Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Tento kurz predstavuje komplexný príklad pracovného postupu synapse Data Science v službe Microsoft Fabric. Scenár vytvára model prognózy, ktorý používa historické údaje o predaji na predpovedanie predaja kategórie produktov v supermarkete.
Predpovedanie je rozhodujúcim prvkom v predaji. Kombinuje historické údaje a prediktívne metódy, vďaka čomu poskytuje prehľady o budúcich trendoch. Prognózovanie dokáže analyzovať minulý predaj a identifikovať trendy. Môžete sa tiež naučiť zo správania spotrebiteľov optimalizovať stratégie inventára, výroby a marketingu. Tento proaktívny prístup zlepšuje prispôsobiteľnosť, odozvu a celkový podnikový výkon v dynamickom trhovisku.
V tomto kurze sú obsiahnuté tieto kroky:
- Načítanie údajov
- Použitie prieskumnej analýzy údajov na pochopenie a spracovanie údajov
- Trénovanie modelu strojového učenia pomocou balíka softvéru typu open-source
- Sledovanie experimentov s MLflow a funkciou automatického označovania služby Fabric
- Uloženie konečného modelu strojového učenia a vytváranie predpovedí
- Zobrazenie výkonu modelu pomocou vizualizácií Power BI
Predpoklady
Získajte predplatné služby Microsoft Fabric . Alebo si zaregistrujte bezplatnú skúšobnú verziu služby Microsoft Fabric.
Prihláste sa do služby Microsoft Fabric.
Prepnite na Fabric pomocou prepínača skúseností v ľavom dolnom rohu domovskej stránky.

- Ak je to potrebné, vytvorte si jazero služby Microsoft Fabric, ako je to popísané v článku Vytvorenie jazera v zdroji služby Microsoft Fabric .
Sledovanie v poznámkovom bloke
Ak si chcete vyskúšať tieto kroky v poznámkovom bloku, máte tieto možnosti:
- Otvorenie a spustenie vstavaného notebooku v prostredí Synapse Data Science
- Nahratie notebooku z GitHubu do prostredia synapse Data Science
Otvorenie vstavaného poznámkového bloku
Ukážkový poznámkový blok prognózy predaja sprevádza tento kurz.
Ak chcete otvoriť vzorový poznámkový blok pre tento kurz, postupujte podľa pokynov v téme Príprava systému na kurzy dátovej vedy.
Uistite sa, že pripojiť lakehouse na notebook , ako začnete bežať kód.
Importovanie notebooku z GitHubu
Notebook AIsample - Superstore Forecast.ipynb sprevádza tento kurz.
Ak chcete otvoriť sprievodný poznámkový blok pre tento kurz, postupujte podľa pokynov v téme Príprava systému na kurzy dátovej vedy a importujte poznámkový blok do pracovného priestoru.
Ak by ste radšej skopírovali a prilepili kód z tejto stránky, môžete vytvoriť nový poznámkový blok.
Uistite sa, že pripojiť lakehouse na notebook , ako začnete spustiť kód.
Krok č. 1: Načítanie údajov
Množina údajov má 9 995 inštancií predaja rôznych produktov. Obsahuje tiež 21 atribútov. Poznámkový blok používa súbor s názvom Superstore.xlsx. Tento súbor má túto štruktúru tabuľky:
| ID riadka | ID objednávky | Dátum objednávky | Dátum vydania | Režim odoslania | ID zákazníka | Meno zákazníka | Segment | Krajina | Mesto | Štát | Psč | Región | ID produktu | Kategória | Sub-Category | Názov produktu | Sales | Množstvo | Zľava | Zisk |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | USA-2015-108966 | 2015-10-11 | 2015-10-18 | Štandardná trieda | SO-20335 | Sean O'Donnell | Spotrebiteľ | Spojené štáty americké | Fort Vlašná | Florida | 33311 | Južne | FUR-TA-10000577 | Nábytok | Tabuľky | Bretford CR4500 Series Štíhla obdĺžniková tabuľka | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Štandardná trieda | Štandardná trieda | Brosina Hoffmanová (Poľ.) | Spotrebiteľ | Spojené štáty americké | Los Angeles | Kalifornia | 90032 | Západne | FUR-TA-10001539 | Nábytok | Tabuľky | Obdĺžnikové konferenčné tabuľky chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Štandardná trieda | TB-21520 | Tracy Blumstein | Spotrebiteľ | Spojené štáty americké | Philadelphia | Pensylvánia | 19140 | Východne | OFF-EN-10001509 | Potreby balíka Office | Obálky | Poly Reťazec Tie obálky | 3.264 | 2 | 0.2 | 1.1016 |
Nasledujúci zlomok kódu definuje konkrétne parametre, aby ste mohli použiť tento poznámkový blok s rôznymi množinami údajov:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Stiahnite si množinu údajov a nahrajte ju do služby lakehouse
Nasledujúci zlomok kódu stiahne verejne dostupnú verziu množiny údajov a potom uloží túto množinu údajov v úryvku kódu v úložisku Fabric lakehouse:
Dôležitý
Musíte pridať lakehouse do notebooku pred spustením. V opačnom prípade sa zobrazí chyba.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Nastavenie sledovania experimentov s MLflow
Microsoft Fabric počas trénovania automaticky zaznamenáva hodnoty vstupných parametrov a výstupné metriky modelu strojového učenia. Tým sa rozširujú možnosti automatického označovania toku MLflow. Informácie sa potom prihlásia do pracovného priestoru, kde k nim môžete získať prístup a vizualizovať ich pomocou rozhraní API toku MLflow alebo pomocou príslušného experimentu v pracovnom priestore. Ďalšie informácie o automatickom označovaní nájdete v zdroji automatického označovania v službe Microsoft Fabric .
Ak chcete vypnúť automatické označovanie služby Microsoft Fabric v relácii poznámkového bloku, zavolajte a nastavte mlflow.autolog()disable=True, ako je to znázornené na nasledujúcom úryvku kódu:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Prečítajte si nespracované údaje z jazera
Nasledujúci zlomok kódu prečíta nespracované údaje zo sekcie Súbory v úryvku jazera. Pridáva tiež ďalšie stĺpce pre rôzne časti dátumu. Rovnaké informácie vytvoria tabuľku rozdelenia oblastí. Keďže nespracované údaje sú uložené ako excelový súbor, musíte na ich čítanie použiť pandas.
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Krok č. 2: Vykonanie prieskumnej analýzy údajov
Import knižníc
Pred začatím analýzy importujte požadované knižnice:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Zobrazenie nespracovaných údajov
Ak chcete lepšie porozumieť samotnej množine údajov, manuálne skontrolujte podmnožinu údajov.
display Funkciu použite na tlač prvku DataFrame. Zobrazenia Chart môžu jednoducho vizualizovať podmnožiny množiny údajov:
display(df)
Tento kurz zahŕňa poznámkový blok, ktorý sa zameriava predovšetkým na Furniture prognózy predaja podľa kategórií. Tento prístup urýchľuje výpočet a pomáha zobrazovať výkon modelu. Tento poznámkový blok však používa adaptívne techniky. Tieto techniky môžete rozšíriť a predpovedať predaj iných kategórií produktov. Ako kategóriu produktov vyberie Furniture nasledujúci úryvok kódu:
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Predprocesuje údaje
Podnikové scenáre z reálneho sveta často potrebujú predpovedať predaj v troch rôznych kategóriách:
- Konkrétna kategória produktu
- Kategória konkrétneho zákazníka
- Konkrétna kombinácia kategórie produktu a kategórie zákazníka
Nasledujúci zlomok kódu znižuje nepotrebné stĺpce, aby sa údaje mohli vopred spracovať. Niektoré stĺpce (Row ID, Order IDaCustomer IDCustomer Name ), nepotrebujeme, pretože nemajú žiadnu relevantnosť. Chceme predpovedať celkový predaj v rámci štátu a oblasti pre konkrétnu kategóriu produktu (Furniture). Preto môžeme zrušiť stĺpce State, Region, Country, Citya Postal Code . Na prognózu predaja pre konkrétne miesto alebo kategóriu môžeme podľa toho upraviť krok predprocesu.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Množina údajov je štruktúrovaná na dennej báze. Musíme znova použiť Order Date stĺpec, pretože chceme vytvoriť model na prognózu predaja na mesačnej báze.
Najprv zoskupte kategóriu Furniture podľa Order Date. Potom vypočítajte súčet stĺpca Sales pre každú skupinu s cieľom určiť celkový predaj pre každú jedinečnú Order Date hodnotu. Zmeňte zobrazenie stĺpca Sales s frekvenciou MS a agregujte údaje podľa mesiacov. Nakoniec vypočítajte priemernú hodnotu predaja pre každý mesiac. Nasledujúci zlomok kódu zobrazuje tieto kroky:
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
V nasledujúcom úryvku kódu zobrazte vplyv Order DateSales na kategóriu Furniture :
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Pred akoukoľvek štatistickou analýzou je potrebné importovať modul statsmodels jazyka Python. Tento modul poskytuje triedy a funkcie na odhad mnohých štatistických modelov. Poskytuje tiež triedy a funkcie na vykonávanie štatistických testov a štatistického skúmania údajov. Nasledujúci zlomok kódu ukazuje tento krok:
import statsmodels.api as sm
Vykonanie štatistickej analýzy
Časový rad sleduje tieto prvky údajov v stanovených intervaloch s cieľom určiť variáciu týchto prvkov vo vzore časového radu:
Úroveň: Základná zložka, ktorá predstavuje priemernú hodnotu pre konkrétne časové obdobie
Trend: popisuje, či časový rad v priebehu času klesá, zostáva konštantný alebo zvyšuje
Sezónnosť: Popisuje pravidelný signál v časovom rade a hľadá cyklické výskyty, ktoré majú vplyv na postupné zvyšovanie alebo klesajúce časové rady
Hluk/Zostatková hodnota: Týka sa náhodných výkyvov a variability údajov v časovom rade, ktoré model nedokáže vysvetliť.
Nasledujúci zlomok kódu zobrazuje tieto prvky pre množinu údajov po predbežnom dokončení:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Vykreslenia popisujú sezónnosť, trendy a hluk v údajoch prognózovania. Môžete zaznamenať základné vzory a vyvíjať modely, ktoré vytvárajú presné predpovede s odolnosťou proti náhodným výkyvom.
Krok č. 3: Trénovať a sledovať model
Teraz, keď máte k dispozícii údaje, definujte model prognózy. V tomto notebooku použite sezónne autoregressive integrovaný pohyblivý priemer s exogénnymi faktormi (SARIMAX) forecasting model. SariMAX kombinuje autoregressive (AR) a pohyblivé komponenty priemeru (MA), sezónne odlišné a externé prediktory, aby sa presné a flexibilné predpovede pre časové rady údajov.
Môžete tiež použiť MLflow a Fabric automatické označovanie sledovať experimenty. Tu načítajte delta tabuľky z jazera. Môžete použiť iné delta tabuľky, ktoré považujú za zdroj lakehouse. Nasledujúci zlomok kódu importuje požadované knižnice:
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Ladenie hyperparametrov
SARIMAX zodpovedá parametrom zapojeným do bežného režimu ARIMA (autoregressive Integrated Moving Average) () a pdqpridáva parametre sezónnosti (P, D, Q, ). s Tieto argumenty modelu SARIMAX majú názov order (p, d, q) a sezónne poradie (P, D, Q, s), resp. . Ak chcete trénovať model, najskôr musíme naladiť sedem parametrov.
Parametre poradia:
p: Poradie komponentu AR, ktoré predstavuje počet minulých pozorovaní v časovom rade použitom na predpovedanie aktuálnej hodnoty.Tento parameter by mal zvyčajne mať nezápornú celočíselnú hodnotu. Spoločné hodnoty sú v rozsahu
0do3. V závislosti od konkrétnych charakteristík údajov sú však možné vykonať vyššie hodnoty. Vyššiaphodnota označuje dlhšiu pamäť minulých hodnôt v modeli.d: Rozdielne poradie, ktoré predstavuje počet výskytov, kedy je potrebné zmeniť časový rad, aby sa dosiahla stacionárita.Tento parameter by mal mať nezápornú celočíselnú hodnotu. Spoločné hodnoty sú v rozsahu
0do2.dhodnota0znamená, že časový rad je už stacionárny. Väčšie hodnoty označujú, že počet odlišných operácií potrebných na jeho zvýšenie je vyšší.q: Poradie súčasti MA. Tento parameter predstavuje počet chýb v minulosti používaných na predpovedanie aktuálnej hodnoty.Tento parameter by mal mať nezápornú celočíselnú hodnotu. Spoločné hodnoty sú v rozsahu
0od ,3ale určité časové rady môžu vyžadovať vyššie hodnoty. Vyššia hodnotaqoznačuje vyššiu závislosť od minulých výrazov chýb, aby sa mohli vytvárať predpovede.
Parametre sezónnych objednávok:
-
P: Sezónne poradie zložky ar, podobné parametrup, ale pokrýva sezónnu časť -
D: Sezónne poradie rozdielnosti, podobné parametrud, ale pokrýva sezónnu časť -
Q: Sezónne poradie súčasti MA, podobné parametruq, ale pokrýva sezónnu časť -
s: Počet krokov na ročné obdobie (napríklad 12 pre mesačné údaje s ročnou sezónnosťou)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX má ďalšie parametre:
enforce_stationarity: Určuje, či má model vynútiť stacionárnosť v údajoch časového radu pred montážou modelu SARIMAX.Hodnota
enforce_stationarity(predvolená) označuje, že model SARIMAX by mal v údajochTruečasového radu vynútiť stacionáritu. Pred montážou modelu model SARIMAX automaticky aplikuje odlišnosti na údaje, aby bol stacionárny, podľadurčenia aDobjednávok. Toto je bežnou praxou, pretože mnohé modely časových radov, vrátane SARIMAX, predpokladajú, že stacionárne údaje.Pre nestály časový rad (napríklad rad, ktorý vykazuje trendy alebo sezónnosť), je vhodné nastaviť ho
enforce_stationaritynaTruea nechať model SARIMAX zvládnuť odlišné s cieľom dosiahnuť stacionáritu. V stacionárnom časovom rade (napríklad pri časovom rade bez trendov alebo sezónnosti) nastavteenforce_stationaritynaFalse, aby sa predišlo zbytočným rozdielom.enforce_invertibility: Určuje, či by model mal počas procesu optimalizácie vynútiť invertovateľnosť na odhadované parametre.Hodnota
enforce_invertibilityTrue(predvolená) označuje, že model SARIMAX by mal v odhadovaných parametroch vynútiť invertovateľnosť. Bezmennosť zaručuje, že dobre definovaný model a odhadované koeficienty AR a MA sa nachádzajú v rozsahu stacionárity.Uplatnenie invertovateľnosti pomáha zabezpečiť, že model SARIMAX spĺňa teoretické požiadavky na stabilný model časového radu. Pomáha tiež predchádzať problémom s odhadom modelu a stabilitou.
Model AR(1) je predvolený. Odkazuje na (1, 0, 0). Bežne však môžete vyskúšať rôzne kombinácie parametrov poradia a parametrov sezónneho poradia a vyhodnotiť výkon modelu pre množinu údajov. Vhodné hodnoty sa môžu líšiť od jedného časového radu k inému.
Stanovenie optimálnych hodnôt často zahŕňa analýzu funkcie autocorrelácie (ACF) a čiastočnú funkciu autocorrelácie (PACF) údajov časového radu. Často tiež zahŕňa použitie kritérií výberu modelu – napríklad informačné kritérium Akaike (AIC) alebo kritérium bayesských informácií (BIC).
Vylaďte hyperparametre, ako je to znázornené v nasledujúcom úryvku kódu:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Po vyhodnotení predchádzajúcich výsledkov môžete určiť hodnoty pre parametre poradia aj parametre sezónneho poradia. Výber je order=(0, 1, 1) a seasonal_order=(0, 1, 1, 12), ktoré ponúkajú najnižšie AIC (napríklad 279,58). Pomocou týchto hodnôt môžete trénovať model. Nasledujúci zlomok kódu ukazuje tento krok:
Trénovať model
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Tento kód vizualizuje prognózu časových radov pre údaje o predaji nábytku. Vykreslené výsledky zobrazujú pozorované údaje aj prognózu pred krokom s tieňovanou oblasťou pre interval spoľahlivosti. Vizualizáciu zobrazujú nasledujúce úryvky kódu:
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Nasledujúci úryvok kódu používa predictions na posúdenie výkonu modelu, pričom ho kontrastuje so skutočnými hodnotami. Hodnota predictions_future označuje budúce prognózovanie.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Krok 4: Skóre modelu a uloženie predpovedí
Nasledujúci úryvok kódu integruje skutočné hodnoty s predpokladanými hodnotami na vytvorenie zostavy služby Power BI. Okrem toho ukladá tieto výsledky v tabuľke v rámci jazera.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok č. 5: Vizualizácia v službe Power BI
Zostava Power BI zobrazuje priemernú absolútnu percentuálnu chybu (MAPE) 16,58. Metrika MAPE definuje presnosť metódy prognózy. Predstavuje presnosť predpokladaných množstiev v porovnaní so skutočnými množstvami.
MAPE je jednoduchá metrika. Hodnota 10% MAPE predstavuje, že priemerná odchýlka medzi predpokladanými hodnotami a skutočnými hodnotami je 10%, bez ohľadu na to, či odchýlka bola kladná alebo záporná. Normy žiaducej hodnoty MAPE sa líšia v rámci rôznych odvetví.
Svetlomodrá čiara v tomto grafe predstavuje skutočné hodnoty predaja. Tmavomodrá čiara predstavuje predpokladané hodnoty predaja. Porovnanie skutočného a predpokladaného predaja ukazuje, že model efektívne predpovedá predaj pre kategóriu Furniture počas prvých šiestich mesiacov roku 2023.
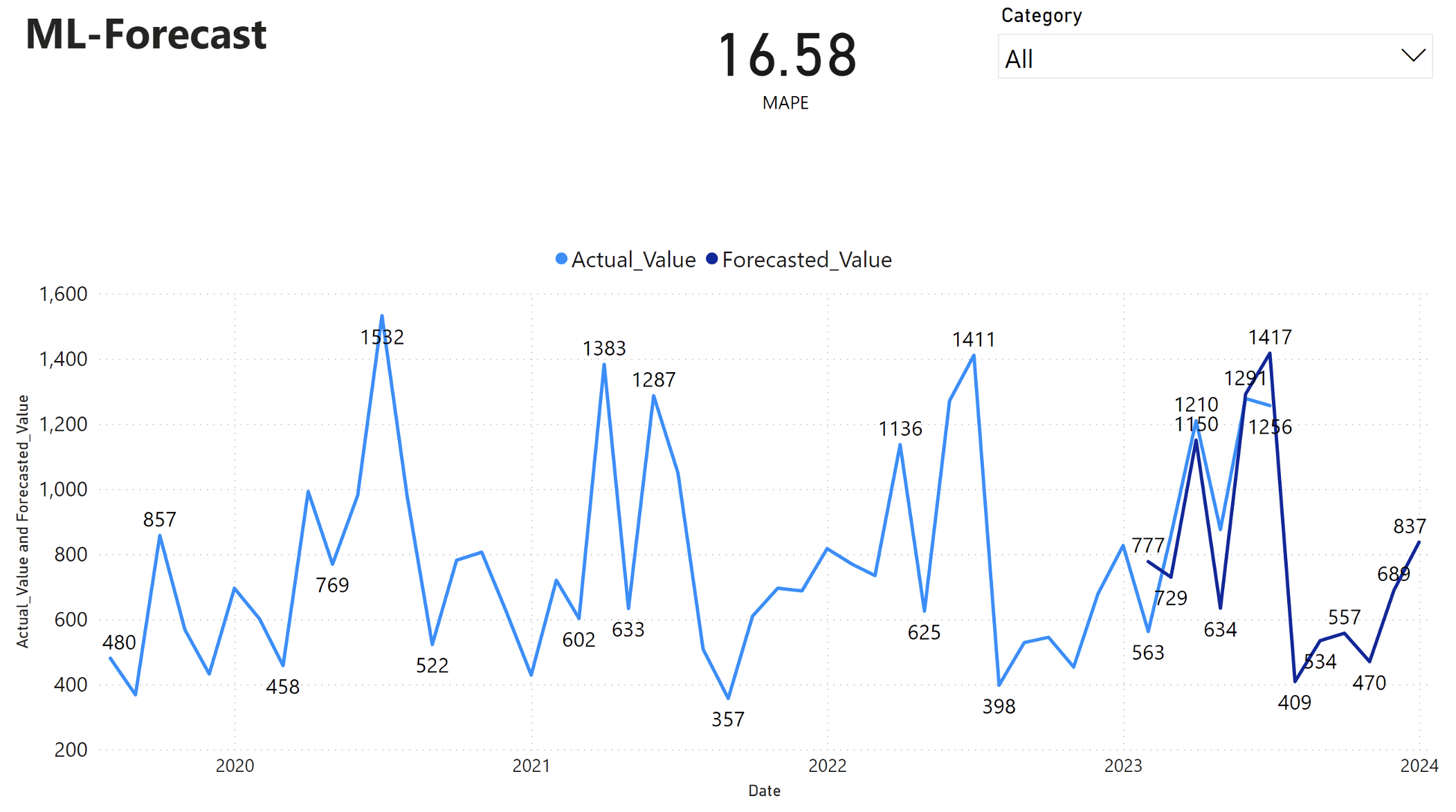
Na základe tohto pozorovania môžeme mať istotu v možnosti prognózovania modelu pre celkový predaj za posledných šesť mesiacov roku 2023 a rozšírenia do roku 2024. Táto dôvera môže informovať strategické rozhodnutia o riadení zásob, obstarávaní surovín a ďalších aspektoch súvisiacich s podnikom.