Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Zrkadlenie v službe Fabric ponúka jednoduchý spôsob, ako sa vyhnúť zložitým procesom ETL (Extract, Transform, Load) a bezproblémovo integrovať existujúce údaje skladu Google BigQuery so zvyškom údajov v službe Fabric. Údaje Google BigQuery môžete priebežne replikovať priamo do OneLake služby Fabric. V službe Fabric môžete využívať výkonné možnosti pre business intelligence, AI, dátové inžinierstvo, dátovú vedu a zdieľanie údajov.
Kurz konfigurácie databázy Google BigQuery na zrkadlenie v službe Fabric nájdete v téme Kurz: Konfigurácia zrkadlených databáz služby Microsoft Fabric zo služby Google BigQuery.
Dôležité
Zrkadlenie pre Google BigQuery je teraz v ukážke. Produkčné vyťaženia nie sú počas ukážky podporované.
Prečo používať zrkadlenie v Fabric?
Zrkadlenie v Microsoft Fabric odstraňuje zložitosť spájania nástrojov od rôznych poskytovateľov. Nie je potrebné migrovať vaše údaje. Pripojte sa k údajom Google BigQuery takmer v reálnom čase a používajte množstvo analytických nástrojov služby Fabric. Fabric tiež bezproblémovo spolupracuje s produktmi spoločnosti Microsoft, Google BigQuery a širokou škálou technológií, ktoré podporujú formát tabuľky Delta Lake s otvoreným zdrojovým kódom.
V akých analytických prostrediach sú zabudované?
Zrkadlenie vytvorí v pracovnom priestore služby Fabric dve položky:
- Zrkadlená položka databázy. Zrkadlenie spravuje replikáciu údajov do OneLake a konverziu do Parquetu vo formáte pripravenom na analýzu. Zrkadlenie umožňuje nadväzujúce scenáre, ako je dátové inžinierstvo, dátová veda a ďalšie. Zrkadlené databázy sa líšia od položiek koncových bodov skladu a analýzy SQL.
- Koncový bod analýzy SQL
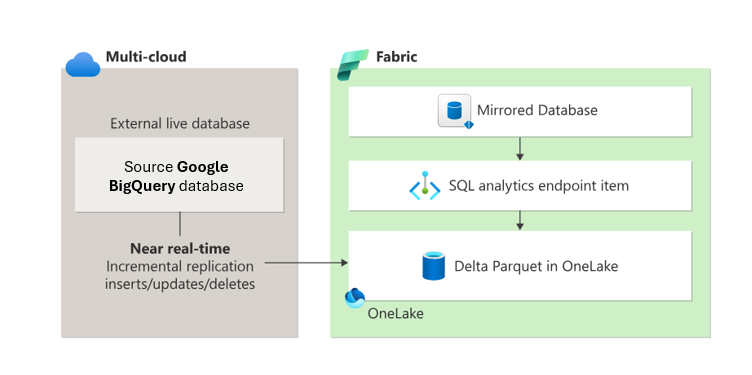
Z každej zrkadlenej databázy poskytuje koncový bod analýzy SQL analytické prostredie iba na čítanie nad tabuľkami Delta vytvorenými počas zrkadlenia. Tento koncový bod podporuje syntax T-SQL na definovanie a dotazovanie dátových objektov, ale neumožňuje priame zmeny údajov, pretože údaje sú iba na čítanie.
Pomocou koncového bodu analýzy SQL môžete:
- Prehľadávajte tabuľky, ktoré odkazujú na vaše údaje Delta Lake zrkadlené z nástroja BigQuery.
- Vytvárajte dotazy a zobrazenia bez kódu a vizuálne skúmajte údaje – nie je potrebný žiadny SQL.
- Vytvárajte zobrazenia SQL, vnorené funkcie s hodnotami tabuľky (TVF) a uložené procedúry na vrstvenie obchodnej logiky pomocou jazyka T-SQL.
- Nastavenie a správa povolení k objektom.
- Dotazujte sa na údaje v iných skladoch a jazerách v rámci rovnakého pracovného priestoru.
Okrem editora dotazov SQL existuje široký ekosystém nástrojov, ktoré môžu dotazovať koncový bod analýzy SQL, vrátane SQL Server Management Studio (SSMS),rozšírenia mssql s Visual Studio Code a dokonca aj GitHub Copilot.
Bezpečnostné aspekty
Existujú špecifické požiadavky na povolenie používateľských povolení na povolenie zrkadlenia štruktúry.
Fabric tiež poskytuje funkcie ochrany údajov na spravovanie prístupu v rámci Microsoft Fabric. Ďalšie informácie nájdete v našej dokumentácii k funkciám ochrany údajov.
Dôležité informácie o nákladoch na zrkadlený nástroj BigQuery
Výpočtové prostriedky Fabric používané na replikáciu údajov do Fabric OneLake sú bezplatné. Náklady na ukladací priestor zrkadlenia sú bezplatné až do limitu založeného na kapacite. Výpočty na dotazovanie údajov pomocou SQL, Power BI alebo Sparku sa účtujú bežnými sadzbami.
Fabric neúčtuje poplatky za vstup do siete do OneLake for Mirroring.
Pri zrkadlení údajov sa účtujú náklady na výpočty a cloudové dotazy Google BigQuery: BigQuery Change Data Capture (CDC) využíva výpočty BigQuery na úpravu riadkov, rozhranie Storage Write API na príjem údajov, úložisko BigQuery na ukladanie údajov, ktoré sú spojené s nákladmi.
Ďalšie informácie o nákladoch na zrkadlenie Google BigQuery nájdete vo vysvetlení cien.