку и нажмите клавишу F5. Можно запустить все ячейки в записной книжке, щелкнув Запустить все на панели инструментов, при этом ячейки запускаются по одной за раз, а при возникновения ошибки в ячейке выполнение останавливается.
Результаты из ячейки отображаются под ней. Для очистки результатов всех выполненных ячеек в записной книжке нажмите кнопку Очистить результаты на панели инструментов.
Сохранение записной книжки
Чтобы сохранить записную книжку, выполните одно из указанных ниже действий.
- Нажмите CTRL+S.
- В меню Файл выберите команду Сохранить.
- В меню Файл выберите команду Сохранить как....
- В меню Файл выберите Сохранить все, чтобы сохранить все открытые записные книжки.
- В палитре команд введите файл: Сохранить
Записные книжки сохраняются в виде файлов .ipynb.
Доверенные и недоверенные
Записные книжки, открытые в Azure Data Studio, являются доверенными по умолчанию.
Записная книжка, открываемая из другого источника, откроется в недоверенном режиме, после чего ее можно сделать доверенной.
Примеры
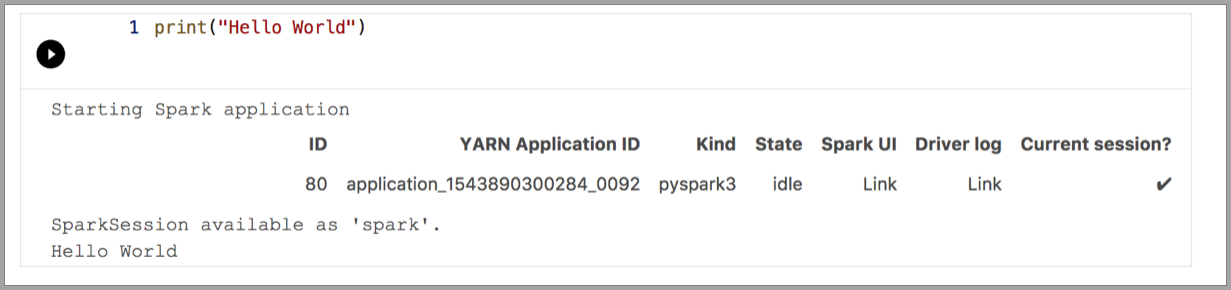
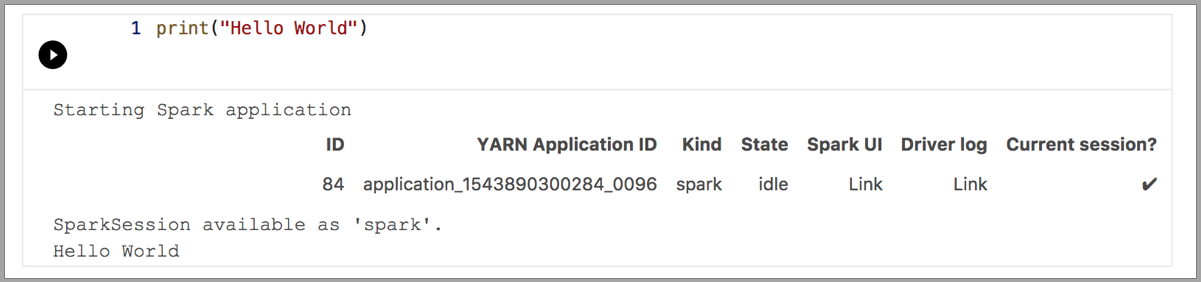
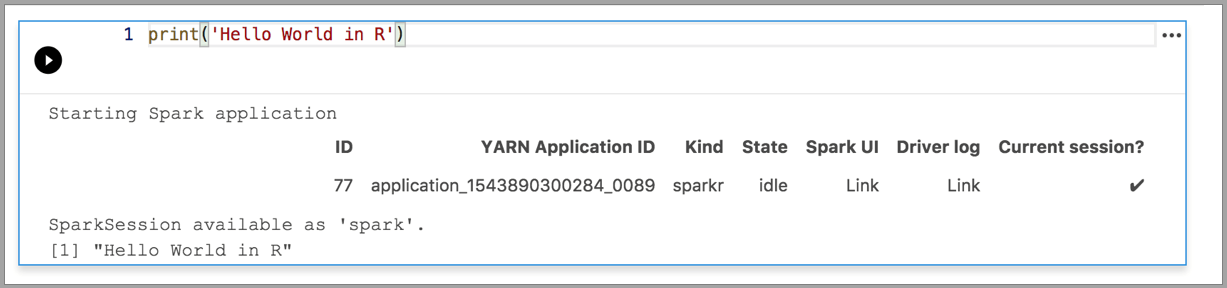
В следующих примерах демонстрируется использование разных ядер для выполнения простой команды Hello World. Выберите ядро, введите код примера в ячейку и щелкните Выполнить ячейку.
Pyspark
Spark | Язык Scala
Spark | Язык R
Python 3

Следующие шаги
- Создание и запуск записной книжки SQL Server.
- Создание и запуск записной книжки Python
- Запуск скриптов Python и R в записных книжках Azure Data Studio с помощью Служб машинного обучения SQL Server.
- Развертывание кластера больших данных SQL Server с помощью записной книжки Azure Data Studio.
- Управление Кластерами больших данных SQL Server с помощью записных книжек Azure Data Studio.
- Запуск примера записной книжки с помощью Spark.