Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Natívny nástroj na spúšťanie je priekopníckym vylepšením pre vykonávanie úloh Apache Spark v službe Microsoft Fabric. Tento vektorovaný nástroj optimalizuje výkon a efektivitu dotazov služby Spark tak, že ich spustí priamo vo vašej infraštruktúre lakehouse. Bezproblémová integrácia nástroja znamená, že nevyžaduje žiadne úpravy kódu a vyhýba sa zablokovaniu dodávateľa. Podporuje rozhrania Apache Spark API a je kompatibilné s modulom Runtime 1.3 (Apache Spark 3.5) a spolupracuje s formátmi Parquet aj Delta. Bez ohľadu na umiestnenie vašich údajov v službe OneLake alebo ak pristupujete k údajom prostredníctvom odkazov, natívny nástroj na spúšťanie maximalizuje efektivitu a výkon.
Natívny nástroj na spúšťanie výrazne zvýši výkon dotazu a zároveň minimalizuje prevádzkové náklady. Prináša pozoruhodné zvýšenie rýchlosti a dosahuje až štyrikrát vyšší výkon v porovnaní s tradičným OSS (open source softvérom) Spark, čo potvrdil benchmark TPC-DS 1 TB. Nástroj je adept na správu širokej škály scenárov spracovania údajov od rutinnej príjmu údajov, dávkových úloh a ETL úloh (extrahovanie, transformácia, načítanie) až po komplexnú analýzu dátovej vedy a interaktívne dotazy. Používatelia môžu využívať zrýchlené časy spracovania, zvýšenú priepustnosť a optimalizované využitie prostriedkov.
Natívny nástroj na spúšťanie je založený na dvoch kľúčových súčastiach OSS: Velox, knižnicu zrýchlenia databázy C++, ktorú zaviedli Meta a Apache Glut (incubating), strednú vrstvu zodpovednú za vyťaženie nástrojov SQL založených na JVM na natívne motory predstavené spoločnosťou Intel.
Kedy použiť natívny nástroj na spúšťania
Natívny nástroj na spúšťanie ponúka riešenie na spúšťanie dotazov na rozsiahle množiny údajov. Optimalizuje výkon pomocou natívnych možností základných zdrojov údajov a minimalizuje režijné náklady zvyčajne spojené s pohybom údajov a serializáciou v tradičných prostrediach Spark. Nástroj podporuje rôzne operátory a typy údajov vrátane agregácie hash súhrnu, spojenia vnorenej slučky (BNLJ) a presných formátov časovej pečiatky. Ak však chcete plne využiť možnosti motora, mali by ste zvážiť jeho optimálne využitie:
- Nástroj je efektívny pri práci s údajmi vo formátoch Parquet a Delta, ktoré dokáže spracovať natívne a efektívne.
- Dotazy, ktoré zahŕňajú zložité transformácie a agregácie, výrazne profitujú zo stĺpcových možností spracovania a vektorizácie motora.
- Vylepšenie výkonu je najvýraznejšie v prípadoch, kde dotazy nespúšťajú záložný mechanizmus tým, že sa vyhýbajú nepodporovaným funkciám alebo výrazom.
- Nástroj je vhodný pre dotazy, ktoré sú výpočtovo náročné a nie jednoduché alebo I/O-bound.
Informácie o operátoroch a funkciách podporovaných natívnym spúšťaním nájdete v dokumentácii Apache Glut.
Povolenie natívneho nástroja na spúšťania
Na využitie úplných funkcií natívneho nástroja na spustenie počas fázy ukážky sú potrebné konkrétne konfigurácie. Nasledujúce postupy ukazujú, ako aktivovať túto funkciu pre poznámkové bloky, definície úloh služby Spark a celé prostredia.
Dôležité
Natívny nástroj na spúšťanie podporuje najnovšiu verziu runtime GA, ktorá je Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). S vydaním natívneho spúšťacieho jadra v Runtime 1.3 sa ukončila podpora predchádzajúcej verzie – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4). Odporúčame všetkým zákazníkom inovovať na najnovší modul Runtime 1.3. Ak používate natívny spúšťací nástroj v prostredí runtime 1.2, natívne zrýchlenie bude zakázané.
Povoliť na úrovni prostredia
Ak chcete zabezpečiť jednotné vylepšenie výkonu, povoľte natívny nástroj na spúšťanie vo všetkých úlohách a poznámkových blokoch priradených k vášmu prostrediu:
Prejdite do pracovného priestoru obsahujúceho vaše prostredie a vyberte prostredie. Ak nemáte vytvorené prostredie, pozrite si tému Vytvorenie, konfigurácia a používanie prostredia v službe Fabric.
V časti Výpočty Spark vyberte položku Zrýchlenie.
Začiarknite políčko s označením Povoliť natívny nástroj spúšťania.
Uložte a publikujte zmeny.
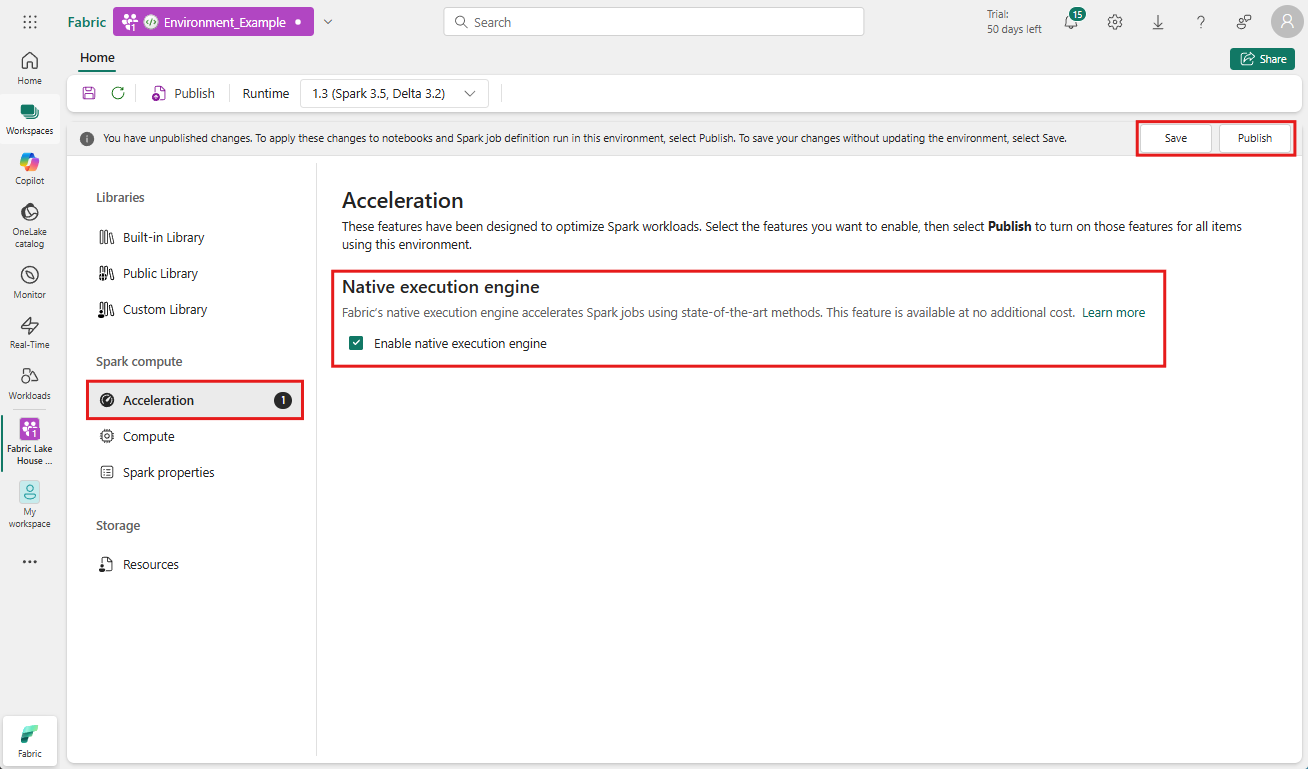

Ak je toto nastavenie povolené na úrovni prostredia, dedia všetky nasledujúce úlohy a poznámkové bloky. Toto dedenie zabezpečí, že všetky nové relácie alebo zdroje vytvorené v prostredí budú automaticky využívať vylepšené možnosti vykonávania.
Dôležité
V minulosti bolo natívny nástroj na spúšťania povolený prostredníctvom nastavení Spark v rámci konfigurácie prostredia. Natívny nástroj na spustenie teraz možno jednoduchšie povoliť pomocou prepínača na karte Acceleration (Zrýchlenie ) v nastaveniach prostredia. Ak chcete pokračovať v jej používaní, prejdite na kartu Acceleration (Zrýchlenie ) a zapnite prepínač. Môžete ho tiež povoliť prostredníctvom vlastností Spark, ak sa uprednostňuje.
Povolenie poznámkového bloku alebo definície úlohy služby Spark
Natívny nástroj na spustenie môžete tiež povoliť pre jeden poznámkový blok alebo definíciu úlohy služby Spark, musíte zahrnúť potrebné konfigurácie na začiatku spúšťania skriptu:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
V prípade poznámkových blokov vložte požadované konfiguračné príkazy do prvej bunky. V prípade definícií úloh služby Spark zahrňte konfigurácie v prvej línii definície úlohy služby Spark. Natívny nástroj na spúšťanie je integrovaný so živými bazénmi, takže po povolení funkcie sa prejaví okamžite bez toho, aby bolo potrebné iniciovať novú reláciu.
Ovládanie na úrovni dotazu
Mechanizmy na povolenie natívneho nástroja na spúšťanie na úrovni nájomníka, pracovného priestoru a prostredia bezproblémovo integrované s používateľskym rozhraním sú v aktívnom vývoji. Natívny nástroj na spúšťanie môžete zatiaľ zakázať pre konkrétne dotazy, a to najmä v prípade, ak zahŕňajú operátory, ktoré momentálne nie sú podporované (pozrite si obmedzenia). Ak chcete zakázať, nastavte spark konfiguráciu spark.native.enabled na hodnotu false pre konkrétnu bunku obsahujúcu váš dotaz.
- Spark SQL
- PySpark
- Iskra Scala
- SparkR
%%sql
SET spark.native.enabled=FALSE;

Po vykonaní dotazu, v ktorom je zakázaný natívny nástroj na spúšťanie, ho musíte znova povoliť pre nasledujúce bunky nastavením hodnoty spark.native.enabled na hodnotu true. Tento krok je nevyhnutný, pretože služba Spark vykonáva bunky kódu postupne.
- Spark SQL
- PySpark
- Iskra Scala
- SparkR
%%sql
SET spark.native.enabled=TRUE;
Identifikácia operácií vykonaných motorom
Existuje niekoľko metód na určenie, či bol operátor vo vašej práci v službe Apache Spark spracovaný pomocou natívneho nástroja na spustenie.
Server spark UI a Spark history
Získajte prístup k serveru Spark UI alebo Spark history a nájdite dotaz, ktorý potrebujete skontrolovať. Ak chcete získať prístup k webovému používateľskému rozhrania služby Spark, prejdite na definíciu úloh služby Spark a spustite ho. Na karte

V pláne dotazu zobrazenom v rozhraní používateľského rozhrania služby Spark vyhľadajte názvy uzla, ktoré sa končia príponou Transformer, *NativeFileScan alebo VeloxColumnarToRowExec. Prípona označuje, že natívny nástroj na spúšťanie vykonal operáciu. Uzly môžu byť napríklad označené ako RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer alebo BroadcastNestedLoopJoinExecTransformer.

Vysvetlenie pre údajový rámec
Prípadne môžete vykonať príkaz v notebooku df.explain() a zobraziť plán vykonávania. V rámci výstupu vyhľadajte rovnaké

Záložný mechanizmus
V niektorých prípadoch natívny nástroj na spúšťanie nemusí byť schopný vykonať dotaz z dôvodov, ako sú napríklad nepodporované funkcie. V týchto prípadoch operácia spadne späť k tradičnému nástroju Spark. Tento automatický záložný mechanizmus zaisťuje, že k pracovnému postupu nedôjde k žiadnemu prerušeniu.


Monitorovanie dotazov a údajových rámca, ktoré nástroj vykonáva
Ak chcete lepšie pochopiť použitie natívneho nástroja na spúšťanie v dotazoch SQL a operáciách údajového rámca a prejsť na detaily na úrovni fáz a operátorov, môžete si prečítať v téme Používateľské rozhranie služby Spark a Server histórie spark, kde nájdete podrobnejšie informácie o spúšťaní natívneho nástroja.
Karta Natívny nástroj na spúšťaie
Môžete prejsť na novú kartu Lepenie SQL /Údajový rámec a zobraziť si informácie o lepku a podrobnosti o spustení dotazu. Tabuľka Dotazy poskytuje prehľady o počte uzlov spustených v natívom nástroji a tých, ktoré spadajú späť do JVM pre každý dotaz.

Graf vykonávania dotazov
Môžete si tiež vybrať v popise dotazu pre vizualizáciu plánu vykonávania dotazu Apache Spark. Graf vykonávania poskytuje natívne podrobnosti o spúšťaní v jednotlivých fázach a príslušných operáciách. Farby pozadia odlišujú spúšťacie zariadenia: zelená predstavuje nástroj na natívne spustenie, zatiaľ čo svetlomodrá označuje, že operácia je spustená v predvolenom nástroji JVM.

Obmedzenia
Zatiaľ čo natívny nástroj na spúšťania (NEE) v službe Microsoft Fabric výrazne zvyšuje výkon pre úlohy v službe Apache Spark, v súčasnosti má nasledujúce obmedzenia:
Existujúce obmedzenia
Nekompatibilné funkcie Sparku: Natívny spúšťací nástroj momentálne nepodporuje funkcie definované používateľom (UDF), funkciu
array_containsani štruktúrované streamovanie. Ak sa tieto funkcie alebo nepodporované funkcie používajú buď priamo, alebo prostredníctvom importovaných knižníc, služba Spark sa vráti k predvolenému nástroju.Nepodporované formáty súborov: Dotazy na
JSON,XML, aCSVformáty nie sú urýchľované natívnym spúšťacím nástrojom. Tieto predvolené nastavenia sa vrátia k bežnému nástroju Spark JVM na spustenie.Režim ANSI nie je podporovaný: Natívny spúšťací nástroj nepodporuje režim ANSI SQL. Ak je povolené, vykonávanie sa vráti späť na vanilkový Spark engine.
Nezhody typu filtra dátumu: Ak chcete využívať výhody zrýchlenia natívneho nástroja na spúšťanie, uistite sa, že obe strany porovnania dátumov sa zhodujú s typom údajov. Napríklad namiesto porovnania stĺpca
DATETIMEs reťazcovým literálom ho explicitne pretypujte tak, ako je to znázornené:CAST(order_date AS DATE) = '2024-05-20'
Ďalšie dôležité informácie a obmedzenia
Desatinné miesta na float casting nesúlad: Pri odlievaní z
DECIMALdoFLOAT, Spark zachováva presnosť konverziou na reťazec a analyzovať ho. Spoločnosť NEE (prostredníctvom spoločnosti Velox) vykonáva priame pretypovanie z internéhoint128_tvyjadrenia, čo môže mať za následok zaokrúhlenie nezrovnalostí.Chyby konfigurácie časového pásma : Nastavenie nerozpoznaného časového pásma v službe Spark spôsobí, že v rámci nee zlyhá táto úloha, zatiaľ čo JVM ju spracuje. Príklad:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEENekonzistentné správanie zaokrúhľovania: Funkcia
round()sa v NEE správa odlišne z dôvodu spoliehania sa nastd::round, ktorý nekopíruje logiku zaokrúhľovania Sparku. Môže to viesť k číselným nekonzistentnostiam pri zaokrúhlení výsledkov.Chýbajúca kontrola duplicitných kľúčov vo
map()funkcii: Keď je nastavenáspark.sql.mapKeyDedupPolicyna hodnotu EXCEPTION, služba Spark vyhodí chybu pre duplicitné kľúče. NEE v súčasnosti túto kontrolu vynechá a umožňuje, aby dotaz uspel nesprávne.
Príklad:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Odchýlka poradia so
collect_list()zoradením: Pri použitíDISTRIBUTE BYaSORT BYzachová Spark poradie prvkov vcollect_list(). NEE môže vrátiť hodnoty v inom poradí z dôvodu rozdielov v náhodnom zamiešaní, čo môže mať za následok nezhodné očakávania pre logiku citlivú na poradie.Nesúlad medzi typmi pre
collect_list()/collect_set(): Spark sa pre tieto agregácie používaBINARYako typ medzikroku, zatiaľ čo NEE používa .ARRAYTento nesúlad môže viesť k problémom s kompatibilitou počas plánovania alebo vykonávania dotazu.Spravované súkromné koncové body potrebné pre prístup k úložisku: Keď je povolený Native Execution Engine (NEE) a ak sa spark úlohy snažia pristupovať k úložnému účtu cez spravovaný súkromný endpoint, používatelia musia konfigurovať samostatné spravované privátne koncové body pre Blob (blob.core.windows.net) aj DFS / File System (dfs.core.windows.net) koncové body, aj keď smerujú na ten istý úložný účet. Jeden koncový bod nemôže byť použitý pre obe funkcie. Toto je aktuálne obmedzenie a môže vyžadovať dodatočnú sieťovú konfiguráciu pri povolení natívneho výkonného enginu v pracovnom priestore, ktorý má spravované súkromné koncové body k úložným účtom.