Scenáre vypočítanej tabuľky a prípady použitia
Používanie vypočítaných tabuliek v toku údajov prináša výhody. Tento článok popisuje prípady použitia pre vypočítané tabuľky a popisuje, ako fungujú na pozadí.
Čo je vypočítaná tabuľka?
Tabuľka predstavuje výstup údajov dotazu vytvoreného v toku údajov po obnovení toku údajov. Predstavuje údaje zo zdroja a voliteľne aj transformácie, ktoré boli naň použité. Niekedy možno budete chcieť vytvoriť nové tabuľky, ktoré budú funkciou predtým preloženej tabuľky.
Napriek tomu, že je možné zopakovať dotazy, ktoré vytvorili tabuľku, a použiť pre ne nové transformácie, tento prístup má nevýhody: údaje sa prenesú dvakrát a zaťaženie zdroja údajov sa zdvojí.
Vypočítané tabuľky riešia oba problémy. Vypočítané tabuľky sú podobné ako v iných tabuľkách v tom, že získavajú údaje zo zdroja, a na ich vytvorenie môžete použiť ďalšie transformácie. Ich údaje však pochádzajú z použitého toku údajov úložiska, nie z pôvodného zdroja údajov. To znamená, že predtým boli vytvorené tokom údajov a potom sa znova použili.
Vypočítané tabuľky možno vytvoriť odkazom na tabuľku v tom istom toku údajov alebo odkazom na tabuľku vytvorenú v inom toku údajov.

Prečo používať vypočítanú tabuľku?
Vykonávanie všetkých krokov transformácie v jednej tabuľke môže byť pomalé. Spomalenie môže mať mnoho príčin – zdroj údajov môže byť pomalý alebo možno bude potrebné replikovať transformácie do dvoch alebo viacerých dotazov. Môže byť výhodné najprv prezrieť údaje zo zdroja a potom ich znova použiť v jednej alebo viacerých tabuľkách. V takýchto prípadoch sa môžete rozhodnúť vytvoriť dve tabuľky: jednu, ktorá získava údaje zo zdroja údajov, a druhú , vypočítanú tabuľku, ktorá použije viac transformácií na údaje už zapísané do dátového jazera, ktoré používa tok údajov. Táto zmena môže zvýšiť výkon a opätovnú využiteľnosť údajov, čím šetrí čas a zdroje.
Ak napríklad dve tabuľky zdieľajú aj časť svojej logiky transformácie bez vypočítanej tabuľky, transformácia sa musí vykonať dvakrát.
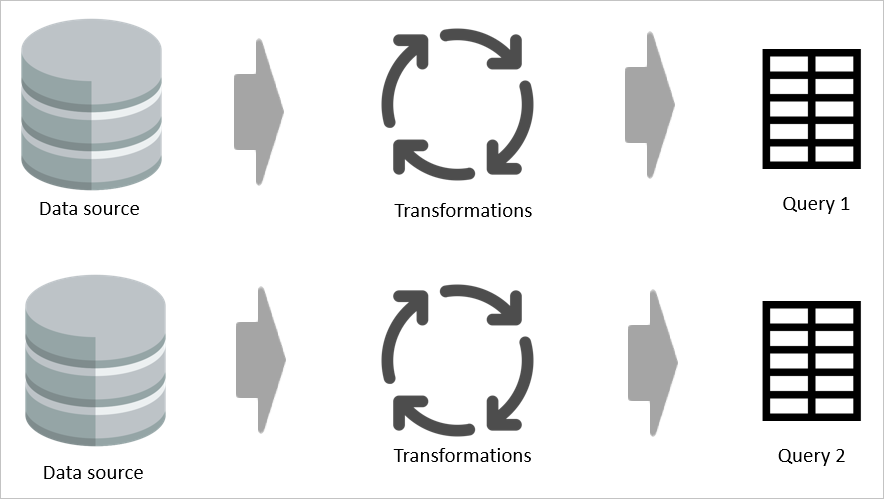
Ak sa však použije vypočítaná tabuľka, bežná (zdieľaná) časť transformácie sa spracuje raz a uloží v úložisku Azure Data Lake Storage. Zostávajúce transformácie sa potom spracujú z výstupu spoločnej transformácie. Celkovo je spracovanie omnoho rýchlejšie.
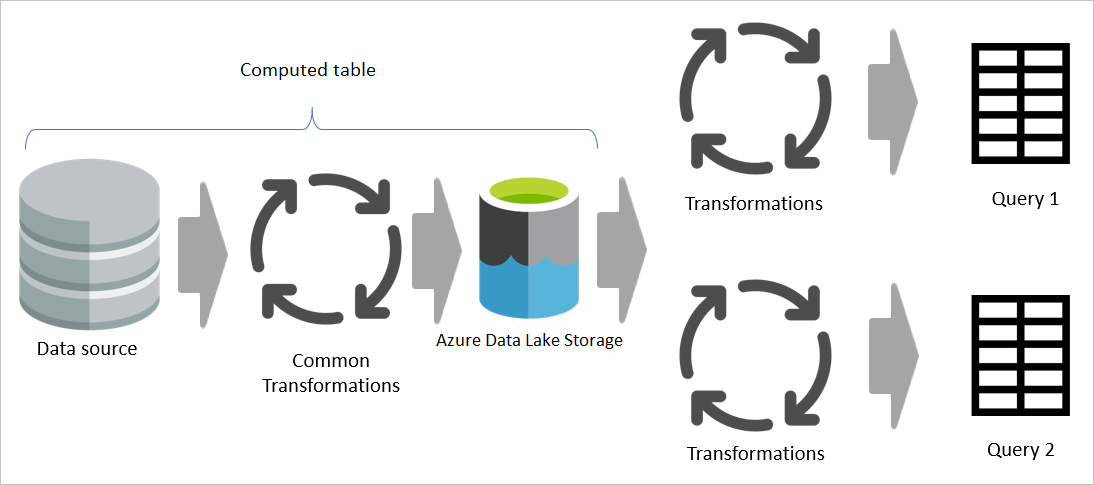
Vypočítaná tabuľka poskytuje jedno miesto ako zdrojový kód transformácie a urýchľuje transformáciu, pretože ju je potrebné vykonať iba raz namiesto viackrát. Zaťaženie zdroja údajov je tiež znížené.
Príklad scenára použitia vypočítanej tabuľky
Ak vytvárate agregovanú tabuľku v službe Power BI na urýchlenie dátového modelu, môžete vytvoriť agregovanú tabuľku odkazom na pôvodnú tabuľku a použitím ďalších transformácií. Pomocou tohto prístupu nemusíte replikovať transformáciu zo zdroja (časť, ktorá je z pôvodnej tabuľky).
Na nasledujúcom obrázku je napríklad znázornená tabuľka Objednávky.

Pomocou odkazu z tejto tabuľky môžete vytvoriť vypočítanú tabuľku.
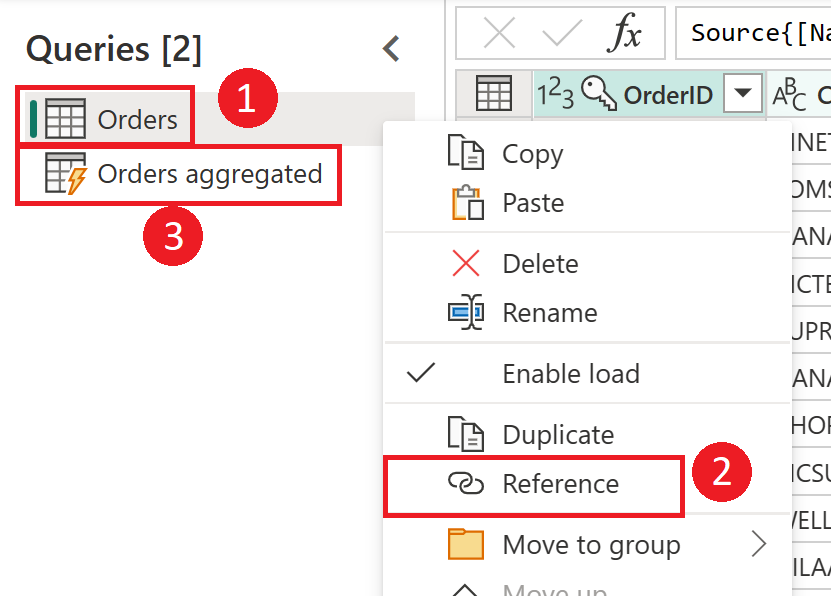
Snímka obrazovky znázorňujúca spôsob vytvorenia vypočítanej tabuľky z tabuľky Orders. Najprv kliknite pravým tlačidlom myši na tabuľku Orders na table Dotazy a v rozbaľovacej ponuke vyberte možnosť Odkaz. Táto akcia vytvorí vypočítanú tabuľku, ktorá sa tu premenuje na Agregované objednávky.
Vypočítaná tabuľka môže mať ďalšie transformácie. Údaje môžete napríklad agregovať na úrovni zákazníka pomocou Zoskupiť podľa.
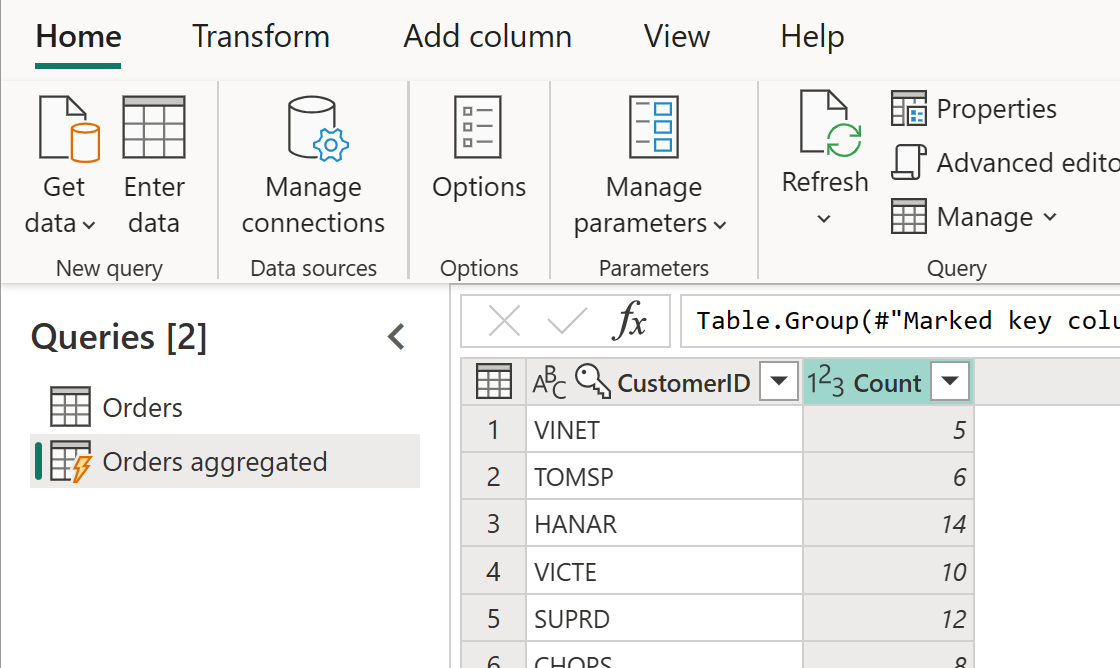
To znamená, že tabuľka Agregované objednávky získava údaje z tabuľky Objednávky a nie údaje zo zdroja údajov. Keďže niektoré transformácie, ktoré je potrebné vykonať, už boli vykonané v tabuľke Orders (Objednávky), výkon je lepší a transformácia údajov je rýchlejšia.
Vypočítaná tabuľka v iných tokoch údajov
Môžete tiež vytvoriť vypočítanú tabuľku v iných tokoch údajov. Dá sa vytvoriť tak, že získava údaje z toku údajov pomocou konektora toku údajov Microsoft Power Platform.
Obrázok zdôrazňuje konektor tokov údajov Power Platform v okne Vybrať zdroj údajov doplnku Power Query. Súčasťou tohto popisu je aj popis, podľa ktorého môže byť jedna tabuľka toku údajov vytvorená na základe údajov z inej tabuľky toku údajov, ktorá už je uložená v úložisku.
Koncept vypočítanej tabuľky spočíva v tom, že tabuľka bude uložená v úložisku a z nej budú pochádzať ďalšie tabuľky, aby ste mohli skrátiť čas čítania zo zdroja údajov a zdieľať niektoré bežné transformácie. Toto zníženie sa dá dosiahnuť tak, že sa údaje z iných tokov údajov dostanú cez konektor toku údajov alebo na iný dotaz v tom istom toku údajov.
Vypočítaná tabuľka: S transformáciami alebo bez?
Teraz, keď viete, že vypočítané tabuľky sú skvelé na zlepšenie výkonu transformácie údajov, je vhodné položiť otázku, či by mali byť transformácie vždy odložené na vypočítanú tabuľku alebo či by sa mali použiť v zdrojovej tabuľke. Mali by sa údaje vždy preniesť do jednej tabuľky a potom transformovať vo vypočítanej tabuľke? Aké sú výhody a nevýhody?
Načítanie údajov bez transformácie pre textové alebo CSV súbory
Ak zdroj údajov nepodporuje skladanie dotazov (napríklad textové/CSV súbory), pri získavaní údajov zo zdroja je použitie transformácií len malé výhody, najmä ak sú objemy údajov veľké. Zdrojová tabuľka by mala načítať údaje zo súboru Text/CSV bez použitia transformácií. Vypočítané tabuľky potom môžu získať údaje zo zdrojovej tabuľky a vykonať transformáciu na základe ingestovaných údajov.
Môžete sa spýtať, aká je hodnota vytvorenia zdrojovej tabuľky, ktorá len prehodí údaje? Takáto tabuľka môže byť užitočná, pretože ak sa údaje zo zdroja používajú vo viacerých tabuľkách, znižuje zaťaženie zdroja údajov. Okrem toho môžu údaje teraz opakovane použiť iní ľudia a toky údajov. Vypočítané tabuľky sú užitočné najmä v prípadoch, keď je objem údajov veľký alebo keď sa k zdroju údajov pristupuje cez lokálnu bránu údajov, pretože znižujú prenosy z brány a zaťaženie zdrojov údajov v ich pozadí.
Niektoré z bežných transformácií pre tabuľku SQL
Ak zdroj údajov podporuje postupné posúvanie dotazov, je vhodné vykonať niektoré transformácie v zdrojovej tabuľke, pretože dotaz sa postupne posúva do zdroja údajov a načítanie z neho sa načíta iba transformované údaje. Tieto zmeny zlepšujú celkový výkon. Množina transformácií, ktorá je bežná v následných vypočítaných tabuľkách, by sa mala použiť v zdrojovej tabuľke, aby sa mohli postupne posúvať na zdroj. Ďalšie transformácie, ktoré sa vzťahujú len na následné tabuľky, by sa mali vykonať vo vypočítaných tabuľkách.