Reliability in Azure Event Grid and Event Grid namespace
This article contains detailed information on Event Grid and Event Grid namespace regional resiliency with availability zones and cross-region disaster recovery and business continuity.
For an architectural overview of reliability in Azure, see Azure reliability.
Availability zone support
Azure availability zones are at least three physically separate groups of datacenters within each Azure region. Datacenters within each zone are equipped with independent power, cooling, and networking infrastructure. In the case of a local zone failure, availability zones are designed so that if the one zone is affected, regional services, capacity, and high availability are supported by the remaining two zones.
Failures can range from software and hardware failures to events such as earthquakes, floods, and fires. Tolerance to failures is achieved with redundancy and logical isolation of Azure services. For more detailed information on availability zones in Azure, see Regions and availability zones.
Azure availability zones-enabled services are designed to provide the right level of reliability and flexibility. They can be configured in two ways. They can be either zone redundant, with automatic replication across zones, or zonal, with instances pinned to a specific zone. You can also combine these approaches. For more information on zonal vs. zone-redundant architecture, see Recommendations for using availability zones and regions.
Event Grid resource definitions for topics, system topics, domains, and event subscriptions and event data are automatically replicated across three availability zones. When there's a regional failure in one of the availability zones, Event Grid resources automatically failover to another availability zone without human intervention. Currently, it isn't possible for you to control (enable or disable) this feature. When an existing region starts supporting availability zones, existing Event Grid resources are automatically failed over to take advantage of this feature. No customer action is required.
Azure Event Grid namespace also achieves intra-region high availability using availability zones.
Prerequisites
For availability zone support, your Event Grid resources must be in a region that supports availability zones. To review which regions support availability zones, see the list of supported regions.
Pricing
Because Event Grid supports availability zones automatically in regions that support availability zones, there are no changes in price.
Create a resource with availability zones enabled
Because Event Grid supports availability zones automatically in regions that support availability zones, there is no required setup configuration.
Migrate to availability zone support
If you relocate your Event Grid resources to a region that supports availability zones, you automatically receive availability zone support. To learn how to relocate your resources to another region that supports availability zones, see the following:
- Relocate Azure Event Grid system topics to another region
- Relocate Azure Event Grid custom topics to another region
- Relocate Azure Event Grid domains to another region
Cross-region disaster recovery and business continuity
Disaster recovery (DR) is about recovering from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you begin to think about creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
When it comes to DR, Microsoft uses the shared responsibility model. In a shared responsibility model, Microsoft ensures that the baseline infrastructure and platform services are available. At the same time, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you are responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR and you can use service-specific features to support fast recovery to help develop your DR plan.
Disaster recovery typically involves creating a backup resource to prevent interruptions when a region becomes unhealthy. During this process a primary and secondary region of Azure Event Grid resources will be needed in your workload.
There are different ways to recover from a severe loss of application functionality. In this section, we describe the checklist you'll need to follow to prepare your client to recover from a failure due to an unhealthy resource or region.
Event Grid supports both manual and automatic geo disaster recovery (GeoDR) on the server side. You can still implement client-side disaster recovery logic if you want a greater control on the failover process. For details about automatic GeoDR, see Server-side geo disaster recovery in Azure Event Grid. For details on how to implement client-side disaster recovery, see Client-side failover implementation in Azure Event Grid.
The following table illustrates the client-side failover and geo disaster recovery support in Event Grid.
| Event Grid resource | Client-side failover support | Geo disaster recovery (GeoDR) support |
|---|---|---|
| Custom Topics | Supported | Cross-Geo / Regional |
| System Topics | Not supported | Enabled automatically |
| Domains | Supported | Cross-Geo / Regional |
| Partner Namespaces | Supported | Not supported |
| Namespaces | Supported | Not supported |
Event grid namespace
Event Grid namespace doesn't support cross-region DR. However, you can achieve cross region high availability through client-side failover implementation by creating primary and secondary namespaces.
With a client-side failover implementation, you can:
Implement a custom (manual or automated) process to replicate namespace, client identities, and other configurations** including CA certificates, client groups, topic spaces, permission bindings, routing, between primary and secondary regions.
Implement a concierge service that provides clients with primary and secondary endpoints by performing a health check on endpoints. The concierge service can be a web application that is replicated and kept reachable using DNS-redirection techniques, for example, using Azure Traffic Manager.
Achieve an Active-Active DR solution by replicating the metadata and balancing load across the namespaces. An Active-Passive DR solution can be achieved by replicating the metadata to keep the secondary namespace ready so that when the primary namespace is unavailable, the traffic can be directed to secondary namespace.
Set up disaster recovery
For regions that are paired, Event Grid offers a capability to fail over the publishing traffic to the paired region for custom topics, system topics, and domains. Behind the scenes, Event Grid automatically synchronizes resource definitions of topics, system topics, domains, and event subscriptions to the paired region. However, event data isn't replicated to the paired region. In the normal state, events are stored in the region you selected for that resource. When there's a region outage and Microsoft initiates the failover, new events begin to flow to the geo-paired region and are dispatched from there with no intervention from you. Events published and accepted in the original region are dispatched from there after the outage is mitigated.
You can choose between two failover options, Microsoft-initiated failover and customer initiated. For detailed steps on how to configure both of these settings, see Configure data residency.
Microsoft-initiated failover is exercised by Microsoft in rare situations to fail over Event Grid resources from an affected region to the corresponding geo-paired region. Microsoft reserves the right to determine when this option will be exercised. This mechanism doesn't involve a user consent before the user's traffic is failed over.
Enable this functionality by updating the configuration for your topic or domain. Select Cross-Geo (default) to enable Microsoft-initiated failover.
Customer-initiated failover is defined by your custom disaster recovery plan for Azure Event Grid topics and domains, an no data of any kind is replicated to another region by Microsoft. While this failover option requires a bit more effort, it enables faster failover, and you are in control of choosing secondary regions. If you want to implement client-side disaster recovery for Azure Event Grid topics, see Build your own client-side disaster recovery for Azure Event Grid topics.
There are a few reasons why you may want to disable the Microsoft-initiated failover feature:
- Microsoft-initiated failover is done on a best-effort basis.
- Some geo pairs don't meet your organization's data residency requirements.
Enable this functionality by updating the configuration for your topic or domain. Select Regional.
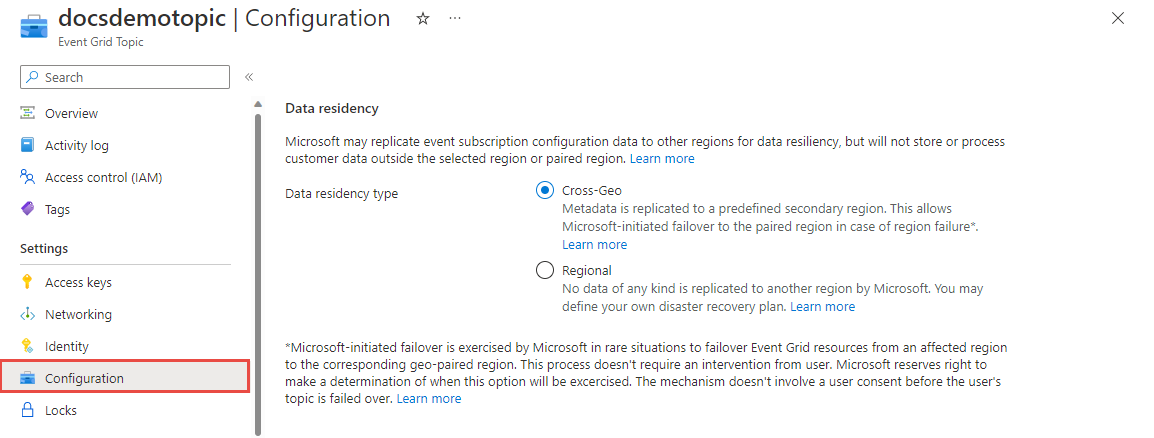
If you use a non-paired region, then regardless of the data residency configuration you select, your metadata will only be replicated within the region.
Disaster recovery failover experience
Disaster recovery is measured with two metrics, Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
Event Grid’s automatic failover has different RPOs and RTOs for your metadata (topics, domains, event subscriptions) and data (events). If you need different specification from the following ones, you can still implement your own client-side failover using the topic health APIs.
Recovery point objective (RPO)
Metadata RPO: zero minutes. For applicable resources, when a resource is created/updated/deleted, the resource definition is synchronously replicated to the geo-pair. When a failover occurs, no metadata is lost.
Data RPO: When a failover occurs, new data is processed from the paired region. As soon as the outage is mitigated for the affected region, the unprocessed events are dispatched from there. If the region recovery required longer time than the time-to-live value set on events, the data could get dropped. To mitigate this data loss, we recommend that you set up a dead-letter destination for an event subscription. If the affected region is lost and nonrecoverable, there will be some data loss. In the best-case scenario, the subscriber is keeping up with the publishing rate and only a few seconds of data is lost. The worst-case scenario would be when the subscriber isn't actively processing events and with a max time to live of 24 hours, the data loss can be up to 24 hours.
Recovery time objective (RTO)
Metadata RTO: Failover decision making is based on factors like available capacity in paired region and can last in the range of 60 minutes or more. Once failover is initiated, within 5 minutes, Event Grid begins to accept create/update/delete calls for topics and subscriptions.
Data RTO: Same as above information.
Important
- In case of server-side disaster recovery, if the paired region has no extra capacity to take on the additional traffic, Event Grid cannot initiate failover. The recovery is done on a best-effort basis.
- There is not charge for using this feature.
- Geo-disaster recovery is not supported for partner namespaces and partner topics.