Integrácia služby OneLake so službou Azure HDInsight
Azure HDInsight je spravovaná cloudová služba na analýzu veľkého objemu údajov, ktorá pomáha organizáciám spracovávať veľké objemy údajov. Tento kurz ukazuje, ako sa pripojiť k službe OneLake pomocou notebooku Jupyter z klastra Azure HDInsight.
Používanie azure HDInsight
Pripojenie k OneLake pomocou notebooku Jupyter zo klastra HDInsight:
Vytvorte klaster Apache Spark HDInsight (HDI). Postupujte podľa týchto pokynov: Nastavte klastre v HDInsight.
Pri zadávaní informácií o klastri si zapamätajte meno používateľa a heslo pre prihlásenie do klastra, pretože ich budete potrebovať na neskorší prístup do klastra.
Vytvorte používateľa s priradenou spravovanou identitou (UAMI): Vytvorte ju pre službu Azure HDInsight – UAMI a vyberte ju ako identitu na obrazovke úložiska .
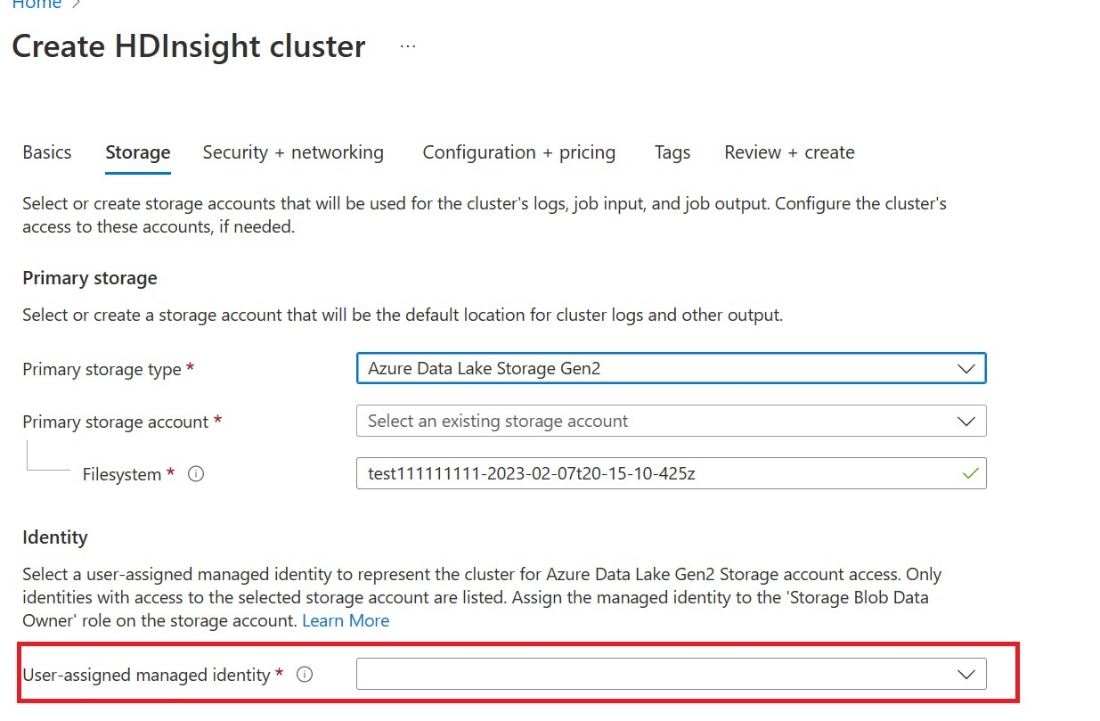
Poskytnite tomuto UAMI prístup k pracovnému priestoru služby Fabric, ktorý obsahuje vaše položky. Pomoc pri rozhodovaní o tom, ktorá rola je najvhodnejšia, nájdete v téme Roly pracovného priestoru.
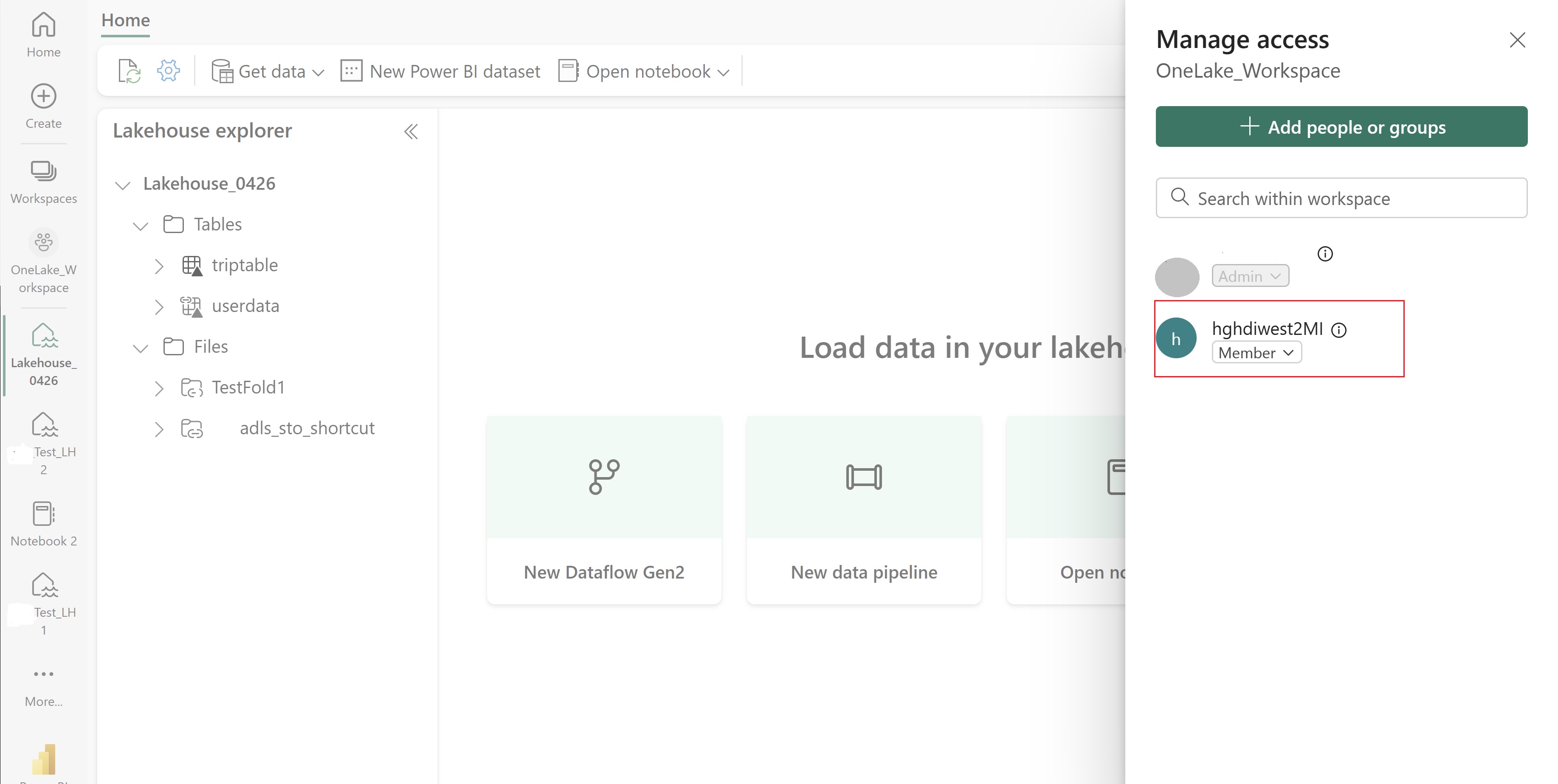
Prejdite do svojho jazera a vyhľadajte názov svojho pracovného priestoru a domova jazier. Nájdete ich v URL adrese svojho jazera alebo na table Vlastnosti pre súbor.
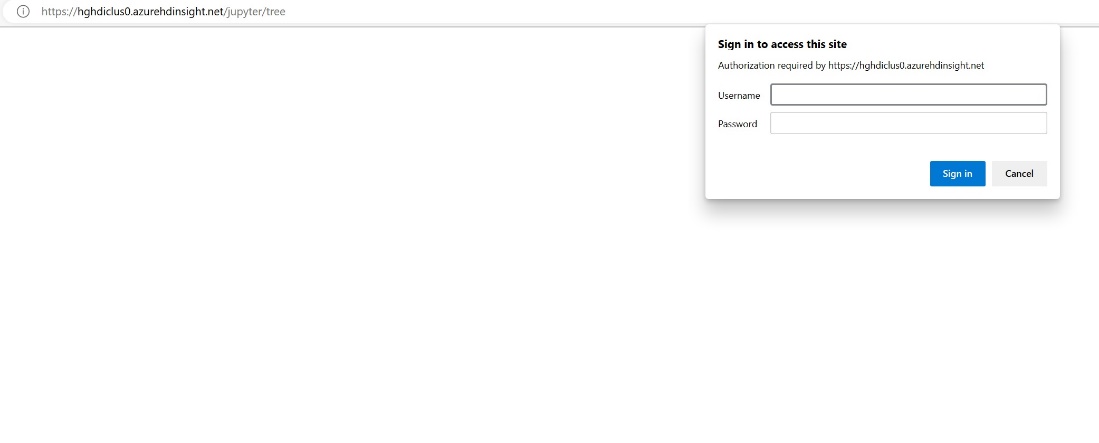
Na portáli Azure vyhľadajte svoj klaster a vyberte poznámkový blok.

Zadajte informácie o poverení, ktoré ste zadali pri vytváraní klastra.
Vytvorte nový notebook Apache Spark.
Skopírujte názvy pracovných priestorov a domov lakehouse do notebooku a vytvorte URL adresu služby OneLake pre váš domov lakehouse. Teraz si môžete prečítať ľubovoľný súbor z tejto cesty k súboru.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Skúste napísať nejaké údaje do jazera.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Overte si, či sa vaše údaje úspešne zapísali kontrolou vášho jazera alebo po prečítaní novo načítaného súboru.




Teraz môžete čítať a zapisovať údaje vo OneLake pomocou notebooku Jupyter v klastri HDI Spark.
Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre