Python-utvecklarhandbok för Azure Functions
Den här guiden är en introduktion till att utveckla Azure Functions med hjälp av Python. Artikeln förutsätter att du redan har läst utvecklarguiden för Azure Functions.
Viktigt!
Den här artikeln stöder både programmeringsmodellen v1 och v2 för Python i Azure Functions. Python v1-modellen använder en functions.json-fil för att definiera funktioner, och med den nya v2-modellen kan du i stället använda en dekoratörsbaserad metod. Den här nya metoden resulterar i en enklare filstruktur och är mer kodcentrerad. Välj v2-väljaren överst i artikeln för att lära dig mer om den nya programmeringsmodellen.
Som Python-utvecklare kanske du också är intresserad av följande ämnen:
- Visual Studio Code: Skapa din första Python-app med Visual Studio Code.
- Terminal eller kommandotolk: Skapa din första Python-app från kommandotolken med Hjälp av Azure Functions Core Tools.
- Exempel: Granska några befintliga Python-appar i webbläsaren Learn-exempel.
- Visual Studio Code: Skapa din första Python-app med Visual Studio Code.
- Terminal eller kommandotolk: Skapa din första Python-app från kommandotolken med Hjälp av Azure Functions Core Tools.
- Exempel: Granska några befintliga Python-appar i webbläsaren Learn-exempel.
Utvecklingsalternativ
Båda Python Functions-programmeringsmodellerna stöder lokal utveckling i någon av följande miljöer:
Python v2-programmeringsmodell:
Programmeringsmodell för Python v1:
Du kan också skapa Python v1-funktioner i Azure Portal.
Dricks
Även om du kan utveckla dina Python-baserade Azure-funktioner lokalt i Windows stöds Python endast på en Linux-baserad värdplan när den körs i Azure. Mer information finns i listan över operativsystem/körningskombinationer som stöds.
Programmeringsmodell
Azure Functions förväntar sig att en funktion är en tillståndslös metod i python-skriptet som bearbetar indata och genererar utdata. Som standard förväntar sig körningen att metoden implementeras som en global metod som anropas main() i filen __init__.py . Du kan också ange en alternativ startpunkt.
Du binder data till funktionen från utlösare och bindningar via metodattribut som använder egenskapen name som definieras i function.json-filen. Följande function.json-fil beskriver till exempel en enkel funktion som utlöses av en HTTP-begäran med namnet req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Baserat på den här definitionen kan den __init__.py fil som innehåller funktionskoden se ut som i följande exempel:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Du kan också uttryckligen deklarera attributtyperna och returnera typen i funktionen med hjälp av Python-typanteckningar. Detta hjälper dig att använda intelliSense- och autocomplete-funktionerna som tillhandahålls av många Python-kodredigerare.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Använd Python-anteckningarna som ingår i paketet azure.functions.* för att binda indata och utdata till dina metoder.
Azure Functions förväntar sig att en funktion är en tillståndslös metod i python-skriptet som bearbetar indata och genererar utdata. Som standard förväntar sig körningen att metoden implementeras som en global metod i filen function_app.py .
Utlösare och bindningar kan deklareras och användas i en funktion i en dekoratörsbaserad metod. De definieras i samma fil, function_app.py, som funktionerna. Följande function_app.py-fil representerar till exempel en funktionsutlösare av en HTTP-begäran.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Du kan också uttryckligen deklarera attributtyperna och returnera typen i funktionen med hjälp av Python-typanteckningar. På så sätt kan du använda IntelliSense- och autocomplete-funktionerna som tillhandahålls av många Python-kodredigerare.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Mer information om kända begränsningar med v2-modellen och deras lösningar finns i Felsöka Python-fel i Azure Functions.
Alternativ startpunkt
Du kan ändra standardbeteendet för en funktion genom att scriptFile ange egenskaperna och entryPoint i filen function.json . Följande function.json anger till exempel att körningen customentry() ska använda metoden i filen main.py som startpunkt för din Azure-funktion.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Startpunkten finns bara i filen function_app.py . Du kan dock referera till funktioner i projektet i function_app.py med hjälp av skisser eller genom att importera.
Mappstrukturen
Den rekommenderade mappstrukturen för ett Python-funktionsprojekt ser ut som i följande exempel:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Huvudprojektmappen, <project_root>, kan innehålla följande filer:
- local.settings.json: Används för att lagra appinställningar och anslutningssträng när du kör lokalt. Den här filen publiceras inte i Azure. Mer information finns i local.settings.file.
- requirements.txt: Innehåller listan över Python-paket som systemet installerar vid publicering till Azure.
- host.json: Innehåller konfigurationsalternativ som påverkar alla funktioner i en funktionsappinstans. Den här filen publiceras till Azure. Alla alternativ stöds inte när de körs lokalt. Mer information finns i host.json.
- .vscode/: (valfritt) innehåller den lagrade Visual Studio Code-konfigurationen. Mer information finns i Visual Studio Code-inställningar.
- .venv/: (Valfritt) innehåller en virtuell Python-miljö som används av lokal utveckling.
- Dockerfile: (Valfritt) Används när du publicerar projektet i en anpassad container.
- tests/: (Valfritt) Innehåller testfallen för din funktionsapp.
- .funcignore: (Valfritt) Deklarerar filer som inte ska publiceras i Azure. Den här filen innehåller vanligtvis .vscode/ för att ignorera redigeringsinställningen .venv/ för att ignorera den lokala virtuella Python-miljön, tester/ för att ignorera testfall och local.settings.json för att förhindra att lokala appinställningar publiceras.
Varje funktion har en egen kodfil och bindningskonfigurationsfil, function.json.
Den rekommenderade mappstrukturen för ett Python-funktionsprojekt ser ut som i följande exempel:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Huvudprojektmappen, <project_root>, kan innehålla följande filer:
- .venv/: (Valfritt) innehåller en virtuell Python-miljö som används av lokal utveckling.
- .vscode/: (valfritt) innehåller den lagrade Visual Studio Code-konfigurationen. Mer information finns i Visual Studio Code-inställningar.
- function_app.py: Standardplatsen för alla funktioner och deras relaterade utlösare och bindningar.
- additional_functions.py: (Valfritt) Alla andra Python-filer som innehåller funktioner (vanligtvis för logisk gruppering) som refereras i function_app.py via skisser.
- tests/: (Valfritt) Innehåller testfallen för din funktionsapp.
- .funcignore: (Valfritt) Deklarerar filer som inte ska publiceras i Azure. Den här filen innehåller vanligtvis .vscode/ för att ignorera redigeringsinställningen .venv/ för att ignorera den lokala virtuella Python-miljön, tester/ för att ignorera testfall och local.settings.json för att förhindra att lokala appinställningar publiceras.
- host.json: Innehåller konfigurationsalternativ som påverkar alla funktioner i en funktionsappinstans. Den här filen publiceras till Azure. Alla alternativ stöds inte när de körs lokalt. Mer information finns i host.json.
- local.settings.json: Används för att lagra appinställningar och anslutningssträng när den körs lokalt. Den här filen publiceras inte i Azure. Mer information finns i local.settings.file.
- requirements.txt: Innehåller listan över Python-paket som systemet installerar när det publiceras till Azure.
- Dockerfile: (Valfritt) Används när du publicerar projektet i en anpassad container.
När du distribuerar projektet till en funktionsapp i Azure bör hela innehållet i huvudprojektmappen, <project_root>, ingå i paketet, men inte själva mappen, vilket innebär att host.json ska finnas i paketroten. Vi rekommenderar att du underhåller dina tester i en mapp tillsammans med andra funktioner (i det här exemplet tester/). Mer information finns i Enhetstestning.
Anslut till en databas
Azure Functions integreras väl med Azure Cosmos DB för många användningsfall, inklusive IoT, e-handel, spel osv.
För händelsekällor är till exempel de två tjänsterna integrerade i power-händelsedrivna arkitekturer med hjälp av Azure Cosmos DB:s ändringsflödesfunktioner. Ändringsflödet ger underordnade mikrotjänster möjlighet att tillförlitligt och inkrementellt läsa infogningar och uppdateringar (till exempel orderhändelser). Den här funktionen kan användas för att tillhandahålla ett beständigt händelselager som meddelandekö för tillståndsförändrande händelser och arbetsflöde för bearbetning av order mellan många mikrotjänster (som kan implementeras som serverlösa Azure Functions).
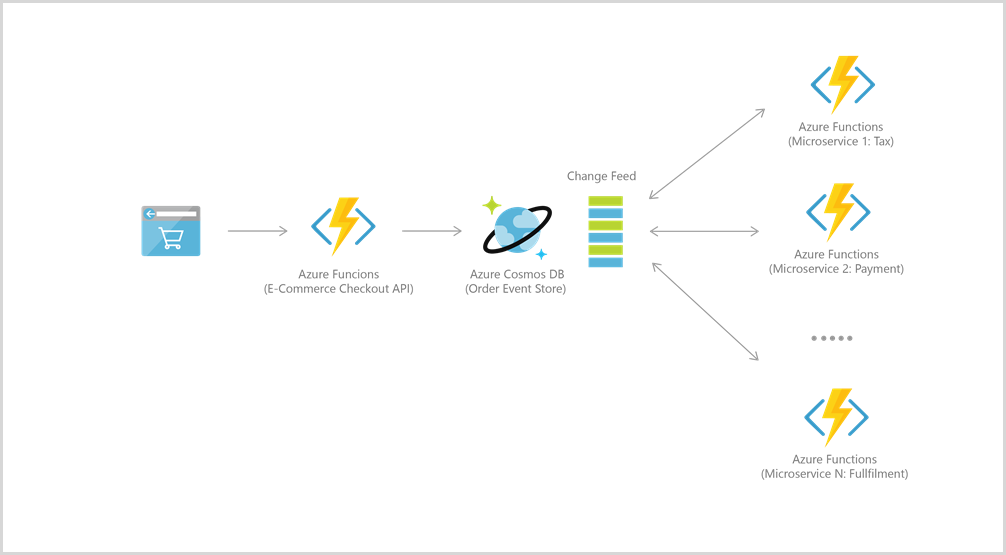
Om du vill ansluta till Azure Cosmos DB skapar du först ett konto, en databas och en container. Sedan kan du ansluta funktionskoden till Azure Cosmos DB med utlösare och bindningar, som i det här exemplet.
Om du vill implementera mer komplex applogik kan du också använda Python-biblioteket för Cosmos DB. En asynkron I/O-implementering ser ut så här:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Skisser
Programmeringsmodellen Python v2 introducerar begreppet skisser. En skiss är en ny klass som instansieras för att registrera funktioner utanför kärnfunktionsprogrammet. Funktionerna som är registrerade i skissinstanser indexeras inte direkt av funktionskörningen. För att få dessa skissfunktioner indexerade måste funktionsappen registrera funktionerna från skissinstanser.
Att använda skisser ger följande fördelar:
- Gör att du kan dela upp funktionsappen i modulära komponenter, vilket gör att du kan definiera funktioner i flera Python-filer och dela upp dem i olika komponenter per fil.
- Tillhandahåller utökningsbara offentliga funktionsappgränssnitt för att skapa och återanvända dina egna API:er.
I följande exempel visas hur du använder skisser:
I en http_blueprint.py fil definieras först en HTTP-utlöst funktion och läggs till i ett skissobjekt.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
I filen function_app.py importeras skissobjektet och dess funktioner registreras i funktionsappen.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Kommentar
Durable Functions har också stöd för skisser. Om du vill skapa skisser för Durable Functions-appar registrerar du orkestrerings-, aktivitets- och entitetsutlösare och klientbindningar med hjälp av azure-functions-durable Blueprint klassen, som du ser här. Den resulterande skissen kan sedan registreras som vanligt. Se vårt exempel för ett exempel.
Importbeteende
Du kan importera moduler i funktionskoden med hjälp av både absoluta och relativa referenser. Baserat på den tidigare beskrivna mappstrukturen fungerar följande importer inifrån funktionsfilen <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Kommentar
När du använder absolut importsyntax måste shared_code/ -mappen innehålla en __init__.py fil för att markera den som ett Python-paket.
Följande __app__ import och bortom relativ import på den översta nivån är inaktuella eftersom de inte stöds av den statiska typkontrollen och inte stöds av Python-testramverk:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Utlösare och indata
Indata är indelade i två kategorier i Azure Functions: utlösarindata och andra indata. Även om de skiljer sig åt i function.json-filen är deras användning identisk i Python-kod. Anslutningssträngar eller hemligheter för utlösare och indatakällor mappas till värden i local.settings.json-filen när de körs lokalt, och de mappas till programinställningarna när de körs i Azure.
Följande kod visar till exempel skillnaden mellan de två indata:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
När funktionen anropas skickas HTTP-begäran till funktionen som req. En post hämtas från Azure Blob Storage-kontot baserat på ID :t i routnings-URL:en och görs tillgänglig som obj i funktionstexten. Här är det angivna lagringskontot den anslutningssträng som finns i appinställningenCONNECTION_STRING.
Indata är indelade i två kategorier i Azure Functions: utlösarindata och andra indata. Även om de definieras med olika dekoratörer är deras användning liknande i Python-kod. Anslutningssträngar eller hemligheter för utlösare och indatakällor mappas till värden i local.settings.json-filen när de körs lokalt, och de mappas till programinställningarna när de körs i Azure.
Till exempel visar följande kod hur du definierar en Blob Storage-indatabindning:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
När funktionen anropas skickas HTTP-begäran till funktionen som req. En post hämtas från Azure Blob Storage-kontot baserat på ID :t i routnings-URL:en och görs tillgänglig som obj i funktionstexten. Här är det angivna lagringskontot den anslutningssträng som finns i appinställningenSTORAGE_CONNECTION_STRING.
För dataintensiva bindningsåtgärder kanske du vill använda ett separat lagringskonto. Mer information finns i Vägledning för lagringskonto.
SDK-typbindningar (förhandsversion)
För utvalda utlösare och bindningar kan du arbeta med datatyper som implementeras av underliggande Azure SDK:er och ramverk. Med dessa SDK-typbindningar kan du interagera med bindningsdata som om du använde den underliggande tjänst-SDK:t.
Viktigt!
Stöd för SDK-typbindningar kräver programmeringsmodellen Python v2.
Functions har stöd för Python SDK-typbindningar för Azure Blob Storage, vilket gör att du kan arbeta med blobdata med hjälp av den underliggande BlobClient typen.
Viktigt!
Stöd för SDK-typbindningar för Python är för närvarande i förhandsversion:
- Du måste använda programmeringsmodellen Python v2.
- För närvarande stöds endast synkrona SDK-typer.
Förutsättningar
- Azure Functions runtime version 4.34 eller en senare version.
- Python version 3.9 eller en senare version som stöds.
Aktivera SDK-typbindningar för Blob Storage-tillägget
Lägg till tilläggspaketet
azurefunctions-extensions-bindings-blobrequirements.txti filen i projektet, som bör innehålla minst följande paket:azure-functions azurefunctions-extensions-bindings-blobLägg till den
function_app.pyhär koden i filen i projektet, som importerar SDK-typbindningarna:import azurefunctions.extensions.bindings.blob as blob
Exempel på SDK-typbindningar
Det här exemplet visar hur du hämtar BlobClient från både en Blob Storage-utlösare (blob_trigger) och från indatabindningen på en HTTP-utlösare (blob_input):
import logging
import azure.functions as func
import azurefunctions.extensions.bindings.blob as blob
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.blob_trigger(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_trigger(client: blob.BlobClient):
logging.info(
f"Python blob trigger function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
@app.route(route="file")
@app.blob_input(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_input(req: func.HttpRequest, client: blob.BlobClient):
logging.info(
f"Python blob input function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
return "ok"
Du kan visa andra SDK-typbindningsexempel för Blob Storage i Python-tilläggslagringsplatsen:
HTTP-strömmar (förhandsversion)
Med HTTP-strömmar kan du acceptera och returnera data från dina HTTP-slutpunkter med hjälp av Api:er för FastAPI-begäran och svar aktiverat i dina funktioner. Med dessa API:er kan värden bearbeta stora data i HTTP-meddelanden som segment i stället för att läsa ett helt meddelande i minnet.
Den här funktionen gör det möjligt att hantera stor dataström, OpenAI-integreringar, leverera dynamiskt innehåll och stödja andra grundläggande HTTP-scenarier som kräver interaktion i realtid via HTTP. Du kan också använda FastAPI-svarstyper med HTTP-strömmar. Utan HTTP-strömmar begränsas storleken på dina HTTP-begäranden och svar av minnesbegränsningar som kan påträffas när hela meddelandenyttolasten bearbetas i minnet.
Viktigt!
Stöd för HTTP-strömmar kräver programmeringsmodellen Python v2.
Viktigt!
Stöd för HTTP-strömmar för Python är för närvarande i förhandsversion och kräver att du använder programmeringsmodellen Python v2.
Förutsättningar
- Azure Functions-körningsversion 4.34.1 eller en senare version.
- Python version 3.8 eller en senare version som stöds.
Aktivera HTTP-strömmar
HTTP-strömmar är inaktiverade som standard. Du måste aktivera den här funktionen i programinställningarna och även uppdatera koden för att använda FastAPI-paketet. Observera att när du aktiverar HTTP-strömmar kommer funktionsappen som standard att använda HTTP-strömning och den ursprungliga HTTP-funktionen fungerar inte.
Lägg till tilläggspaketet
azurefunctions-extensions-http-fastapirequirements.txti filen i projektet, som bör innehålla minst följande paket:azure-functions azurefunctions-extensions-http-fastapiLägg till den
function_app.pyhär koden i filen i projektet, som importerar FastAPI-tillägget:from azurefunctions.extensions.http.fastapi import Request, StreamingResponseNär du distribuerar till Azure lägger du till följande programinställning i funktionsappen:
"PYTHON_ENABLE_INIT_INDEXING": "1"Om du distribuerar till Linux-förbrukning lägger du även till
"PYTHON_ISOLATE_WORKER_DEPENDENCIES": "1"När du kör lokalt måste du också lägga till samma inställningar i
local.settings.jsonprojektfilen.
Exempel på HTTP-strömmar
När du har aktiverat funktionen FÖR HTTP-direktuppspelning kan du skapa funktioner som strömmar data via HTTP.
Det här exemplet är en HTTP-utlöst funktion som strömmar HTTP-svarsdata. Du kan använda dessa funktioner för att stödja scenarier som att skicka händelsedata via en pipeline för realtidsvisualisering eller identifiera avvikelser i stora datauppsättningar och tillhandahålla omedelbara meddelanden.
import time
import azure.functions as func
from azurefunctions.extensions.http.fastapi import Request, StreamingResponse
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
def generate_sensor_data():
"""Generate real-time sensor data."""
for i in range(10):
# Simulate temperature and humidity readings
temperature = 20 + i
humidity = 50 + i
yield f"data: {{'temperature': {temperature}, 'humidity': {humidity}}}\n\n"
time.sleep(1)
@app.route(route="stream", methods=[func.HttpMethod.GET])
async def stream_sensor_data(req: Request) -> StreamingResponse:
"""Endpoint to stream real-time sensor data."""
return StreamingResponse(generate_sensor_data(), media_type="text/event-stream")
Det här exemplet är en HTTP-utlöst funktion som tar emot och bearbetar strömmande data från en klient i realtid. Den visar funktioner för direktuppladdning som kan vara till hjälp för scenarier som bearbetning av kontinuerliga dataströmmar och hantering av händelsedata från IoT-enheter.
import azure.functions as func
from azurefunctions.extensions.http.fastapi import JSONResponse, Request
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="streaming_upload", methods=[func.HttpMethod.POST])
async def streaming_upload(req: Request) -> JSONResponse:
"""Handle streaming upload requests."""
# Process each chunk of data as it arrives
async for chunk in req.stream():
process_data_chunk(chunk)
# Once all data is received, return a JSON response indicating successful processing
return JSONResponse({"status": "Data uploaded and processed successfully"})
def process_data_chunk(chunk: bytes):
"""Process each data chunk."""
# Add custom processing logic here
pass
Anropa HTTP-strömmar
Du måste använda ett HTTP-klientbibliotek för att göra strömningsanrop till en funktions FastAPI-slutpunkter. Klientverktyget eller webbläsaren som du använder kanske inte har inbyggt stöd för strömning eller kan bara returnera det första datasegmentet.
Du kan använda ett klientskript som det här för att skicka strömmande data till en HTTP-slutpunkt:
import httpx # Be sure to add 'httpx' to 'requirements.txt'
import asyncio
async def stream_generator(file_path):
chunk_size = 2 * 1024 # Define your own chunk size
with open(file_path, 'rb') as file:
while chunk := file.read(chunk_size):
yield chunk
print(f"Sent chunk: {len(chunk)} bytes")
async def stream_to_server(url, file_path):
timeout = httpx.Timeout(60.0, connect=60.0)
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.post(url, content=stream_generator(file_path))
return response
async def stream_response(response):
if response.status_code == 200:
async for chunk in response.aiter_raw():
print(f"Received chunk: {len(chunk)} bytes")
else:
print(f"Error: {response}")
async def main():
print('helloworld')
# Customize your streaming endpoint served from core tool in variable 'url' if different.
url = 'http://localhost:7071/api/streaming_upload'
file_path = r'<file path>'
response = await stream_to_server(url, file_path)
print(response)
if __name__ == "__main__":
asyncio.run(main())
Utdata
Utdata kan uttryckas både i returvärden och utdataparametrar. Om det bara finns ett utdata rekommenderar vi att du använder returvärdet. För flera utdata måste du använda utdataparametrar.
Om du vill använda returvärdet för en funktion som värdet för en utdatabindning name ska bindningens egenskap anges till $return i function.json-filen.
Om du vill skapa flera utdata använder du metoden set() som tillhandahålls av azure.functions.Out gränssnittet för att tilldela bindningen ett värde. Följande funktion kan till exempel skicka ett meddelande till en kö och även returnera ett HTTP-svar.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Utdata kan uttryckas både i returvärden och utdataparametrar. Om det bara finns ett utdata rekommenderar vi att du använder returvärdet. För flera utdata måste du använda utdataparametrar.
Om du vill skapa flera utdata använder du metoden set() som tillhandahålls av azure.functions.Out gränssnittet för att tilldela bindningen ett värde. Följande funktion kan till exempel skicka ett meddelande till en kö och även returnera ett HTTP-svar.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Loggning
Åtkomst till Azure Functions-körningsloggaren är tillgänglig via en rothanterare logging i funktionsappen. Den här loggaren är kopplad till Application Insights och gör att du kan flagga varningar och fel som inträffar under funktionskörningen.
I följande exempel loggas ett informationsmeddelande när funktionen anropas via en HTTP-utlösare.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Det finns fler loggningsmetoder som gör att du kan skriva till konsolen på olika spårningsnivåer:
| Metod | beskrivning |
|---|---|
critical(_message_) |
Skriver ett meddelande med nivån CRITICAL på rotloggaren. |
error(_message_) |
Skriver ett meddelande med nivåFEL på rotloggaren. |
warning(_message_) |
Skriver ett meddelande med nivå VARNING på rotloggaren. |
info(_message_) |
Skriver ett meddelande med nivåINFORMATION på rotloggaren. |
debug(_message_) |
Skriver ett meddelande med nivå DEBUG på rotloggaren. |
Mer information om loggning finns i Övervaka Azure Functions.
Loggning från skapade trådar
Om du vill se loggar som kommer från dina skapade trådar inkluderar du context argumentet i funktionens signatur. Det här argumentet innehåller ett attribut thread_local_storage som lagrar en lokal invocation_id. Detta kan ställas in på funktionens aktuella invocation_id för att säkerställa att kontexten ändras.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Logga anpassad telemetri
Som standard samlar Functions-körningen in loggar och andra telemetridata som genereras av dina funktioner. Den här telemetrin hamnar som spårningar i Application Insights. Telemetri för förfrågningar och beroenden för vissa Azure-tjänster samlas också in som standard av utlösare och bindningar.
Om du vill samla in anpassad begäran och anpassad beroendetelemetri utanför bindningar kan du använda OpenCensus Python-tillägg. Det här tillägget skickar anpassade telemetridata till din Application Insights-instans. Du hittar en lista över tillägg som stöds på OpenCensus-lagringsplatsen.
Kommentar
Om du vill använda OpenCensus Python-tillägg måste du aktivera Python Worker-tillägg i funktionsappen genom att ange PYTHON_ENABLE_WORKER_EXTENSIONS till 1. Du måste också växla till att använda Application Insights-anslutningssträng genom att lägga till APPLICATIONINSIGHTS_CONNECTION_STRING inställningen i dina programinställningar, om den inte redan finns där.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
HTTP-utlösare
HTTP-utlösaren definieras i filen function.json . Bindningen name måste matcha den namngivna parametern i funktionen.
I föregående exempel används ett bindningsnamn req . Den här parametern är ett HttpRequest-objekt och ett HttpResponse-objekt returneras.
Från HttpRequest-objektet kan du hämta begärandehuvuden, frågeparametrar, vägparametrar och meddelandetexten.
Följande exempel kommer från HTTP-utlösarmallen för Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
I den här funktionen hämtar du värdet för name frågeparametern från parametern params för HttpRequest-objektet . Du läser den JSON-kodade meddelandetexten get_json med hjälp av metoden .
På samma sätt kan du ange status_code och headers för svarsmeddelandet i det returnerade HttpResponse-objektet .
HTTP-utlösaren definieras som en metod som tar en namngiven bindningsparameter, som är ett HttpRequest-objekt , och returnerar ett HttpResponse-objekt . Du använder dekoratören function_name på metoden för att definiera funktionsnamnet, medan HTTP-slutpunkten anges genom att använda dekoratören route .
Det här exemplet kommer från HTTP-utlösarmallen för python v2-programmeringsmodellen, där namnet på bindningsparametern är req. Det är exempelkoden som tillhandahålls när du skapar en funktion med hjälp av Azure Functions Core Tools eller Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
Från HttpRequest-objektet kan du hämta begärandehuvuden, frågeparametrar, vägparametrar och meddelandetexten. I den här funktionen hämtar du värdet för name frågeparametern från parametern params för HttpRequest-objektet . Du läser den JSON-kodade meddelandetexten get_json med hjälp av metoden .
På samma sätt kan du ange status_code och headers för svarsmeddelandet i det returnerade HttpResponse-objektet .
Om du vill skicka in ett namn i det här exemplet klistrar du in den URL som angavs när du kör funktionen och lägger sedan till den med "?name={name}".
Webbramverk
Du kan använda webservergatewaygränssnitt (WSGI)-kompatibla och Asynkrona ASGI-kompatibla ramverk (Server Gateway Interface), till exempel Flask och FastAPI, med dina HTTP-utlösta Python-funktioner. Det här avsnittet visar hur du ändrar dina funktioner för att stödja dessa ramverk.
Först måste function.json-filen uppdateras för att inkludera en route i HTTP-utlösaren, som du ser i följande exempel:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Den host.json filen måste också uppdateras för att inkludera en HTTP routePrefix, enligt följande exempel:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Uppdatera Python-kodfilen init.py, beroende på vilket gränssnitt som används av ditt ramverk. I följande exempel visas antingen en ASGI-hanteringsmetod eller en WSGI-omslutningsmetod för Flask:
Du kan använda Asynkrona ASGI-kompatibla ramverk (Server Gateway Interface) och WSGI-kompatibla ramverk (Web Server Gateway Interface), till exempel Flask och FastAPI, med dina HTTP-utlösta Python-funktioner. Du måste först uppdatera host.json-filen så att den innehåller en HTTP routePrefix, som du ser i följande exempel:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Ramverkskoden ser ut som i följande exempel:
AsgiFunctionApp är den översta funktionsappklassen för att konstruera ASGI HTTP-funktioner.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Skalning och prestanda
Metodtips för skalning och prestanda för Python-funktionsappar finns i artikeln Python-skalning och prestanda .
Kontext
Om du vill hämta anropskontexten för en funktion när den körs tar du med argumentet i signaturen context .
Till exempel:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Klassen Context har följande strängattribut:
| Attribut | beskrivning |
|---|---|
function_directory |
Katalogen där funktionen körs. |
function_name |
Namnet på funktionen. |
invocation_id |
ID:t för den aktuella funktionsanropet. |
thread_local_storage |
Den lokala trådlagringen av funktionen. Innehåller en lokal invocation_id för loggning från skapade trådar. |
trace_context |
Kontexten för distribuerad spårning. Mer information finns i Trace Context. |
retry_context |
Kontexten för återförsök till funktionen. Mer information finns i retry-policies. |
Globala variabler
Det är inte garanterat att appens tillstånd bevaras för framtida körningar. Azure Functions-körningen återanvänder dock ofta samma process för flera körningar av samma app. Om du vill cachelagra resultatet av en dyr beräkning deklarerar du den som en global variabel.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Miljövariabler
I Azure Functions exponeras programinställningar, till exempel tjänst anslutningssträng, som miljövariabler när de körs. Det finns två huvudsakliga sätt att komma åt de här inställningarna i koden.
| Metod | beskrivning |
|---|---|
os.environ["myAppSetting"] |
Försöker hämta programinställningen efter nyckelnamn och genererar ett fel när den misslyckas. |
os.getenv("myAppSetting") |
Försöker hämta programinställningen efter nyckelnamn och returnerar null när den misslyckas. |
Båda dessa sätt kräver att du deklarerar import os.
I följande exempel används os.environ["myAppSetting"] för att hämta programinställningen med nyckeln med namnet myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
För lokal utveckling underhålls programinställningarna i filen local.settings.json.
I Azure Functions exponeras programinställningar, till exempel tjänst anslutningssträng, som miljövariabler när de körs. Det finns två huvudsakliga sätt att komma åt de här inställningarna i koden.
| Metod | beskrivning |
|---|---|
os.environ["myAppSetting"] |
Försöker hämta programinställningen efter nyckelnamn och genererar ett fel när den misslyckas. |
os.getenv("myAppSetting") |
Försöker hämta programinställningen efter nyckelnamn och returnerar null när den misslyckas. |
Båda dessa sätt kräver att du deklarerar import os.
I följande exempel används os.environ["myAppSetting"] för att hämta programinställningen med nyckeln med namnet myAppSetting:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
För lokal utveckling underhålls programinställningarna i filen local.settings.json.
Python-version
Azure Functions stöder följande Python-versioner:
| Funktionsversion | Python*-versioner |
|---|---|
| 4.x | 3.11 3,10 3.9 3,8 3.7 |
| 3.x | 3.9 3,8 3.7 |
* Officiella Python-distributioner
Om du vill begära en specifik Python-version när du skapar din funktionsapp i Azure använder --runtime-version du alternativet för az functionapp create kommandot . Functions-körningsversionen anges av --functions-version alternativet . Python-versionen anges när funktionsappen skapas och den kan inte ändras för appar som körs i en förbrukningsplan.
Körningen använder den tillgängliga Python-versionen när du kör den lokalt.
Ändra Python-version
Om du vill ange en Python-funktionsapp till en specifik språkversion måste du ange språket och språkversionen i LinuxFxVersion fältet i platskonfigurationen. Om du till exempel vill ändra Python-appen så att den använder Python 3.8 anger du linuxFxVersion till python|3.8.
Information om hur du visar och ändrar webbplatsinställningen linuxFxVersion finns i Så här riktar du dig till Azure Functions-körningsversioner.
Mer allmän information finns i supportprincipen för Azure Functions-körning och språk som stöds i Azure Functions.
Pakethantering
När du utvecklar lokalt med hjälp av Core Tools eller Visual Studio Code lägger du till namn och versioner av de nödvändiga paketen i filen requirements.txt och installerar dem sedan med hjälp pipav .
Du kan till exempel använda följande requirements.txt fil och pip kommando för att installera requests paketet från PyPI.
requests==2.19.1
pip install -r requirements.txt
När du kör dina funktioner i en App Service-plan får beroenden som du definierar i requirements.txt företräde framför inbyggda Python-moduler, till exempel logging. Den här prioriteten kan orsaka konflikter när inbyggda moduler har samma namn som kataloger i koden. När du kör en förbrukningsplan eller en Elastic Premium-plan är konflikter mindre sannolika eftersom dina beroenden inte prioriteras som standard.
Om du vill förhindra problem som körs i en App Service-plan ska du inte namnge dina kataloger på samma sätt som eventuella inbyggda Python-moduler och inte inkludera inbyggda Python-bibliotek i projektets requirements.txt-fil.
Publicera i Azure
När du är redo att publicera kontrollerar du att alla dina offentligt tillgängliga beroenden visas i filen requirements.txt . Du kan hitta den här filen i roten i projektkatalogen.
Du hittar de projektfiler och mappar som undantas från publicering, inklusive mappen för den virtuella miljön, i rotkatalogen för projektet.
Det finns tre byggåtgärder som stöds för publicering av Python-projektet till Azure: fjärrversion, lokal version och versioner med hjälp av anpassade beroenden.
Du kan också använda Azure Pipelines för att skapa dina beroenden och publicera med hjälp av kontinuerlig leverans (CD). Mer information finns i Kontinuerlig leverans med Azure Pipelines.
Fjärrbygge
När du använder fjärrversion matchar beroenden som återställs på servern och interna beroenden produktionsmiljön. Detta resulterar i ett mindre distributionspaket att ladda upp. Använd fjärrbygge när du utvecklar Python-appar i Windows. Om projektet har anpassade beroenden kan du använda fjärrversion med extra index-URL.
Beroenden hämtas via fjärranslutning baserat på innehållet i den requirements.txt filen. Fjärrversion är den rekommenderade byggmetoden. Som standard begär Core Tools en fjärrversion när du använder följande func azure functionapp publish kommando för att publicera ditt Python-projekt till Azure.
func azure functionapp publish <APP_NAME>
Kom ihåg att ersätta <APP_NAME> med namnet på funktionsappen i Azure.
Azure Functions-tillägget för Visual Studio Code begär också en fjärrversion som standard.
Lokal version
Beroenden hämtas lokalt baserat på innehållet i den requirements.txt filen. Du kan förhindra att en fjärrversion utförs med hjälp av följande func azure functionapp publish kommando för att publicera med en lokal version:
func azure functionapp publish <APP_NAME> --build local
Kom ihåg att ersätta <APP_NAME> med namnet på funktionsappen i Azure.
När du använder --build local alternativet läss projektberoenden från filen requirements.txt och de beroende paketen laddas ned och installeras lokalt. Projektfiler och beroenden distribueras från din lokala dator till Azure. Detta resulterar i att ett större distributionspaket laddas upp till Azure. Om du av någon anledning inte kan hämta requirements.txt-filen med hjälp av Core Tools måste du använda alternativet anpassade beroenden för publicering.
Vi rekommenderar inte att du använder lokala versioner när du utvecklar lokalt i Windows.
Anpassade beroenden
När projektet har beroenden som inte finns i Python-paketindexet finns det två sätt att skapa projektet. Det första sättet, byggmetoden , beror på hur du skapar projektet.
Fjärrversion med extra index-URL
När dina paket är tillgängliga från ett tillgängligt anpassat paketindex använder du en fjärrversion. Innan du publicerar måste du skapa en appinställning med namnet PIP_EXTRA_INDEX_URL. Värdet för den här inställningen är URL:en för ditt anpassade paketindex. Med den här inställningen uppmanas fjärrversionen att köras pip install med hjälp --extra-index-url av alternativet . Mer information finns i Python-dokumentationenpip install.
Du kan också använda grundläggande autentiseringsuppgifter med dina extra paketindex-URL:er. Mer information finns i Grundläggande autentiseringsuppgifter i Python-dokumentationen.
Installera lokala paket
Om ditt projekt använder paket som inte är offentligt tillgängliga för våra verktyg kan du göra dem tillgängliga för din app genom att placera dem i katalogen __app__/.python_packages . Innan du publicerar kör du följande kommando för att installera beroendena lokalt:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
När du använder anpassade beroenden bör du använda publiceringsalternativet --no-build eftersom du redan har installerat beroendena i projektmappen.
func azure functionapp publish <APP_NAME> --no-build
Kom ihåg att ersätta <APP_NAME> med namnet på funktionsappen i Azure.
Enhetstestning
Funktioner som skrivs i Python kan testas som annan Python-kod med hjälp av standardtestningsramverk. För de flesta bindningar är det möjligt att skapa ett falskt indataobjekt genom att skapa en instans av en lämplig klass från azure.functions paketet. azure.functions Eftersom paketet inte är omedelbart tillgängligt måste du installera det via din requirements.txt-fil enligt beskrivningen i avsnittet om pakethantering ovan.
Med my_second_function som exempel är följande ett test av en HTTP-utlöst funktion:
Skapa först en <project_root>/my_second_function/function.json-fil och definiera sedan den här funktionen som en HTTP-utlösare.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Sedan kan du implementera my_second_function och shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Du kan börja skriva testfall för HTTP-utlösaren.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
I mappen för den .venv virtuella Python-miljön installerar du ditt favorit-Python-testramverk, till exempel pip install pytest. Kör pytest tests sedan för att kontrollera testresultatet.
<Skapa först filen project_root>/function_app.py och implementera my_second_function funktionen som HTTP-utlösare och shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Du kan börja skriva testfall för HTTP-utlösaren.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
I mappen för den virtuella Python-miljön i .venv installerar du ditt favorit-Python-testramverk, till exempel pip install pytest. Kör pytest tests sedan för att kontrollera testresultatet.
Tillfälliga filer
Metoden tempfile.gettempdir() returnerar en tillfällig mapp som i Linux är /tmp. Ditt program kan använda den här katalogen för att lagra temporära filer som genereras och används av dina funktioner när de körs.
Viktigt!
Filer som skrivs till den tillfälliga katalogen är inte garanterade att sparas mellan anrop. Under utskalning delas inte temporära filer mellan instanser.
I följande exempel skapas en namngiven temporär fil i den temporära katalogen (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Vi rekommenderar att du underhåller dina tester i en mapp som är separat från projektmappen. Den här åtgärden hindrar dig från att distribuera testkod med din app.
Förinstallerade bibliotek
Några bibliotek levereras med Python-funktionskörningen.
Python-standardbiblioteket
Python-standardbiblioteket innehåller en lista över inbyggda Python-moduler som levereras med varje Python-distribution. De flesta av dessa bibliotek hjälper dig att komma åt systemfunktioner, till exempel filindata/utdata (I/O). I Windows-system installeras dessa bibliotek med Python. I Unix-baserade system tillhandahålls de av paketsamlingar.
Om du vill visa biblioteket för python-versionen går du till:
- Python 3.8-standardbibliotek
- Python 3.9-standardbibliotek
- Python 3.10-standardbibliotek
- Python 3.11-standardbibliotek
Azure Functions Python-arbetsberoenden
Azure Functions Python-arbetaren kräver en specifik uppsättning bibliotek. Du kan också använda de här biblioteken i dina funktioner, men de ingår inte i Python-standarden. Om dina funktioner förlitar sig på något av dessa bibliotek kanske de inte är tillgängliga för din kod när den körs utanför Azure Functions.
Kommentar
Om funktionsappens requirements.txt fil innehåller en azure-functions-worker post tar du bort den. Funktionsarbetaren hanteras automatiskt av Azure Functions-plattformen och vi uppdaterar den regelbundet med nya funktioner och buggkorrigeringar. Manuellt installation av en gammal arbetsversion i requirements.txt-filen kan orsaka oväntade problem.
Kommentar
Om ditt paket innehåller vissa bibliotek som kan kollidera med arbetarberoenden (till exempel protobuf, tensorflow eller grpcio) konfigurerar du PYTHON_ISOLATE_WORKER_DEPENDENCIES till 1 i appinställningar för att förhindra att ditt program refererar till arbetarberoenden.
Azure Functions Python-biblioteket
Varje Python-arbetsuppdatering innehåller en ny version av Azure Functions Python-biblioteket (azure.functions). Den här metoden gör det enklare att kontinuerligt uppdatera dina Python-funktionsappar eftersom varje uppdatering är bakåtkompatibel. En lista över versioner av det här biblioteket finns i Azure-functions PyPi.
Körningsbiblioteksversionen har åtgärdats av Azure och kan inte åsidosättas av requirements.txt. Posten azure-functions i requirements.txt gäller endast för linting och kundmedvetenhet.
Använd följande kod för att spåra den faktiska versionen av Python-funktionsbiblioteket i din körning:
getattr(azure.functions, '__version__', '< 1.2.1')
Systembibliotek för körning
En lista över förinstallerade systembibliotek i Docker-avbildningar för Python-arbetare finns i följande:
| Funktionskörning | Debian-version | Python-versioner |
|---|---|---|
| Version 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Python Worker-tillägg
Med Python-arbetsprocessen som körs i Azure Functions kan du integrera bibliotek från tredje part i funktionsappen. Dessa tilläggsbibliotek fungerar som mellanprogram som kan mata in specifika åtgärder under livscykeln för funktionens körning.
Tillägg importeras i funktionskoden ungefär som en standardmodul för Python-bibliotek. Tillägg körs baserat på följande omfång:
| Scope | beskrivning |
|---|---|
| Programnivå | När det importeras till en funktionsutlösare gäller tillägget för varje funktionskörning i appen. |
| Funktionsnivå | Körningen är begränsad till endast den specifika funktionsutlösare som den importeras till. |
Läs informationen för varje tillägg om du vill veta mer om omfånget där tillägget körs.
Tillägg implementerar ett Python-arbetstilläggsgränssnitt. Med den här åtgärden kan Python-arbetsprocessen anropa tilläggskoden under funktionens körningslivscykel. Mer information finns i Skapa tillägg.
Använda tillägg
Du kan använda ett Python Worker-tilläggsbibliotek i dina Python-funktioner genom att göra följande:
- Lägg till tilläggspaketet i filen requirements.txt för projektet.
- Installera biblioteket i din app.
- Lägg till följande programinställningar:
- Lokalt: Ange
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"i avsnittet iValuesdin local.settings.json-fil. - Azure: Ange
PYTHON_ENABLE_WORKER_EXTENSIONS=1i appinställningarna.
- Lokalt: Ange
- Importera tilläggsmodulen till funktionsutlösaren.
- Konfigurera tilläggsinstansen om det behövs. Konfigurationskrav bör anges i tilläggets dokumentation.
Viktigt!
Python Worker-tilläggsbibliotek från tredje part stöds inte eller motiveras inte av Microsoft. Du måste se till att alla tillägg som du använder i funktionsappen är tillförlitliga och att du löper hela risken att använda ett skadligt eller dåligt skrivet tillägg.
Tredje part bör tillhandahålla specifik dokumentation om hur de installerar och använder sina tillägg i funktionsappen. Ett grundläggande exempel på hur du använder ett tillägg finns i Använda tillägget.
Här är exempel på hur du använder tillägg i en funktionsapp, efter omfång:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Skapa tillägg
Tillägg skapas av biblioteksutvecklare från tredje part som har skapat funktioner som kan integreras i Azure Functions. En tilläggsutvecklare utformar, implementerar och släpper Python-paket som innehåller anpassad logik som utformats specifikt för att köras i samband med funktionskörning. Dessa tillägg kan publiceras antingen till PyPI-registret eller till GitHub-lagringsplatser.
Information om hur du skapar, paketar, publicerar och använder ett Python Worker-tilläggspaket finns i Utveckla Python-arbetstillägg för Azure Functions.
Tillägg på programnivå
Ett tillägg som ärvs från AppExtensionBase körs i ett programomfång .
AppExtensionBase exponerar följande abstrakta klassmetoder som du kan implementera:
| Metod | beskrivning |
|---|---|
init |
Anropas när tillägget har importerats. |
configure |
Anropas från funktionskoden när det behövs för att konfigurera tillägget. |
post_function_load_app_level |
Anropas direkt efter att funktionen har lästs in. Funktionsnamnet och funktionskatalogen skickas till tillägget. Tänk på att funktionskatalogen är skrivskyddad och att alla försök att skriva till en lokal fil i den här katalogen misslyckas. |
pre_invocation_app_level |
Anropas precis innan funktionen utlöses. Argumenten för funktionskontext och funktionsanrop skickas till tillägget. Du kan vanligtvis skicka andra attribut i kontextobjektet som funktionskoden ska använda. |
post_invocation_app_level |
Anropas direkt efter att funktionskörningen har slutförts. Funktionskontexten, argumenten för funktionsanrop och returobjektet för anrop skickas till tillägget. Den här implementeringen är en bra plats för att verifiera om körningen av livscykelkrokerna lyckades. |
Tillägg på funktionsnivå
Ett tillägg som ärver från FuncExtensionBase körs i en specifik funktionsutlösare.
FuncExtensionBase exponerar följande abstrakta klassmetoder för implementeringar:
| Metod | beskrivning |
|---|---|
__init__ |
Konstruktorn för tillägget. Den anropas när en tilläggsinstans initieras i en specifik funktion. När du implementerar den här abstrakta metoden kanske du vill acceptera en filename parameter och skicka den till den överordnade metoden super().__init__(filename) för korrekt tilläggsregistrering. |
post_function_load |
Anropas direkt efter att funktionen har lästs in. Funktionsnamnet och funktionskatalogen skickas till tillägget. Tänk på att funktionskatalogen är skrivskyddad och att alla försök att skriva till en lokal fil i den här katalogen misslyckas. |
pre_invocation |
Anropas precis innan funktionen utlöses. Argumenten för funktionskontext och funktionsanrop skickas till tillägget. Du kan vanligtvis skicka andra attribut i kontextobjektet som funktionskoden ska använda. |
post_invocation |
Anropas direkt efter att funktionskörningen har slutförts. Funktionskontexten, argumenten för funktionsanrop och returobjektet för anrop skickas till tillägget. Den här implementeringen är en bra plats för att verifiera om körningen av livscykelkrokerna lyckades. |
Cross-origin resource sharing (CORS)
Azure Functions stöder resursdelning mellan ursprung (CORS). CORS konfigureras i portalen och via Azure CLI. CORS-listan över tillåtna ursprung gäller på funktionsappsnivå. När CORS är aktiverat innehåller Access-Control-Allow-Origin svaren rubriken. Mer information finns i Cross-origin resource sharing.
Resursdelning mellan ursprung (CORS) stöds fullt ut för Python-funktionsappar.
Asynkrona
Som standard kan en värdinstans för Python endast bearbeta en funktionsanrop i taget. Det beror på att Python är en enkeltrådad körning. För en funktionsapp som bearbetar ett stort antal I/O-händelser eller som är I/O-bunden kan du avsevärt förbättra prestandan genom att köra funktioner asynkront. Mer information finns i Förbättra prestanda för Python-appar i Azure Functions.
Delat minne (förhandsversion)
För att förbättra dataflödet låter Azure Functions din out-of-process Python-språkarbetare dela minne med Functions-värdprocessen. När funktionsappen stöter på flaskhalsar kan du aktivera delat minne genom att lägga till en programinställning med namnet FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED med värdet 1. När delat minne är aktiverat kan du sedan använda inställningen DOCKER_SHM_SIZE för att ange det delade minnet till ungefär som 268435456, vilket motsvarar 256 MB.
Du kan till exempel aktivera delat minne för att minska flaskhalsar när du använder Blob Storage-bindningar för att överföra nyttolaster som är större än 1 MB.
Den här funktionen är endast tillgänglig för funktionsappar som körs i Premium- och Dedicated-planer (Azure App Service). Mer information finns i Delat minne.
Kända problem och vanliga frågor och svar
Här är två felsökningsguider för vanliga problem:
Här är två felsökningsguider för kända problem med programmeringsmodellen v2:
- Det gick inte att läsa in filen eller sammansättningen
- Det går inte att matcha Azure Storage-anslutningen med namnet Storage
Alla kända problem och funktionsbegäranden spåras i en GitHub-problemlista. Om du stöter på ett problem och inte kan hitta problemet i GitHub öppnar du ett nytt problem och tar med en detaljerad beskrivning av problemet.
Nästa steg
Mer information finns i följande resurser:
- Dokumentation om Azure Functions-paket-API
- Metodtips för Azure Functions
- Azure Functions-utlösare och bindningar
- Blob Storage-bindningar
- HTTP- och webhook-bindningar
- Kölagringsbindningar
- Timerutlösare
Har du problem med att använda Python? Berätta vad som händer.